
数据项目总结:王者荣耀总决赛预测!
王者荣耀就要打KPL总决赛了,Datawhale数据项目群有粉丝希望来一期游戏数据挖掘。

0. 前言
玩过王者荣耀的同学都知道,游戏为了尽可能地平衡,包括游戏地地形和英雄地强度会每隔一段时间调整,因此游戏数据中游戏本身是变化的。
在游戏过程中,玩家的等级的高低以及金币的多少包括战术的多变也会让整个比赛变得极具有对抗性,同时选手的个人状态和现场教练的战术灵活指导也会让电子竞技的的结果瞬息万变。
在这个项目中我们我们尽可能地用简单的模型来来对结果进行预测,希望大家在享受电子竞技的同时也能感受数据挖掘的魅力。
1. 数据获取
针对KPL秋季赛,王者荣耀本身是提供了一个赛事数据平台

但是这个平台似乎不怎么稳定,公开的数据信息量不多,因此我们选择了玩加电竞平台。
链接:https://link.zhihu.com/?target=http%3A//www.wanplus.com/kog
2020KPL秋季赛常规赛总共有15轮依次对战,截止到现在总共产生了520场比赛,我们通过爬虫爬取比赛的相关信息。
第一部分是获得比赛在网站中的代号。
"""
王者荣耀比赛预测
#2020KPL秋季赛
比赛模型预测
"""
import time
import random
import requests
from bs4 import BeautifulSoup
from lxml import etree
import pandas as pd
from tqdm import tqdm
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)"]
#爬取比赛的信息
def spyder():
headers = {'User-Agent': random.choice(user_agent)}
# 爬取比赛代号
schedule=[i for i in range(66028,66148)] #常规赛
schedule1=[i for i in range(66652,66664)] #季后赛
schedule.extend(schedule1)
match_list=[]
for i in tqdm(schedule):
url='https://www.wanplus.com/schedule/%s.html'%i
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'lxml')
all_match = soup.find_all('li', status='done')
for match in all_match:
matchnum=match['match']
match_list.append(matchnum)
df=pd.DataFrame(columns=['match','teama','teamb','label','moneya','moneyb','killa','killb','towera','towerb','bana1','bana2','bana3','bana4','banb1','banb2','banb3','banb4','heroa1','heroa2','heroa3','heroa4','heroa5','herob1','herob2','herob3','herob4','herob5','kdaa1','kdaa2','kdaa3','kdaa4','kdaa5','kdab1','kdab2','kdab3','kdab4','kdab5','moneya1','moneya2','moneya3','moneya4','moneya5','moneyb1','moneyb2','moneyb3','moneyb4','moneyb5','playera1','playera2','playera3','playera4','playera5','playerb1','playerb2','playerb3','playerb4','playerb5'])
for match in tqdm(match_list):
url='https://www.wanplus.com/match/%s.html#data'%match
try:
result_info=get_match_info(match,headers,url)
df=df.append(result_info,ignore_index=True)
except:
print('爬取失败,可以手动访问https://www.wanplus.com/match/%s.html#data补充'%match)
df.to_excel('./KPL1.xlsx',index=False)
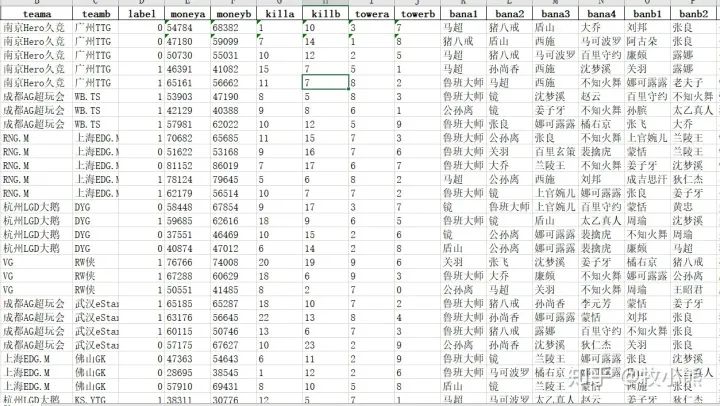
第二部分爬取比赛的结果,推塔数,金币数,所选英雄等比赛相关信息。
def get_match_info(match,headers,url):
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'lxml')
win=0
#获得AB队名称
teama=soup.find('span',class_='tl bssj_tt1').get_text()
