
读博两年的工作整理:AI-GPU显存优化领域前沿工作发展史

极市导读
本文为作者读博两年的一个工作总结,对AI场景下关于GPU显存优化的工作综述,详细介绍了该领域下的发展现状以及各设计的优缺点。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
一、前言
来浙两年,从开始对AI、对系统的一窍不通,通过积累,到现在的对部分系统领域有了一定的学术知识积累,这个过程也是跌跌撞撞,充满坎坷。今天,我也将自己读博两年在AI场景下关于GPU显存的优化工作进行整理,为这个领域写一份通俗化的“Survey”。
为什么是AI+GPU显存优化呢?这个就是一个历史问题。当年刚读博的时候一脚踏入AI+Sys的领域(老师接的项目驱使),当时甚至AI模型都没跑过(本科打了2年的CTF比赛2333333),更别说系统的知识。当时印象中只记得我学过操作系统,体系结构,这些知识都是比较泛的内容,并不能给我很好的系统方向科研支撑。可以说是举步维艰。
但是经过这两年的不断看论文,不断跟老师、同学讨论,我也对这个领域逐渐积累了一些知识,知道这个领域的发展现状,各个里程碑论文的详细的设计以及其优缺点。这个过程也迫使我对AI模型、GPU架构等知识进行学习。
多读,多写,多思考。
二、发展伊始(背景)
开坑的论文总会值得一个新的章节。我就把该领域的背景以及开坑的论文放在本章节进行讲述。
为什么说这个领域很重要呢?我们都知道,DNN随机发展异常火,这里就不多说AI的趋势了,反正现在不懂计算机的人也知道AI的概念。

但是我们作为计算机选手,尤其是经常跑模型的人是不是经常会遇到AI框架的Out of Memory的错误?这个原因是随着深度学习的发展,模型变的越来越大,对显存的需求越来越大,而GPU的显存发展跟不上了。
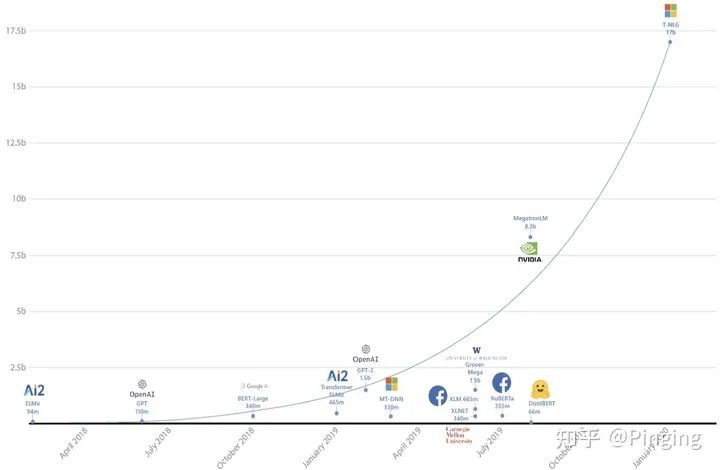
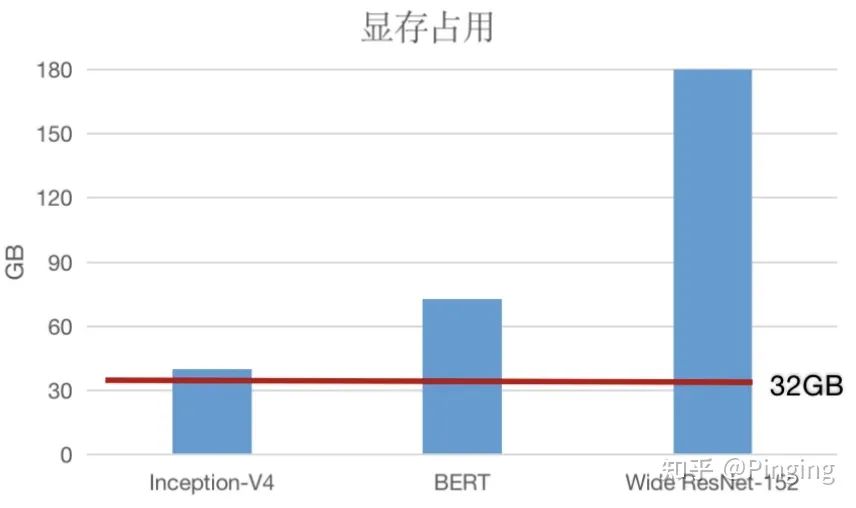
有数据表明深度学习模型(例如GPT-3)这种模型动不动就上百GB,而一个最好的GPU(A100)目前也才80GB的显存容量(也不仅限于NLP模型,CV也有非常大的),所以很明显,当前设备的显存已经不够模型的训练所用了,那你说一边是那么火、那么有用的AI模型,一边是由于系统原因而限制了AI的发展,是不是这个问题需要派人解决一下?
