
pyspider爬取王者荣耀数据(下)
咪哥杂谈

本篇阅读时间约为 4 分钟。
1
前言
本篇来继续完成数据的爬取。离上周文章已经过了一星期了,忘记的可以回顾下:《pyspider爬取王者荣耀数据(上)》
上篇文章中写到的,无非就是头像图片的懒加载是个小困难点,其余部分,操作起来使用网页自带的 css 选择器很好选择。
2
pyspider爬取数据
1. 完善上周的代码
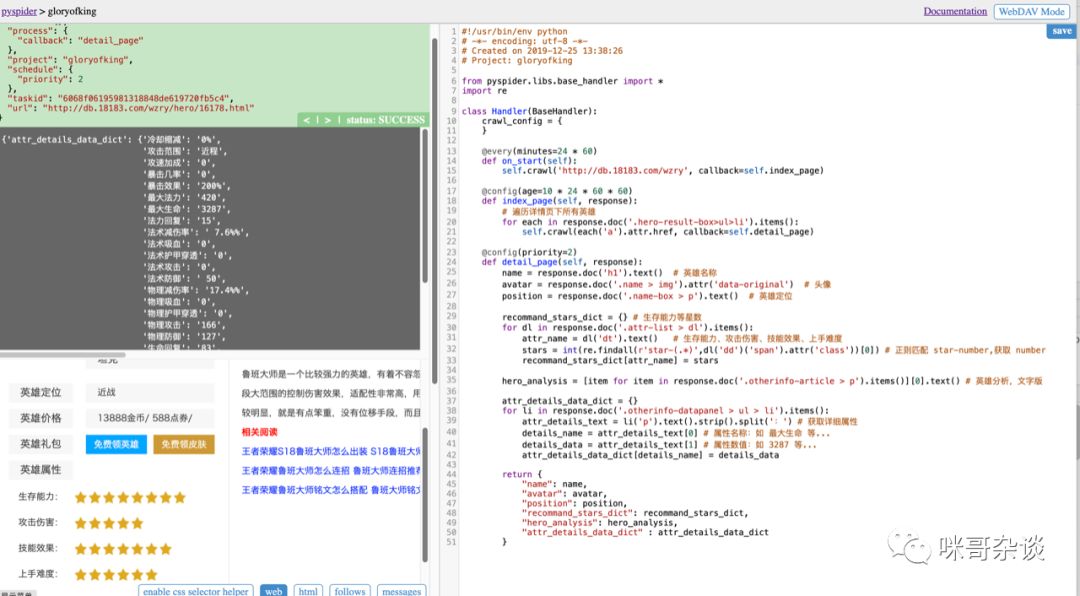
右侧是完善的代码,将具体的目标爬取了下来,并且可以看到左侧上方已经输出了响应的内容。
写完代码后,别忘了点击右上方的 save 按钮。(具体代码文末有获取方式)
2. pyspider启动爬取
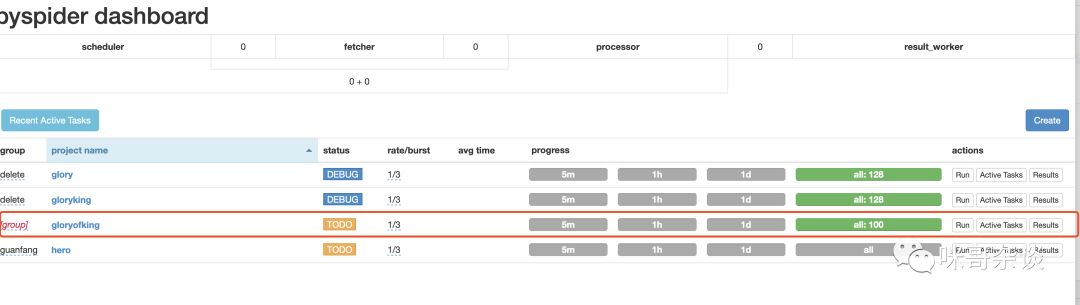
写好了代码后,如何去启动此爬虫呢?
