
DiffRate:首个可微分Token压缩,性能SOTA | ICCV 2023
Token压缩,指的是在模型推理过程中减少token数量,其是加速Vision Transformers (ViTs)的重要手段。目前,Token压缩主要分为两种:token剪枝(如 EViT [1])和token合并(如 ToMe [2])。但现有的工作,无论是token剪枝还是token压缩,都需要人工去定义token压缩率,为不同的FLOPs定义不同的token压缩率不仅繁琐,且通常会导致次优结果。
为了解决这个问题,我们提出可微压缩率(Differentiable Compression Rate, DiffRate),论文DiffRate : Differentiable Compression Rate for Efficient Vision Transformers已被ICCV 2023会议接收,代码、预训练模型均已在GitHub上开源。

论文:
https://arxiv.org/abs/2305.17997
代码:(点击文末“阅读原文”直达开源链接)
https://github.com/OpenGVLab/DiffRate


DiffRate的优势


Diffrate具有如下优势:
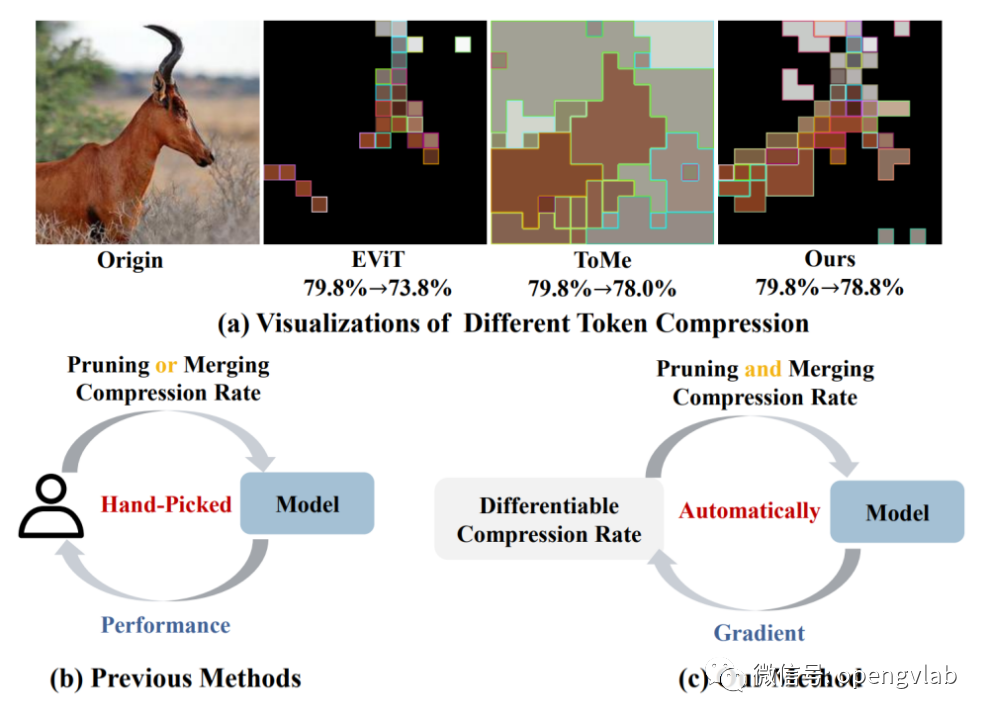 图1 和此前token压缩方法的对比
图1 和此前token压缩方法的对比 方法详述
Token压缩可以发生在每一个Transformer Block中。一个Transformer Block中包含有两个模块,Attention和MLP。由于token交互只发生在Attention模块,为了节约更多计算量,通常选择在Attention与MLP模块中间进行token压缩,其基本形式可以表示为下图:
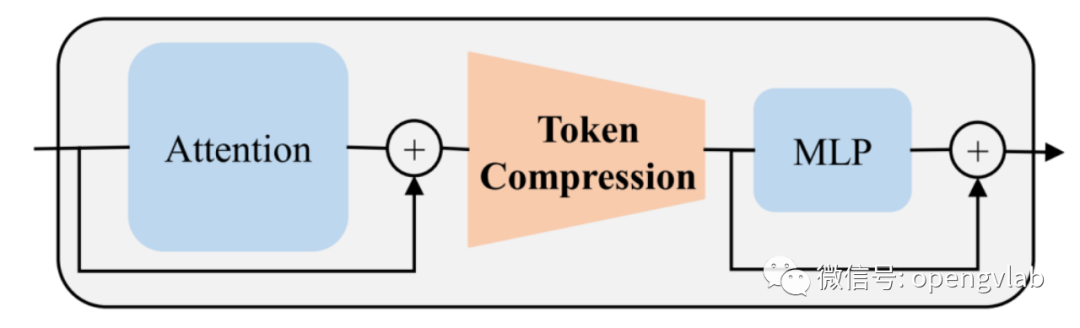 图2 Token压缩示意图
图2 Token压缩示意图 搜索最优的token剪枝压缩率和token合并压缩率以最小化任务损失:
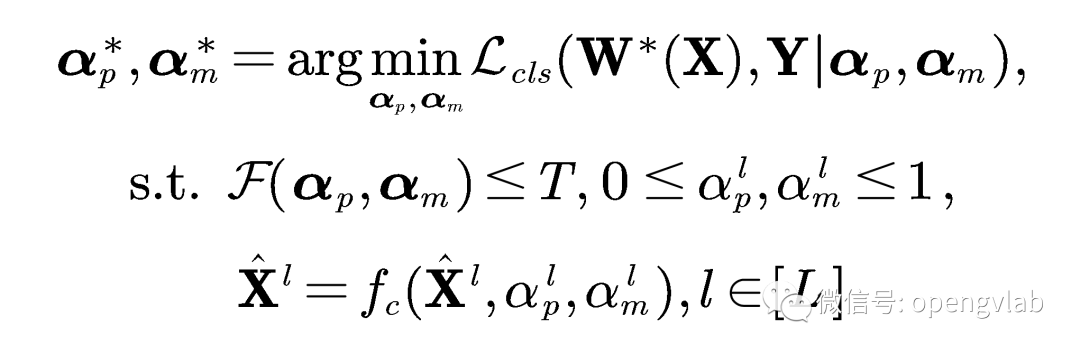
可微的离散代理
(Differentiable Discrete Proxy)
Token排序
(Token Sorting)
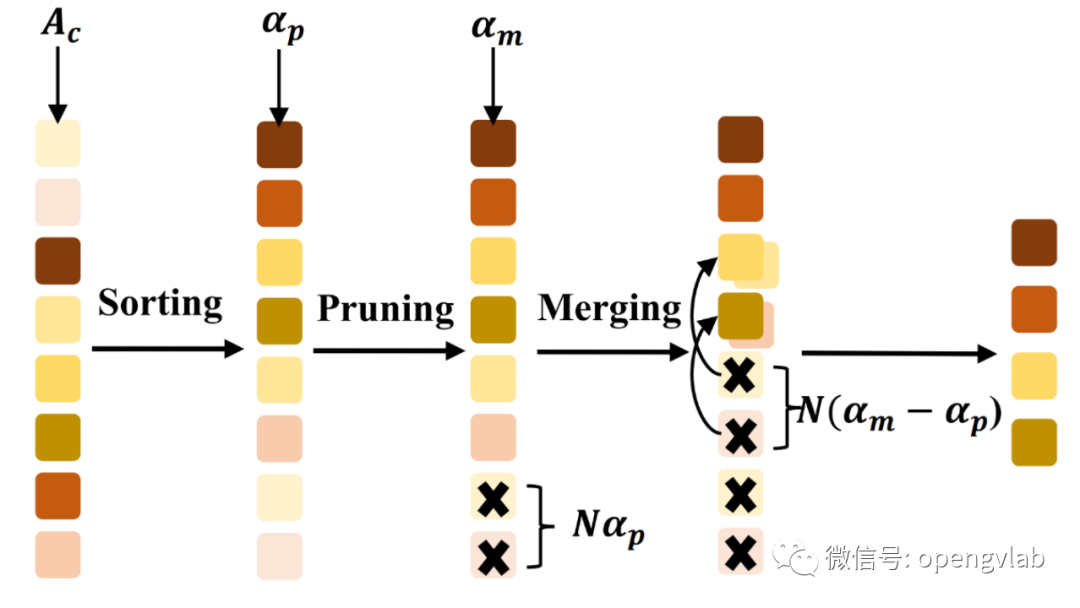 图3 Token排序
图3 Token排序 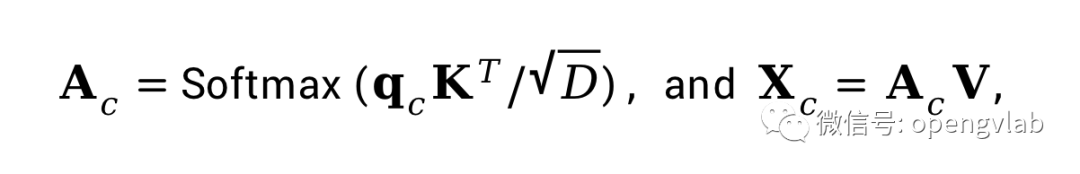 其中,
其中, 表示每一个image token对class token的贡献程度,越高的值表明image token对最终输出贡献越大,即越重要。如图3所示,我们首先根据
