
干货|对比理解不同概率估计和模型损失函数
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

来源:知乎,张小磊
我们这有一个任务,就是根据已知的一堆数据样本,来推测产生该数据的模型的参数,即已知数据,推测模型和参数。因此根据两大派别的不同,对于模型的参数估计方法也有两类:极大似然估计与最大后验概率估计。
① 极大似然估计(MLE)
-她是频率学派模型参数估计的常用方法。
-顾名思义:似然,可以简单理解为概率、可能性,也就是说要最大化该事件发生的可能性
-她的含义是根据已知样本,希望通过调整模型参数来使得模型能够最大化样本情况出现的概率。
- 在这举个猜黑球的例子:假如一个盒子里面有红黑共10个球,每次有放回的取出,取了10次,结果为7次黑球,3次红球。问拿出黑球的概率  是多少?
是多少?
我们假设7次黑球,3次红球为事件
 ,一个理所当然的想法就是既然事件 已经发生了,那么事件 发生的概率应该最大。所以既然事件 的结果已定, 我们就有理由相信这不是一个偶然发生的事件,这个已发生的事件肯定一定程度上反映了黑球在整体中的比例。所以我们要让模型产生这个整体事件的概率最大,我们把这十次抽取看成一个整体事件 ,很明显事件 发生的概率是每个子事件概率之积。我们把
,一个理所当然的想法就是既然事件 已经发生了,那么事件 发生的概率应该最大。所以既然事件 的结果已定, 我们就有理由相信这不是一个偶然发生的事件,这个已发生的事件肯定一定程度上反映了黑球在整体中的比例。所以我们要让模型产生这个整体事件的概率最大,我们把这十次抽取看成一个整体事件 ,很明显事件 发生的概率是每个子事件概率之积。我们把  看成一个关于 的函数,求 取最大值时的 ,这就是极大似然估计的思想。具体公式化描述为
看成一个关于 的函数,求 取最大值时的 ,这就是极大似然估计的思想。具体公式化描述为
接下来就是取对数转换为累加,然后通过求导令式子为0来求极值,求出p的结果。

② 最大后验概率估计(MAP)
-她是贝叶斯派模型参数估计的常用方法。
-顾名思义:就是最大化在给定数据样本的情况下模型参数的后验概率
-她依然是根据已知样本,来通过调整模型参数使得模型能够产生该数据样本的概率最大,只不过对于模型参数有了一个先验假设,即模型参数可能满足某种分布,不再一味地依赖数据样例(万一数据量少或者数据不靠谱呢)。
-在这里举个掷硬币的例子:抛一枚硬币10次,有10次正面朝上,0次反面朝上。问正面朝上的概率  。
。
在频率学派来看,利用极大似然估计可以得到
 10 / 10 = 1.0。显然当缺乏数据时MLE可能会产生严重的偏差。
10 / 10 = 1.0。显然当缺乏数据时MLE可能会产生严重的偏差。如果我们利用极大后验概率估计来看这件事,先验认为大概率下这个硬币是均匀的 (例如最大值取在0.5处的Beta分布),那么
 ,是一个分布,最大值会介于0.5~1之间,而不是武断的给出= 1。
,是一个分布,最大值会介于0.5~1之间,而不是武断的给出= 1。显然,随着数据量的增加,参数分布会更倾向于向数据靠拢,先验假设的影响会越来越小
经验风险最小化与结构风险最小化是对于损失函数而言的。可以说经验风险最小化只侧重训练数据集上的损失降到最低;而结构风险最小化是在经验风险最小化的基础上约束模型的复杂度,使其在训练数据集的损失降到最低的同时,模型不至于过于复杂,相当于在损失函数上增加了正则项,防止模型出现过拟合状态。这一点也符合奥卡姆剃刀原则:如无必要,勿增实体。
经验风险最小化可以看作是采用了极大似然的参数评估方法,更侧重从数据中学习模型的潜在参数,而且是只看重数据样本本身。这样在数据样本缺失的情况下,很容易管中窥豹,模型发生过拟合的状态;结构风险最小化采用了最大后验概率估计的思想来推测模型参数,不仅仅是依赖数据,还依靠模型参数的先验假设。这样在数据样本不是很充分的情况下,我们可以通过模型参数的先验假设,辅助以数据样本,做到尽可能的还原真实模型分布。
① 经验风险最小化
-MLE她是经验风险最小化的例子。当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化就等价于极大似然估计。在这里举个逻辑回归(LR)的例子,更多跟LR有联系的模型可参看拙作由Logistic Regression所联想到的...。
对于二分类的逻辑回归来说,我们试图把所有数据正确分类,要么0,要么1。
通过累乘每个数据样例来模拟模型产生数据的过程,并且最大化
 。
。我们需要通过取对数来实现概率之积转为概率之和
 。
。我们可以根据数据标签的0、1特性来把上式改为