teamb=soup.find('span',class_='tr bssj_tt3').get_text()
#判断谁赢了
if '胜' in teama:
win=1
else:
win=0
teama=teama.replace('胜','').strip()
teamb=teamb.replace('胜','').strip()
# #获得金钱数
summer=soup.find_all('div',class_='bssj_tt')
moneya=summer[0].find('span',class_='tl').get_text()
moneyb=summer[0].find('span',class_='tr').get_text()
# #获得击杀数
killa=summer[1].find('span',class_='tl').get_text()
killb=summer[1].find('span',class_='tr').get_text()
# #获得推塔数
towera=summer[2].find('span',class_='tl').get_text()
towerb=summer[2].find('span',class_='tr').get_text()
# #获得ban位英雄
ban=soup.find('div',class_='las_box').find_all('img')
try:
bana1=ban[0]['alt']
except:
bana1=''
try:
bana2=ban[1]['alt']
except:
bana2=''
try:
bana3=ban[2]['alt']
except:
bana3=''
try:
bana4=ban[3]['alt']
except:
bana4=''
try:
banb1=ban[4]['alt']
except:
banb1=''
try:
banb2=ban[5]['alt']
except:
banb2=''
try:
banb3=ban[6]['alt']
except:
banb3=''
try:
banb4=ban[7]['alt']
except:
banb4=''
# #获得英雄信息
hero=soup.find_all('div',class_='bans_tx fl')
heroa1=hero[0].find_all('a')[1].get_text()
heroa2=hero[2].find_all('a')[1].get_text()
heroa3=hero[4].find_all('a')[1].get_text()
heroa4=hero[6].find_all('a')[1].get_text()
heroa5=hero[8].find_all('a')[1].get_text()
herob1=hero[1].find_all('a')[1].get_text()
herob2=hero[3].find_all('a')[1].get_text()
herob3=hero[5].find_all('a')[1].get_text()
herob4=hero[7].find_all('a')[1].get_text()
herob5=hero[9].find_all('a')[1].get_text()
# #获得选手信息
playera1=hero[0].find_all('a')[0].get_text()
playera2=hero[2].find_all('a')[0].get_text()
playera3=hero[4].find_all('a')[0].get_text()
playera4=hero[6].find_all('a')[0].get_text()
playera5=hero[8].find_all('a')[0].get_text()
playerb1=hero[1].find_all('a')[0].get_text()
playerb2=hero[3].find_all('a')[0].get_text()
playerb3=hero[5].find_all('a')[0].get_text()
playerb4=hero[7].find_all('a')[0].get_text()
playerb5=hero[9].find_all('a')[0].get_text()
# #获得英雄kda
info=soup.find_all('div',class_='bans_m')
kdaa1=info[0].find('span',class_='tr').get_text()
kdaa2=info[1].find('span',class_='tr').get_text()
kdaa3=info[2].find('span',class_='tr').get_text()
kdaa4=info[3].find('span',class_='tr').get_text()
kdaa5=info[4].find('span',class_='tr').get_text()
kdab1=info[0].find('span',class_='tl').get_text()