对N个token进行排序。紧接着,遵循此前的token剪枝工作,为了移除语义无关的冗余token, 我们依照剪枝压缩率移除最不重要的
个token。剪枝之后,我们进一步进行token合并, 进一步选出
个不重要的token,依据cosine相似度,将他们融合到最相似的保留token中,融合操作直接采用求平均。基于此排序-剪枝-合并的流程,token剪枝率和token压缩率可以通过DiffRate被最优得决定。因此,DiffRate可以无缝合并token剪枝和token压缩。
压缩率重参
(Compression Rate Re-parameterization)
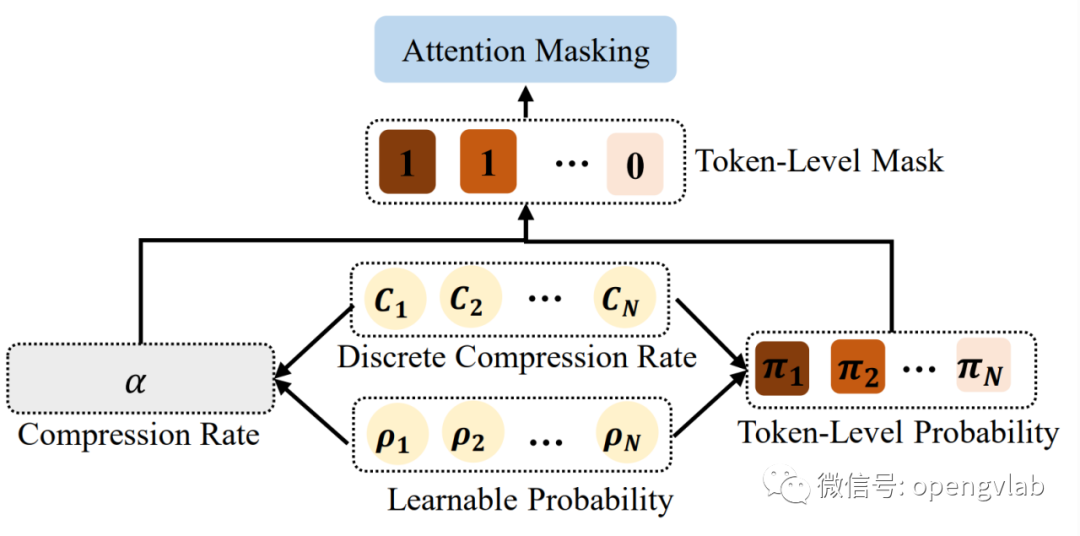 图4 压缩率重参
图4 压缩率重参 可微,我们将其重参成N个离散的候选压缩率,
。其中,
, 表示最不重要的k-1个token需要被移除。每一个候选压缩率对应一个可学习概率
,其中
。基于此,最终压缩率
可以表示成:
。为了将可学习概率
融入计算图,我们首先根据候选压缩率与其对应的可学习概率求出每一个token被压缩的概率:
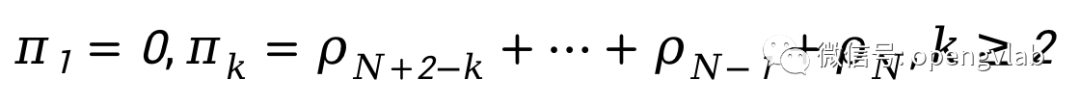 其中,
其中, 表示至少一个token会被保留。并且,从上式可以看出,