-这样,我们通过极大似然来推导出了逻辑回归的损失函数,同时极大似然是经验风险最小化的一个特例。
② 结构风险最小化
-MAP她是结构风险最小化的例子。当模型是条件概率分布、损失函数是对数损失函数、模型复杂度由模型的先验概率表示时,结构风险最小化就等价于最大后验概率估计。在这里举个推荐系统中的概率矩阵分解(PMF)的例子。
先说下矩阵分解的原理:推荐系统的评分预测场景可看做是一个矩阵补全的游戏,矩阵补全是推荐系统的任务,矩阵分解是其达到目的的手段。因此,矩阵分解是为了更好的完成矩阵补全任务(欲其补全,先其分解之)。之所以可以利用矩阵分解来完成矩阵补全的操作,那是因为基于这样的假设-假设UI矩阵是低秩的,即在大千世界中,总会存在相似的人或物,即物以类聚,人以群分,然后我们可以利用两个小矩阵相乘来还原评分大矩阵。
它假设评分矩阵中的元素
 是由用户潜在偏好向量
是由用户潜在偏好向量 和物品潜在属性向量
和物品潜在属性向量 的内积决定的,并且服从均值为
的内积决定的,并且服从均值为 ,方差为
,方差为 的正态分布:
的正态分布:  。
。则观测到的评分矩阵条件概率为:
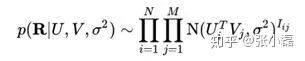
同时,假设用户偏好向量与物品偏好向量服从于均值都为0,方差分别为
 ,
, 的正态分布:
的正态分布:
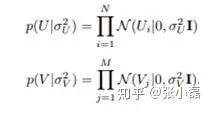
根据最大后验概率估计,可以得出隐变量
 的后验概率为:
的后验概率为:
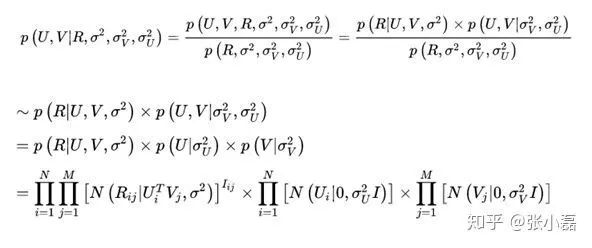
接着,等式两边取对数
 ,并且将正态分布展开后得到:
,并且将正态分布展开后得到:
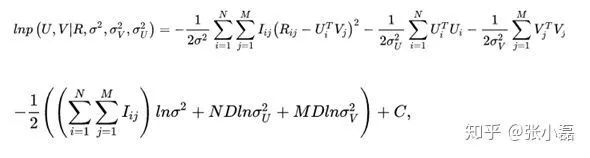
-这样,我们通过最大后验概率估计推导出了概率矩阵分解的损失函数。可以看出结构风险最小化是在经验风险最小化的基础上增加了模型参数的先验。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~