kdab2=info[1].find('span',class_='tl').get_text()
kdab3=info[2].find('span',class_='tl').get_text()
kdab4=info[3].find('span',class_='tl').get_text()
kdab5=info[4].find('span',class_='tl').get_text()
# #获得英雄金钱
moneya1=info[0].find_all('span',class_='tr')[1].get_text()
moneya2=info[1].find_all('span',class_='tr')[1].get_text()
moneya3=info[2].find_all('span',class_='tr')[1].get_text()
moneya4=info[3].find_all('span',class_='tr')[1].get_text()
moneya5=info[4].find_all('span',class_='tr')[1].get_text()
moneyb1=info[0].find_all('span',class_='tl')[1].get_text()
moneyb2=info[1].find_all('span',class_='tl')[1].get_text()
moneyb3=info[2].find_all('span',class_='tl')[1].get_text()
moneyb4=info[3].find_all('span',class_='tl')[1].get_text()
moneyb5=info[4].find_all('span',class_='tl')[1].get_text()
temp={'match':match,'teama':teama,'teamb':teamb,'label':win,'moneya':moneya,'moneyb':moneyb,'killa':killa,'killb':killb,'towera':towera,'towerb':towerb,'bana1':bana1,'bana2':bana2,'bana3':bana3,'bana4':bana4,'banb1':banb1,'banb2':banb2,'banb3':banb3,'banb4':banb4,'heroa1':heroa1,'heroa2':heroa2,'heroa3':heroa3,'heroa4':heroa4,'heroa5':heroa5,'herob1':herob1,'herob2':herob2,'herob3':herob3,'herob4':herob4,'herob5':herob5,'kdaa1':kdaa1,'kdaa2':kdaa2,'kdaa3':kdaa3,'kdaa4':kdaa4,'kdaa5':kdaa5,'kdab1':kdab1,'kdab2':kdab2,'kdab3':kdab3,'kdab4':kdab4,'kdab5':kdab5,'moneya1':moneya1,'moneya2':moneya2,'moneya3':moneya3,'moneya4':moneya4,'moneya5':moneya5,'moneyb1':moneyb1,'moneyb2':moneyb2,'moneyb3':moneyb3,'moneyb4':moneyb4,'moneyb5':moneyb5,'playera1':playera1,'playera2':playera2,'playera3':playera3,'playera4':playera4,'playera5':playera5,'playerb1':playerb1,'playerb2':playerb2,'playerb3':playerb3,'playerb4':playerb4,'playerb5':playerb5}
return temp
最后我们将520场比赛的结果存在xlsx中。
2. 数据预处理
因为在爬取比赛过程中我们发现有比赛出现ban位放弃的情况,因此这里用-1对空值填充
import pandas as pd
pd.set_option('display.max_columns', None)
data=pd.read_excel('./KPL.xlsx')
data=data.fillna(-1) #填补空白数据
将队伍名词、英雄名称、选手姓名进行编号。
2.1 队伍名编码成数字
#将队伍名转成数字
Teamall=set(list(data['teama'])+list(data['teamb']))
TeamDictF={}
TeamDictS={}
count=0
for i in Teamall:
TeamDictF[i]=count
TeamDictS[count]=i
count+=1
TeamDictF

2.2 英雄编码成数字
Heroall=set()
for i in range(1,5):
for j in ['a','b']:
Heroall=set.union(Heroall, set(list(data['ban%s%s'%(j,i)])))
