
pyspider爬取王者荣耀数据(上)
咪哥杂谈

本篇阅读时间约为 8 分钟。
1
前言
不知道还有多少人记得几个月前写的两篇文章,介绍关于 PyQuery 入门使用的教程。忘记的朋友,可以去回顾下用法:
爬虫神器之PyQuery实用教程(二),50行代码爬取穷游网
在之前的某一期文章下面,我记得有过一次留言,说是要安排一下王者荣耀的数据爬取,并且是使用 PySpider 爬虫框架。
那么,今天就带来一篇关于 pyspider 的入门教程。
题外话:
对于王者荣耀这种电竞类游戏来说,为什么有些人能轻松上王者?而有些人却一直停留在低段位?无非就是没有了解过规则,以及其背后的数据罢了。
一款游戏,对于数据和规则熟知于心,那么,上分是轻轻松松的事儿。
作为一个电竞游戏从初中开始玩的人来说,从 dota1 到 lol,再到后来的 dota2,最后到移动端的王者荣耀,每次都是将数据与规则了解后,才得心应手的去上分。
放上我的王者荣耀段位图,秀一波 :
:
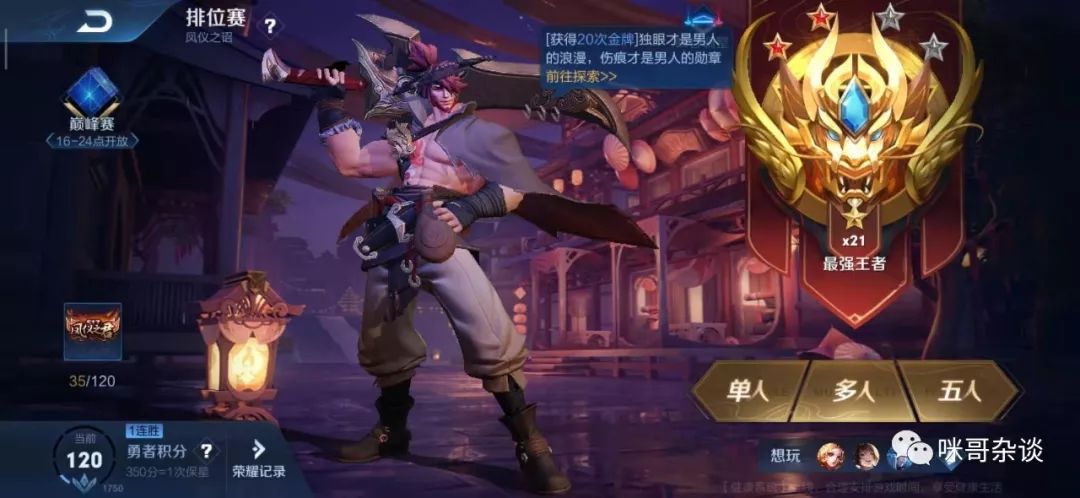
 ~可以一起排位。下面进入正题。
~可以一起排位。下面进入正题。今天这篇,爬取的网站数据包括技能,英雄属性数值,推荐装备等。
2
准备工作
1. 什么是 pyspider
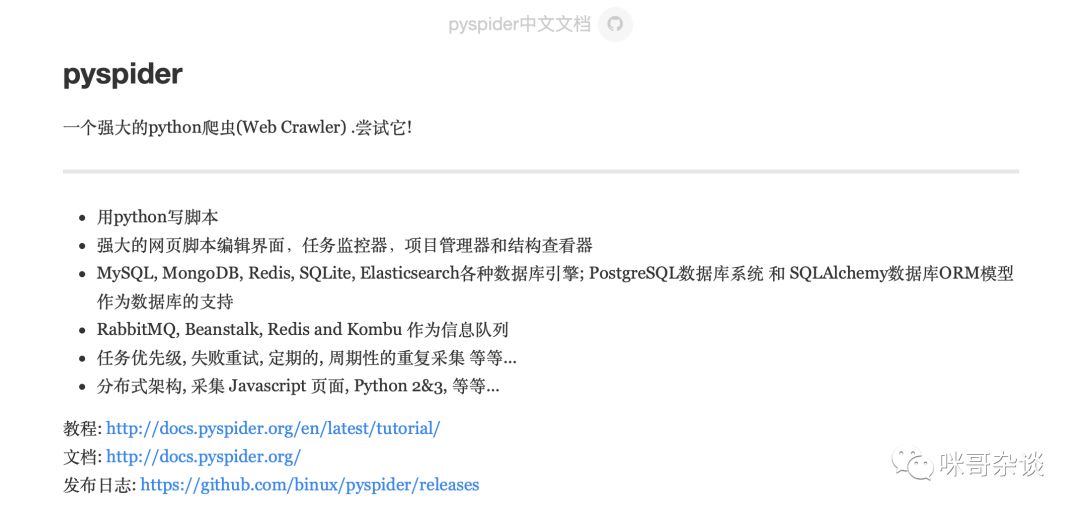
