点击下方 “AI算法与图像处理 ”,一起进步!
重磅干货,第一时间送达
在本文中,作者提出了一种名为 动态区域感知卷积(DRConv) 的新卷积,它可以自动将多个滤波器分配给具有相似特征表示的空间区域。标准卷积层通常是增加滤波器的数量以提取更多的视觉信息,但这会导致较高的计算成本。
而 本文的DRConv使用可学习的指导将增加的滤波器转移到空间维度,这不仅提高了卷积的表示能力,而且保持了计算成本和标准卷积的平移不变性 。DRConv是处理复杂多变空间信息分布的一种有效而优雅的方法,由于其即插即用的特性,它可以代替现有网络中的标准卷积。 作者在广泛的模型(MobileNet系列、ShuffleNet V2等)和任务(分类、人脸识别、检测和分割)上评估了DRConv。在ImageNet任务上,基于DRConv的ShuffleNet V2-0.5×在46M的multiply-adds计算量水平上实现了67.1%的SOTA性能,相对baseline提高了 6.3 % 。
Dynamic Region-Aware Convolution
论文地址:https://arxiv.org/abs/2003.12243
代码地址:未开源
卷积神经网络(CNNs)由于其强大的表示能力,在图像分类、人脸识别、目标检测等许多应用领域取得了重大进展。CNN强大的表示能力源于不同的滤波器负责在不同的抽象级别的信息提取。
然而,当前主流的卷积运算是以滤波器共享的方式跨空间域执行的,因此只有在重复应用这些卷积运算时,才能捕获更有效的信息(比如用更多的滤波器来增加通道数和深度)。但这种方式会带来几个局限性:首先,它的 计算效率很低 ;其次, 滤波器数量的增加会导致优化的困难 。 与滤波器共享的方法不同,为了对更多的视觉元素进行建模,目前一些研究侧重于通过在空间维度上使用多个滤波器来利用语义信息的多样性。比如,一些方法在每个像素上都使用单独的滤波器的替代卷积(在文中这类方法成为局部卷积),因此,每个位置的特征将被用不同方式地处理,这比标准卷积能够更有效地提取空间特征。虽然与标准卷积相比,局部卷积并没有增加计算复杂度,但它有两个致命的缺点: 1、局部卷积带来大量的参数,这些参数量和特征的大小呈正相关。 2、局部卷积破坏了平移不变性,这对某些需要平移不变性特征的任务 是不友好的 (例如,局部卷积不适用于分类任务)。
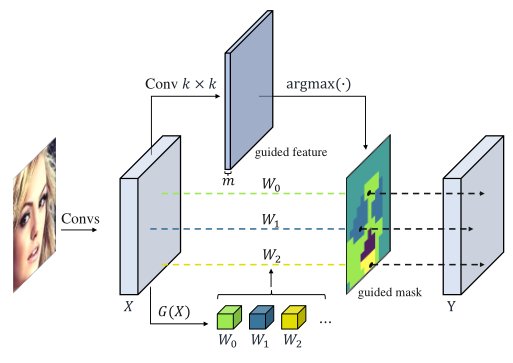
这两种方法都难以在神经网络中广泛应用。此外,局部卷积仍然在不同样本之间共享滤波器,这使模型对每个样本的特定特征不敏感。例如,在人脸识别和目标检测任务中,存在具有不同姿势或视点的样本。因此,跨不同样本的共享过滤器无法有效地提取特定于样本的特征。 考虑到上述局限性,本文提出了一种新的卷积算法,称为 动态区域卷积算法(DRConv) ,该算法能够自动将滤波器分配到相应的空间区域,因此,DRConv具有强大的语义表示能力,并完美地保持了平移不变性。 具体来说,作者设计了一个可学习的 引导掩模模块(guided mask module) ,根据每个输入图像的特征自动生成滤波器,并在相同的区域内共享滤波器。由于区域和滤波器都是基于样本的特征生成的,这种方法能更有效地关注样本自身的重要特征。