for i in range(1,6):
for j in ['a','b']:
Heroall=set.union(Heroall, set(list(data['hero%s%s'%(j,i)])))
HeroDictF={}
HeroDictS={}
count=0
for i in Heroall:
HeroDictF[i]=count
HeroDictS[count]=i
count+=1
2.3 选手名编码成数字
Playerall=set()
for i in range(1,6):
for j in ['a','b']:
Playerall=set.union(Playerall, set(list(data['player%s%s'%(j,i)])))
PlayerDictF={}
PlayerDictS={}
count=0
for i in Playerall:
PlayerDictF[i]=count
PlayerDictS[count]=i
count+=1
2.4进行编码替换
data['teama']=data['teama'].map(TeamDictF)
data['teamb']=data['teamb'].map(TeamDictF)
data['bana1']=data['bana1'].map(HeroDictF)
data['bana2']=data['bana2'].map(HeroDictF)
data['bana3']=data['bana3'].map(HeroDictF)
data['bana4']=data['bana4'].map(HeroDictF)
data['banb1']=data['banb1'].map(HeroDictF)
data['banb2']=data['banb2'].map(HeroDictF)
data['banb3']=data['banb3'].map(HeroDictF)
data['banb4']=data['banb4'].map(HeroDictF)
data['heroa1']=data['heroa1'].map(HeroDictF)
data['heroa2']=data['heroa2'].map(HeroDictF)
data['heroa3']=data['heroa3'].map(HeroDictF)
data['heroa4']=data['heroa4'].map(HeroDictF)
data['heroa5']=data['heroa5'].map(HeroDictF)
data['herob1']=data['herob1'].map(HeroDictF)
data['herob2']=data['herob2'].map(HeroDictF)
data['herob3']=data['herob3'].map(HeroDictF)
data['herob4']=data['herob4'].map(HeroDictF)
data['herob5']=data['herob5'].map(HeroDictF)
data['playera1']=data['playera1'].map(PlayerDictF)
data['playera2']=data['playera2'].map(PlayerDictF)
data['playera3']=data['playera3'].map(PlayerDictF)
data['playera4']=data['playera4'].map(PlayerDictF)
data['playera5']=data['playera5'].map(PlayerDictF)
data['playerb1']=data['playerb1'].map(PlayerDictF)
data['playerb2']=data['playerb2'].map(PlayerDictF)
data['playerb3']=data['playerb3'].map(PlayerDictF)
data['playerb4']=data['playerb4'].map(PlayerDictF)
data['playerb5']=data['playerb5'].map(PlayerDictF)
到这里我们的数据就预处理完成了。
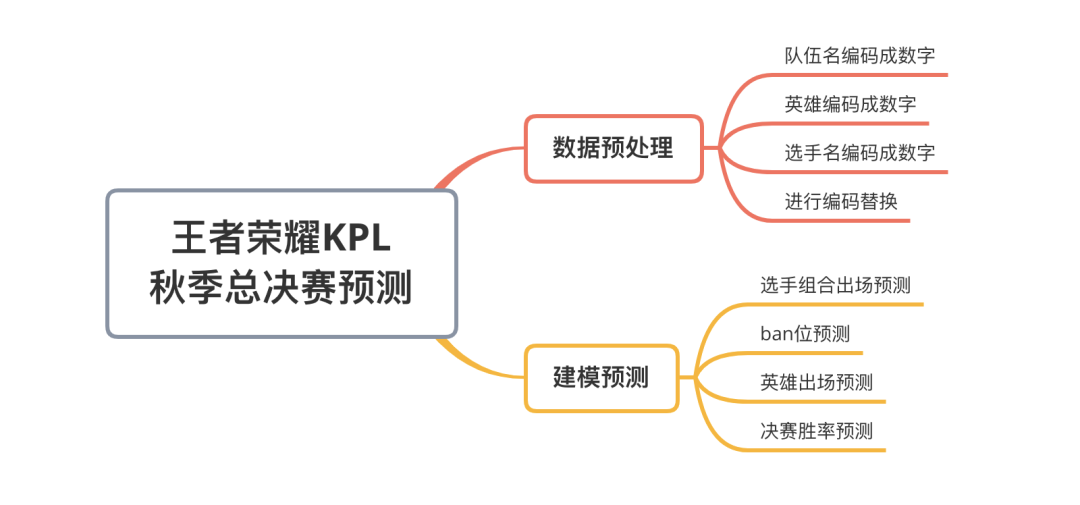
3. 建模预测
在本节中我们选择了2个常用的模型,分别是是朴素贝叶斯与决策树模型。
因为12.19号DYG战队和成都AG超玩会战队在重庆进行总决赛,用的非常简单的模型,因此不要过度解读结果。
3.1 选手组合出场预测
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
DYGa=data[(data['teama']==5)&(data['label']==1)][['playera1','playera2','playera3','playera4','playera5']]
DYGa.columns=['1号位','2号位','3号位','4号位','5号位']