pyspider是一款优秀的框架,并配有 WebUI 的界面。
平时我们写爬虫时,只能是自己从零开始不断地搭建代码,但是有没有发现,当你写了很多爬虫的时候,有些逻辑无非就是在修改获取节点元素的规则,其它代码是不用做修改的。
这样一来,每次都要重复的去写一些相同的代码,不仅枯燥,且浪费时间。在这样的场景下,框架才会诞生出来。
只需要你对变化的东西进行“填充”即可,其余相同的地方,框架帮你做。
对于框架来说,学习成本也各不相同,比如知名的爬虫框架 scrapy ,相对于新手来说,可能难度就大一些。
而 pyspider 自带了一个页面,可以实时调试,对于初学者来说,上手容易,脚本编写规则也非常简单。
介绍就到此结束了。
3
确定爬取目标
先来看下王者荣耀第三方网站首页:
http://db.18183.com/wzry/
18183王者荣耀
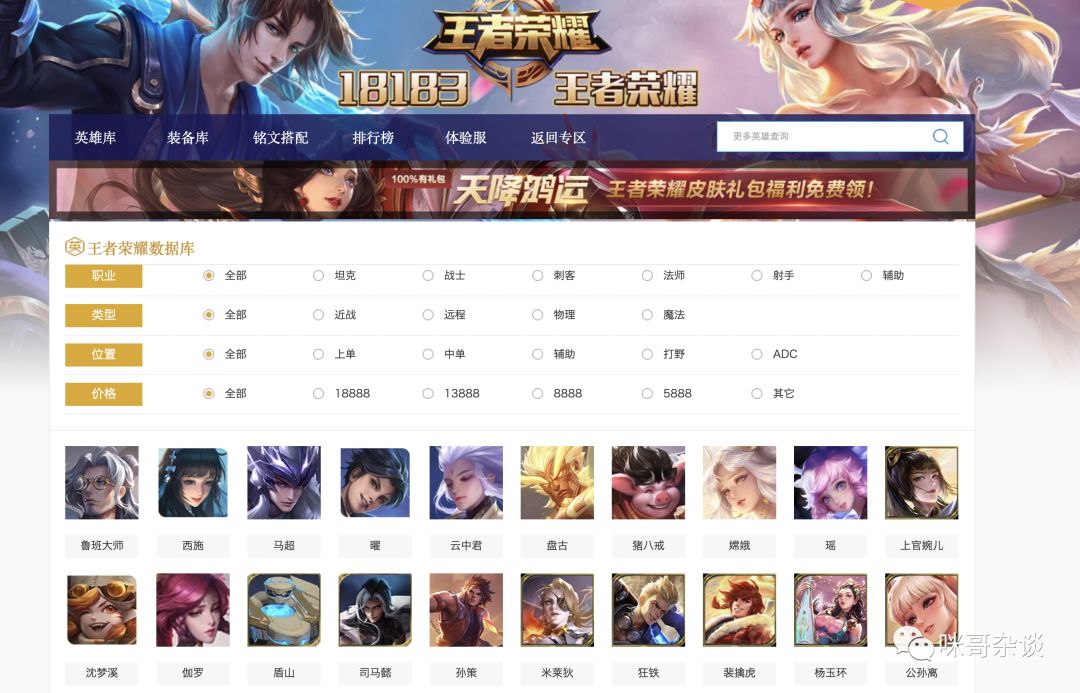
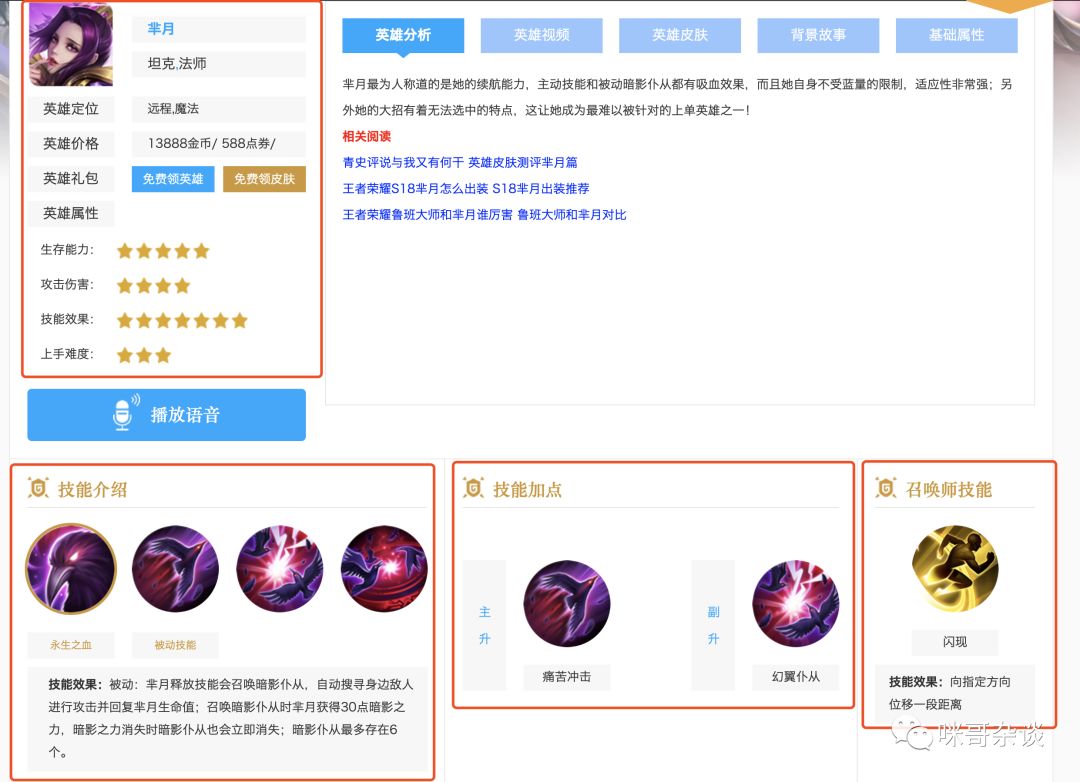
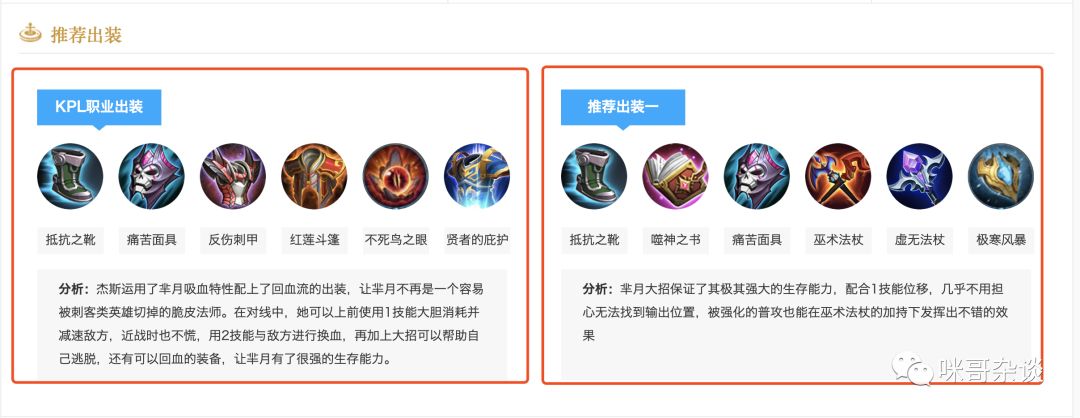
红框即爬取目标,整理一下,具体有:
- 每个英雄简介
- 技能介绍描述
- 推荐技能加点
- 英雄出装建议
