
TNT | 致敬Network in Network,华为诺亚提出Transformer-in-Transformer

极市导读
本文是华为诺亚方舟实验在Transformer方面的又一次探索,针对现有Transformer存在打破图像块的结构信息的问题,提出了一种新颖的同时进行patch与pixel表达建模的TNT模块。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

本文是华为诺亚方舟实验在Transformer方面的又一次探索,针对现有Transformer存在打破图像块的结构信息的问题,提出了一种新颖的同时进行patch与pixel表达建模的TNT模块,它包含用于块嵌入建模的Outer Transformer 模块与像素嵌入建模的Inner Transformer模块,通过这种方式使得TNT可以同时提取全局与局部结构信息。在ImageNet数据集上,TNT-S模型以81.3%的top1精度超过了DeiT-S的的79.8%;TNT-B以82.8%的top1精度超过了DeiT-B的81.8%的top1精度。
Abstract
Transformer是一种自注意力机制神经网络,最早兴起于NLP领域。近来,纯transformer模型已被提出并用于CV的各个领域,比如用于low-level问题的IPT,detection的DETR,classification的ViT,segmentation的SETR等等。然而这些Visual Transformer通过将图像视作块序列而忽视了它们最本质的结构信息。
针对上述问题,我们提出了一种新颖的Transformer iN Transformer(TNT)模型用于对patch与pixel层面特征建模。在每个TNT模块中,outer transformer block用于处理块嵌入,而inner transformer block用于处理像素嵌入的局部特征,像素级特征通过线性变换投影到块嵌入空间并与块嵌入相加。通过堆叠TNT模块,我们构建了TNT模块用于图像识别。
我们在ImageNet与下游任务上验证了所提TNT架构的优越性,比如,在相似计算复杂度下,TNT在ImageNet上取得了81.3%的top1精度,以1.5%优于DeiT。
Method
接下来,我们将重点描述本文所提TNT架构并对其复杂度进行分析。在正式介绍之前,我们先对transformer的一些基本概念进行简单介绍。
Preliminaries
Transformer的基本概念包含MSA(Multi-head Self-Attention)、MLP(Multi-Layer Perceptron)以及LN(Layer Normalization)等。
MSA 在自注意力模块中,输入将被线性变换为三部分,即queries, keys, values。其中n表示序列长度,分别表示输入、queries以及values的维度。此时自注意力机制可以描述如下:
最后,通过一个线性层生成最终的输出。而多头自注意力会将queries、keys、values拆分h次分别实施上述注意力机制,最后将每个头的输出concat并线性投影得到最后的输出。
MLP MLP是位于自注意力之间的一个特征变换模块,起定义如下:
其中表示激活函数,常用GELU,其他参数则是全连接层的weight与bias,不再赘述。
LN LN 是确保transformer稳定训练与快速手链的关键部分,起定义如下:
其中,分别表示特征的均值与标准差,o表示点乘操作,为可学习变换参数。
Transformer in Transformer
给定2D图像,我们将其均匀的拆分为n块,其中p表示每个图像块的大小。ViT一文采用了标准transformer处理块序列,打破了块间的局部结构关系,可参考下图a。
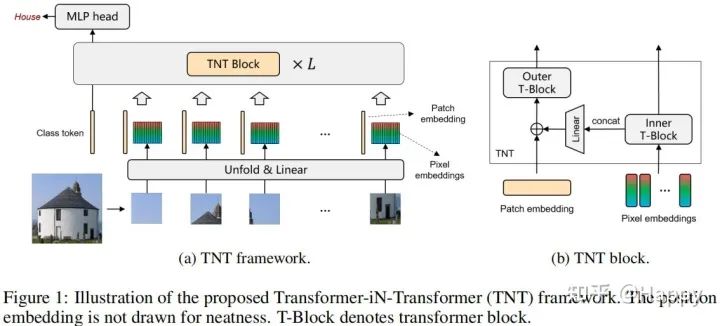
相反,本文提出了Transformer-iN-Transformer结构同时学习图像的全局与局部信息。在每个TNT模块中,每个块通过unfold进一步变换到目标尺寸,结合线性投影,块序列变为:
其中, c表示通道数量。具体来说,我们将每个块视作像素嵌入信息:
其中,。
在TNT内部,我们具有两个数据流,一个用于跨块操作,一个用于块内像素操作。对于像素嵌入,我们采用transformer模块探索像素之间的相关性:
其中表示层索引,L表示总共层数。所有块张量变换为。它可以视作inner transformer block,表示为,该过程构建了任意两个像素之间的相关性。
在块层面,我们创建了块嵌入内存以保存块特征,其中表示类信息,切初始化为0。在每一层,块张量通过线性投影变换到块嵌入空间并与块嵌入相加:
其中表示flatten操作。然后我们采用标准transformer模块对块嵌入进行变换:
该输出即为outer transformer block',它用于建模块嵌入之间的相关性。
总而言之,TNT的输入与输出包含像素嵌入与块嵌入,因此TNT可以表示为:
通过堆叠L次TNT模块,我们即可构建一个Transformer-in-Transformer网络,最后类别token作为图像特征表达,全连接层用于分类。
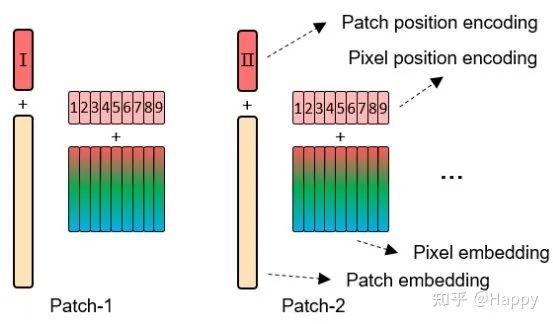
除了内容/特征信息外,空间信息也是图像识别非常重要的因素。对于块嵌入与像素嵌入来说,我们同时添加了位置编码信息,见上图。这里采用标准1D可学习位置编码信息,具体来说,每个块被赋予一个位置编码:
通过这种方式,块位置编码可以更好的保持全局空间结构信息,而像素位置编码可以保持局部相对位置关系。
Complexity Analysis
对于标准transformer而言,它包含两部分:MSA与MLP。MSA的FLOPs如下:
而MLP的FLOPs则为。所以,标准transformer的整体FLOPs如下:
一般来说,所以FLOPs可以简化为,而参数量则是
本文所提TNT则包含三部分:inner transformer block, outer transformer block与线性层。的计算复杂度分别为,线性层的FLOPS则是。因此TNT的总体FLOPs则表示如下:
类似的TNT的参数量表示如下:
尽管TNT添加了两个额外的成分,但FLOPs提升很小。TNT的Flops大约是标准模块的1.09x,参数量大概是1.08x。通过小幅的参数量与计算量提升,所提TNT模块可以有效的建模局部结构信息并取得精度-复杂度的均衡。
Network Architecture
在最终网络结构配置方面,我们延续了ViT与DeiT的配置方式。块大小为,unfold块大小。下表给出了TNT网络的不同大小的配置信息,它们分别包含23.8M核65.6M参数量,对应的FLOPs分别为5.2B与14.1B(注:输入图像尺寸为)。

