
华为提出DyNet:动态卷积
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自 | 视觉算法

背景
《DyNet: Dynamic Convolution for Accelerating Convolutional Neural Networks》是华为挂出的论文,其核心思想和谷歌的CondConv类似,产生kernel的方式有细微的不同,同时也取得了很高的性能涨点。

论文地址:http://de.arxiv.org/abs/2004.10694
一、 研究动机:
该论文利用了动态卷积来做神经网络的加速。该文章对activation进行了协方差的分析和可视化,从而提出了Coefficient prediction模块和Dynamic generation模块来产生动态卷积。相比于标准卷积,相同的通道数下,动态卷积的性能有明显的提升。
二、研究方法
整体思路如图所示:
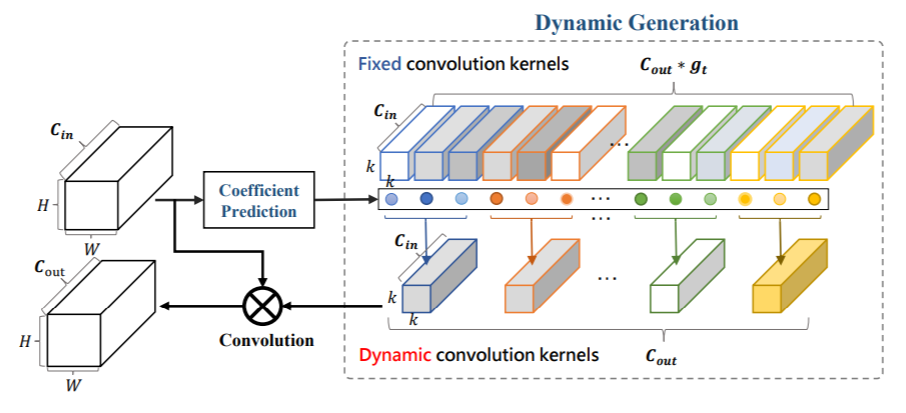
其核心思想和谷歌提出的条件卷积类似,通过activation生成一组权重,然后对fixed 权重进行加权求和生成动态卷积的权重。和CondConv主要区别在于该论文生成的权重参数更多,对于谷歌而言,一组卷积核的权重是共享的,而该论文是不共享的。
具体来看:
首先作者对现有网络的输出进行了协方差的统计和可视化:

其中S代表相关性最强,M、W、N依次减少。
可以看到,VGG的网络输出有较强的相关性。MobileNetv2的相关性相对较小,对于裁剪算法也较难进行裁剪。
协方差预测模块:

主要是生成卷积核采用一个全局pooling,然后采用全连接生成对应的权重。注意此处c的维度应该是 的。而在谷歌Condconv此处对应的应该是gt。
动态卷积核生成模块:

如前图所示,是各个group中的加权求和。
训练算法:
在训练过程中,由于每张图的卷积核都是不一致的,所以在一个batch里并行计算是困难的(在旷视DRConv中,是用过将batch方向的并行计算堆叠到c方向通过group卷积实现),该论文通过等效在特征图上进行等效加权,这样就类似于通道上的注意力机制:(

作者给出了mobileNet、shuffleNet、resnet18、resnet50上的增加动态卷积的方式:

三、实验结果:

可以看到,在相近的计算量下,Dy-MobileNetv3-small的性能更高;在性能接近的情况下,Dy-ResNet50的计算量减少了三分之二。
从可视化的角度看:
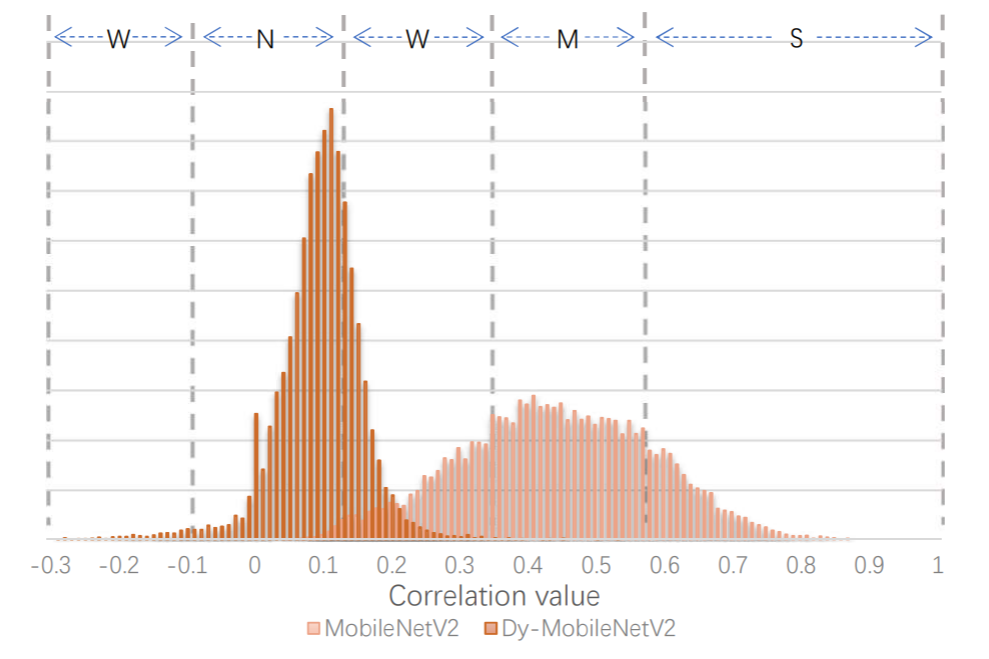
从可视化上看,MobileNetv2的activation的协方差来的更小。
四、总结分析:
该论文从轻量设计的角度提出了DyNet,能够有效地降低模型的计算量。思路上和CondConv较为接近,在实现上类似于通道注意力机制,另一方面该论文的训练采用了cosine学习率、label smooth等技巧。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~