。即表明DiffRate对齐了不重要的token要有更大概率被压缩的事实。进一步的,我们将此被压缩概率转换成一个0-1 mask:
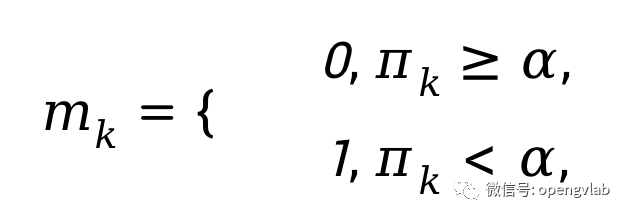
表示第k个token被保留,反之亦然。在每一个transformer block中, 我们引入两个独立的重参数模块,以此同时学习剪枝和合并压缩率。因此,每一个block中有两个mask。针对每个token而言,其同时具备剪枝mask
和合并mask
。注意一旦一个token在前一个block中被移除,其在当前block中也应当被移除,因此,最终的mask定义为:
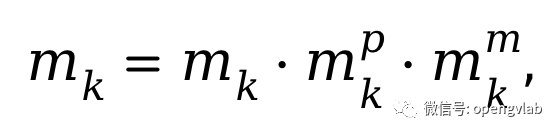
:
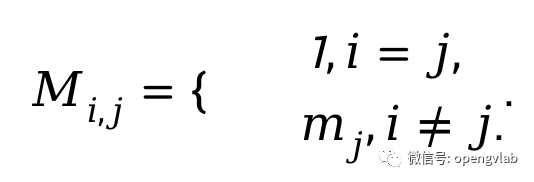
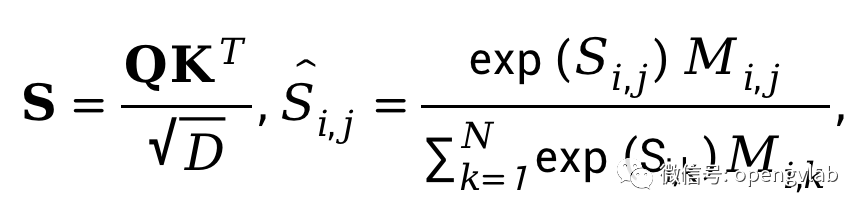
通过以上attention masking的操作,我们实现了训练时保证梯度链的完整性,且计算结果和测试时直接丢弃token等价。
训练目标
(Training Objective)
我们通过最小化以下loss来求解最优的token剪枝和合并压缩率。
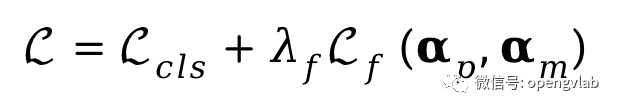