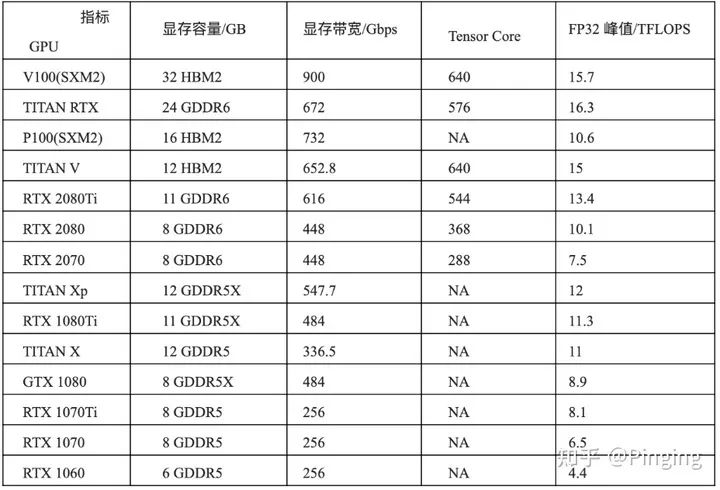
于是,如何解决显存不足问题变得异常重要了。从哲学角度,解决一个问题首先是想让他可用,其次就是让他用的更好。所以,该领域的文章开始的时候都是让GPU能训练大模型,然后逐渐解决如何在已有资源下训练的更快。
1 vDNN-开坑作-2016
首位开坑的文章,即发表在MICRO16(体系结构A会)上的vDNN[1]。
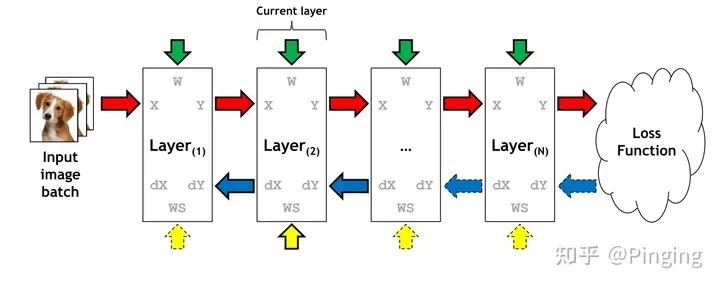
众所周知,了解过GPU的同学应该知道,体系结构上GPU通过PICe总线与Memory相连,而相比于GPU的显存,CPU的内存则显得大的多的多。于是我们是不是想到了转移的思路?

简单来说就是在训练时,把训练当前阶段不需要的数据转移到CPU上,借助CPU上的大内存暂存数据。
而支撑这个想法的原因是因为我们的DNN模型是按照层进行排列的,每一个时刻GPU其实只训练某个层,势必会有一些层的数据我们暂时不需要访问,所以这些数据便可以转移出去。
而这个文章对当时常用的CV模型进行了测试,发现Feature map类型的数据占空间是最大的。
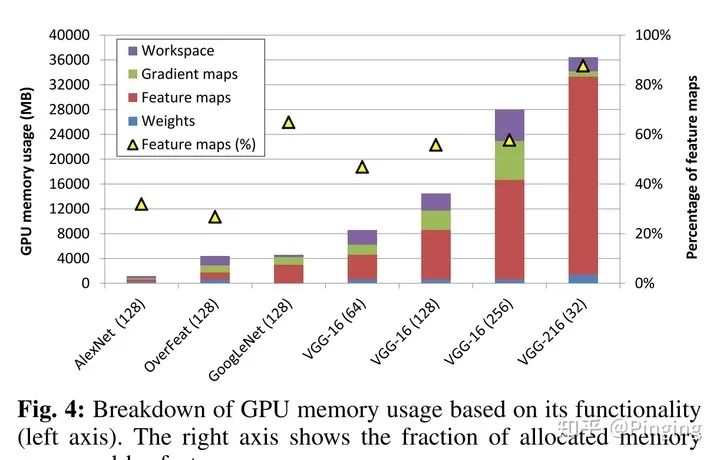
所以重点是面向Feature map的数据进行优化。
进一步,作者发现CV主要包括两个比较重要的层,卷积以及FC全连接。而这两个层中,卷积层的输入占用空间特别多:
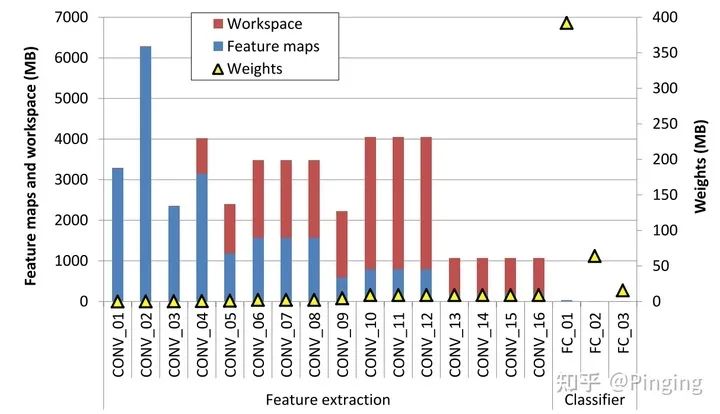
因此,这个文章说,既然卷积这么大,那干脆我就把卷积层的Tensor在前传的时候转出到CPU里面,等到反传需要的时候再提起转回来,于是就有了如下的策略:
这里为了保障系统不崩溃正常运行,所以每一次转入转出操作调用的时候,都需要在该层最后加一个同步指令,从而保障这一层已经转出成功了,才能进行下一层的训练。
至此,vDNN的详细内容应该都清楚了,那他有什么优缺点呢?
