
【NLP】从各大顶会看对比学习在句子表征研究进展
作者 | 上杉翔二
悠闲会 · 信息检索
整理 | NewBeeNLP
前已经有博文整理过了对比学习的概念,比较重要且流行的文章,和一些已经有的应用:
SimCSE
SimCSE: Simple Contrastive Learning of Sentence Embeddings paper: https://arxiv.org/abs/2104.08821 code: https://github.com/princeton-nlp/SimCSE
EMNLP2021,简单方法大能量,即仅将标准dropout用作噪声在对比目标中进行预测。
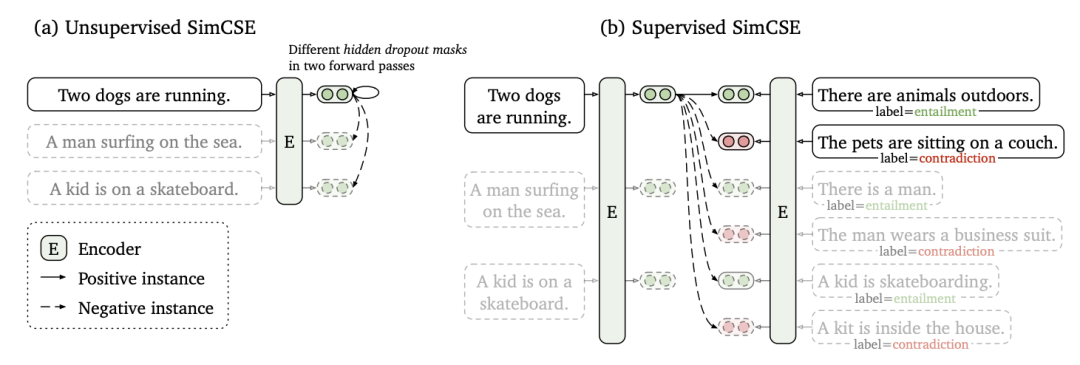
如上图,有两种形式:
unsupervised SimCSE。将相同的输入语句两次传递给经过预训练的编码器,并通过应用独立采样的dropout掩码获得两个嵌入,作为“正例对”。通过仔细的分析,作者们发现dropout本质上是作为数据扩充来使用,而删除它会导致表示崩溃。 supervised SimCSE。利用了基于自然语言推理(NLI)数据集进行句子嵌入学习,并将受监督的句子对纳入对比学习中。
可以来看看对比学习部分的代码实现:
def cl_forward(cls,...): #对比学习的部分代码
return_dict = return_dict if return_dict is not None else cls.config.use_return_dict
ori_input_ids = input_ids
batch_size = input_ids.size(0)
# Number of sentences in one instance
# 2: pair instance; 3: pair instance with a hard negative
num_sent = input_ids.size(1)
mlm_outputs = None
# Flatten input for encoding
input_ids = input_ids.view((-1, input_ids.size(-1))) # (bs * num_sent, len)
attention_mask = attention_mask.view((-1, attention_mask.size(-1))) # (bs * num_sent len)
if token_type_ids is not None:
token_type_ids = token_type_ids.view((-1, token_type_ids.size(-1))) # (bs * num_sent, len)
# Get raw embeddings,得到原句子特征
outputs = encoder(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=True if cls.model_args.pooler_type in ['avg_top2', 'avg_first_last'] else False,
return_dict=True,
)
# MLM auxiliary objective,执行MLM任务
if mlm_input_ids is not None:
mlm_input_ids = mlm_input_ids.view((-1, mlm_input_ids.size(-1)))
mlm_outputs = encoder( #得到特征
mlm_input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=True if cls.model_args.pooler_type in ['avg_top2', 'avg_first_last'] else False,
return_dict=True,
)
# Pooling,池化
pooler_output = cls.pooler(attention_mask, outputs)
pooler_output = pooler_output.view((batch_size, num_sent, pooler_output.size(-1))) # (bs, num_sent, hidden)