首先回到配置任务的界面,画红线是我现在编写的任务:
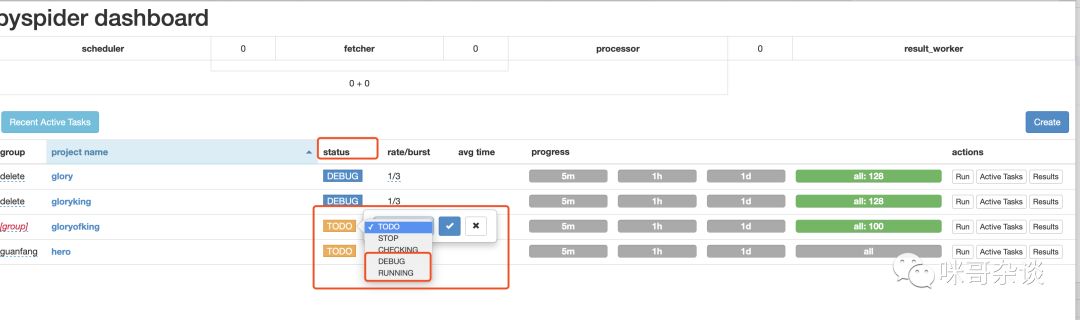
可以看到有个 status 栏,你需要将此状态换成 debug 或者 run 才行。
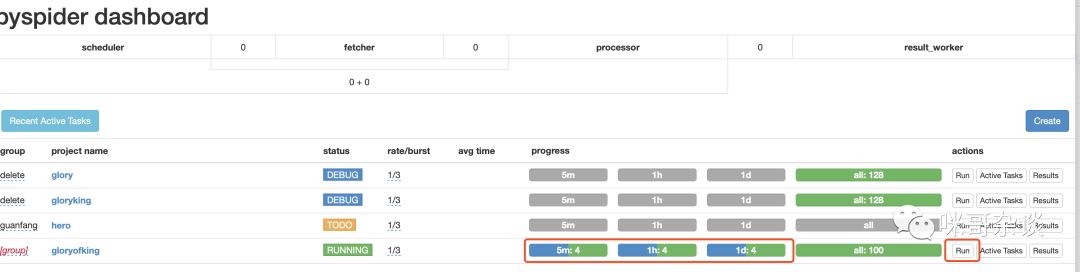
点击 run ,即可运行,同时progress的进度条也会变颜色:
3. 获取数据
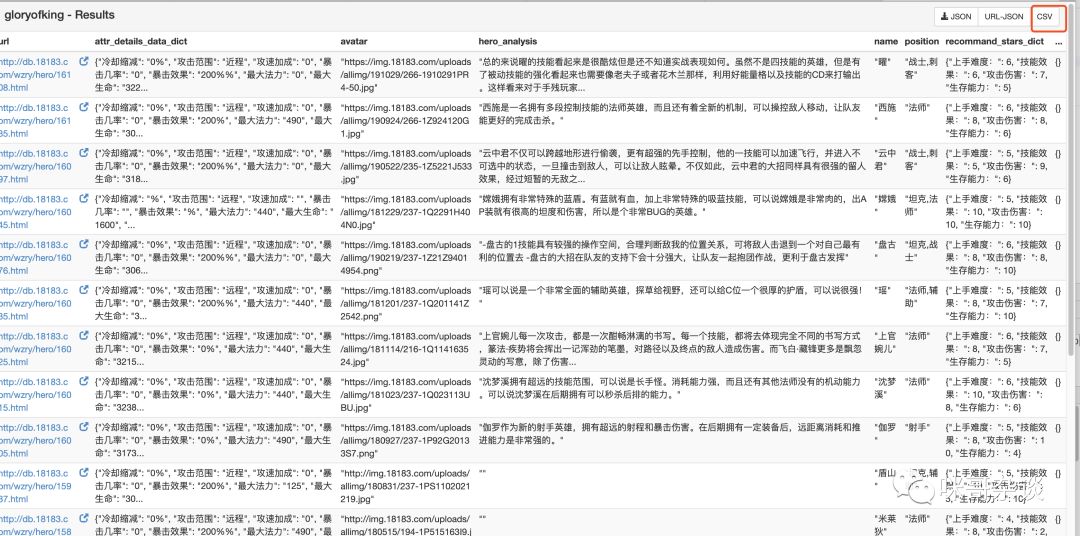
4. 关于数据落地于数据库中
此时的做法,引入相应的数据库即可,以 mysql 为例。下面提供一个编程的思路,无代码。
在 pyspider 提供的 Handler 类中,可以自行实现一个 __init__ 方法(学过面向对象的同学应该不陌生),在此方法中,对连接 mysql 数据库的操作进行初始化,生成一个实例对象变量 db。
这样一来,在 detail_page 函数中,我们便可以用 self.db 的方式来对 mysql 实例进行入库操作。
3
总结
在此次爬取中,图片的懒加载可以注意下,找到对应js即可。
对比一下用框架来爬取数据,和我们自己写代码的区别:
有想要看 pyspider 源码的同学,后台回复 pyspider 即可获得。
硬核!用Python为你的父母送上每日天气提醒!
 你点的每个在看,我都认真当成了喜欢
你点的每个在看,我都认真当成了喜欢评论