优点:第一个利用转移解决显存不足问题的工作,对CV模型进行了详细的特征分析,并降低了显存的使用量; 缺点:由于同步的影响,导致了严重的性能开销,且比较死板,先入为主的就对卷积做策略,随着未来模型的发展,这种方案势必不智能;
同年,Tianqi Chen另辟蹊径,提出了DNN模型层的重计算思想[2]。
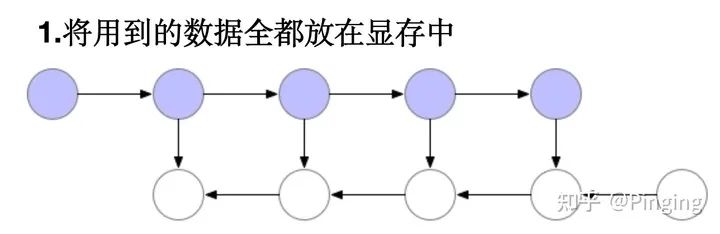
即将上图变成下图的模式,将暂时用不到的显存释放掉,然后反传用到时再通过前传得到。
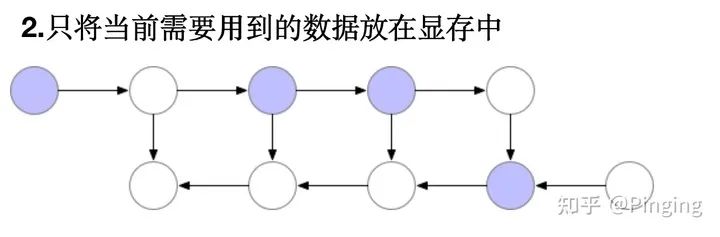
好处能立刻释放大量显存,坏处是计算开销是串行的,特别大。
2 方案二次发展-2018/2019
由第一部分我们学习了两个不同的解决方案,我们首先看对于转移方案来说,有什么进一步的优化文章:
vDNN引起了一票工作的攻击,包括DATE18的MoDNN[3]、IPDPS19的vDNN++[4]。
MoDNN是2018年发表在DATE(CCF-B)上的一篇基于转移的显存优化工作。 他的核心发现是DNN框架中,卷积函数包括很多不同的类别,有的卷积函数空间使用多,但是性能较快(FFT、Winograd algorithm),有的不占用太多内存,但是性能相对较差(GEMM)。所以moDNN能够只能的选择卷积函数,并调整mini-batchsize来最优化系统的执行性能,并智能选择转移策略。(详细内容可移步我之前的总结:moDNN: Memory Optimal DNN Training on GPUs阅读总结) https://www.jianshu.com/p/4bd7e4724193
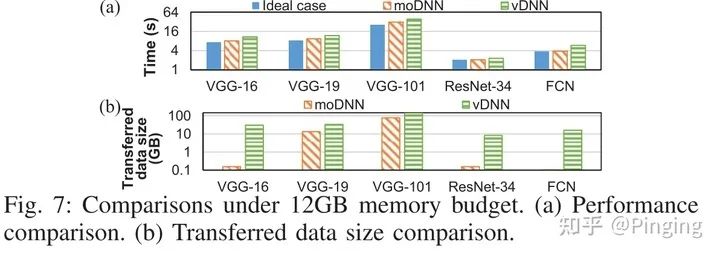
最终于vDNN相比,提升了不少的性能。
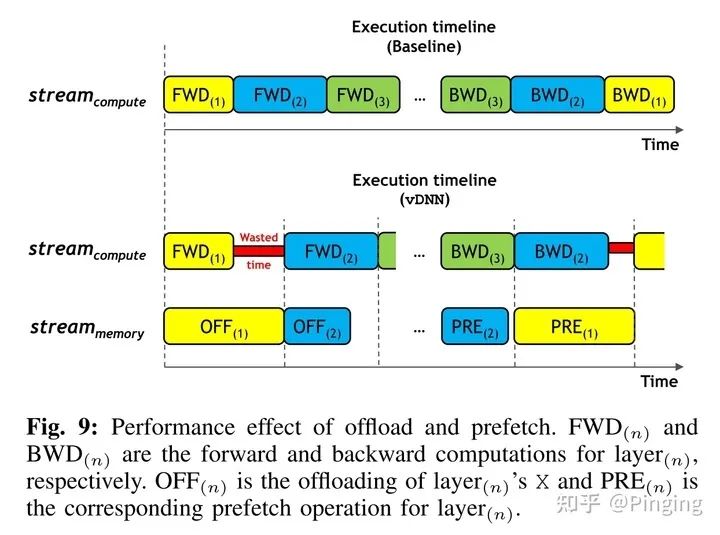
