
Yolov5理论学习笔记
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
转自 | 马少爷
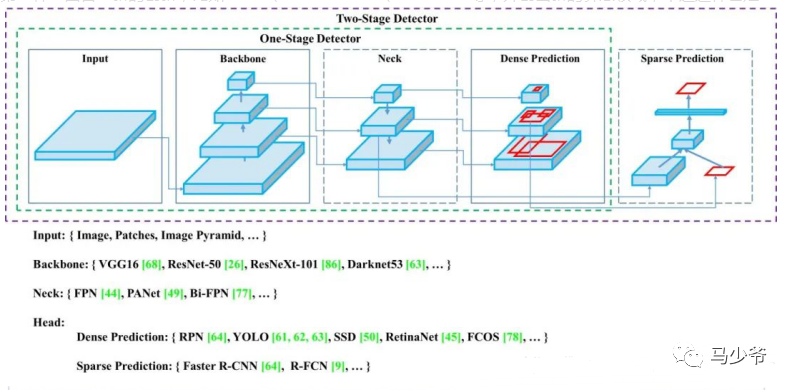
不同网络的宽度:
V5x: 367MB,V5l: 192MB,V5m: 84MB,V5s: 27MB,YOLOV4: 245 MB
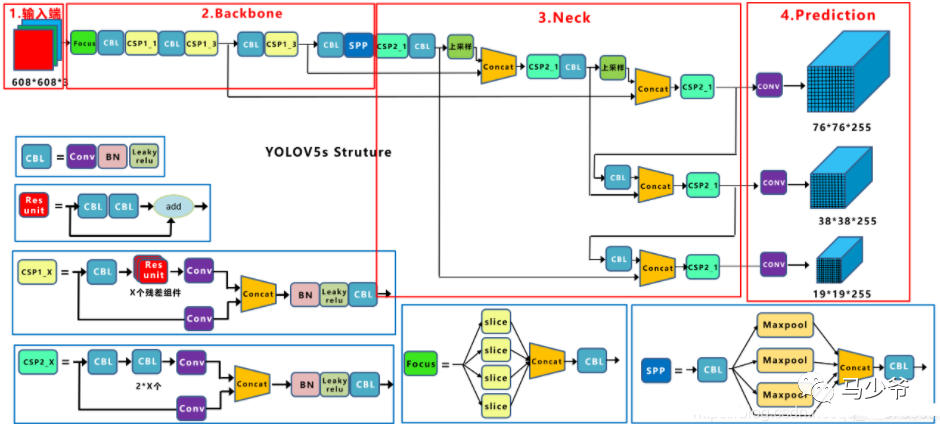
【输入端】
①数据增强:
Mosaic数据增强
②自适应锚定框Auto Learning Bounding Box Anchors
网络在初始锚框的基础上 基于训练数据 输出预测框,因此初始锚框也是比较重要的一部分。见配置文件*.yaml, yolov5预设了COCO数据集640×640图像大小的锚定框的尺寸:
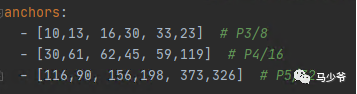
每次训练时,自适应的计算不同训练集中的最佳锚框值。如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。具体操作为train.py中下面一行代码,设置成False

③自适应图片缩放
在常用的目标检测算法中,一般将原始图片统一缩放到一个标准尺寸,再送入检测网络中。Yolo算法中常用416416,608608等尺寸。因为填充的比较多,会存在信息冗余,所以yolov5对原始图像自适应的添加最少的黑边。
