点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文分享一篇的论文『3D Human Pose Estimation with Spatial and Temporal Transformers』。文中提出首个纯粹基于Transformer 的架构,在不涉及卷积的情况下在视频中实现3D人体姿态估计。算法在Human3.6M和MPI-INF-3DHP数据集上均达到SOTA performance,并在 in the wild 视频中有着不错的表现。论文作者:Ce Zheng, Sijie Zhu, Matias Mendieta, Taojiannan Yang, Chen Chen, Zhengming Ding
作者单位:北卡夏洛特分校;杜兰大学
论文链接:https://arxiv.org/abs/2103.10455
项目地址:https://github.com/zczcwh/PoseFormer
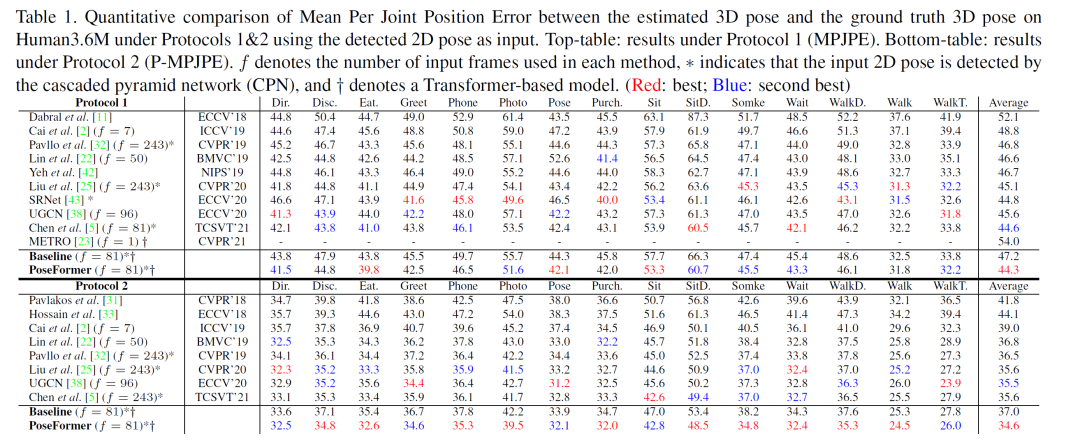
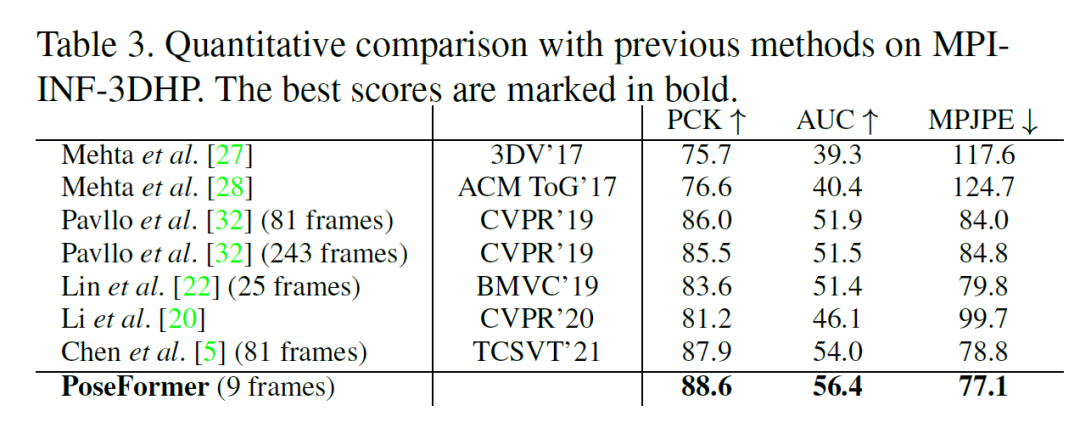
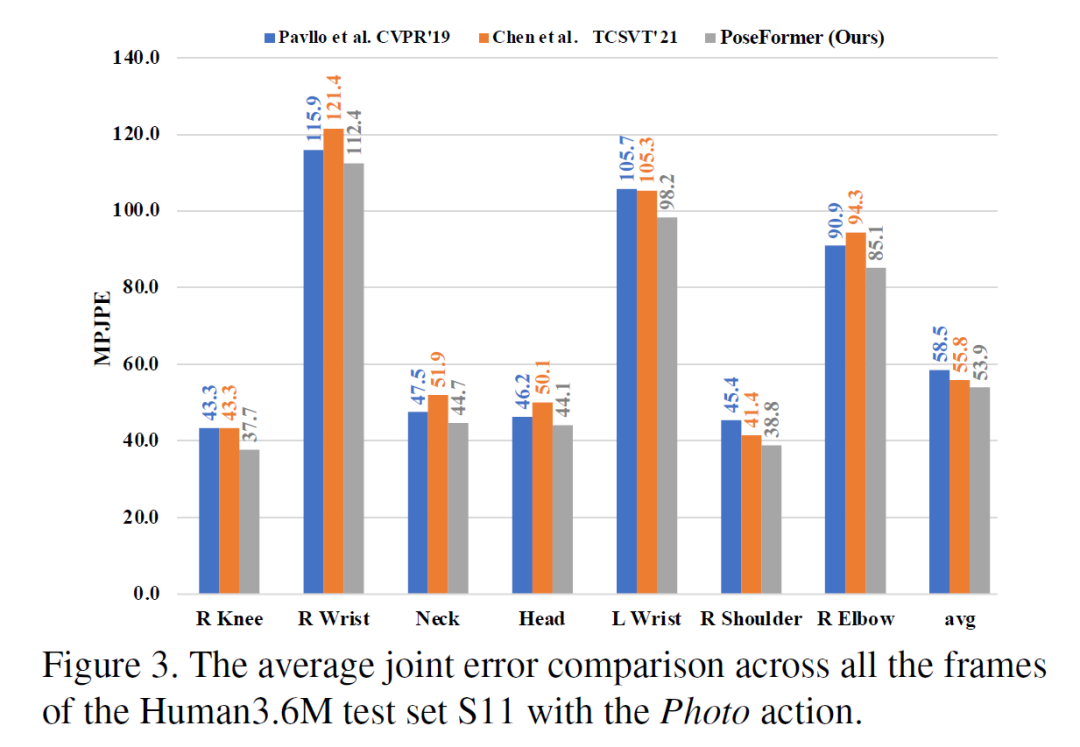
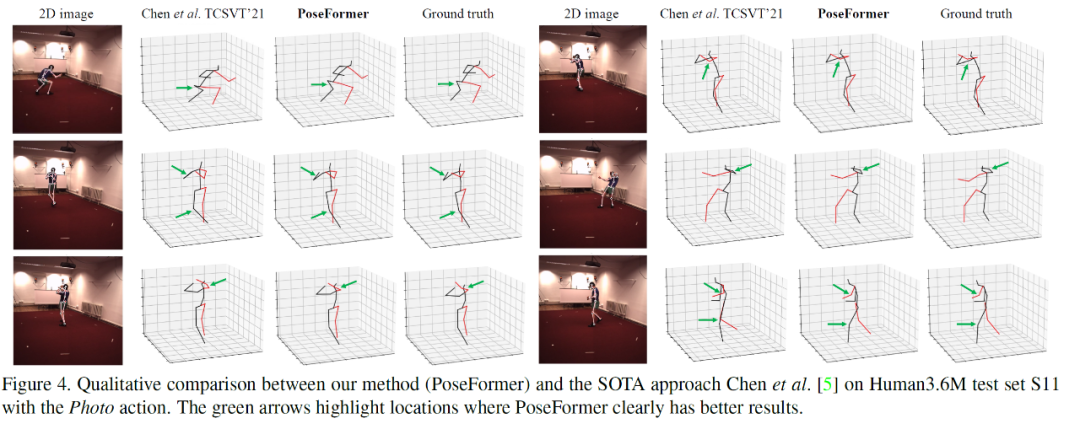
人体姿态估计在近年来受到广泛的关注,并已被运用于人机交互,运动分析,虚拟现实等任务中。3D人体姿态估计的方法主要分为两类:直接估计(Direct estimation)和 2D 到 3D (2D to 3D lifting) 。其中 2D 到 3D 的方法先利用 SOTA 2D 人体姿态估计算法得到 2D 关键点,再通过神经网络估计 3D 人体姿态。基于其优异的表现,2D 到 3D 已成为主流方法。与从单张图片中估计 3D 人体姿态相比,从视频中估计 3D 人体姿态能利用时序信息进行更准确的预测。然而主流方法大多利用时序卷积(Temporal convolutional network)来学习视频的时序信息,其表现往往受制于感受野的大小。