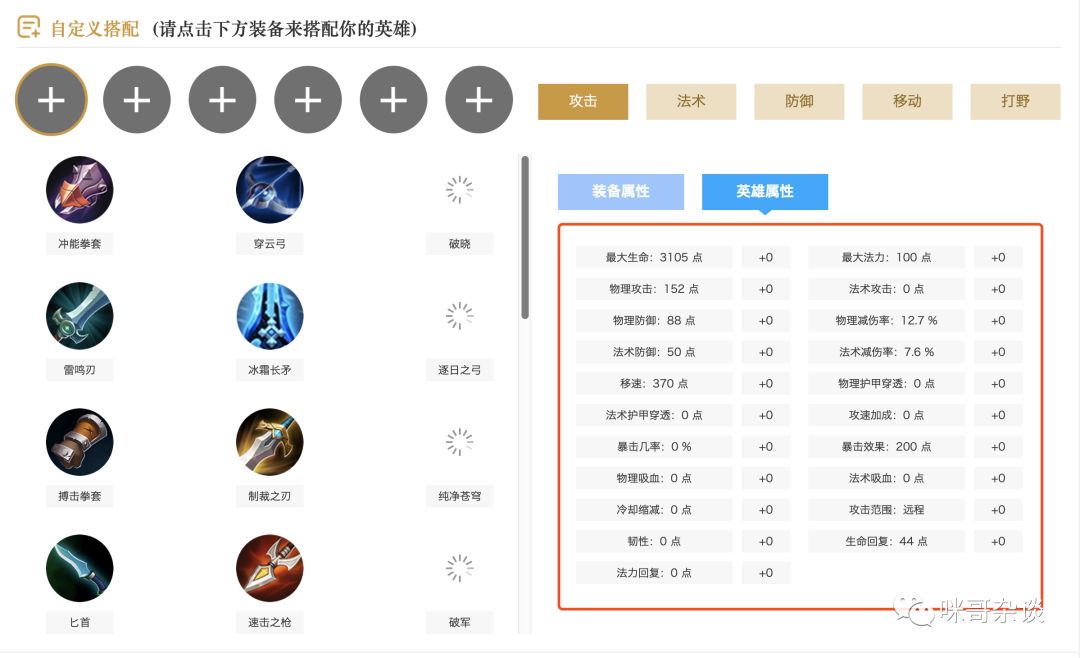
- 英雄属性数值
4
pyspider入门
1. 安装 pyspider 库
开始介绍入门之前,先来安装下它。
pip install pyspider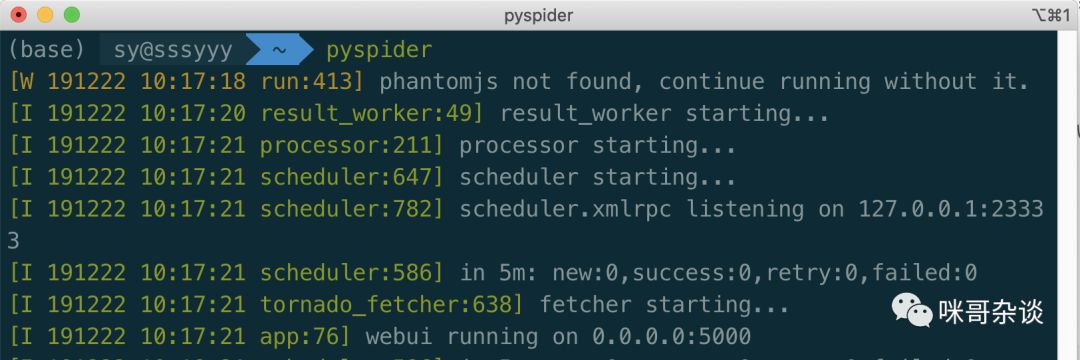
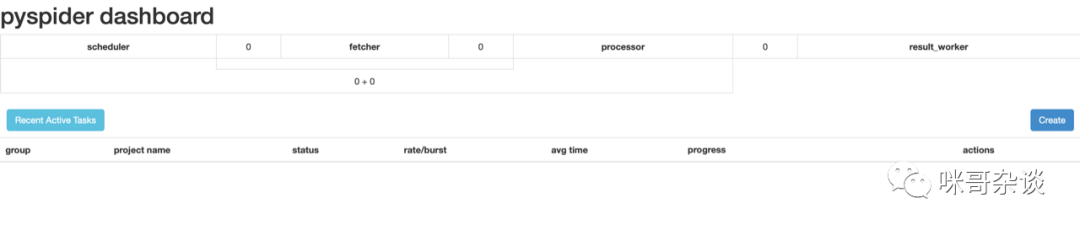
启动后,打开浏览器,输入 http://localhost:5000 ,可以看到下图:
3. 创建任务
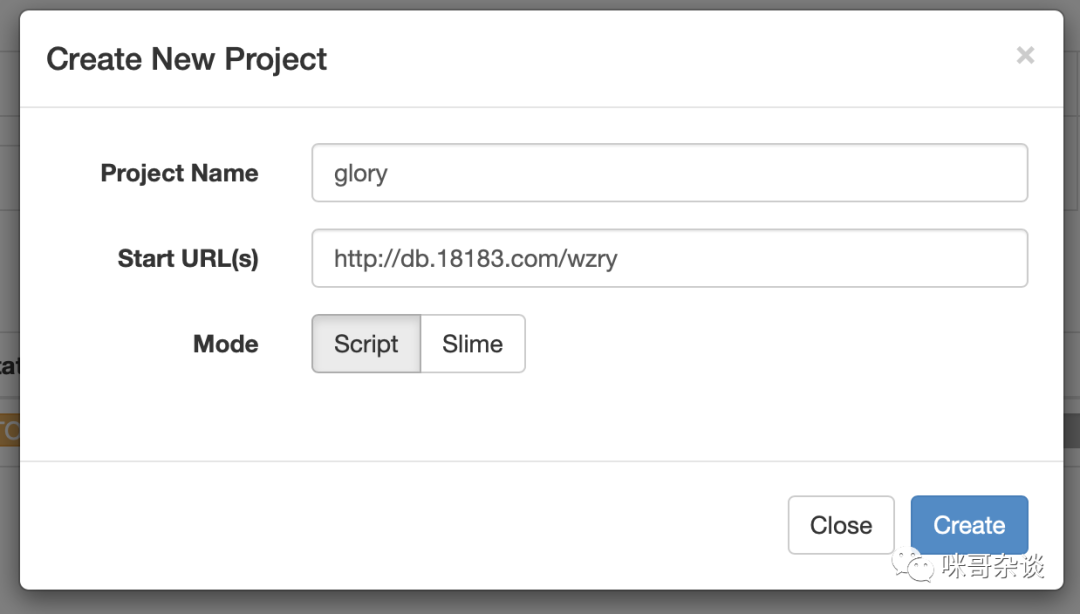
点击 create 按钮,创建新工程任务。name 随意写,start url 写我们要爬取的首页即可。
4. 自动生成代码
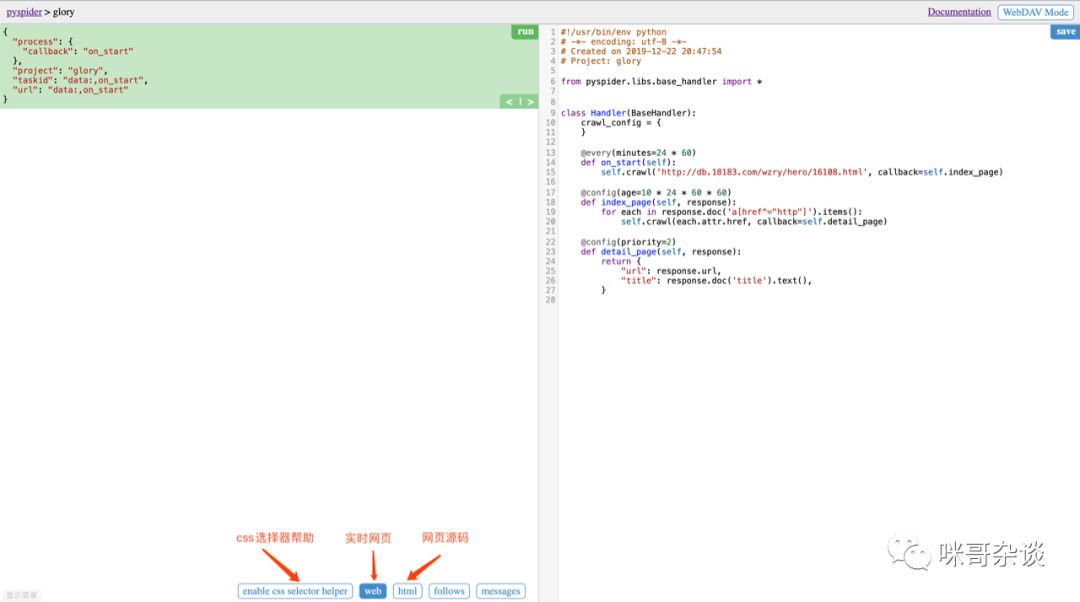
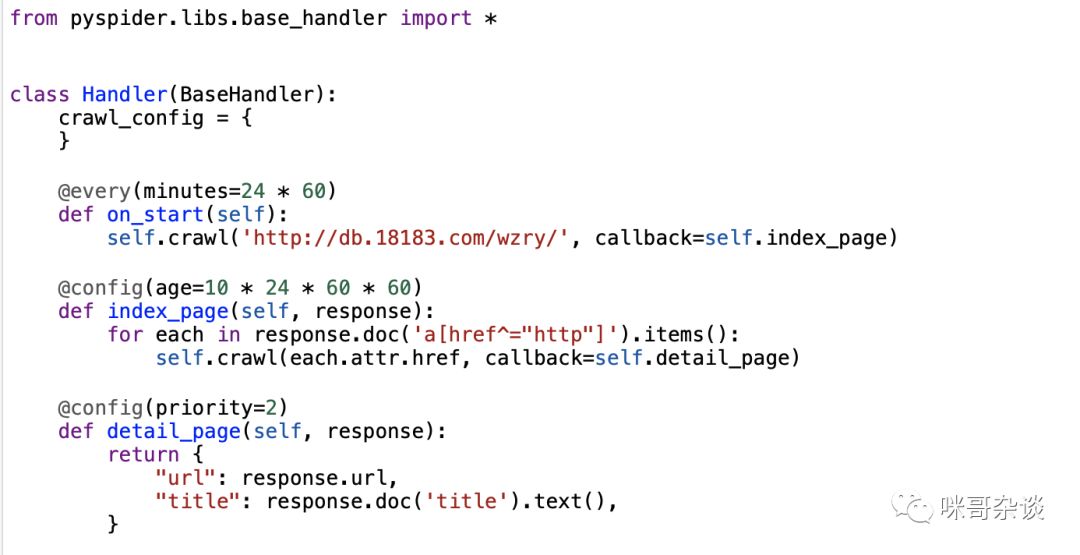
Handler类里有 3 个方法,分别是 on_start,index_page,detail_page 方法,每个方法上面有着自己的装饰器。
- on_start():启动后进入的第一个方法,主 url 在此处被请求,响应会传入 callback 后面的 index_page 函数中。