是任务约束,
将压缩后的FLOPs约束到T。在反向传播过程中,基于直通估计(straight-through-estimator, STE),
对于
的梯度可以计算如下:
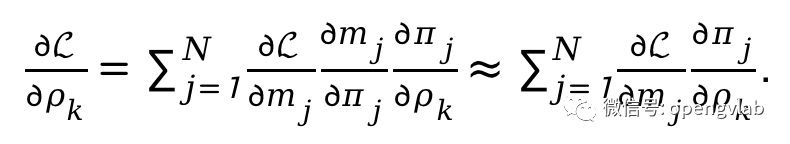
实验结果
压缩后若是无需fine-tuning,显然具有更好的易用性。表1展示了进行token压缩后不fine-tuning的实验结果,可以看出,相比于EViT和ToMe, DiffRate显著提高了性能。并且,在ViT-S(DeiT), ViT-B (DeiT), ViT-L (MAE), ViT-H (MAE)上,DiffRate压缩30%-40%左右的FLOPs开销,在ImageNet上性能损失皆小于0.4%。尤其是在ViT-H (MAE)上,40%的FLOPs降低仅带来了0.16%的性能损失。
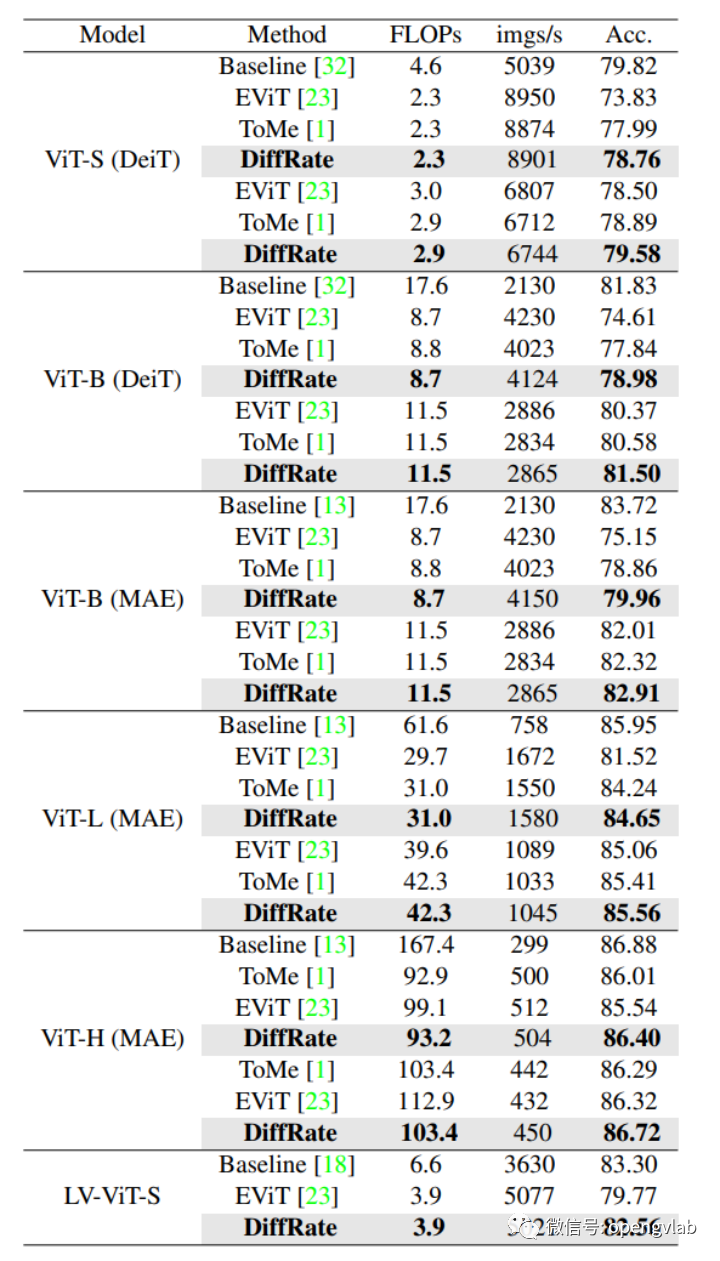 表1 token压缩后不fine-tuning的实验结果
表1 token压缩后不fine-tuning的实验结果 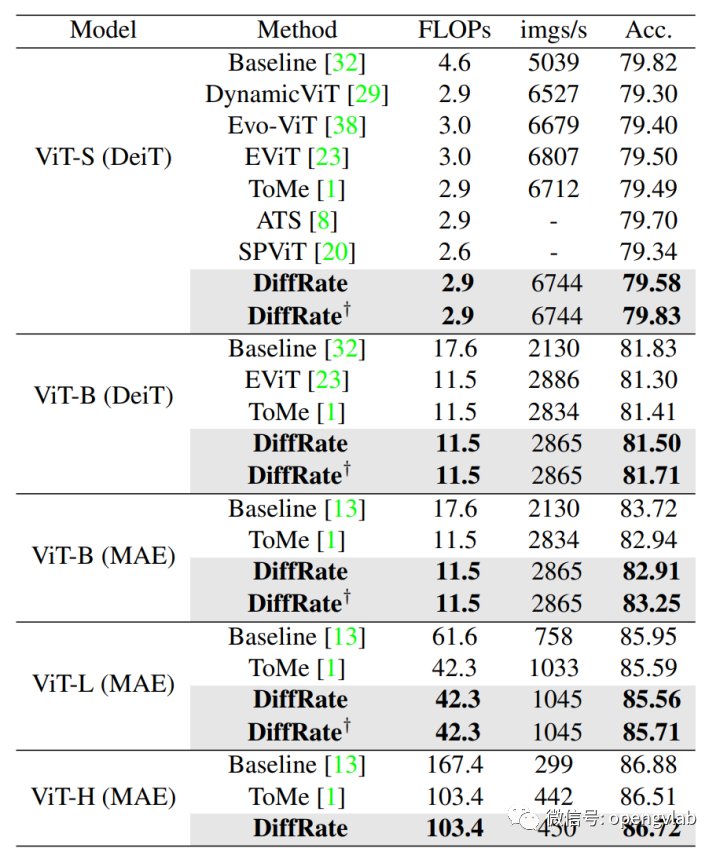 表2 token压缩且fine-tuning 30epoch的实验结果
