
论文浅尝 | 预训练Transformer用于跨领域知识图谱补全

笔记整理:汪俊杰,浙江大学硕士,研究方向为知识图谱
链接:https://arxiv.org/pdf/2303.15682.pdf
动机
传统的直推式(tranductive)或者归纳式(inductive)的知识图谱补全(KGC)模型都关注于域内(in-domain)数据,而比较少关注模型在不同领域KG之间的迁移能力。随着NLP领域中迁移学习的成功,目前有不少研究使用预训练的语言模型来提高KGC模型的表现,或者同时训练语言模型和KGC模型提升下游NLP任务的表现。尽管这种在结构化的KG和非结构化的文本之间的迁移已经取得了进展,但是关于将模型从一个KG迁移到其他KG的研究还比较少。因此,这项工作的目标是预训练一个Transformer-based可以同时用于transductive和inductive任务的知识图谱补全模型,并且从非结构化文本和结构化KG中同时学习可迁移的知识表示。
贡献
本论文的主要贡献如下:
(1). 提出了一个新的知识图谱补全模型iHT,使用实体的文本信息和实体的邻居进行实体的表示,可以同时用于transductive和inductive KGC;
(2). 在百科全书式大型知识图谱Wikidata5M上进行预训练,预训练的链接预测取得了比传统方法更好的效果;
(3). 将预训练的模型iHT迁移到小型知识图谱上进行微调,取得了比传统模型以及预训练语言模型更好的效果;
方法
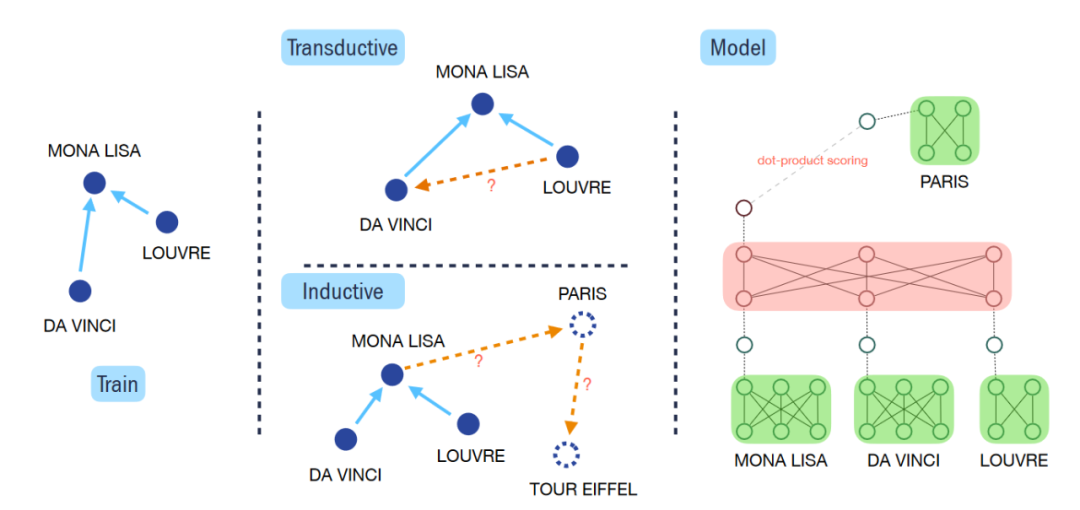
1. 预训练
预训练阶段使用的数据集为Wikidata5M,数据集里面的每个实体都有一段文本描述,作者首先构造了Entity Transformer输入每个实体的文本描述从而得到每个实体的表示。因为有实体文本的存在,所以在inductive KGC任务下,测试中没有见过的实体可以通过文本的内容进行表示。此处Entity Transformer的初始化参数来自于预训练的语言模型BERT,从而更好获取实体文本中蕴含的知识。