DYGb=data[(data['teamb']==5)&(data['label']==0)][['playerb1','playerb2','playerb3','playerb4','playerb5']]
DYGb.columns=['1号位','2号位','3号位','4号位','5号位']
DYGwin=pd.concat([DYGa,DYGb])
DYGwin['label']=1
DYGa=data[(data['teama']==5)&(data['label']==0)][['playera1','playera2','playera3','playera4','playera5']]
DYGa.columns=['1号位','2号位','3号位','4号位','5号位']
DYGb=data[(data['teamb']==5)&(data['label']==1)][['playerb1','playerb2','playerb3','playerb4','playerb5']]
DYGb.columns=['1号位','2号位','3号位','4号位','5号位']
DYGfail=pd.concat([DYGa,DYGb])
DYGfail['label']=0
DYG=pd.concat([DYGwin,DYGfail])
y=DYG['label']
x=DYG.drop(['label'],axis=1)
UniqueDYG=x.copy().drop_duplicates(subset=x.columns, keep='first')
mnb = DecisionTreeClassifier()
mnb.fit(x,y)
y_pre=mnb.predict_proba(UniqueDYG)[:,1]
UniqueDYG['y_pre']=y_pre
UniqueDYG['1号位']=UniqueDYG['1号位'].map(PlayerDictS)
UniqueDYG['2号位']=UniqueDYG['2号位'].map(PlayerDictS)
UniqueDYG['3号位']=UniqueDYG['3号位'].map(PlayerDictS)
UniqueDYG['4号位']=UniqueDYG['4号位'].map(PlayerDictS)
UniqueDYG['5号位']=UniqueDYG['5号位'].map(PlayerDictS)
UniqueDYG['组合']=UniqueDYG['1号位']+'--'+UniqueDYG['2号位']+'--'+UniqueDYG['3号位']+'--'+UniqueDYG['4号位']+'--'+UniqueDYG['5号位']
UniqueDYG=UniqueDYG.sort_values(by='y_pre',ascending=False)
UniqueDYG=UniqueDYG.reset_index()
UniqueDYG=UniqueDYG.drop(['index'],axis=1)
UniqueDYG
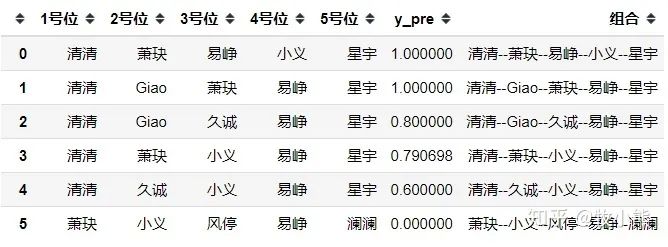
通过模型来看DYG首战出场的选手 清清-萧玦-易峥-小义-星宇出战的可能性最大,Giao做替补。
接下来我们看看AG超玩会:
#总决赛的队伍 DYG/AG超玩会
#我们看看AG超玩会的战绩
#六点六--笑影--汤汤--一诺--爱思 组合胜率最高
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
AGa=data[(data['teama']==0)&(data['label']==1)][['playera1','playera2','playera3','playera4','playera5']]
AGa.columns=['1号位','2号位','3号位','4号位','5号位']
AGb=data[(data['teamb']==0)&(data['label']==0)][['playerb1','playerb2','playerb3','playerb4','playerb5']]
AGb.columns=['1号位','2号位','3号位','4号位','5号位']
AGwin=pd.concat([AGa,AGb])
AGwin['label']=1
AGa=data[(data['teama']==0)&(data['label']==0)][['playera1','playera2','playera3','playera4','playera5']]
AGa.columns=['1号位','2号位','3号位','4号位','5号位']
AGb=data[(data['teamb']==0)&(data['label']==1)][['playerb1','playerb2','playerb3','playerb4','playerb5']]
AGb.columns=['1号位','2号位','3号位','4号位','5号位']
AGfail=pd.concat([AGa,AGb])
AGfail['label']=0
AG=pd.concat([AGwin,AGfail])
y=AG['label']
x=AG.drop(['label'],axis=1)