vDNN++是2019年的IPDPS(CCF-B)的文章,下图可知,vDNN会引入许多的Wasted Time,性能太差。
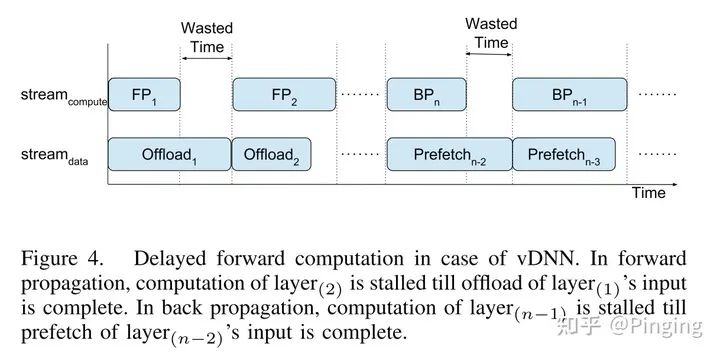
而很多时候其实不用做同步操作,FP1+FP2>Offload1+Offload2,或者不同步也不会造成系统的崩溃情况,于是可以设计成下面的情况:
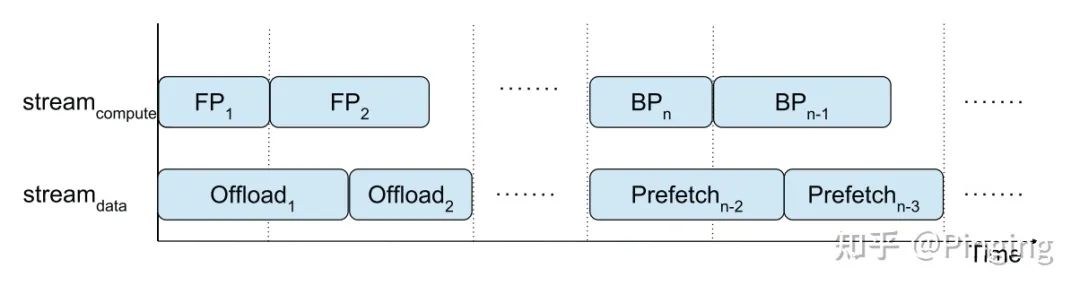
所以针对这一点,vDNN++做了一些优化手段,改进了vDNN。当然vDNN++还对GPU碎片问题,转移后的数据压缩问题进行了进一步优化。
对此其实我觉得剩下的优化都是为了拼凑成,据我看源码所理解,例如现有PyTorch的内存分配机制就做的比较完善,可以避免非常多的分配操作并且重用最适合的空间,碎片问题并不突出,而vDNN++的对比对象是GPU的一个很早期的内存分配工具CNMeM,显得这种对比并不专业;其次,压缩这个问题并不重要,文章的动机是说使用了Pinned memory后DRAM空间被锁死,导致这部分空间占用太大不能被交换到disk,而如今的DRAM就比较大,这样做文章显得Idea分散的非常严重。这里不建议这样做论文。
除了转移的优化外,2018年还有一篇影响力比较大的文章SuperNeurons[5]。一反常态,这个工作首次将转移、重计算结合到一起,提出了一个系统级的优化框架。
其核心思想可以归结为下面三点,从而针对不同类别的层进行不同的策略。

最终一步一步释放显存:
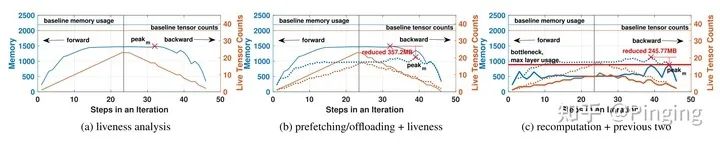
然而,作为早期文章,该方案同样先入为主的对当时比较主流的几个模型进行了分析,并有使用固定思维对某些层做某些事情,不够灵活。随着发展,更多的模型出来后,这种略显不灵活的方法就不够用了。后面在2020年会有一篇新的文章做的更深入。
