yolov5超参数演化
ML 中的超参数控制训练的各个方面,为它们找到最佳值可能是一个挑战。由于 1) 高维搜索空间 2) 维度之间未知的相关性,以及 3) 评估每个点的适应度的昂贵性质,网格搜索等传统方法很快变得难以处理,这使得 GA 成为超参数搜索的合适候选者。
在你开始前
克隆这个 repo 并安装requirements.txt依赖项,包括Python>=3.8和PyTorch>=1.7。
$ git clone https://github.com/ultralytics/yolov5 # clone repo
$ cd yolov5
$ pip install -r requirements.txt # install dependencies
1. 初始化超参数
YOLOv5 有大约 25 个超参数用于各种训练设置。这些在 /data 目录中的 yaml 文件中定义。更好的初始猜测会产生更好的最终结果,因此在进化之前正确初始化这些值很重要。如果有疑问,只需使用为 YOLOv5 COCO 训练从头开始优化的默认值。https://github.com/ultralytics/yolov5/blob/3bb414890a253bb1a269fb81cc275d11c8fffa72/data/hyp.scratch.yaml#L1-L33
2. 定义适合度
健身是我们寻求最大化的价值。在 YOLOv5 中,我们将默认适应度函数定义为度量的加权组合:mAP@0.5 贡献了 10% 的权重,而 mAP@0.5:0.95 贡献了剩余的 90%。您可以根据需要调整这些参数或使用默认的适应度定义。https://github.com/ultralytics/yolov5/blob/c5d233189729a9e7e25d3aa2d347aed02b545d30/utils/general.py#L917-L921
3. 进化
进化是针对我们寻求改进的基本场景进行的。本示例中的基本场景是使用预训练的 YOLOv5 对 COCO128 进行 10 个时期的微调。基本场景训练命令是:
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache
为了演化特定于此场景的超参数,从我们在第 1. 节中定义的初始值开始,并最大化第 2. 节中定义的适应度,附加--evolve:
# Single-GPU
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
# Multi-GPU
for i in 0 1 2 3; do
nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve --device $i > evolve_gpu_$i.log &
done
# Multi-GPU bash while (not recommended)
for i in 0 1 2 3; do
nohup "$(while true; do python train.py ... --evolve --device $i; done)" > evolve_gpu_$i.log &
done
默认进化设置将运行基本场景 300 次,即 300 代:https://github.com/ultralytics/yolov5/blob/c5d233189729a9e7e25d3aa2d347aed02b545d30/train.py#L497
主要的遗传算子是交叉和变异。在这项工作中使用突变,以 90% 的概率和 0.04 的方差,基于所有前几代的最佳父母的组合来创建新的后代。结果在 中跟踪yolov5/evolve.txt,并且每代保存最高适应度的后代为yolov5/runs/evolve/hyp_evolved.yaml:
# Hyperparameter Evolution Results
# Generations: 1000
# P R mAP.5 mAP.5:.95 box obj cls
# Metrics: 0.4761 0.79 0.763 0.4951 0.01926 0.03286 0.003559
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
anchors: 0 # anchors per output grid (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
我们建议至少进行 300 代进化以获得最佳结果。请注意,进化通常既昂贵又耗时,因为基本场景经过数百次训练,可能需要数百或数千个 GPU 小时。
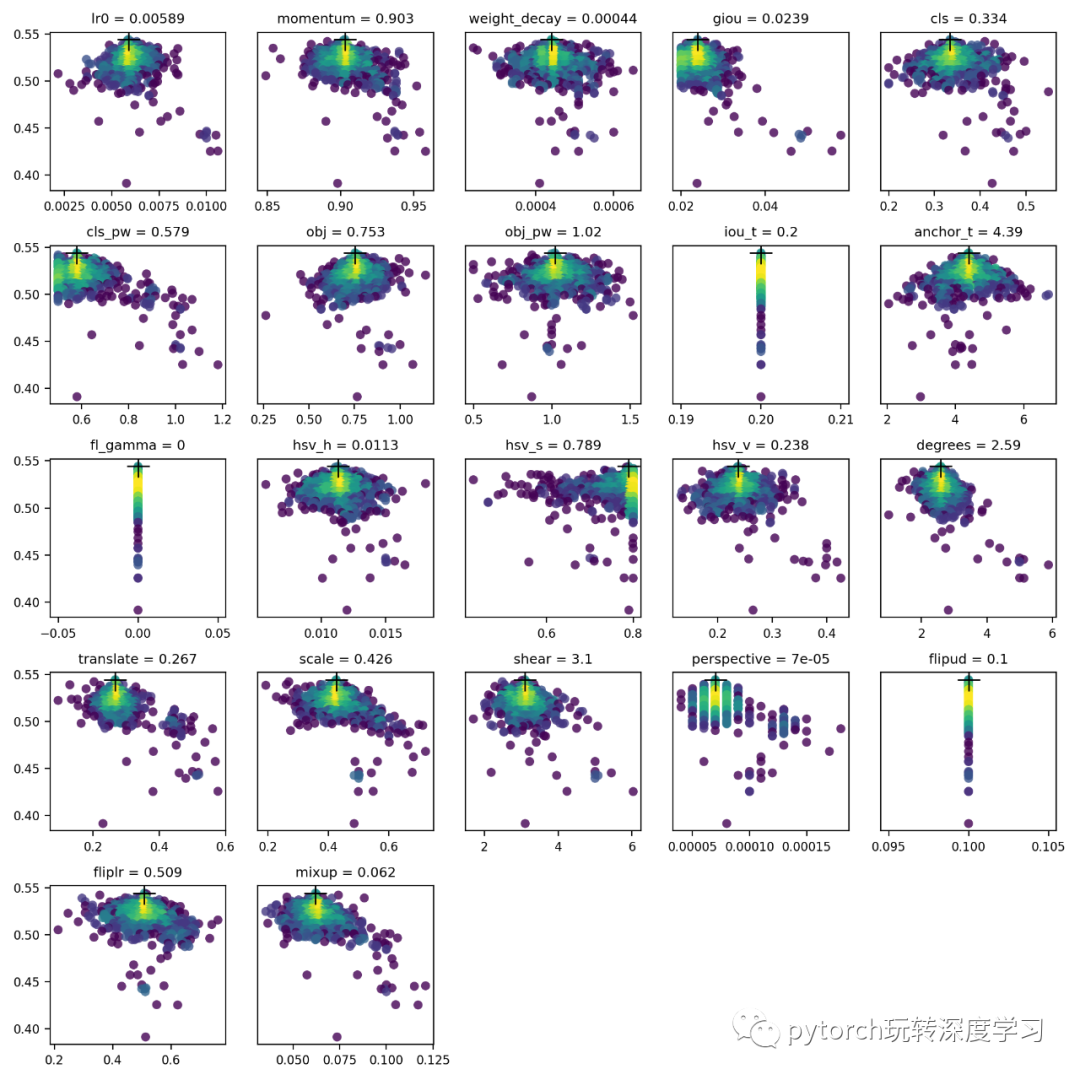
4. 可视化
结果保存为yolov5/evolve.png,每个超参数一个图。值在 x 轴上,适应度在 y 轴上。黄色表示较高的浓度。垂直线表示参数已被禁用且不会发生变化。这是用户可以在metatrain.py的字典中选择的,对于固定参数和防止它们演变很有用。