UniqueAG=x.copy().drop_duplicates(subset=x.columns, keep='first')
mnb = DecisionTreeClassifier()
mnb.fit(x,y)
y_pre=mnb.predict_proba(UniqueAG)[:,1]
UniqueAG['y_pre']=y_pre
UniqueAG['1号位']=UniqueAG['1号位'].map(PlayerDictS)
UniqueAG['2号位']=UniqueAG['2号位'].map(PlayerDictS)
UniqueAG['3号位']=UniqueAG['3号位'].map(PlayerDictS)
UniqueAG['4号位']=UniqueAG['4号位'].map(PlayerDictS)
UniqueAG['5号位']=UniqueAG['5号位'].map(PlayerDictS)
UniqueAG['组合']=UniqueAG['1号位']+'--'+UniqueAG['2号位']+'--'+UniqueAG['3号位']+'--'+UniqueAG['4号位']+'--'+UniqueAG['5号位']
UniqueAG=UniqueAG.sort_values(by='y_pre',ascending=False)
UniqueAG=UniqueAG.reset_index()
UniqueAG=UniqueAG.drop(['index'],axis=1)
UniqueAG
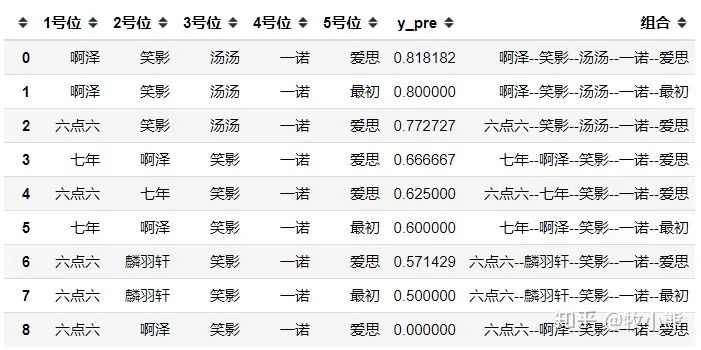
通过模型来看AG超玩会首战出场的选手 阿泽-笑影-汤汤-一诺-爱思出战的可能性最大,其它位置都有1-2个替补,唯独4号位,铁打的一诺。
3.2 ban位预测
DYGa=data[(data['teama']==numa)&(data['label']==1)][['bana1','bana2','bana3','bana4']]
DYGa.columns=['1','2','3','4']
DYGb=data[(data['teamb']==numa)&(data['label']==0)][['bana1','bana2','bana3','bana4']]
DYGb.columns=['1','2','3','4']
DYGwin=pd.concat([DYGa,DYGb])
DYGwin['label']=1
DYGa=data[(data['teama']==numa)&(data['label']==0)][['bana1','bana2','bana3','bana4']]
DYGa.columns=['1','2','3','4']
DYGb=data[(data['teamb']==numa)&(data['label']==1)][['bana1','bana2','bana3','bana4']]
DYGb.columns=['1','2','3','4']
DYGfail=pd.concat([DYGa,DYGb])
DYGfail['label']=0
DYG=pd.concat([DYGwin,DYGfail])
y=DYG['label']
x=DYG.drop(['label'],axis=1)
UniqueDYG=x.copy().drop_duplicates(subset=x.columns, keep='first')
mnb = MultinomialNB()
mnb.fit(x,y)
y_pre=mnb.predict_proba(UniqueDYG)[:,1]
UniqueDYG['y_pre']=y_pre
UniqueDYG['1']=UniqueDYG['1'].map(HeroDictS)
UniqueDYG['2']=UniqueDYG['2'].map(HeroDictS)
UniqueDYG['3']=UniqueDYG['3'].map(HeroDictS)
UniqueDYG['4']=UniqueDYG['4'].map(HeroDictS)
UniqueDYG=UniqueDYG.sort_values(by='y_pre',ascending=False)
UniqueDYG=UniqueDYG.reset_index()
UniqueDYG=UniqueDYG.drop(['index'],axis=1)
UniqueDYG
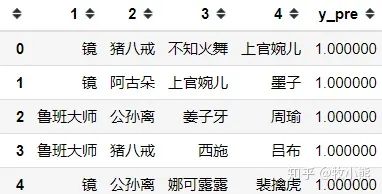
通过结果可以看到DYG第一ban位大概率要ban鲁班大师或者镜,第二ban位大概率要针对一诺的公孙离或者猪八戒。
接下来对AG的ban位进行预测:
pd.set_option('display.float_format', lambda x: '%.6f' % x)
AGa=data[(data['teama']==numb)&(data['label']==1)][['bana1','bana2','bana3','bana4']]
AGa.columns=['1','2','3','4']
AGb=data[(data['teamb']==numb)&(data['label']==0)][['bana1','bana2','bana3','bana4']]