本年度还有一篇顶会文章-Gist[6],该文章通过另辟蹊径,将压缩引入DNN的显存优化,从而开辟了新的领域。
本文针对ReLU的输出进行有损+无损的压缩,释放了许多ReLU层相关的显存,节省了空间。
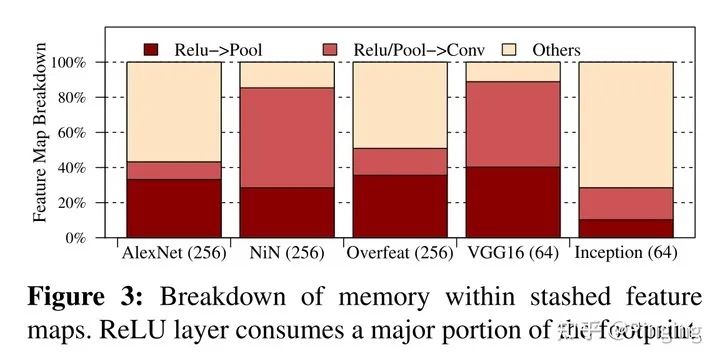
而该文章具有较强的针对性,即必须对含有ReLU的模型进行操作,所以也限制了其贡献。而想看详细文章的同学可以移步我之前总结的GIST的内容:Pinging:Gist: Efficient Data Encoding for Deep Neural Network Training(https://zhuanlan.zhihu.com/p/366260011)
而在压缩方面,2018年同样在顶会上有一篇基于硬件的压缩文章-cDMA[7]。
该文章利用了ReLU输出层的稀疏特性,并在GPU中做了一个硬件core来压缩这些数据,以减少转移的数据量,最终提升性能。
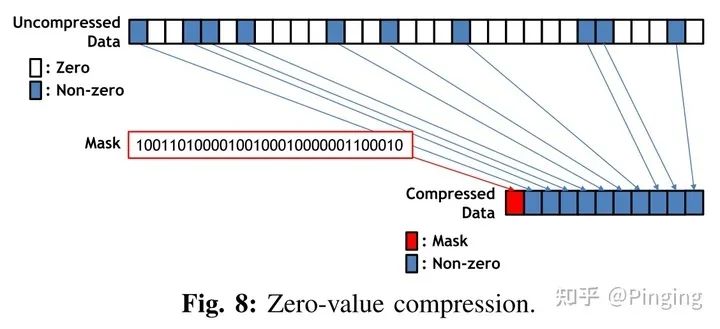
但是这种硬件的文章其实都是基于模拟器做,也无法为我们所用。并且压缩算法定制到硬件上,也比较单一,所以弊端还是很多的。
3 第三次跃进-2020
第三次工作便要来到2020年,这一年涌出了一批相对比较优秀的GPU显存解决工作,其中具有代表性的是ASPLOS'20这个会议。
首先是SwapAdvisor[8]。这篇工作的想法比较简单,作者认为之前的基于人工判断的转移方法并不高效(例如vDNN的只对卷积转移)。所以他认为系统可以使用传统的启发式搜索方案来进行转移策略的搜索,这里选择的是遗传算法。
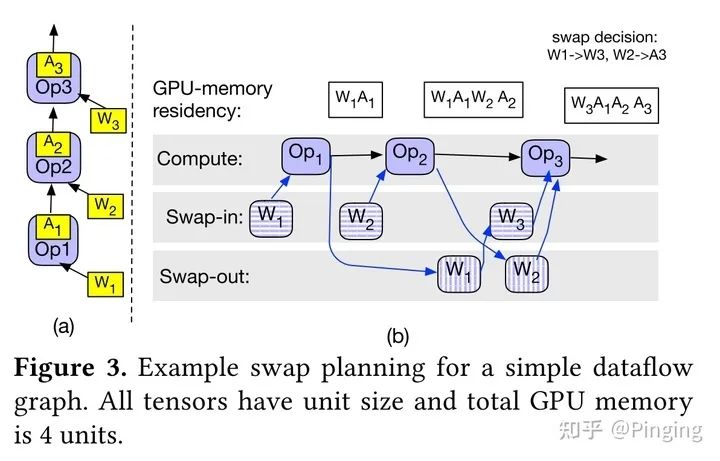
虽然想法简单,但是作者还是经过了大量的实验测试以及对比,最终选择了遗传算法,并且针对遗传算法的流程以及DNN的流程,将转移这个操作建模出来,并且也对非线性网络的支持比较好。