Operational Optimizations 此外,启发与SE,我们进行tansformer的通道注意力机制探索。我们首先对所有patch/pixel嵌入进行平均,然后采用两层MLP计算注意力,所的注意力与所有嵌入相乘。SE模块仅仅带来非常少的参数量,但有助于进行通道层面的特征增强。
Experiments
为验证所提方案的有效性,我们在ImageNet以及其他下游数据上进行了对比分析,相关数据信息如下所示。
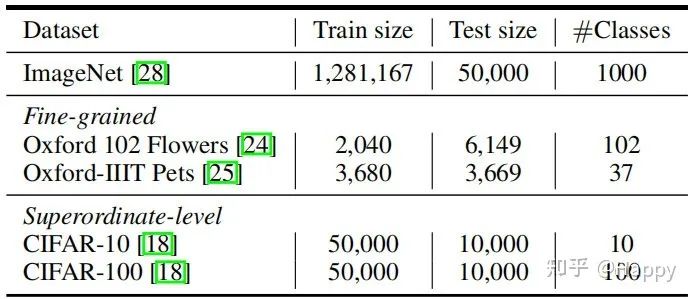
训练超参方面的配置信息如下所示。

我们先来看一下TNT、CNN以及其他Transformer在ImageNet上的性能对比,结果见下表。
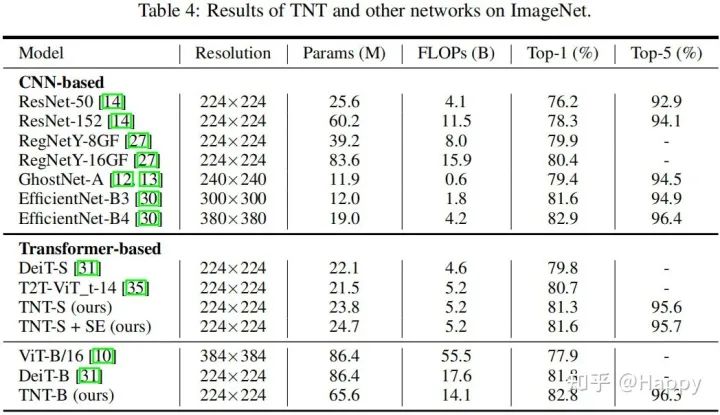
从上表可以看到:
所提TNT模型优于其他所有Transformer模块,TNT-S取得了81.3%top-1精度并以1.5%指标优于DeiT-S;通过添加SE模块,其性能可以进一步提升到81.6%top-1。 相比CNN模型,TNT优于广泛采用的ResNet与RegNet。
最后,我们再来看一下在下游任务的迁移效果,结果见效果。注:所有模型在分辨率进行了微调。
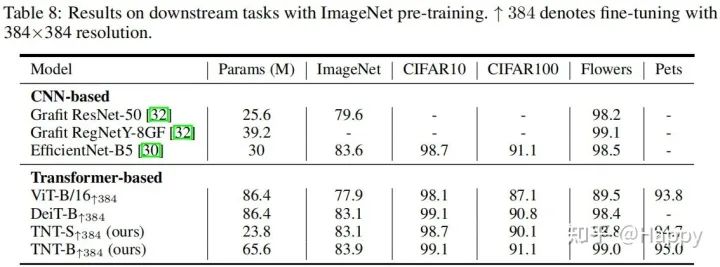
从上表可以看到:
在迁移学习方面,TNT取得了比DeiT更优的效果; 通过更高分辨率的微调,TNT-B取得了83.9%的top-1精度。
全文到此结束,更多消融实验与分析建议各位同学查看原文。
推荐阅读
2021-03-02

2021-01-28
2021-01-24

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
