
深入理解计算机视觉中的损失函数
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
损失函数在模型的性能中起着关键作用。选择正确的损失函数可以帮助你的模型学习如何将注意力集中在数据中的正确特征集合上,从而获得最优和更快的收敛。
计算机视觉是计算机科学的一个领域,主要研究从数字图像中自动提取信息。
Pixel-wise损失函数
类不平衡是像素级分类任务中常见的问题。当图像数据中的各种类不平衡时,就会出现这种情况。由于像素方面的损失是所有像素损失的平均值,因此训练会被分布最多的类来主导。
Perceptual损失函数
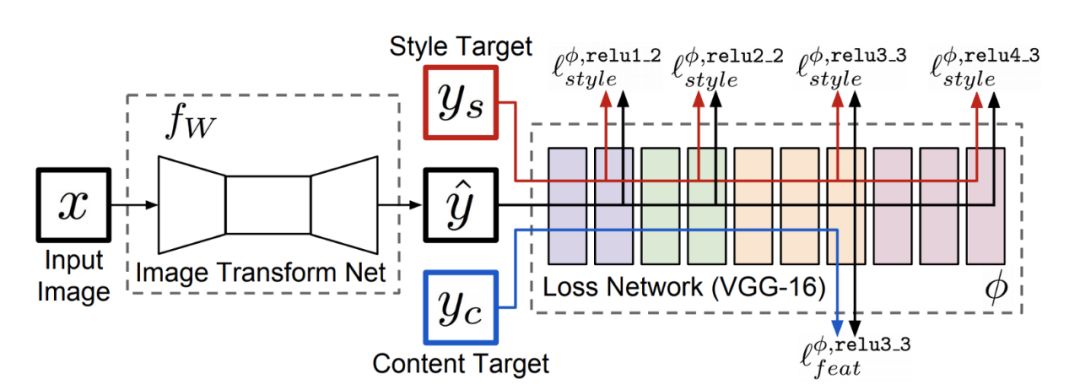
Perceptual损失的数学表示
其中,表示VGG网络第j层在处理图像Y时的激活情况,其形状为。我们使用L2损失的平方,根据图像的形状归一化,比较了ground truth图像Y和预测图像Y^的激活情况。
如果你想使用VGG网络的多个特征映射作为你的损失计算的一部分,只需为多个添加值。
内容-风格损失函数—神经网络风格转换

风格转换是将图像的语义内容转换成不同风格的过程。风格转换模型的目标是,给定一个内容图像(C)和一个风格图像(S),生成包含C的内容和S的风格的输出图像。
内容/风格损失的数学表示
注意:只有减少样式和内容损失的优化会导致高像素化和噪声输出。为了解决这个问题,我们引入了total variation loss来保证生成的图像的空间连续性和平滑性。
纹理损失
纹理损失的数学表示
网络的纹理损失是所有纹理损失的加权和,表示为:
这里a是原始图像,x是预测图像。
注意:虽然这里的数学看起来有点复杂,但请理解纹理损失只是应用在特征图的gram矩阵上的感知损失。
拓扑感知损失函数
拓扑感知损失的数学表示
对比损失/三元组损失
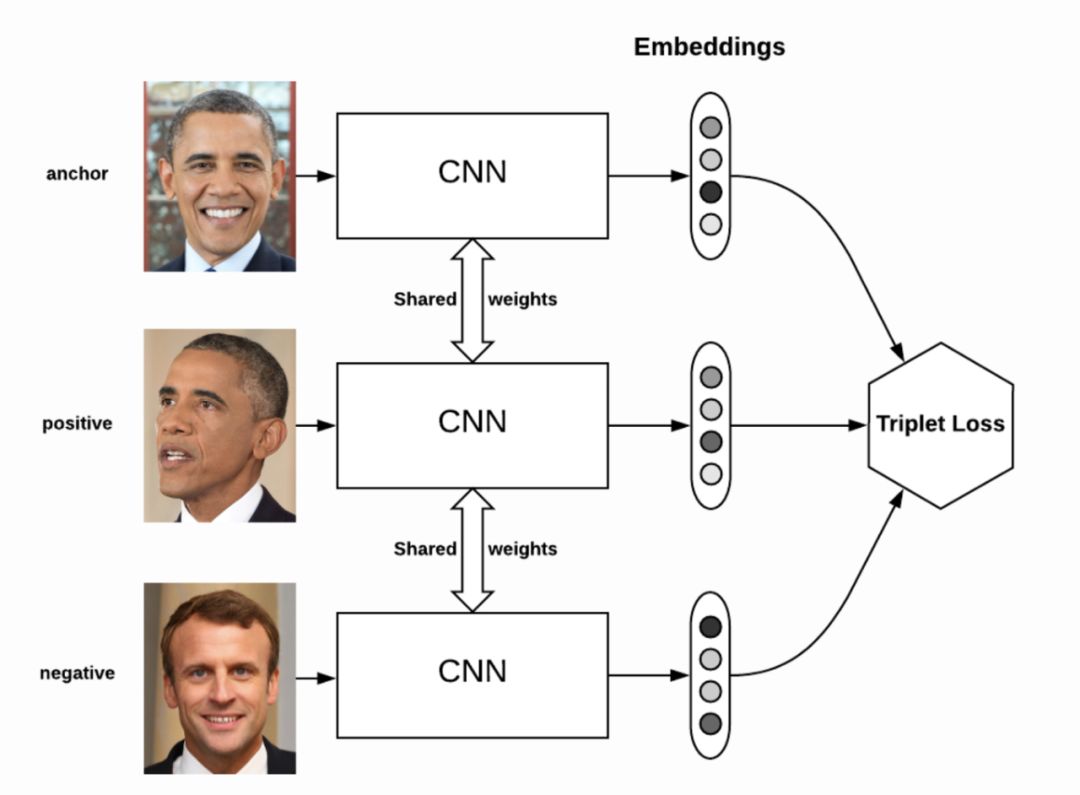
重申一下,Siamese网络的目标是确保一个特定的人的图像(锚点)与同一个人的所有其他图像(positive)的距离要比与任何其他人的图像(negative)的距离更近。
定义距离度量d=L2范数 计算anchor图像与positive图像的嵌入距离=d(a, p) 计算anchor图像嵌入到negative图像的距离=d(a, n) 三元组损失= d(a, p) - d(a, n) + offset
三元组的数学表示
GAN损失
由Ian Goodfellow等人(https://arxiv.org/abs/1406.2661)(2014)首先提出的生成式对抗网络是目前最流行的图像生成任务解决方案。GANs的灵感来自博弈论,并使用一个对抗的方案,使它可以用无监督的方式训练。
1. Min-Max损失函数
2. 不饱和的GAN损失
3. 最小均方GAN损失
4. Wasserstein GAN损失
5. 循环一致性损失

图像到图像的转换是一个图像合成的任务,需要对给定的图像进行有控制的修改,生成一个新的图像。例如,把马转换成斑马(或反过来),把绘画转换成照片(或反过来),等等。
循环一致性是指第一个生成器输出的图像可以用作第二个生成器的输入,而第二个生成器的输出应该与原始图像匹配。反之亦然。
下载1:OpenCV黑魔法
在「AI算法与图像处理」公众号后台回复:OpenCV黑魔法,即可下载小编精心编写整理的计算机视觉趣味实战教程
下载2 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得有趣就点亮在看吧

评论