# If using "cls", we add an extra MLP layer
# (same as BERT's original implementation) over the representation.
if cls.pooler_type == "cls":
pooler_output = cls.mlp(pooler_output)
# Separate representation,分别得到两个表示z1,z2
z1, z2 = pooler_output[:,0], pooler_output[:,1]
cos_sim = cls.sim(z1.unsqueeze(1), z2.unsqueeze(0)) #计算对比loss
labels = torch.arange(cos_sim.size(0)).long().to(cls.device)
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(cos_sim, labels)
CLEAR
CLEAR: Contrastive Learning for Sentence Representation paper: https://arxiv.org/abs/2012.15466 code: no code
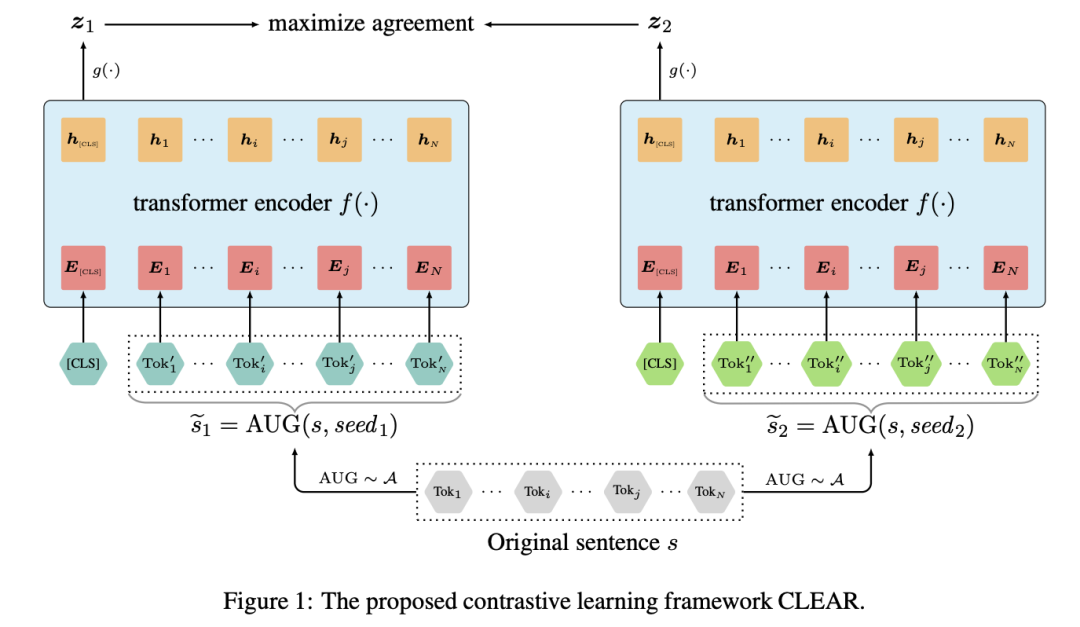
句子级别特征的抽取任务。CLEAR的模型结构和SimCLR类似。因此这篇文章主要是提出了四种数据增强构建负例句子的方法,词汇删除(Word deletion)、词段删除(Span deletion)、词序重排(Reordering)、同义词替换(Synonym Substitution)。如下图所示。