DRConv的结构如上图所示,首先用标准卷积从输入生成引导特征,然后根据引导特征,将空间维度划分为多个区域,每个区域用不同的颜色表示。在每个共享区域中,作者用滤波器生成器模块生成多个滤波器来执行二维卷积运算。 因此需要优化的参数主要集中在滤波器生成器模块中,其参数量与特征空间大小无关。除了显著提高网络性能外,本文的DRConv与局部卷积相比可以大大减少参数量,并且与标准卷积相比几乎不增加计算复杂度。 为了验证本文方法的有效性,作者在几个不同的任务上进行了一系列的实验研究,包括图像分类、人脸识别、目标检测和分割。实验结果表明,DRConv可以在这些任务上获得优异的性能。此外,作者还提供了充分的消融研究,以分析DRConv的有效性和鲁棒性。
权重共享机制限制了标准卷积模拟语义的变化。因此,标准卷积必须在通道维度上增加滤波器的数量,以匹配更多的空间视觉元素,但是这种做法是低效的。局部卷积利用了空间信息的多样性,但牺牲了平移不变性。
为了解决上述限制,作者提出了DRConv,它不仅通过在空间维度上使用多个滤波器来增加多样性,而且保持这些具有相似特征的区域的平移不变性。
3.1. Dynamic Region-Aware Convolution 标准卷积的输入可以表示为、 、
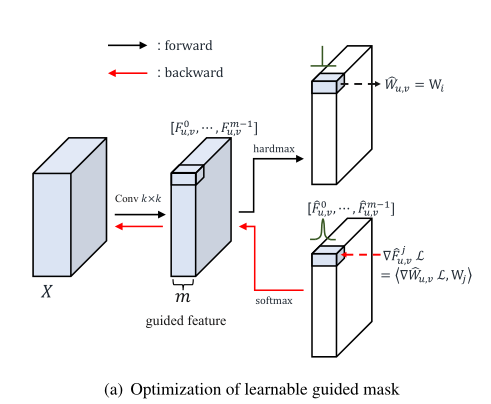
对于局部卷积,使用 基于上述公式,作者定义了 引导掩模(guided mask) 这个引导掩模是基于输入数据自适应学习的,相应的,每个区域对应的滤波器可以表示为 本文的方法主要分为两个步骤。首先,使用一个 可学习的引导掩模 将特征划分为多个空间区域,从语义上讲,语义相似的特征将被分配到同一区域。 其次,在每个共享区域中,作者们使用 滤波器生成器模块 生成一个基于输入的滤波器来执行正常的二维卷积运算。 可学习的引导掩模 决定将哪个滤波器器分配给哪个区域。 滤波器生成器模块 用于生成不同区域的相应滤波器。 3.2. Learnable guided mask 作为DRConv的最重要部分之一,可学习引导掩模决定了滤波器在空间维度上的分布,并通过损失函数进行优化。对于具有m个共享区域的k×k的DRConv,作者用k×k的标准卷积基于输入来生成输出通道数为m的引导特征。用,
其中, 但是,
Forward propagation 基于上面的介绍,每个位置的滤波器
通过这种方式,m个滤波器将与所有位置建立对应关系,并且可以将整个空间像素划分为m个组。空间上使用相同滤波器的像素具有相似的上下文,因为具有平移不变性的标准卷积将其信息传递给了引导特征。 Backward propagation 如上图所示,在反向传播的时候,作者引入了
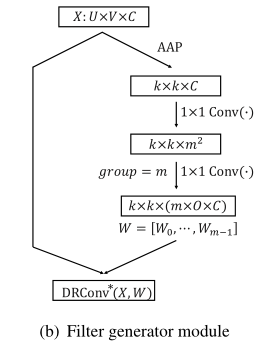
通过上式的 其中, 3.3. Dynamic Filter: Filter generator module 在DRConv中,多个滤波器将分配到不同的区域,滤波器生成器模块用于为这些区域生成滤波器。由于不同图像之间特征的多样性,跨图像的共享滤波器不足以有效地关注图像自身的特征。因此,作者在本文中提出了滤波器生成模块,基于输入数据自适应的生成滤波器。