但是这个时候有人会问,既然是启发式搜索,那为什么不选择暴力搜索呢?岂不是效果会更好?那这个问题问到点子上了,那我们看下面一篇文章。
AutoTM[9]是ASPLOS'20的另一篇文章,这个文章的大背景就是使用暴力搜索(线性整数规划)来搜索出来合适的转移策略。而这个文章的另一个卖点是他是第一个使用CPU的DRAM+NVM(非易失性内存)进行策略搜索的工作,并且开源了代码。
其实这个工作我探究了比较多,其实文章也或多或少不能解决所有的问题。比如由于是暴力搜索,那搜索空间不能太大,所以模型太大了直接gg;其次,这里的转移搜索策略对于NVM来说,只能是同步,因为异步的话会卡在内存总线的带宽上,性能很差;
不过整体来说,这个工作也算是开辟新思路,功劳不是特别足,苦劳很足的一篇文章。(详细内容可以移步我之前的总结:AutoTM: Automatic Tensor Movement in Heterogeneous Memory Systems using Integer Linear Programmin...)
https://www.jianshu.com/p/3c5f89166eb1
然而,除了上述几篇转移的工作外,本年的ASPLOS会议上还有一篇GPU显存优化的工作-Capuchin[10],而该工作就是在SuperNeurons的基础上,做的更深更好(转移+重计算)。
这篇工作我个人认为是这个领域做的最好的文章之一,可以说解决了很多GPU显存的问题。简单来说,该工作有如下三点Motivation:
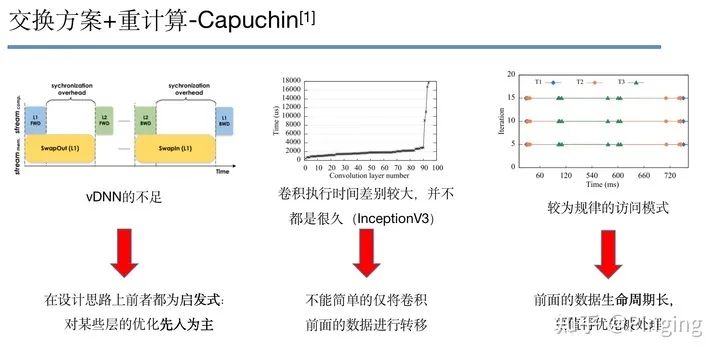
不能先入为主的对各种层做特定操作(例如就对卷积的Tensor做转移,对Pool做重计算等等),这样势必不能达到比较高效(也不能是最高效),于是这个文章先详尽一切办法把能并行的转移并行进来,然后迭代调出最优的重计算方案,直到内存容量足够为止。那么对那些数据进行重计算呢?