- index_page():主 url 返回的响应源码进入到此函数到 response 里,其中 reponse.doc 用到了 PyQuery 语法,用来匹配你想要的信息节点,继续传入到下一个详情页中。
- detail_page():处理最后的具体逻辑,当然你也可以继续类似上面的回调,主要看你要抓取的信息到底在多少层的页面中。
分析下王者荣耀的官网,我们需要的信息:
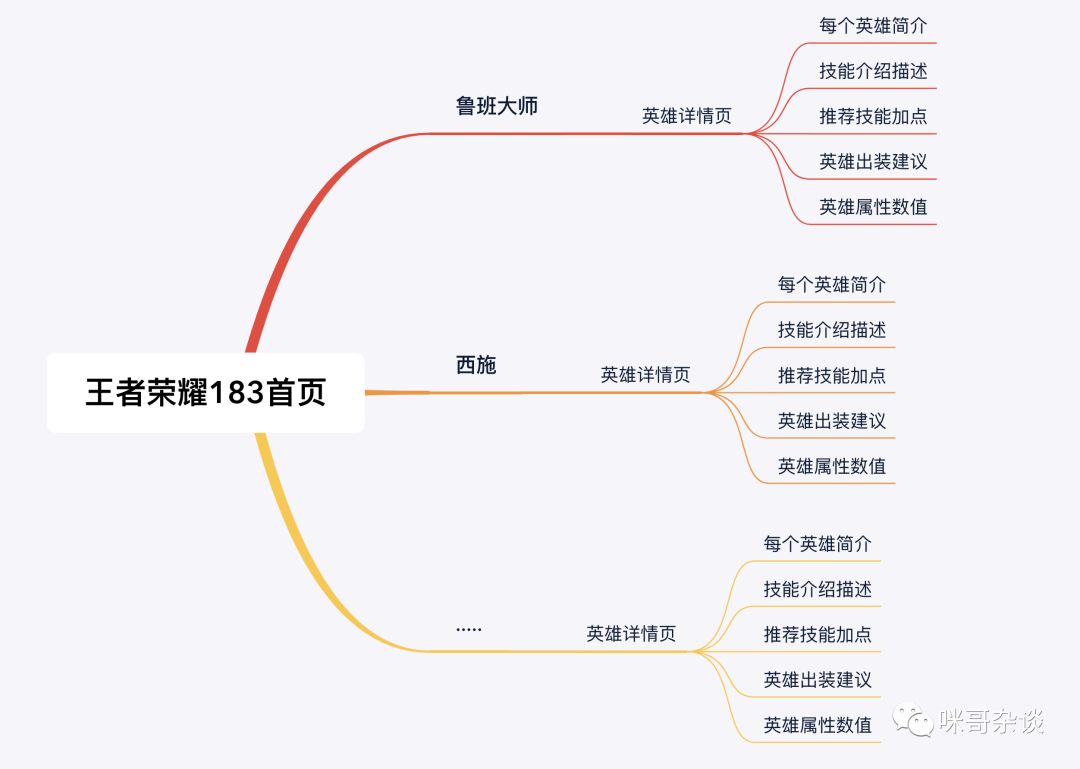
以下,首页到鲁班大师详情页为例:
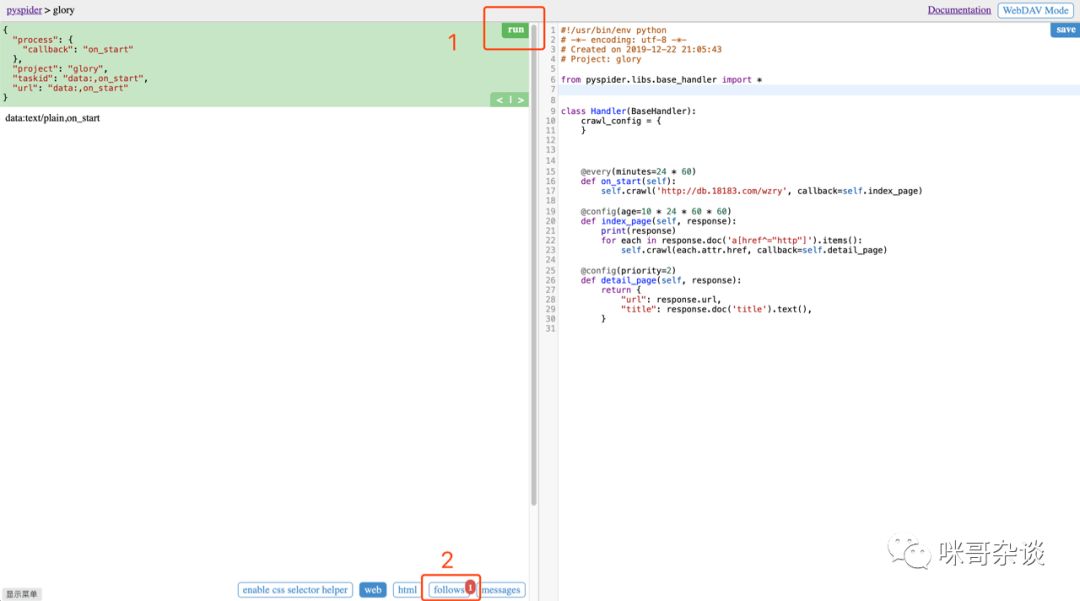
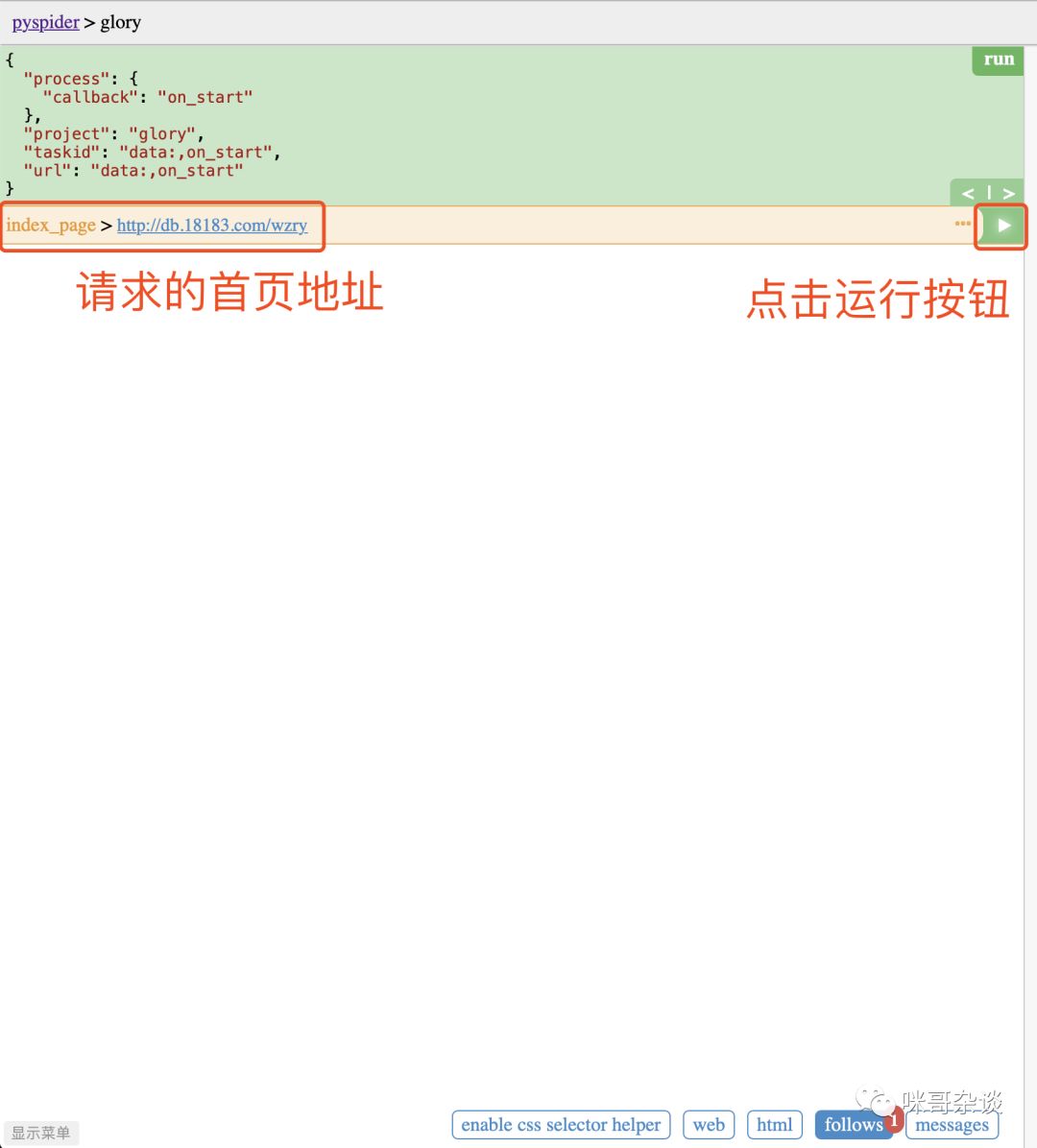
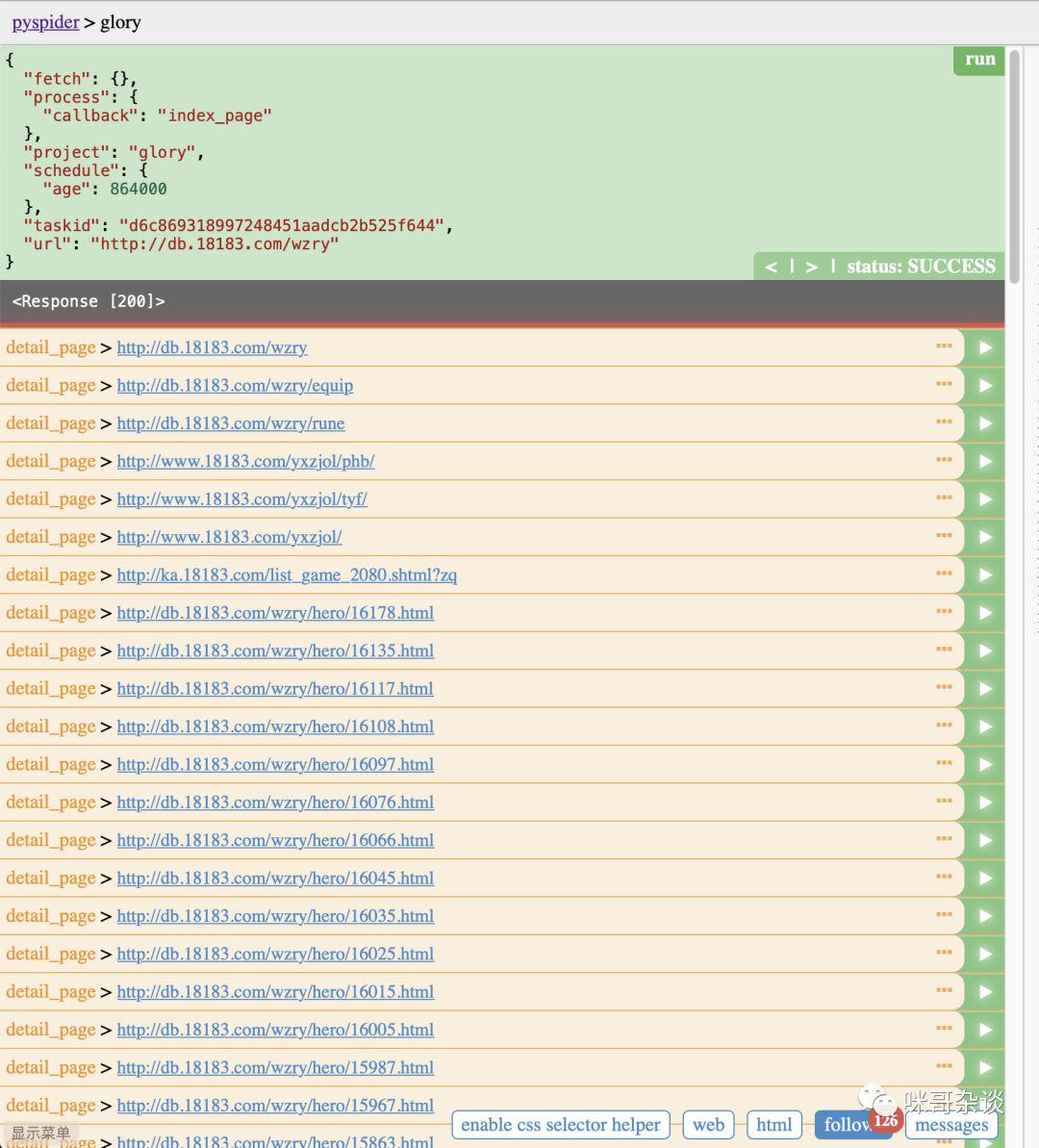
点击运行后的瞬间,可以看到 pyspider 自动为我们识别出了首页的 126 条超链接,但是我想要的仅仅是英雄列表中的每个英雄的 url 地址。
所以,接下来就要发挥 pyspider 的便捷之处了。
点击到 web ,即可实时看到首页:
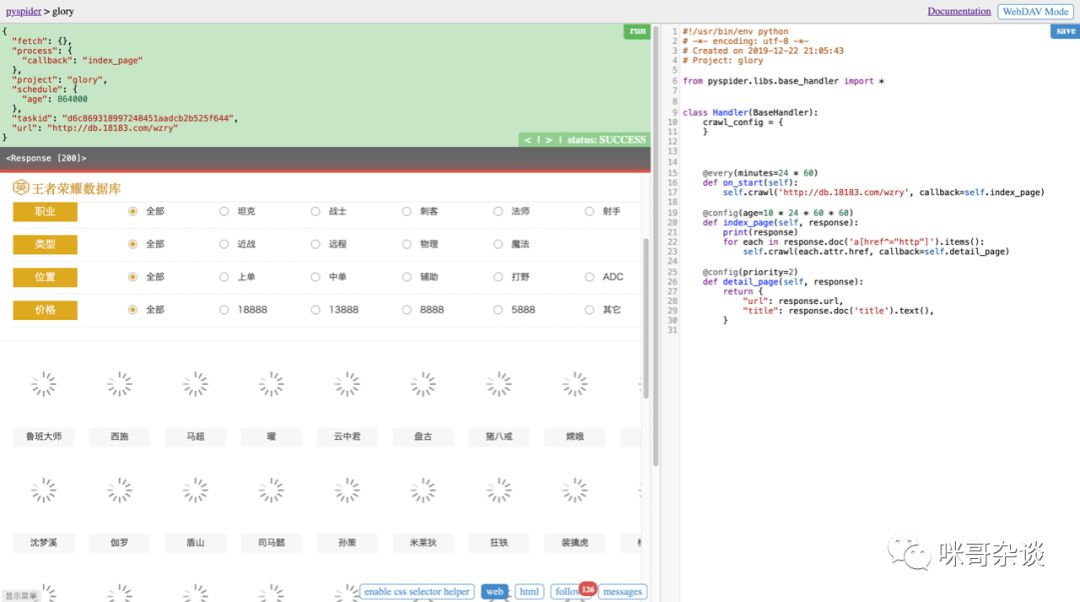
点击 css selector helper ,即 css 选择器帮助。
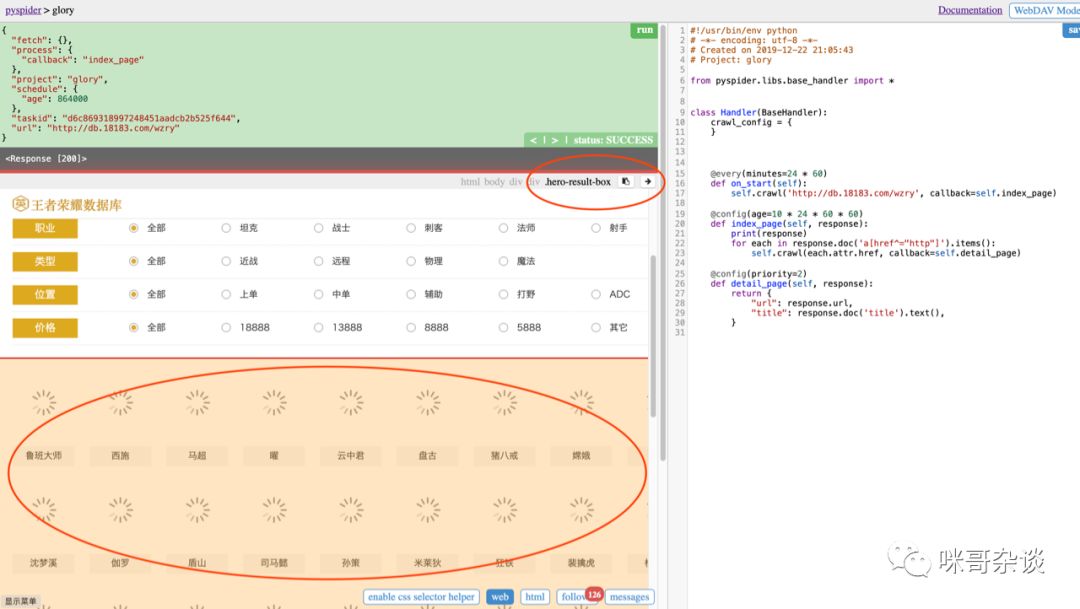