得益于 self-attention 机制,Transformer 能捕捉长时序输入的内在关联,且不受制于其距离。受此启发,我们设计了一种不含卷积的时空 Transformer 的网络结构。针对多帧输入,其中 spatial transformer 能提取每帧 2D 骨架中的人体关节联系,temporal transformer 能捕捉多帧信息的时间相关性,最后输出中间帧的准确3D人体姿态。Spatial transformer module受视觉Transformer(ViT)的启发,对于每帧图片已得到的2D骨架作为输入,spatial transformer把该帧的每个关键点当做一个patch,通过patch embedding和spatial positional embedding得到的高维特征,送入spatial transformer encoder来提取关键点之间的人体关节联系。Temporal transformer module类似的,每一帧图片经过spatial transformer module 提取高维特征后,将被看做temporal transformer的一个Patch。经过temporal positional embedding加入时序信息后,temporal transformer encoder会捕捉多帧输入的时间相关性,最终得到包含整个输入的时空信息的特征。为了输出中间帧的3D人体姿态,本文使用一个加权平均的操作得到属于中间帧的特征,然后通过MLP和LayerNorm 得到最终的输出。本文在 Human3.6M 和 MPI-INF-3DHP 两个流行数据集上进行了试验,均得到最优结果。同时比较了在 Human3.6M 数据集下 3D 重建的视觉效果最后本文展示了在任意视频下的3D人体姿态估计的效果可以看到在户外,快速移动,高遮挡的情况下均能达到不错的效果。
视频解析:
更多的细节分析请见原文,代码已经开源,敬请关注加星,谢谢大家。
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看