本文引入公式,对不同Tensor按照下面的公式计算,从而排序进行优化:
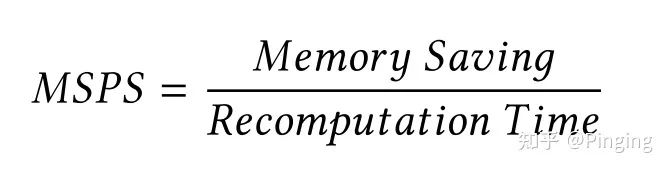
而这个公式将Tensor按照内存保存量以及重计算的时间需要进行了权重计算,简单来说,Tensor中重计算时间越少,内存保存量越大的数据,越值得我们首先考虑(很符合我们的正常逻辑)。
相比于之前的SuperNeurons,这个工作就无关什么层的类型,我一视同仁,只要你能并行,我就并行起来,并且选择最优的重计算方案。对比其他的仅转移方案的文章,本文引入了重计算,从而在某些情况下重计算的开销会比转移低,从而提升模型训练的性能。
(详细内容可以移步我之前的总结:Capuchin: Tensor-based GPU Memory Management for Deep Learning论文总结)
https://www.jianshu.com/p/cfa4e8c3e224
而对于本文,我其实还是持赞扬的态度,做的比较扎实,并且效果比较好。这也为我们该领域未来的创新带来了不小的压力。可以说是转移+重计算方案的天花板级别。
3 转移工作第四次跃进-2021
随着工作越做越细致(卷),2021年在显存优化上出现了颇多更有意思的点,例如FlashNeuron[11]。这个论文一反常态,认为上述一堆文章都是把数据转移到CPU的DRAM上,但是那些文章都没有考虑过内存、CPU正在执行数据预处理操作,从而使得内存总线始终在忙碌,从而使得转移性能极差,例如下图所示,转移性能随着CPU忙碌而变差。
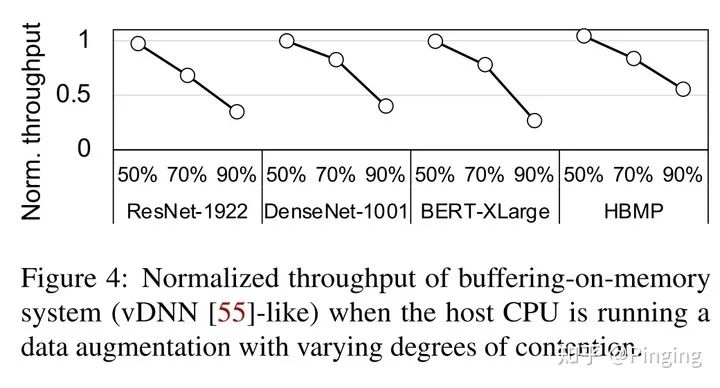
于是这个文章破天荒的将数据转移到SSD上,并利用了比较简单的转移方法,引入压缩从而进一步降低转移数据量。
而该文章也push我去学习了一下GPU 2 SSD的一些知识。GPU direct技术也是前些年出来的,但是现在论文利用的并不多。我分析来主要原因就是因为他的转移速度不够快,虽然走PCIE总线,但是大概只有3GB/s的单项转移速度。而对于内存,因为有Pinned memory,所以其理论转移能到16GB/s。
该年还有一篇显存优化的文章:Sentinel来自HPCA21[12]。这篇文章其实最早的时候挂在Arxiv上,我在刚入学的时候也曾拜读过,他算是第二篇将NVM与DRAM结合的文章,但是他的点比较微观,抓住的是转移页的时候,生命周期不同的的数据被分配到了同一个页中,造成了大量不必要的转移。
所以这个文章把这个问题解决了。并且实验对比了当前最好的一系列文章,最终也中了顶会。但是这个文章很难复现,且只利用了转移这个思想,整体读起来有点向着底层走,而不像ASPLOS20那几个文章一样更容易宏观理解。
再者就是ATC21的ZeRO-Offload文章[13]。
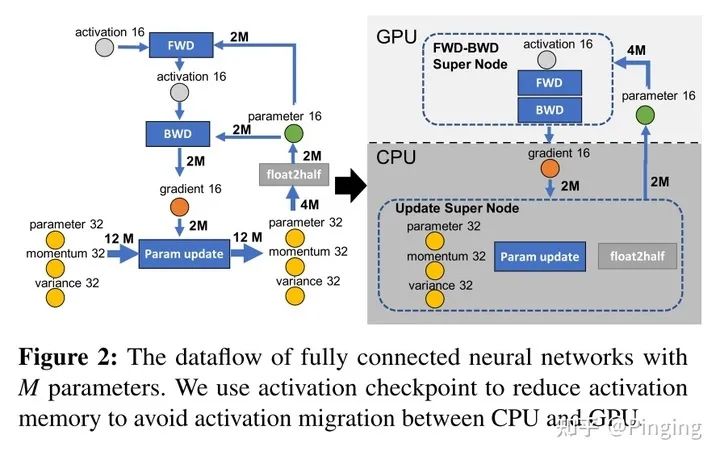
上述两个文章出于同一个作者,不得不膜拜Jie Ren学姐。而该文章在讲故事的时候,说之前的文章就转移、重计算以及压缩三个手段,做来做去的没啥意思。那能否考虑第四种方案?比如利用CPU的计算?