如果之前用过 webscrape 插件的同学(爬虫工具(二) webscraper 教程 (知乎案例)),一定很熟悉这个场景,手动选择你想要的节点,然后系统自动生成。
点击 css 样式的右箭头, 网页自动将 css 代码帮你替换到你光标放置的右侧代码位置:
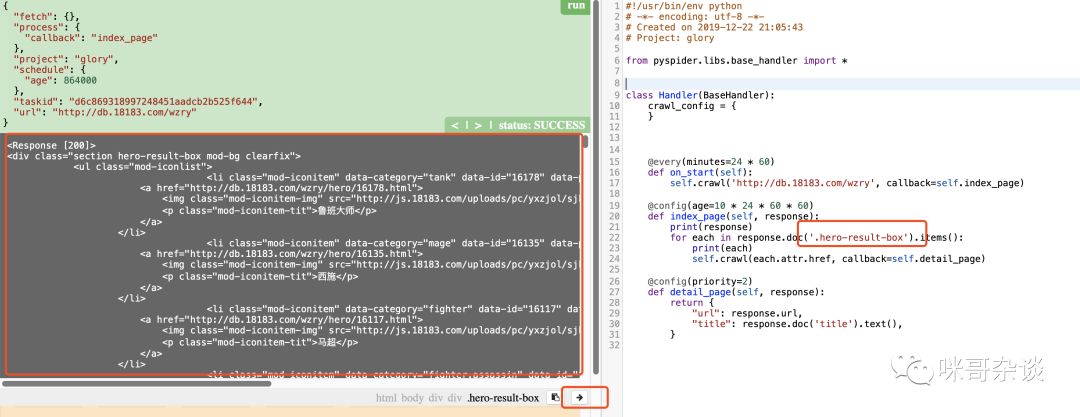
顺便,打印下 each ,看下结果。
打印发现,这并不是我们想要的 li 节点,所以继续进一步提取。
可以看到此行 div 里包含的 li 标签,而 li 标签中又包含了 a 标签。
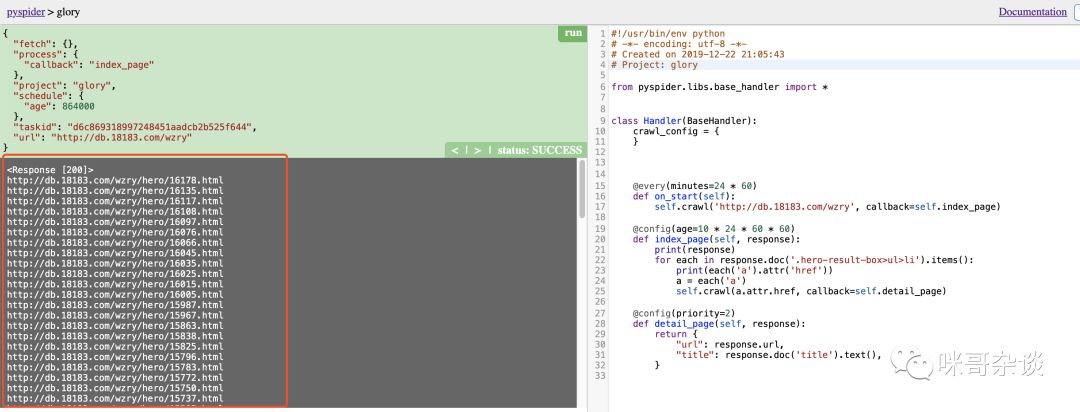
于是,提取如下:
def index_page(self, response): print(response) for each in response.doc('.hero-result-box>ul>li').items(): print(each('a').attr('href')) a = each('a') self.crawl(a.attr.href, callback=self.detail_page)
其实,熟悉 PyQuery 语法的朋友,一定很容易就写出来了,这里给新手朋友放个思维导图吧,也许你看了图就明白了,不过多文字解释了:

像不像一个沙漏!让我想起了营销学提到的漏斗模型,感兴趣的同学可以自行查下资料了解。
当然,以上过程,如果你不习惯用 pyspider 给你提供的,也可以用 Chrome 等浏览器自带的开发者工具自行调试。
关于详情页,这里只以抓取头像,姓名,定位来举例:
这里使用 css helper 去直接点我们想要的节点,然后移动 css 代码到右侧代码,很容易写出爬取节点:
def detail_page(self, response): name = response.doc('h1').text() img = response.doc('.name > img').attr('src') position = response.doc('.name-box > p').text() return { "url": response.url, "name": name, "img": img, "position": position }
结果:
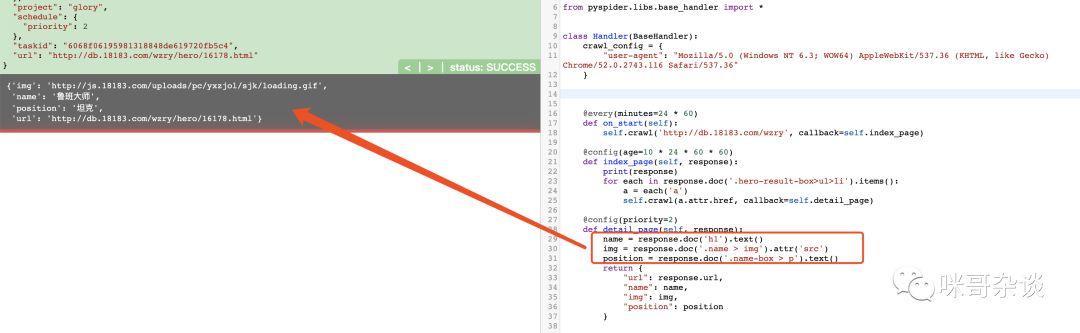
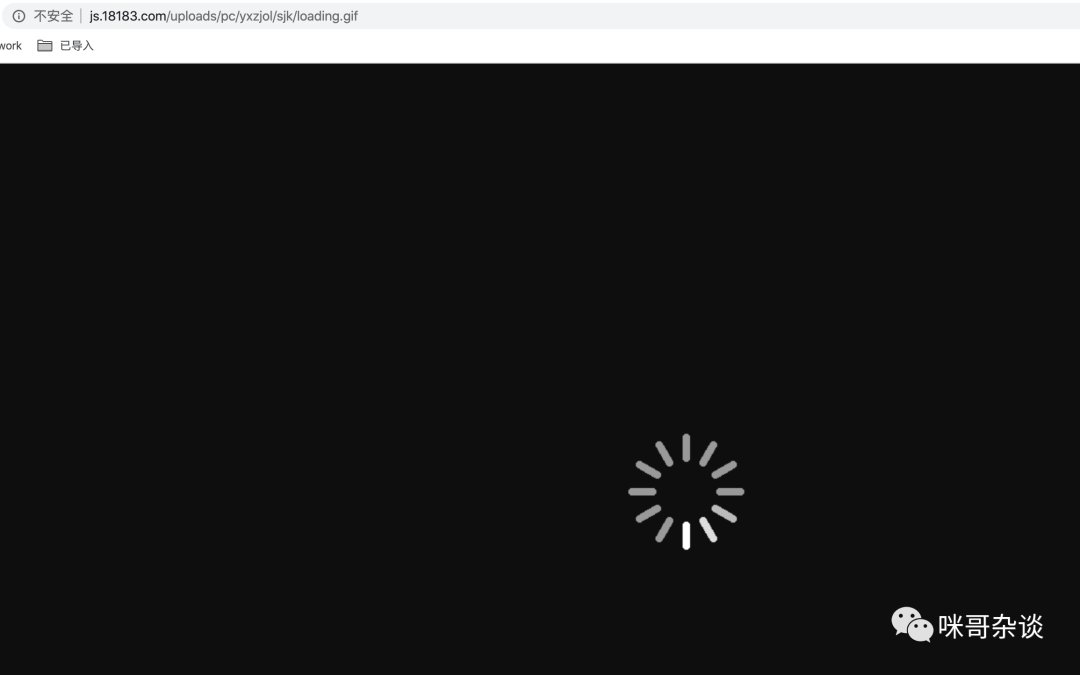
直到这里一切都顺利,但是让我疑惑的是头像的图片为什么是 gif 地址?访问下,一看这图片一直在转圈啊!