AGb.columns=['1','2','3','4']
AGwin=pd.concat([AGa,AGb])
AGwin['label']=1
AGa=data[(data['teama']==numb)&(data['label']==0)][['bana1','bana2','bana3','bana4']]
AGa.columns=['1','2','3','4']
AGb=data[(data['teamb']==numb)&(data['label']==1)][['bana1','bana2','bana3','bana4']]
AGb.columns=['1','2','3','4']
AGfail=pd.concat([AGa,AGb])
AGfail['label']=0
AG=pd.concat([AGwin,AGfail])
AGwin
y=AG['label']
x=AG.drop(['label'],axis=1)
UniqueAG=x.copy().drop_duplicates(subset=x.columns, keep='first')
mnb = MultinomialNB()
mnb.fit(x,y)
y_pre=mnb.predict_proba(UniqueAG)[:,1]
UniqueAG['y_pre']=y_pre
UniqueAG['1']=UniqueAG['1'].map(HeroDictS)
UniqueAG['2']=UniqueAG['2'].map(HeroDictS)
UniqueAG['3']=UniqueAG['3'].map(HeroDictS)
UniqueAG['4']=UniqueAG['4'].map(HeroDictS)
UniqueAG=UniqueAG.sort_values(by='y_pre',ascending=False)
UniqueAG=UniqueAG.reset_index()
UniqueAG=UniqueAG.drop(['index'],axis=1)
UniqueAG
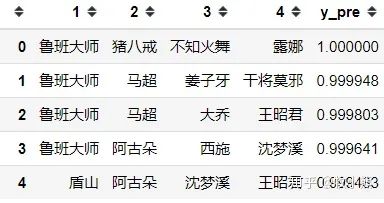
通过模型来看,AG第一ban位禁鲁班大师的概率极高,第二ban位禁用猪八戒、马超、阿古多的可能性大。
3.3 英雄出场预测
DYGa=data[(data['teama']==14)&(data['label']==1)][['heroa1','heroa2','heroa3','heroa4','heroa5']]
DYGa.columns=['1号位','2号位','3号位','4号位','5号位']
DYGb=data[(data['teamb']==14)&(data['label']==0)][['herob1','herob2','herob3','herob4','herob5']]
DYGb.columns=['1号位','2号位','3号位','4号位','5号位']
DYGwin=pd.concat([DYGa,DYGb])
DYGwin['label']=1
DYGa=data[(data['teama']==14)&(data['label']==0)][['heroa1','heroa2','heroa3','heroa4','heroa5']]
DYGa.columns=['1号位','2号位','3号位','4号位','5号位']
DYGb=data[(data['teamb']==14)&(data['label']==1)][['herob1','herob2','herob3','herob4','herob5']]
DYGb.columns=['1号位','2号位','3号位','4号位','5号位']
DYGfail=pd.concat([DYGa,DYGb])
DYGfail['label']=0
DYG=pd.concat([DYGwin,DYGfail])
DYGwin
y=DYG['label']
x=DYG.drop(['label'],axis=1)
UniqueDYG=x.copy().drop_duplicates(subset=x.columns, keep='first')
mnb = MultinomialNB()
mnb.fit(x,y)
y_pre=mnb.predict_proba(UniqueDYG)[:,1]
UniqueDYG['y_pre']=y_pre
UniqueDYG['1号位']=UniqueDYG['1号位'].map(HeroDictS)
UniqueDYG['2号位']=UniqueDYG['2号位'].map(HeroDictS)
UniqueDYG['3号位']=UniqueDYG['3号位'].map(HeroDictS)
UniqueDYG['4号位']=UniqueDYG['4号位'].map(HeroDictS)
UniqueDYG['5号位']=UniqueDYG['5号位'].map(HeroDictS)
UniqueDYG
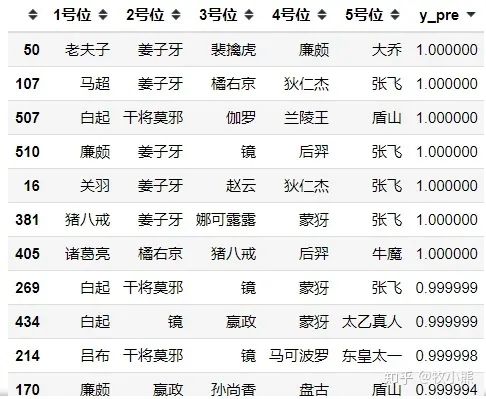
通过结果可以看到,总决赛中DYG用到老夫子大乔组合的概率非常之高,2号位用到姜子牙的概率非常高。
