
Meta-DETR | 图像级“元”学习提升目标检测精度
One-shot目标检测旨在通过几个标注的样本来检测新的目标。之前的工作已经证明了元学习是一个很有前途的解决方案,它们中的大多数基本上是通过解决在区域上的元学习检测来进行分类和位置微调。
启发:人类可以只看目标一次,就可以达到对目标的快速识别能力,但是机器目前无法达到这样的水平。也就是在小样本情况下的深度学习目标检测仍然存在很大的困难。
然而,这些方法在很大程度上依赖于最初位置良好的候选区域,这通常在one-shot设置下很难获得。研究者提出了一种新的元检测器框架,即Meta-DETR,实现区域预测,并以统一互补的方式在图像水平上学习目标位置和分类。具体地说,它首先将support和query图像编码为特定类别的特征,然后将它们输入到一个与类别无关的解码器中,以直接生成具体类的预测。为了促进深度网络的元学习,研究者设计了一个简单而有效的语义对齐机制(Semantic Alignment Mechanism,SAM),它协调高级和低级特征语义,以改进元学习表示的泛化。
二、背景
计算机视觉近年来取得了重大进展。然而,在从很少的例子中学习新概念方面,当前的计算机视觉技术和人类视觉系统之间仍然存在着巨大的差距:大多数现有的方法需要大量的标注样本,而人类即使需要很少的指导,也可以毫不费力地识别一个新概念。特别是当没有足够的训练样本或很难获得其注释时,这种从有限的例子中推广的类人能力对于机器视觉系统是非常可取的。

如上图的上部,它们主要通过对区域执行元学习,包括候选区域、定位点和窗口中心,来进行分类和位置微调。然而,正如在[QiFan,WeiZhuo,Chi-KeungTang,andYu-WingTai.Few-
shot object detection with attention-RPN and multi-relation
detector. In CVPR, 2020]和[Weilin Zhang, Yu-Xiong Wang, and D. Forsyth. Coop-
erating RPN’s improve few-shot object detection. ArXiv,
2011.10142, 2020]中所指出的那样,这些方法在很大程度上依赖于初始候选区域的质量,这在训练样本稀缺的one-shot设置中不能得到保证,从而产生不准确或缺失的检测。虽然FSOD提议元学习区域候选的生成,但这个问题仍然是由于该框架本身仍然是基于区域的。