表2 token压缩且fine-tuning 30epoch的实验结果
表示fine-tuning 30 epoch
图5展示了不同token压缩设置下DiffRate搜索到的压缩率与人工定义的压缩率(EViT, ToMe),以及10000个随机采样的压缩率的对比,可以看出,DiffRate搜索到的压缩率基本接近最优曲线。
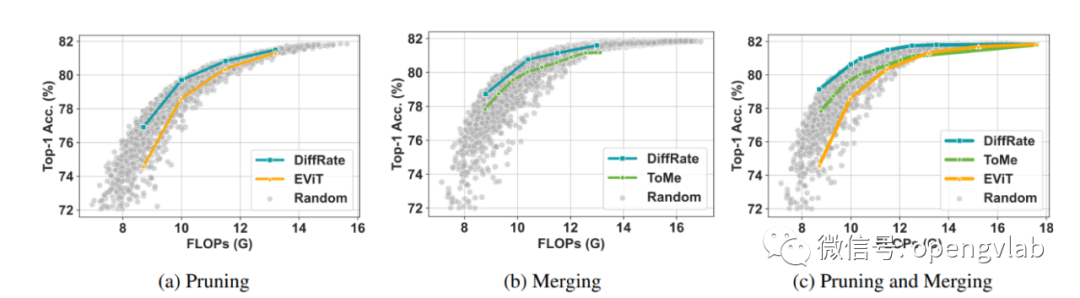 图5 Token压缩率对比
图5 Token压缩率对比 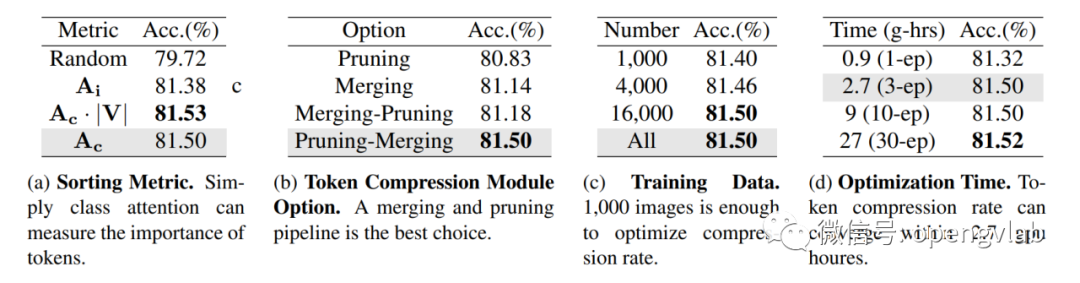 表4 DeiT-B上的消融实验
表4 DeiT-B上的消融实验  图6 可视化
图6 可视化 结语
该文对token压缩进行研究,提出了一个统一的token剪枝与token合并流程,并提出可微压缩率以根据计算量约束自适应决定网络每一层的token剪枝和token合并压缩率。实验结果证明了提出方法在性能上的优势,尤其是可以在不fine-tuning的情况下,优于此前需要fine-tuning的方法。
Paper:
https://arxiv.org/abs/2305.17997
Code:(点击文末“阅读原文”直达开源链接)
https://github.com/OpenGVLab/DiffRate
往期推荐
点击下方名片,获取通用视觉团队更多研究动态