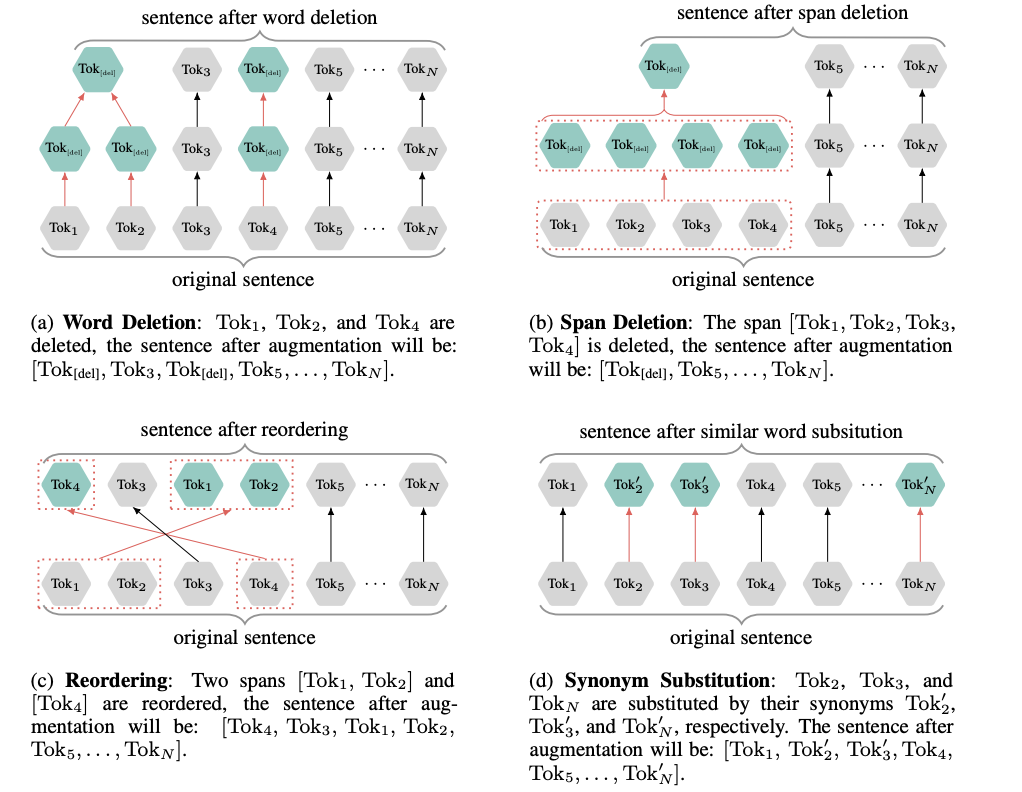
词汇删除即随机删除一些词汇作为负例句子,当连续的词被删除时,用一个[del]符号来表示,即句子最终变成[Tok[del], Tok3, Tok[del], Tok5, . . . , TokN] 词段删除是词汇删除的一个特例,其删除连续的某些词,即[Tok[del], Tok5, . . . , TokN] 词序重排和BART中的句子排序类似,替换句子中某些词对的顺序,变成[Tok4, Tok3, Tok1, Tok2, Tok5, . . . , TokN] 同义词替换则随机选择某些词汇并使用同义词进行替换作为负例句子,如[Tok1, Tok’2, Tok’3, Tok4, Tok5, . . . , Tok’N]。
其实构建的负例的方法会更多咯,可以参考一些自监督文章。
DeCLUTR
DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations paper: https://aclanthology.org/2021.acl-long.72/ code: https://github.com/JohnGiorgi/DeCLUTR
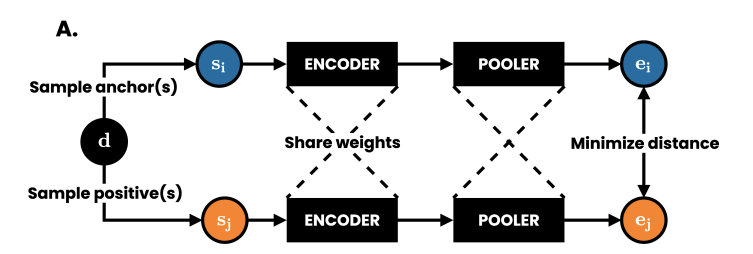
ACL2021,无监督句子级别的特征提取。其实也是探讨如何构建负例,这篇文章的架构如上图,使用对比学习的方法拉近相同文章中句子embedding之间的距离,拉远不同文章之间句子embedding之间的距离。