将输入特征表示为 的滤波器,作者首先用了adaptive average pooling将输入 卷积,中间用了 4.1. Classification
上表展示了在ImageNet分类任务上,将不同的轻量级网络的卷积替换为DRConv的实验结果,可以看出DRConv能够显著提升模型的性能,并且对于不同的网络都是有用的。 4.2. Face Recognition
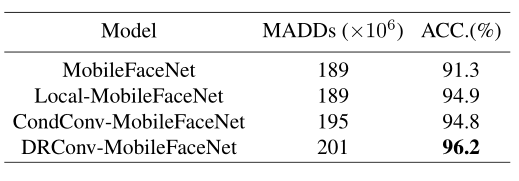
上表展示了人脸识别任务上,基于MobileFaceNet,不同方法的计算量和准确率对比,可以看出,本文的方法能够显著提高模型的性能。 4.3. COCO Object Detection and Segmentation
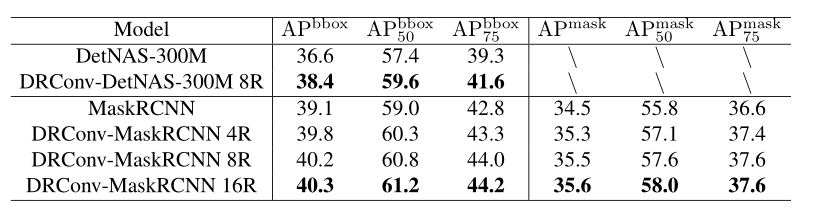
上表展示了在COCO目标检测和分割任务上,基于DetNAS-300M和Mask R-CNN框架,baseline和DRConv的实验结果对比,可以看出,相比于baseline,本文方法能够明显提高性能,证明了DRConv的有效性。 4.4. Ablation Study Visualization of dynamic guided mask
上图展示了本文方法划分区域的可视化结果,可以看出,划分的区域具有显著的语义信息,能够帮助模型的学习。 Different model size
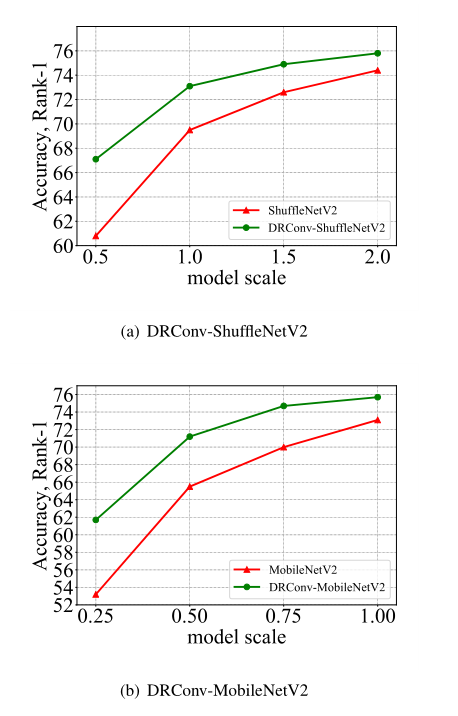
上图展示了在不同模型大小下,本文方法和baseline方法的对比,可以看出,本文的方法在小模型上能够实现更显著的性能提升,因为通过用DRConv取代标准卷积,小型模型将显著提高其建模语义信息的能力,从而获得更好的性能。
在本文中,作者提出了一种新的卷积,称为 动态区域感知卷积(DRConv) ,该卷积在空间域中采用了部分共享的滤波器,并成功地保持了平移不变性。本文提出的DRConv可以完全替代任何现有网络中的标准卷积。
实现上,作者设计了一个 可学习的引导掩模模块 用于滤波器的分配引导任务,这保证了一个区域中的相似特征可以匹配相同的滤波器器。 此外,作者还设计了 滤波器生成器模块 ,为每个数据样本生成基于输入的滤波器,这使得不同的输入可以使用自己的专用滤波器。 在多个不同任务上的综合实验表明了DRConv的有效性,此外,消融实验的结果表明,可学习引导掩模在每个样本的滤波器分布中起着关键作用,有助于获得更好的性能。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉 、计算摄影 、检测、分割、识别、医学影像、GAN、算法竞赛 等微信群
下载1:何恺明顶会分享
在「 AI算法与图像处 理」 公众号后台回复: 何恺明 ,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「 AI算法与图像处 理」 公众号后台回复: c++ ,即可下载。 历经十年考验,最权威的编程规范!
在「AI算法与图像处 理 」 公众号后台回复: CVPR , 即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文