于是这个文章发现啊,NLP里面有许多参数其实是为优化器所用的。与CV不同,CV是Feature map特别大,而NLP偏向parameter,而优化器内部其实是和weight的量成正比的。加上momentum以及variance大概能有3倍。所以这个文章把优化器所有参数卸载到CPU上了,包括计算在内,并设计了更快的CPU优化器运算,从而做到了完美的GPU显存优化。
最后,我再分享一下2021年CLUSTER21的关于DNN+压缩的优化文章-CSWAP。
这个文章利用了ReLU输出数据的稀疏特性、稀疏可变特性(随着训练的进行不同层的稀疏程度是可变的),提出了选择性压缩的架构,在转移的过程中,如果数据压缩+转移性能好,那我们就压缩,否则就不压缩。
为了达成这个目的,本文利用了2个机器学习模型对一些指标进行预测,从而比较准确的挑选出合适的层进行压缩+转移,其余只转移,从而在优化显存的同时,最优化训练性能。
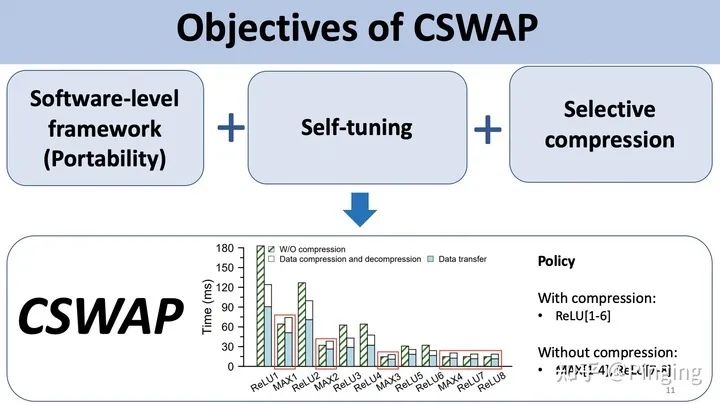
不卖关子了,这个文章就是我的:)
总结
其实这几年看了不少相关的文章,这里只挑选了我觉得比较重要的几篇进行串讲。这里对上面的文章做一个表格总结:
| 年份 | 会议 | 题目 | 方案 | 备注 |
|---|---|---|---|---|
| 2016 | MICRO | VDNN | 转移 | 第一篇转移 |
| 2016 | arXiv | Checkpoint | 重计算 | 第一篇重计算 |
| 2018 | DATE | moDNN | 转移 | 考虑不同卷积函数的性能 |
| 2018 | PPoPP | SuperNeurons | 转移+重计算 | 第一篇转移+重计算 |
| 2018 | HPCA | cDMA | 转移+压缩 | 硬件对ReLU输出层压缩 |
| 2019 | IPDPS | vDNN++ | 转移+压缩 | 针对vDNN的性能问题进行解决 |
| 2020 | ASPLOS | AutoTM | 转移 | NVM+DRAM的暴力搜索 |
| 2020 | ASPLOS | SwapAdvisor | 转移 | 启发式搜索+GPU碎片问题 |
| 2020 | ASPLOS | Capuchin | 转移+重计算 | 转移+重计算的较为优秀的方案 |
| 2021 | FAST | FlashNeuron | 转移 | 引入SSD转移 |
| 2021 | ATC | ZeRO-Offload | 转移 | 利用CPU的计算能力 |
| 2021 | CLUSTER | CSWAP | 转移+压缩 | 对稀疏数据进行选择性压缩,最优化性能 |
| 2021 | HPCA | Sentinel | 转移 | NVM+DRAM场景,考虑细粒度Page上的数据情况 |
这里放一些B站之前做系统方面分享的GPU知识视频:系统论文阅读研讨会week8: GPU简介和PIM(Processing in Memory)简介(https://www.bilibili.com/video/BV18V411J7uT?spm_id_from=333.999.0.0)
以及上述文章的PPT讲解版:系统论文阅读研讨会week10:机器学习系统(二)(https://www.bilibili.com/video/BV1VV411E7Gb?spm_id_from=333.999.0.0)
希望本文能帮助同行们梳理知识点,并且希望自己能做一个合格的博士生,毕业的时候能问问自己,少了自己的研究,自己的领域会不会因此而少了很多关键技术。
未来:写了这么多内容,是不是要谈一谈在这个领域耕耘这么多年的看法了?
首先,GPU显存一定是个很值得关注的问题。现在最好的A100才80GB,但是却要花费小10w元。而GPT-3这种模型动不动就上百上千的显存需求。所以不研究不行呀!
其次,这个领域已经白热化了(非常卷)。这几年涌现了比较多的文章,其实再提出新的解决思路已经比较困难了。但是,我觉得传统的方案仍然具有时代印记,随着新模型、新的模型运算特征出现,新的方法或者手段就可以被用进来。另外就是AI框架的代码确实不容易阅读,要沉下心来仔细钻研;
其实我的研究不仅限于GPU显存,我们对很多AI的场景以及存储、计算等都进行过调研研究,最后,欢迎感兴趣的同学跟我交流,对AI+Sys有兴趣的话,有机会可以来我们组深造读书,我们一起并肩战斗!
参考文献
感谢实验室的老师和伙伴们,这几年确实学到了许多,未来继续努力。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