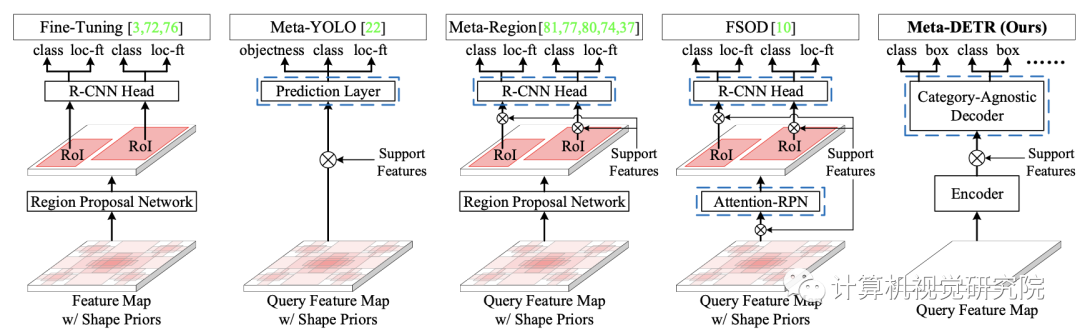
基于上述分析,现有元检测器的一个关键局限性是区域预测方法。此外,在具有挑战性的one-shot目标检测设置下,对标注样本的监督最小,应该最大限度地利用分类和定位之间的互补效应。因此,理想的元检测器应该放弃这种基于区域的预测,并通过完全端到端的元学习两个子任务,有效地利用分类和定位之间的协同关系。然而,据我们所知,这样的框架仍然没有存在。
Few-Shot Learning
one-shot学习旨在在从很少的样本中学习新概念,缩小现有模型和人类之间的差距。一个很有前途的解决方案是元学习,它旨在提取元层次的知识,可以通过“学习到学习”跨各种任务进行推广。大量的研究已经证明了元学习范式在one-shot分类任务中的有效性。然而,其他更复杂的one-shot学习任务仍然相对没有充分探索。
三、新框架
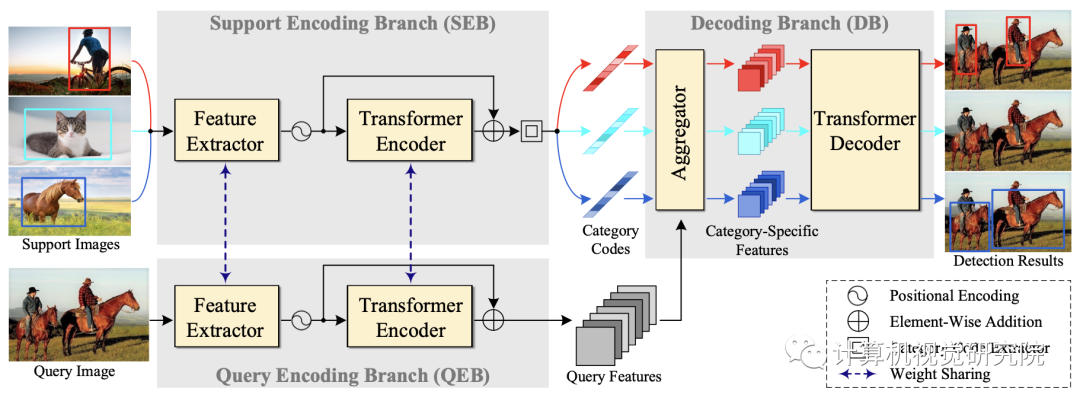
为了在图像层面上进行统一的定位和分类元学习,新框架的元学习在概念上很简单。如上图所示,它由查询编码分支(QEB)、支持编码分支(SEB)和解码分支(DB)组成。给定一个查询图像和几个带有实例标注的支持图像,QEB和SEB首先分别将它们分别编码为查询特征和类别代码。然后,DB以查询特征和类别代码作为输入,并预测相应支持类别的检测结果。由于要检测的目标类别是基于提供的支持图像的动态条件的,Meta-DETR能够提取类别不可知的元级知识,可以很容易地适应新的类别。
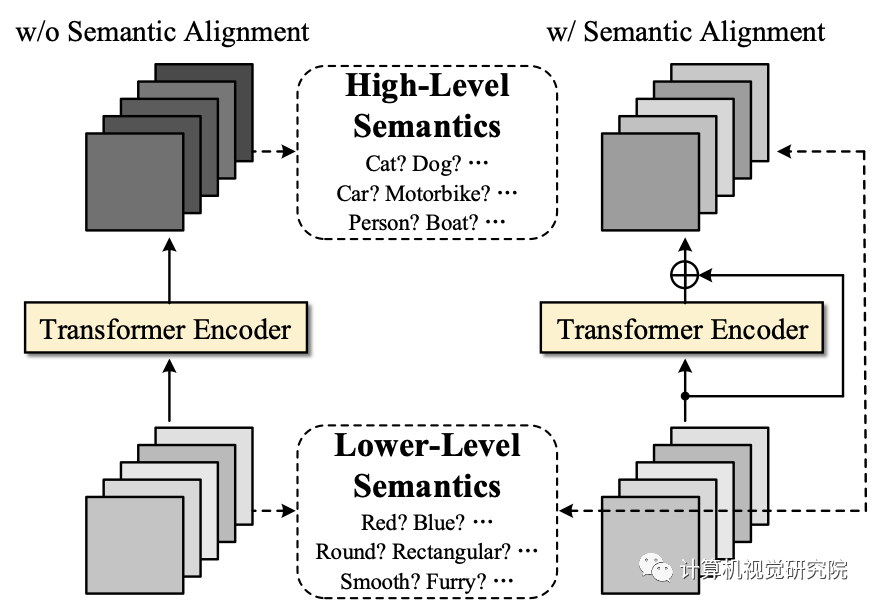
Semantic Alignment Mechanism:一个简单的残差连接作为自正则化,通过对齐输入和输出的特征语义,防止transformer编码器依赖于期望的类别特定特征。
四、实验
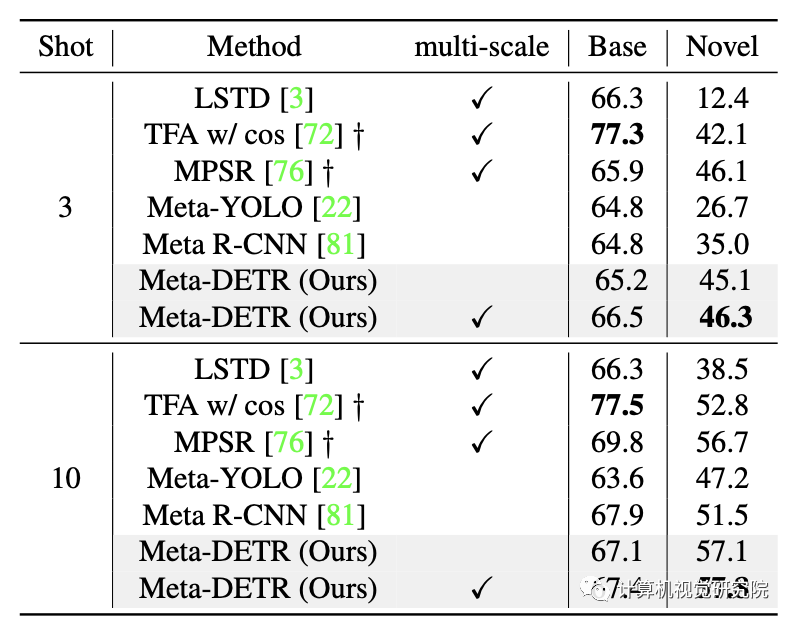
Pascal VOC test 07测试结果
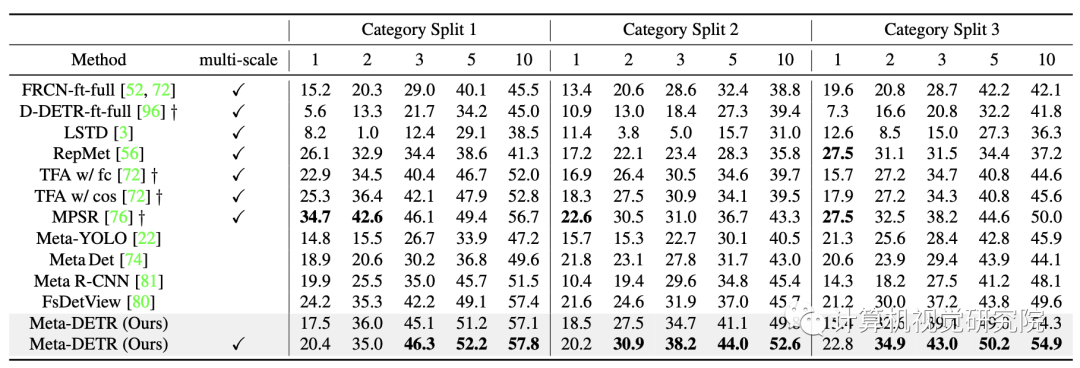
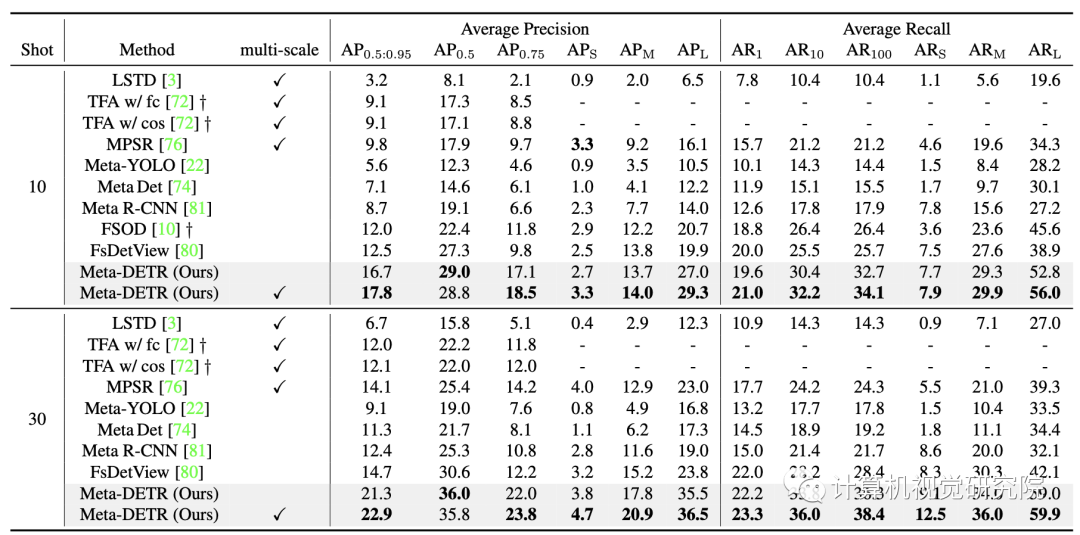
MS COCO val 2017测试结果

可视化查询特征和类别代码之间的相关性。通过引入语义对齐机制(SAM),观察到了对基类和新类(鸟)的清晰响应,证明了SAM在增强元学习表示的泛化方面的有效性。

Visualization of multi-scale Meta-DETR’s 10-shot object detection results on Pascal VOC category split 1. Novel categories
include bird, bus, cow, motorcycle, and sofa. For simplicity, only results of novel categories are illustrated. White boxes indicate correct
detections. Red solid boxes indicate false positives. Red dashed boxes indicate false negatives.

Visualization of multi-scale Meta-DETR’s 30-shot object detection results on MS COCO. Novel categories include person,
bicycle, car, motorcycle, airplane, bus, train, boat, bird, cat, dog, horse, sheep, cow, bottle, chair, couch, potted plant, dining table, and
tv. For simplicity, only results of novel categories are illustrated. White boxes indicate correct detections. Red solid boxes indicate false
positives. Red dashed boxes indicate false negatives.
✄------------------------------------------------
双一流高校研究生团队创建 ↓
专注于计算机视觉原创并分享相关知识 ☞