AGa=data[(data['teama']==3)&(data['label']==1)][['heroa1','heroa2','heroa3','heroa4','heroa5']]
AGa.columns=['1号位','2号位','3号位','4号位','5号位']
AGb=data[(data['teamb']==3)&(data['label']==0)][['herob1','herob2','herob3','herob4','herob5']]
AGb.columns=['1号位','2号位','3号位','4号位','5号位']
AGwin=pd.concat([AGa,AGb])
AGwin['label']=1
AGa=data[(data['teama']==3)&(data['label']==0)][['heroa1','heroa2','heroa3','heroa4','heroa5']]
AGa.columns=['1号位','2号位','3号位','4号位','5号位']
AGb=data[(data['teamb']==3)&(data['label']==1)][['herob1','herob2','herob3','herob4','herob5']]
AGb.columns=['1号位','2号位','3号位','4号位','5号位']
AGfail=pd.concat([AGa,AGb])
AGfail['label']=0
AG=pd.concat([AGwin,AGfail])
AGwin
y=AG['label']
x=AG.drop(['label'],axis=1)
UniqueAG=x.copy().drop_duplicates(subset=x.columns, keep='first')
mnb = MultinomialNB()
mnb.fit(x,y)
y_pre=mnb.predict_proba(UniqueAG)[:,1]
UniqueAG['y_pre']=y_pre
UniqueAG['1号位']=UniqueAG['1号位'].map(HeroDictS)
UniqueAG['2号位']=UniqueAG['2号位'].map(HeroDictS)
UniqueAG['3号位']=UniqueAG['3号位'].map(HeroDictS)
UniqueAG['4号位']=UniqueAG['4号位'].map(HeroDictS)
UniqueAG['5号位']=UniqueAG['5号位'].map(HeroDictS)
UniqueAG
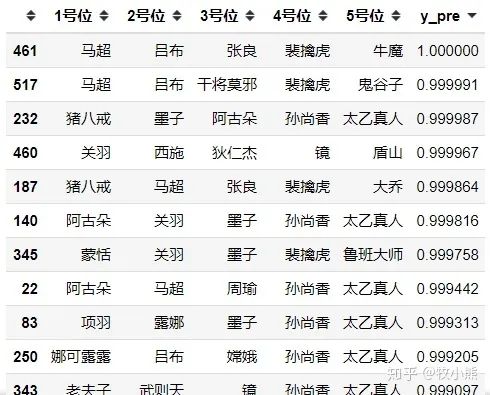
通过模型可以看到,AG超玩会中路偏向用工具人概率非常大,通过工具人来辅助射手输出。
3.4 决赛胜率预测
通常游戏的胜利和很多因素有关联,因此在胜率预测时,尽可能用简化的模型来进行预测。
因为是BO7 我们预测4种情况:
连续赢4场
赢4场 输1场
赢4场 输2场
赢4场 输3场
最后计算2个战队拿到冠军的概率。
from scipy.special import comb
def pre(score):
win=score
fail=1-score
score1=score**4
score2=comb(4,1)*(win**3)*(fail)*win
score3=comb(5,2)*(win**3)*(fail**2)*win
score4=comb(6,3)*(win**3)*(fail**3)*win
return score1+score2+score3+score4
allteam=pd.read_excel('全部战队-20200917-20201216.xlsx')
DYGwin=allteam.iloc[0,2]
AGwin=allteam.iloc[1,2]
DYG=DYGwin/(DYGwin+AGwin)
AG=AGwin/(DYGwin+AGwin)
print('AG胜利概率为%s'%pre(AG))
print('DYG胜利概率为%s'%pre(DYG))
AG胜利概率为0.46268343014154045
DYG胜利概率为0.5373165698584595
通过概率来看,DYG以非常小的优势获胜概率较大。
4. 小结
在这个项目中,我们只采集到了520场比赛数据,为什么不采集以前比赛的数据呢?
有几个方面的考虑:
1.以前的数据受到游戏平衡的影响,英雄强度和地图都会有所改变,因此对本来就不准确的预测模型增加一个更加不准确的因素。
2.项目的时间也比较紧,没有过多的时间去采集。
3.520这个数字不香嘛?点赞的小伙伴2021年必定脱单
采集的数据中还有其它好玩的信息可以挖掘,比如使用关联规则预测哪2个组合在一起概率最大,或者选手的赛季数据,由于篇幅的原因,剩余的数据探索部分就留给其它感兴趣的同学去继续探索了。
因为采集数据和使用的模型偏简单,因此预测的结果会受到多方面的影响,喜欢KPL的同学锁定12月19号的总决赛,如果比赛现场与预测情况相似,记得过来点赞...
项目数据及源代码
链接:https://pan.baidu.com/s/1roQb-Egl64-1opoCs_z0KA
提取码:foui