在E ntity Transformer之后,作者又设置了Context Transformer。对于一个训练样本(h,r,t)来说,会随机采样K个头实体(h)的邻居以及相连的关系(r)作为这个训练样本的环境信息(Context),Context Transformer的输入为CLS token、h、r,以及h的Context组成的序列。在Context Transformer最后一层GCLS token的embedding将用于之后的链接预测(link predication)。
在link prediction这一步,如果是在训练阶段,每个batch内将会随机采样N个实体作为负样本,将这N个错误的实体与正确的尾实体都和GCLS的embedding计算点乘相似度作为分数,得到N+1维的预测向量,再将此预测向量和one-hot标签计算交叉熵损失。而在预测阶段,这一步将会使用所有的候选实体计算预测分数。
2. 模型迁移
在Wikidata5M上完成iHT的预训练之后,作者将其迁移到小型知识图谱FB15K-237和WN18RR上进行微调。这两个小型KG与预训练的KG存在区别,故可以视为是跨领域的知识图谱补全,虽然FB15K-237中的实体大多数都在Wikidata5M中出现过,但是关系的分布存在区别,作者统计得出在FB15K-237中有80%的头尾实体对是没有在Wikidata5M中出现过的,故也能在一定程度上说明模型的迁移能力;而WN18RR和Wikidata5M的区别会更大,他们的数据源和内容都不一样,因此更能说明模型在不同领域KG之间的迁移能力。
实验
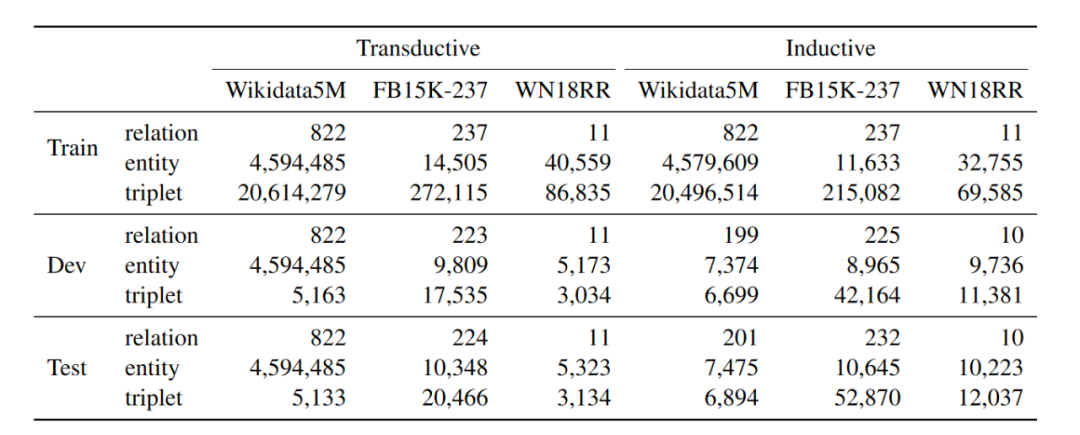
本文在预训练和迁移实验中分别用到了Wikidata5M、FB15K-237和WN18RR三个数据集,并且每个数据集都有transductive和inductive两个版本,数据集的统计信息如下:
实验的部分参数设置如下:

1. 预训练实验
在预训练阶段,作者测试了模型的表现能力,在transductive设定下的实验结果为:
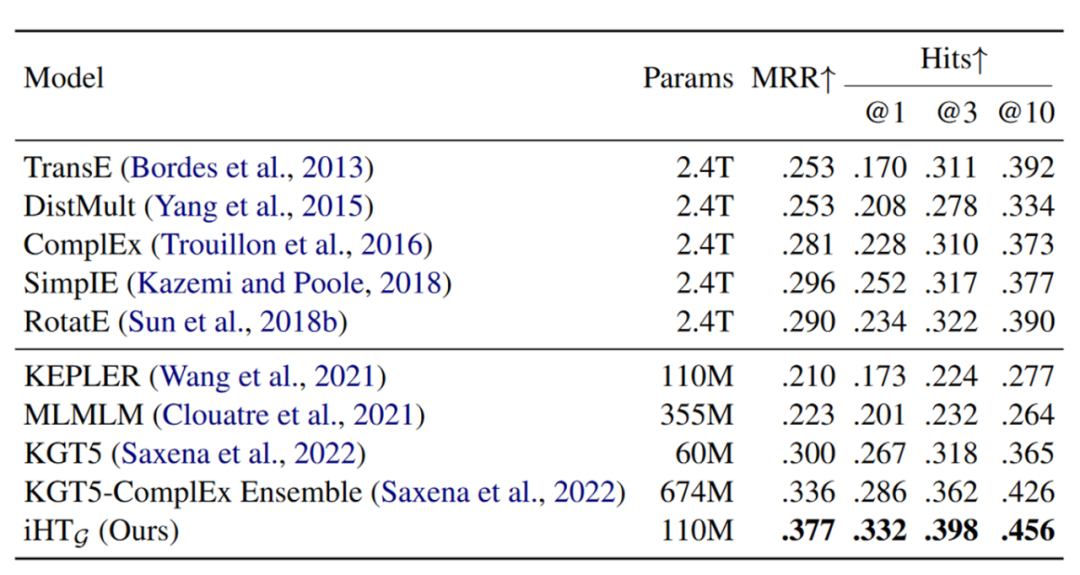