对于图片源地址来说,我们还是用自带的浏览器来调试,方便观察。
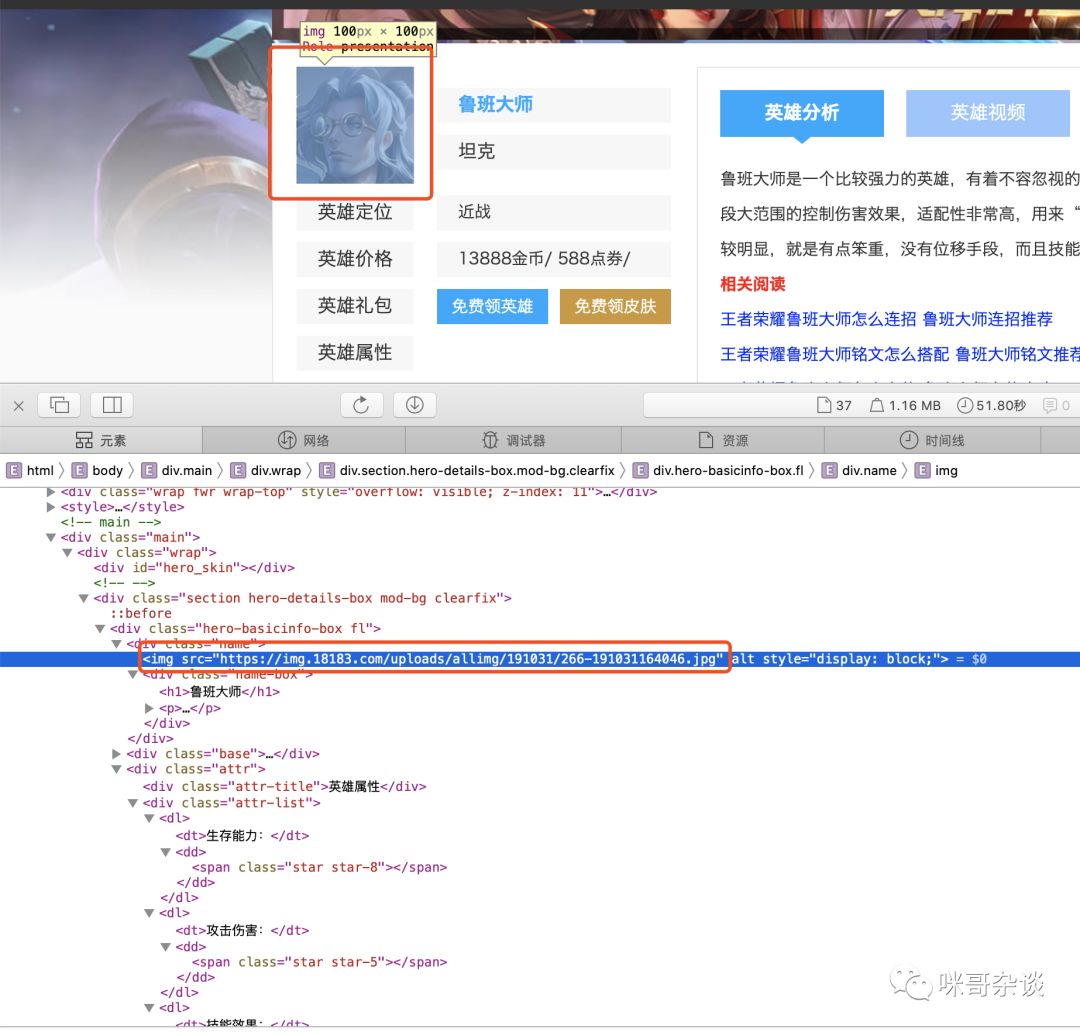
经过用开发者工具的这么一看,源地址应该是这个才对,怎么一直加载不出来?再仔细观察爬取到的地址:
http://js.18183.com/uploads/pc/yxzjol/sjk/loading.gif
和 js 肯定有关系,果不其然,这里遇到了图片的优化机制,图片懒加载。此机制也可以当做反爬虫机制的一种,隐藏了真实的图片地址。
图片懒加载是一种网页优化技术。图片作为一种网络资源,在被请求时也与普通静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面的首屏加载时间。
网络
那么,如何找到图片的真实地址?这就得去看 js 如何写的了!
拉到详情页最下方,看到有个懒加载的 js 。无疑就是它了!