【Backbone】
①Focus结构
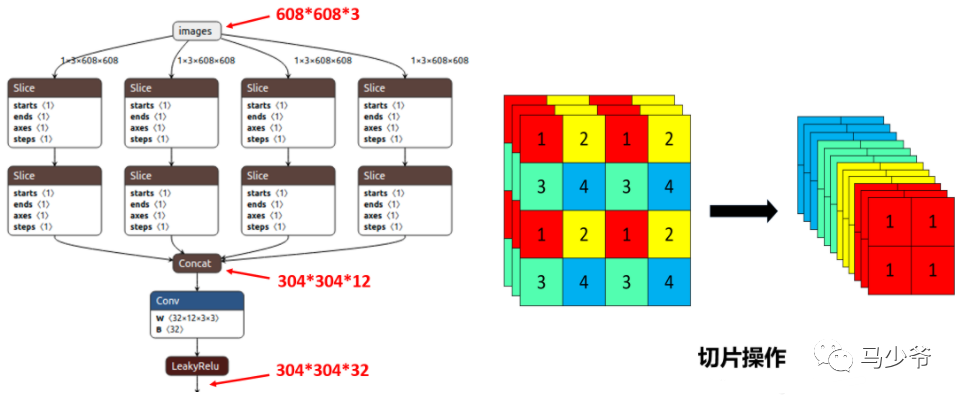
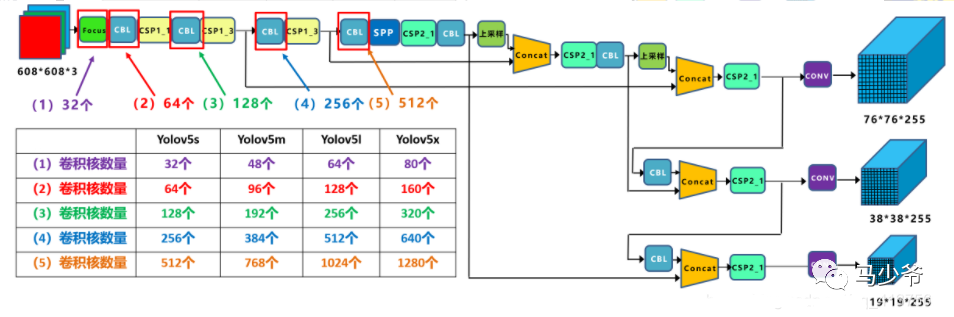
以Yolov5s的结构为例,原始608x608x3的图像输入Focus结构,采用切片操作,先变成304x304x12的特征图,再经过一次32个卷积核的卷积操作,最终变成304x304x32的特征图。
②CSP结构
作者认为推理计算过高的问题是由于网络优化中的梯度信息重复致,CSPNet(Cross Stage Paritial Network, 跨阶段局部网络),主要从网络结构设计的角度解决推理中计算量很大的问题。
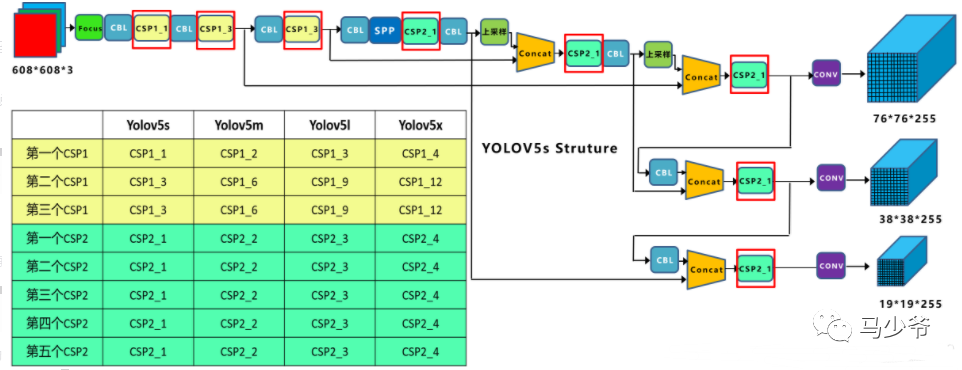
Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
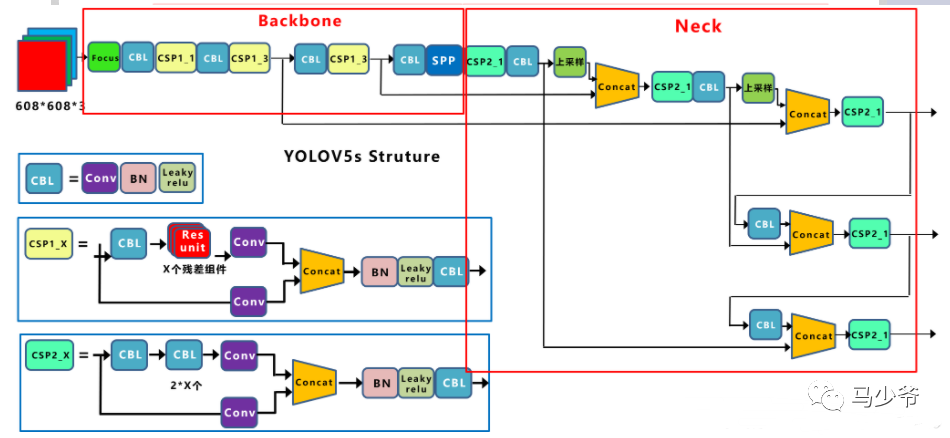
【Neck】
FPN+PAN,网络特征融合的能力更强
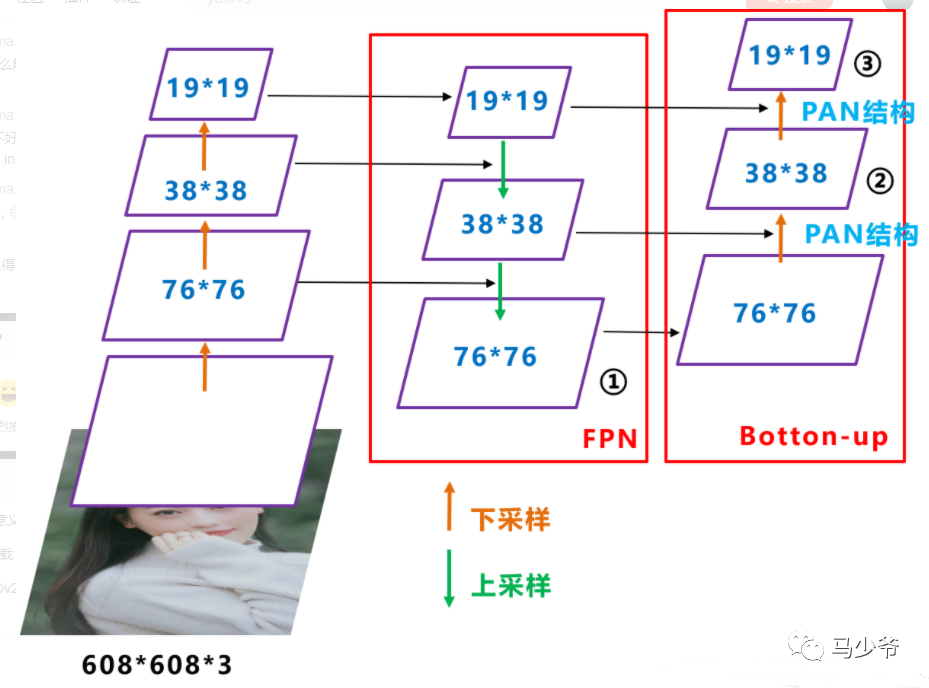
PAN(路径聚合网络)借鉴了图像分割领域PANet的创新点
该作者认为在对象检测中,特征融合层的性能非常重要,根据谷歌大脑的研究,[BiFPN]才是特征融合层的最佳选择。谁能整合这项技术,很有可能取得性能大幅超越。
【输出端】
①Activation Function
在 YOLO V5中,中间/隐藏层使用了 Leaky ReLU 激活函数,最后的检测层使用了 Sigmoid 形激活函数
②nms非极大值抑制
在同样的参数情况下,将nms中IOU修改成DIOU_nms。对于一些遮挡重叠的目标,会有一些改进。
③Optimization Function
YOLO V5的作者为我们提供了两个优化函数Adam和SGD,并都预设了与之匹配的训练超参数。默认为SGD。
④Cost Function
loss = objectness score+class probability score+ bounding box regression score
YOLO V5使用 GIOU Loss作为bounding box的损失。
YOLO V5使用二进制交叉熵和 Logits 损失函数计算类概率和目标得分的损失。同时我们也可以使用fl _ gamma参数来激活Focal loss计算损失函数。
参考文献:
https://blog.csdn.net/qq_41375609/article/details/112059670
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
—THE END—