表格的上半部分为传统的KGE模型,下半部分为Transformer-based并且使用了数据集中文本信息的模型,这些Transformer-based模型与本文所提出的模型的主要区别在于Decoder部分,例如MLMLM和KGT5都利用语言建模目标的分布来估计目标实体的可能性,而KEPLER使用类似TransE的评分函数。可以看出不管与哪种模型比较,本文的新模型iHT都取得了最优的效果。在inductive设定下,本文的模型iHT也依然取得了最优效果,具体表现如下所示:
随后作者做了预训练阶段的消融实验,结果如下表所示:
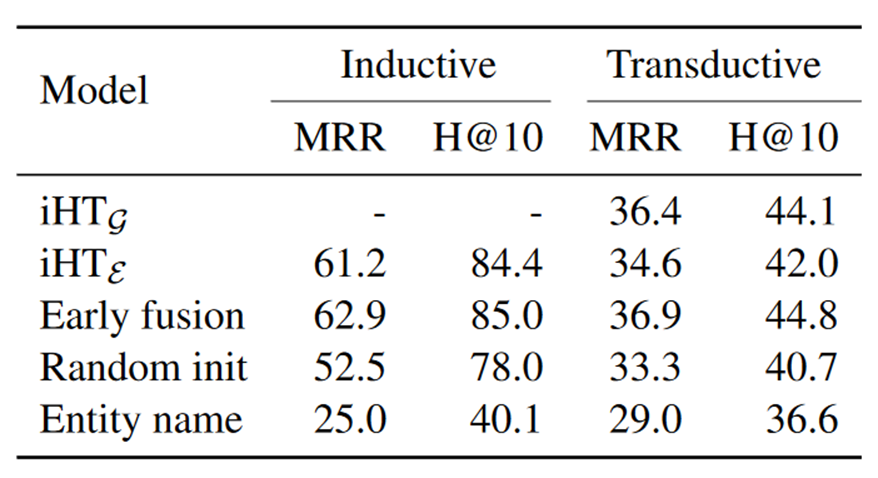
为了节约时间,作者在消融实验阶段只设置了5个epoch,所以完整实验结果会与主实验存在微小差异,但并不影响对于模型效果影响因素的探究。第一行是在Context Transformer中使用了头实体邻居信息的结果;第二行是没有使用头实体邻居信息的结果,可以看出在Transductive情境下实体的邻居信息对于实验效果起到了一定程度的贡献;第三行Early Fusion代表着在Entity Transformer中融入关系信息(具体实现方法论文中未详细阐述),可以看出提前给模型关于关系的信息可以提高模型在KGC任务上的表现,但这也会带来效率的下降,因此是否使用提前使用关系信息可以视为在模型表现和模型效率之间的权衡;第四行Random init代表不使用预训练的语言模型BERT进行参数初始化,而是使用参数随机初始化的Transformer模型,在给定的训练epoch下,模型的表现出现了较大程度的下降,因此可以证明预训练的语言模型在训练资源有限的情况下可以帮助理解实体的文本信息从而提高KGC模型的表现;最后一行Entity name代表的是实体的文本类型对于模型性能的影响,在消融实验中作者将实体的文本替换为长度更短、信息更少的实体名称,结果实验效果出现了最大幅度的下降。从上可以看出,在作者设计的模型中,预训练语言模型以及语料信息起到非常大的作用。