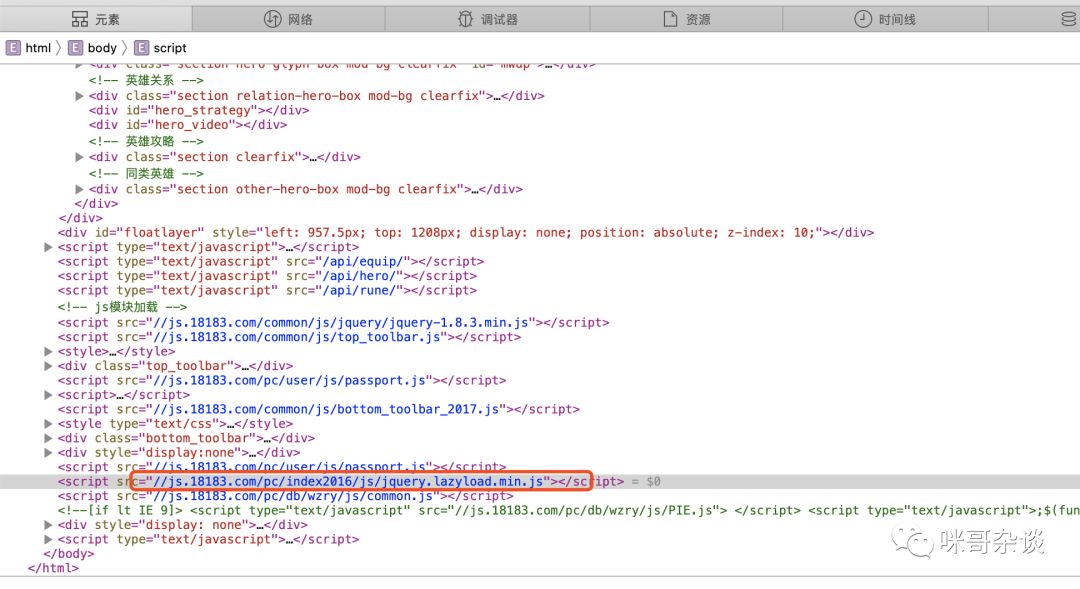
点过去看下,可以看到有段这样的代码:
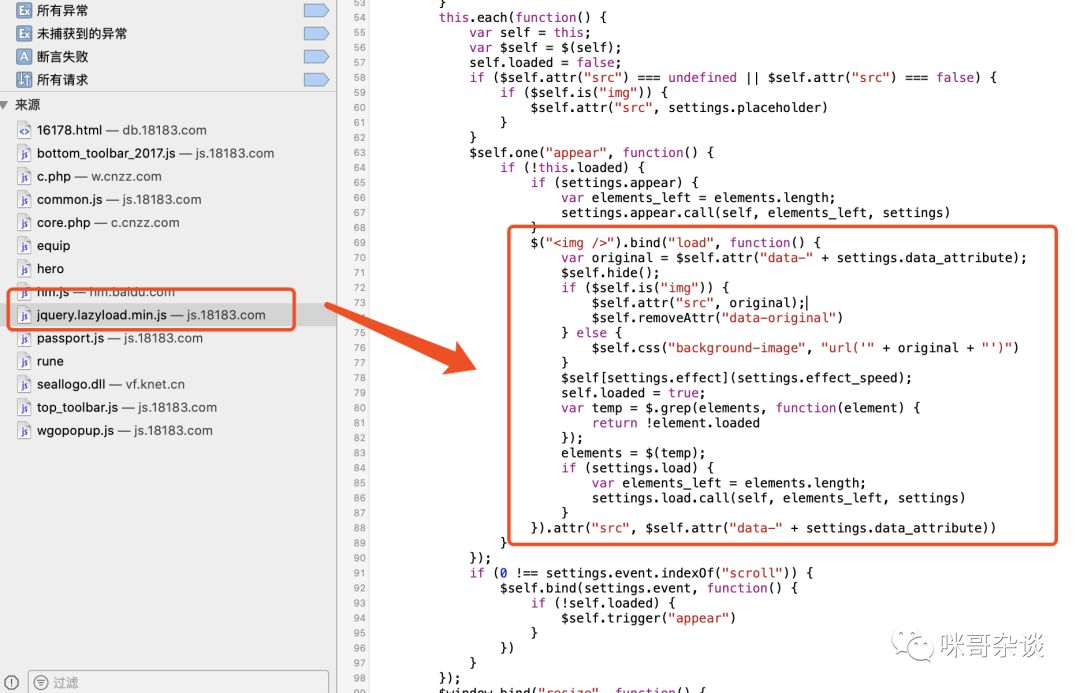
结合上下文看这段 js 代码,最终能猜出, img 的真实地址属性标签应为:"data-original"。
那么,来试一下:
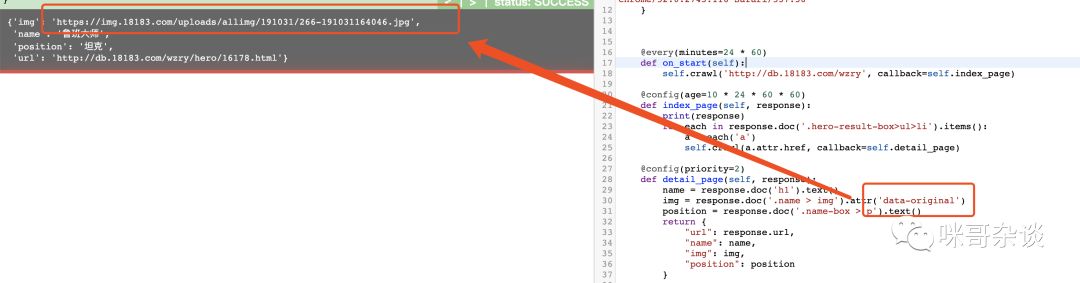
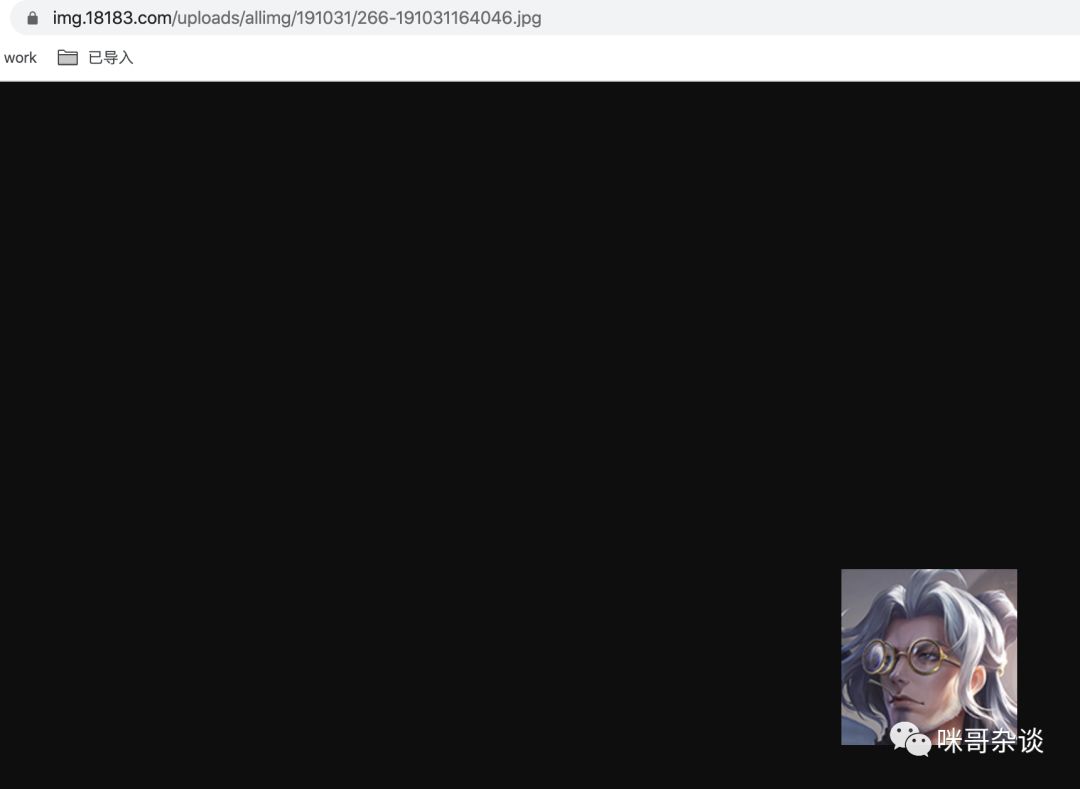
可以看到成功了。
5
结语
以上,便是 pyspider 爬取的入门教程了,当然,这只是抓取的步骤,数据离不开落地,下一篇,讲下如何数据落地,并且提供源码和这次抓取到的数据。
本篇内容高达 2500+ 字,如果看懂了,欢迎分享给身边对爬虫感兴趣的其他人看哟!顺便支持下点个好看呗,给点动力~
▼往期精彩回顾▼本期无推荐,推荐内容都在文中,回顾即可。
 你点的每个在看,我都认真当成了喜欢
你点的每个在看,我都认真当成了喜欢
评论