具体的做法是通过从同一文档中的其他部分采样文本段,并通过对抗loss来最大化上下文段落span的相似性,以学习句子的上下表示。
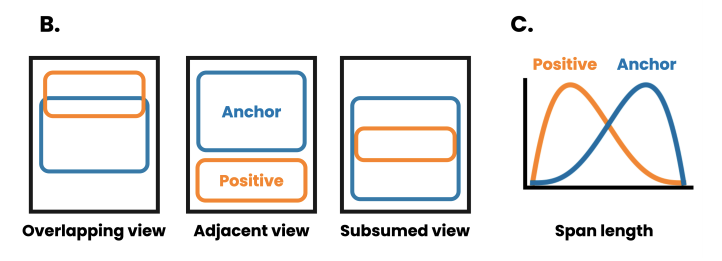
如下图,将三种类型的正例:部分与锚点重叠,与锚点相邻,以及包含于锚点中。两种类型的负例:来自于其他文档的易负例,来自于同一文档的难负例。
DiffCSE
DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings paper:https://arxiv.org/pdf/2204.10298.pdf code:https://github.com/voidism/DiffCSE
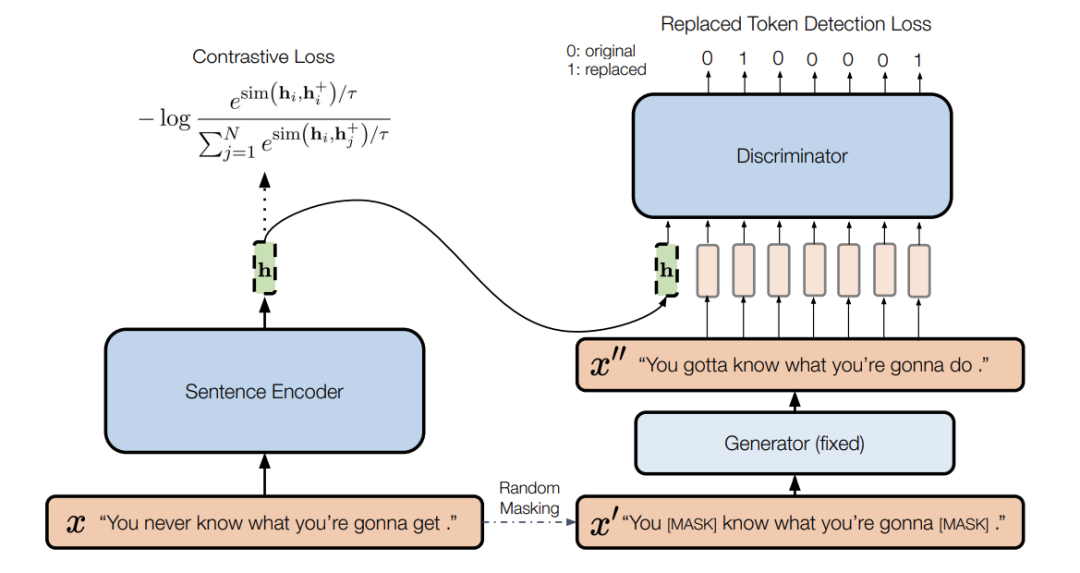
来自NAACL2022,主要基于dropout masks作为数据增强策略,作为不敏感转换学习对比学习损失和基于MLM语言模型进行词语替换的方法作为敏感转换学习,即原始句子与编辑句子之间的差异,共同优化句向量表征。
模型架构图如上,左侧为一个标准的SimCSE模型,右侧为一个带条件的句子差异预测模型。左侧不再赘述,右侧包含生成器和判别器。
生成器。给定一个长度为T的句子,MLM预训练语言模型作为生成器G,通过掩码序列来生成句子中被掩掉的token,获取生成序列。 判别器。判别器进行替换token检测,也就是预测哪些token是被替换的。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码:
评论