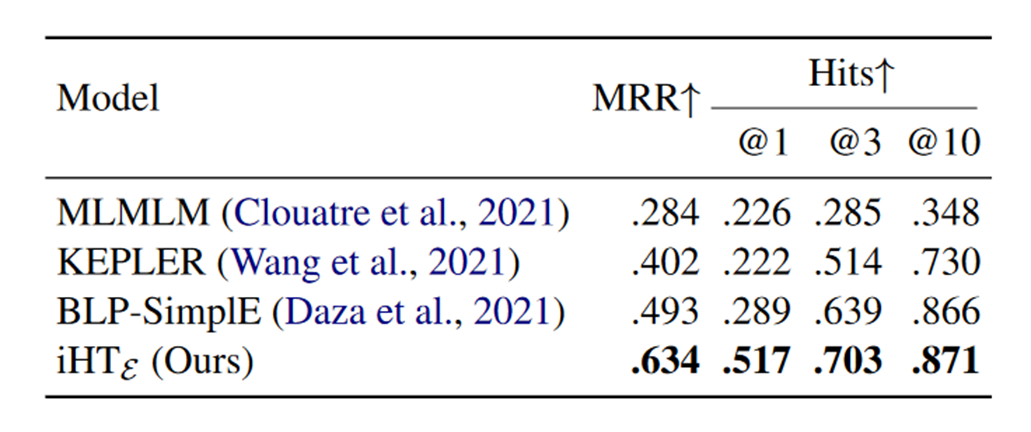
2. 迁移实验
作者将预训练之后的模型iHT在两个小型知识图谱上进行了微调,并测试了链接预测的实验结果,如下表所示:
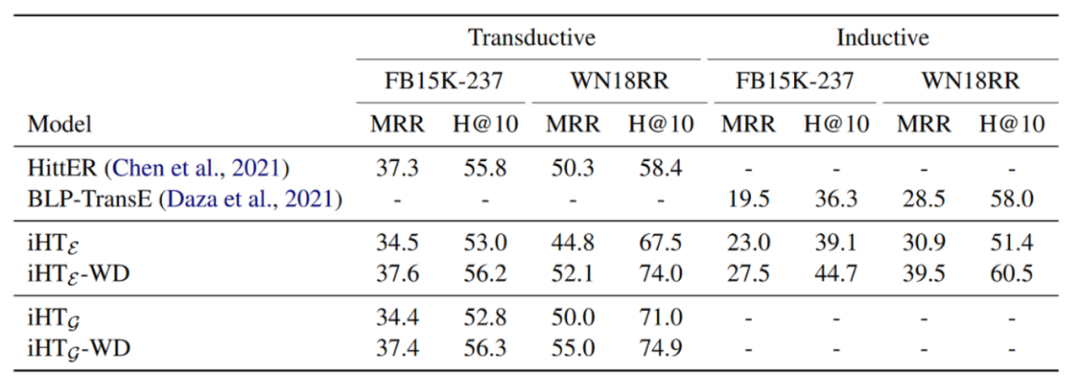
作者对比了两个从头训练的baseline模型,并对比了有无Wikidata5M预训练的模型,表格中WD代表使用在Wikidata5M上预训练过的模型进行微调的测试结果,未带WD的实验结果为直接使用预训练的语言模型BERT进行微调的结果,可以看出使用大型知识图谱预训练过的模型会比原始的BERT效果更好一点,说明了在一个KG上预训练然后迁移到另外一个KG上会比直接使用预训练的语言模型迁移到KG上效果更好。
论文还进一步探究在迁移实验下不同的训练数据量对于模型表现的影响,实验结果对下表所示:
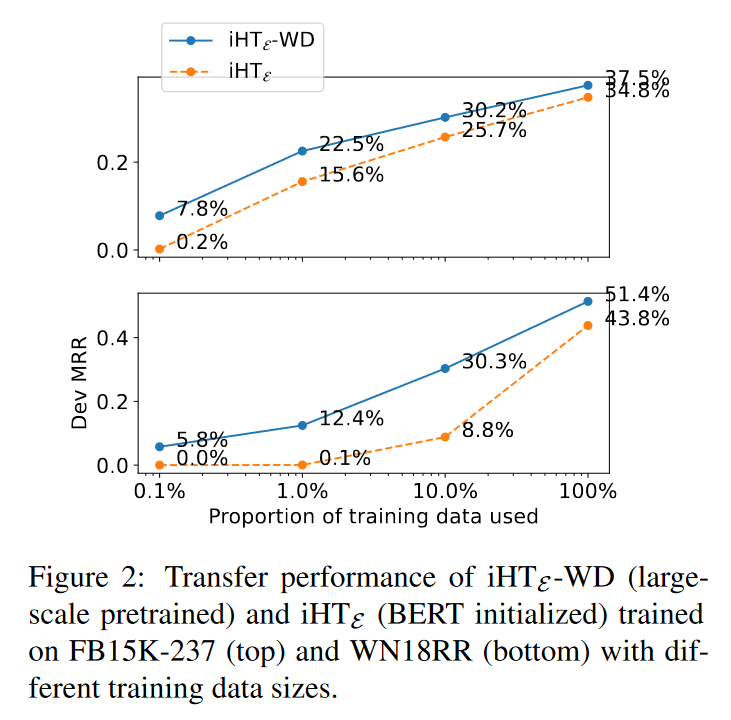
在任何体量的训练数据下,使用Wikidata5M大型知识图谱预训练的模型的链接预测效果都比不进行预训练的效果更好,值得注意的是,在WN18RR数据集中使用10%的训练数据原模型就可以达到0.3以上的MRR,对比使用全量训练数据且未经KG预训练的语言模型的MRR(0.438),已经可以达到其70%以上的效果。可见在大型知识图谱上进行预训练有望减少下游迁移任务的训练数据量要求。
总结
这篇论文提出了一个Transformer-based可以用于inductive KGC和transductive KGC的模型,模型适用于有实体文本信息的数据。在这样的设定下,Wikidata5M上的预训练结果不管在transuctive还是inductive情境下都取得了SOTA效果。最后将Wikidata5M上预训练过的模型迁移到了FB15K-237和WN18RR上进行微调,证明了使用语言模型在大型KG上进行预训练之后,可以提升它在其他领域KG上的表现。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。
点击阅读原文,进入 OpenKG 网站。