三行代码,AutoML性能提高十倍!微软开源FLAMA,比sota还要sota

新智元报道
新智元报道
来源:towardsdatascience
编辑:LRS
【新智元导读】AI程序员狠起来连自己的岗位都要干掉。随着AutoML研究的深入,自动搜索最优的神经网络模型已经变得越来越快。最近微软开源了他们的方案FLAMA,网络搜索性能比sota还要显著提升,资源消耗降低为原来的十分之一!最重要的是它是Python库,三行代码就能彻底改造你的AutoML方案!





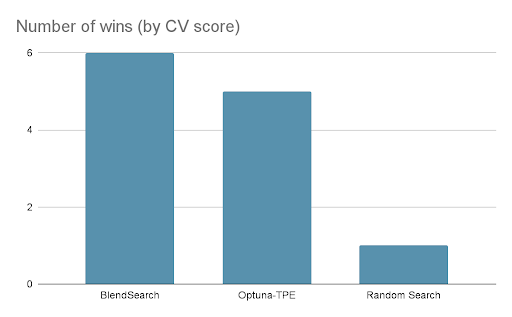
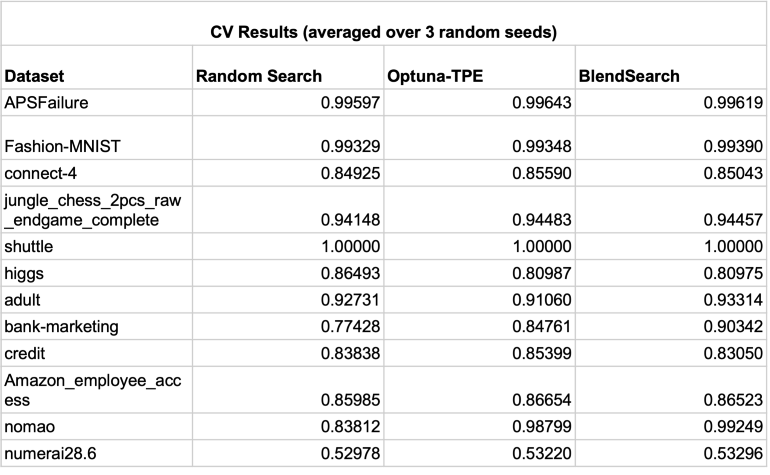



参考资料:

评论
 下载APP
下载APP新智元报道
来源:towardsdatascience
编辑:LRS
参考资料: