编辑:小咸鱼
GitHub上,有一位小哥放出了「2021年充满惊喜的人工智能论文综述」这个项目。目前,里面总结了33篇今年必看论文,堪称「良心宝藏」。这个项目仍在更新中,收藏一波,继续追更!
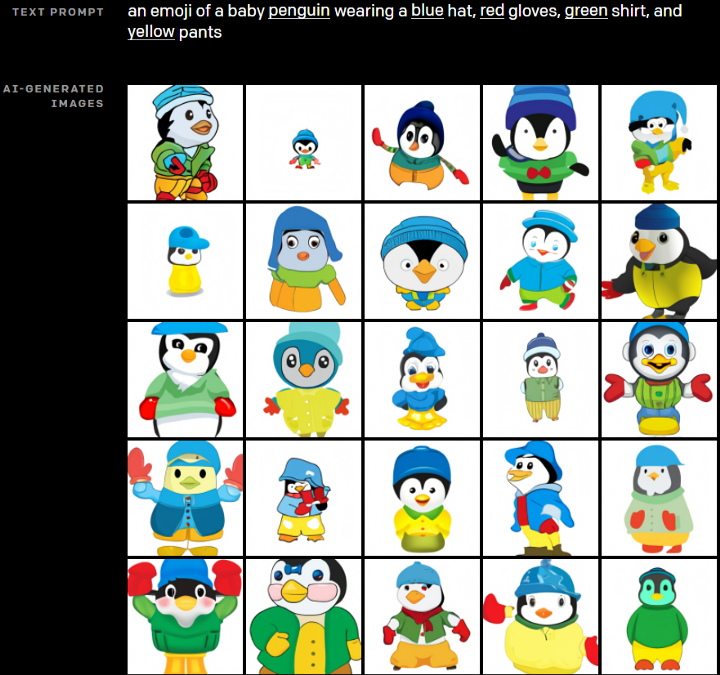
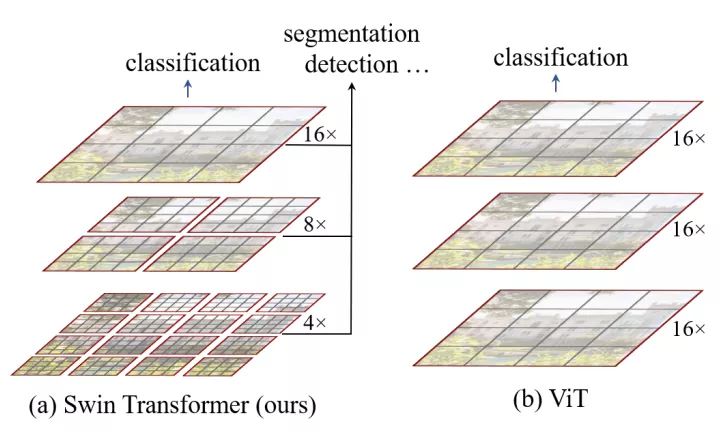
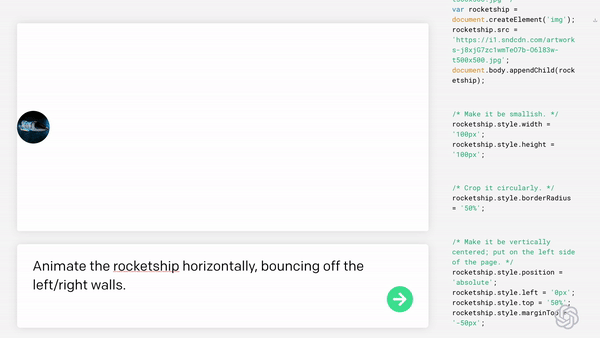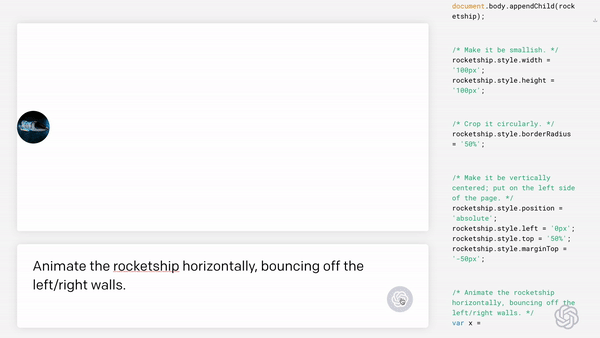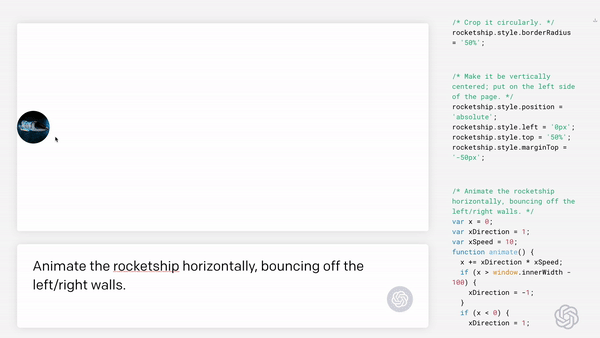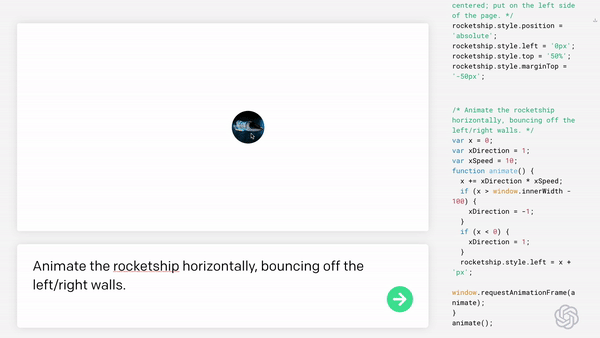
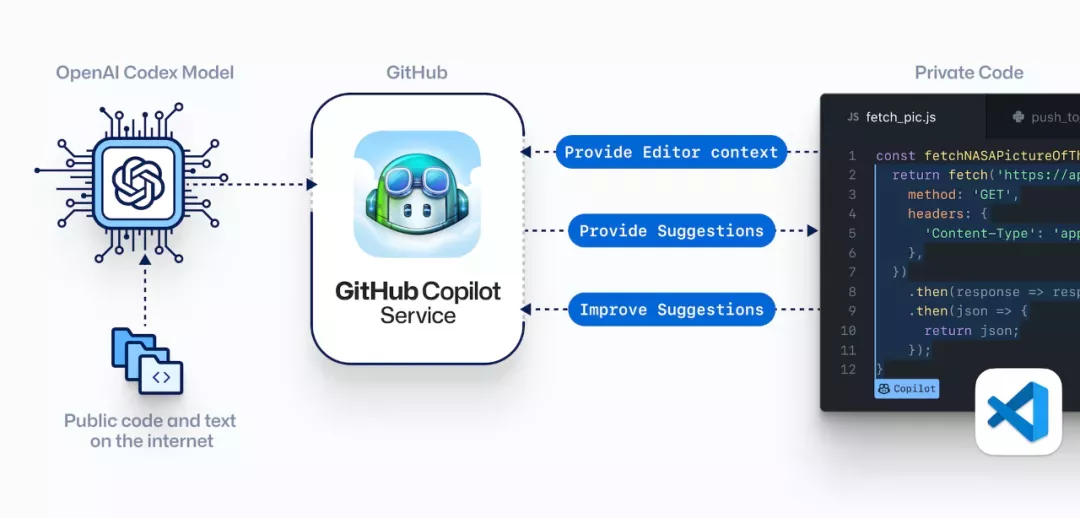
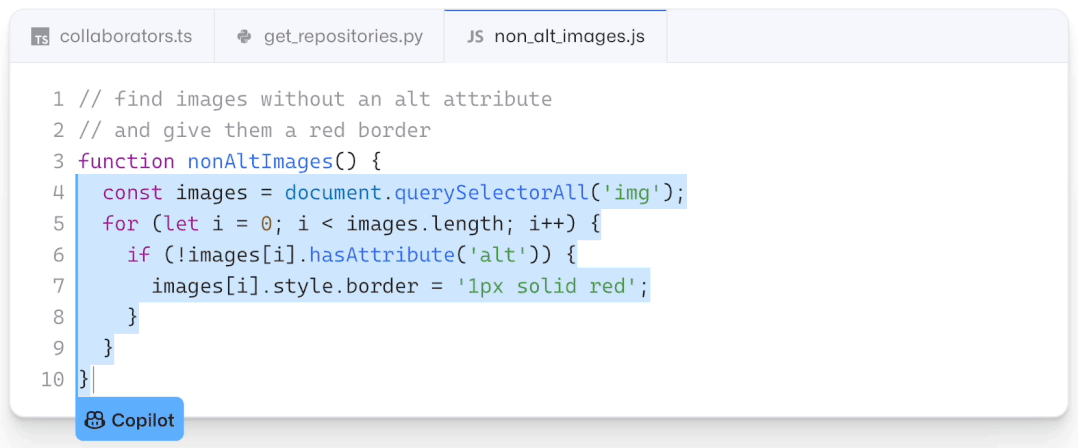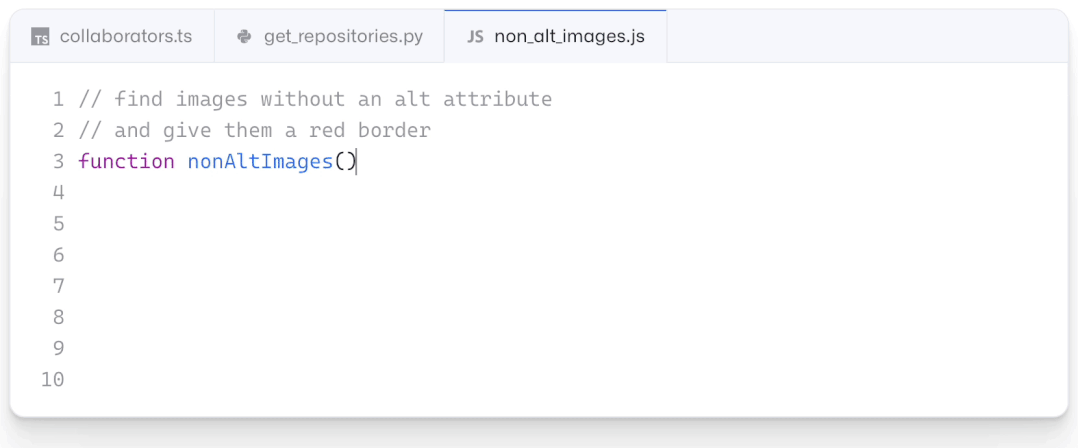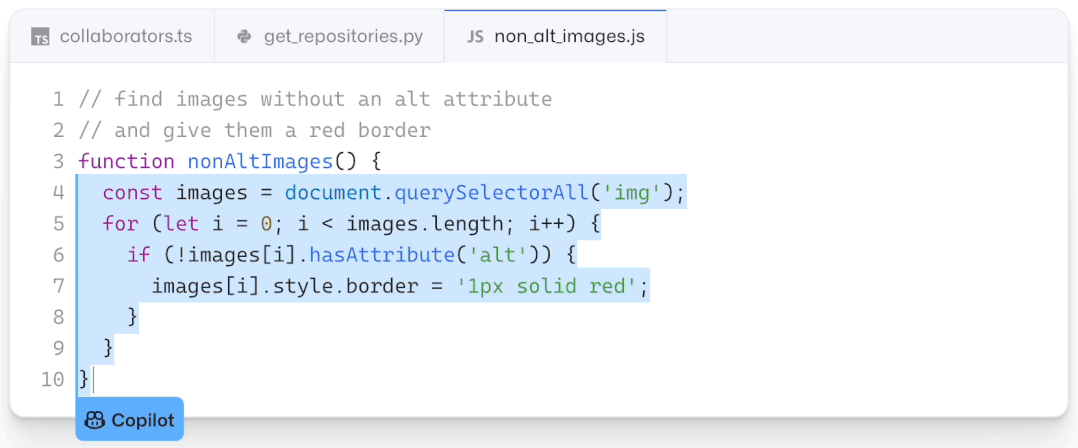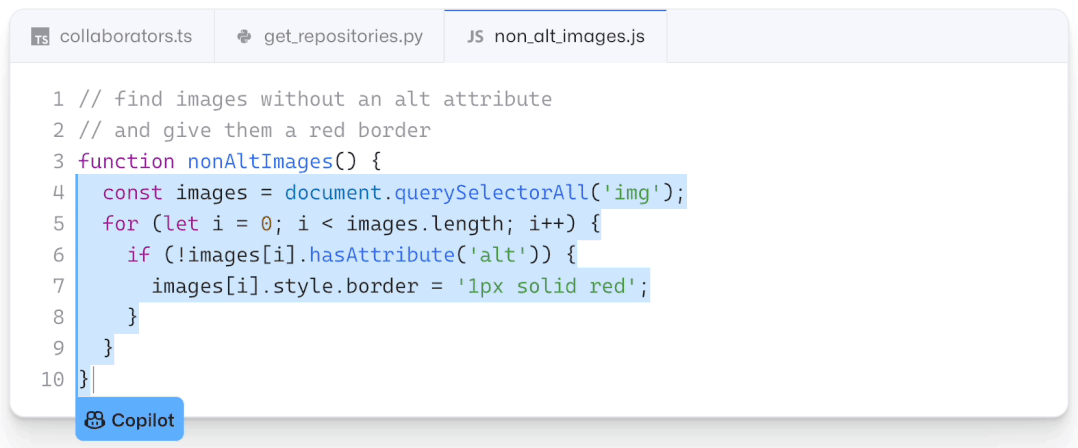
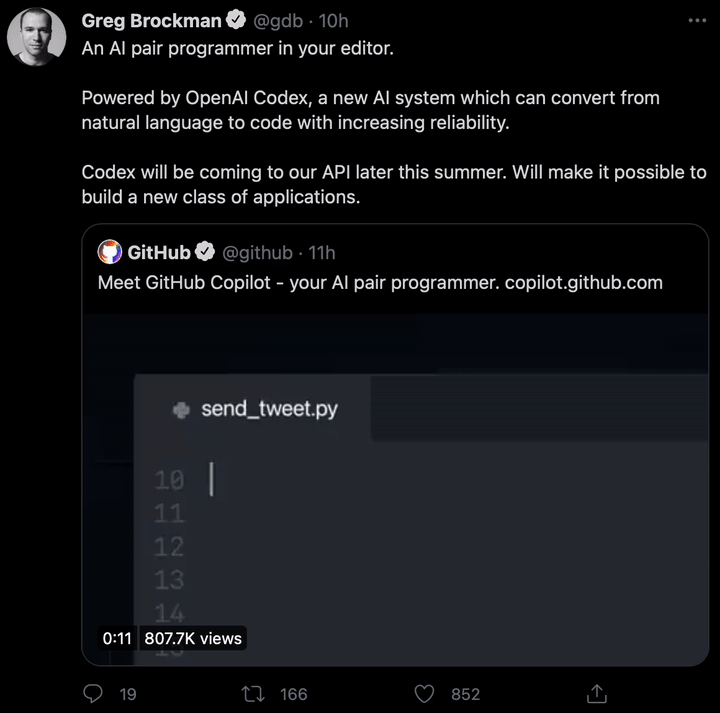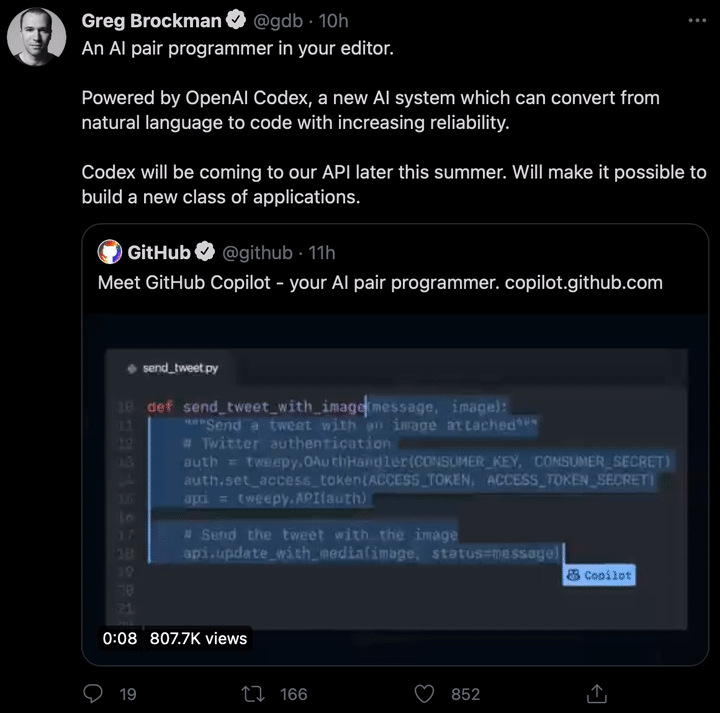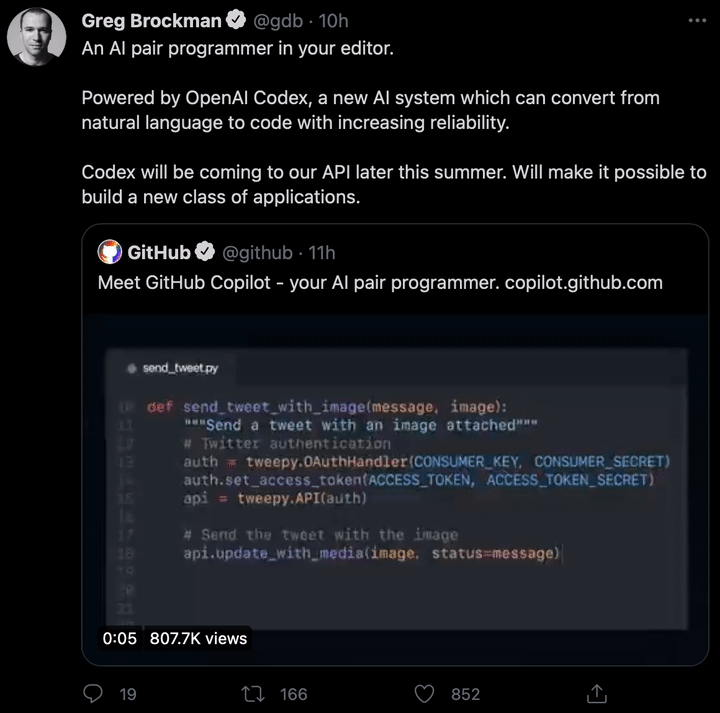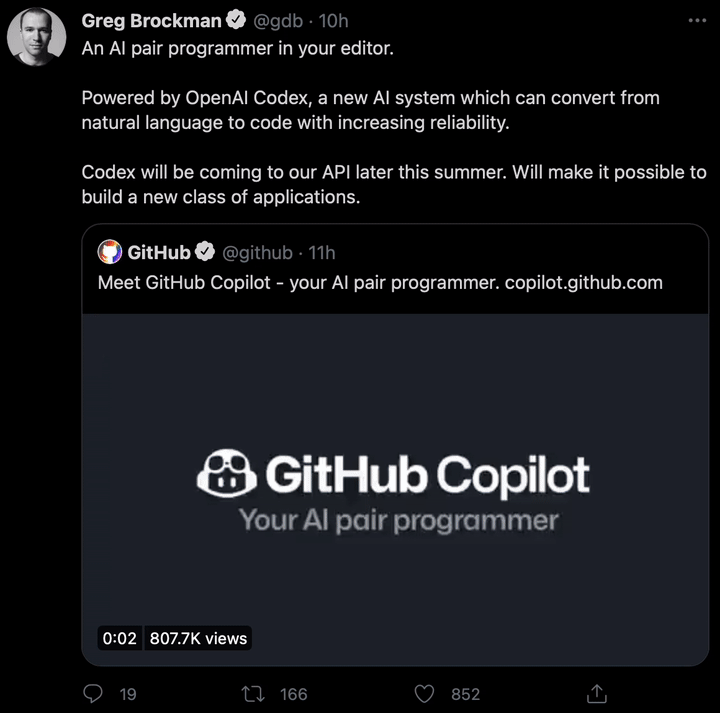
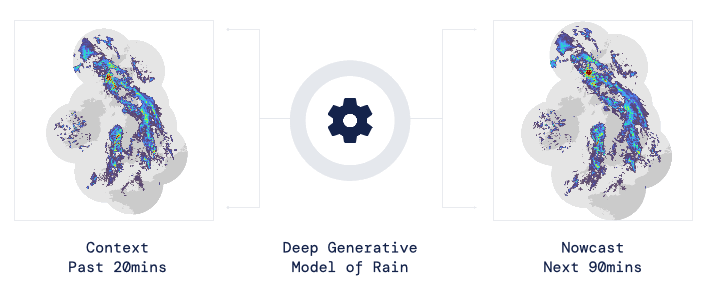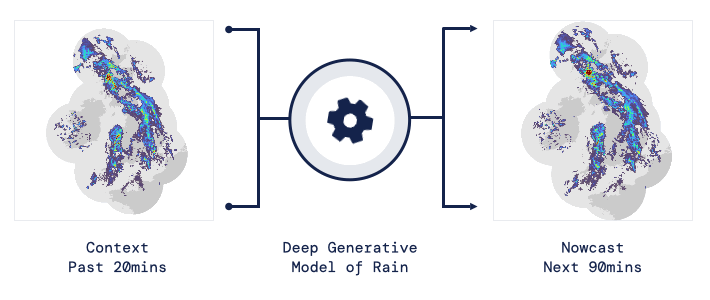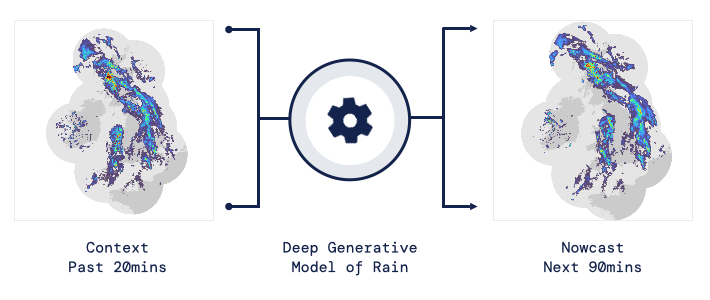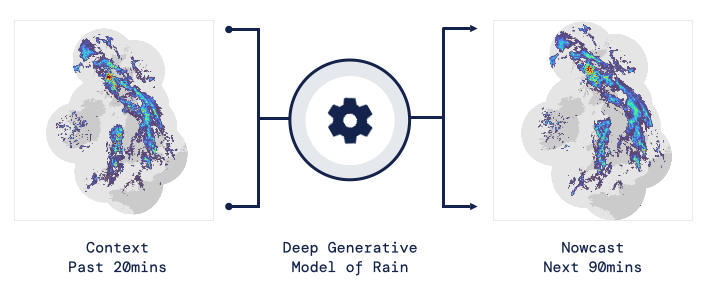
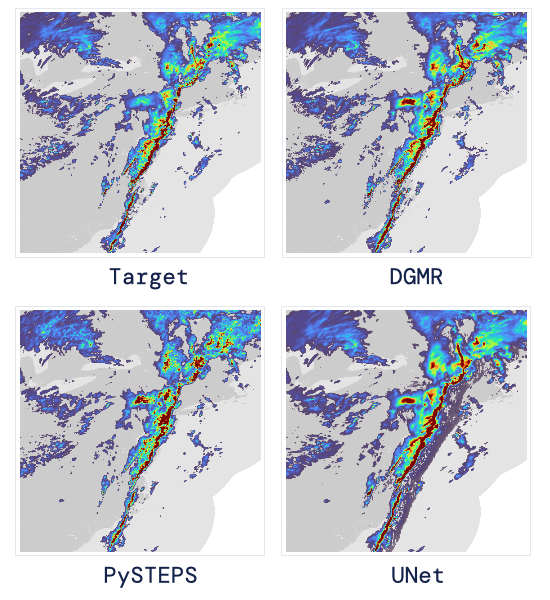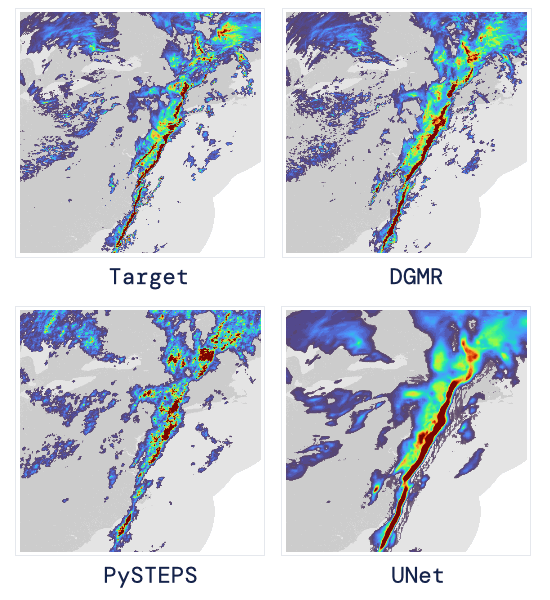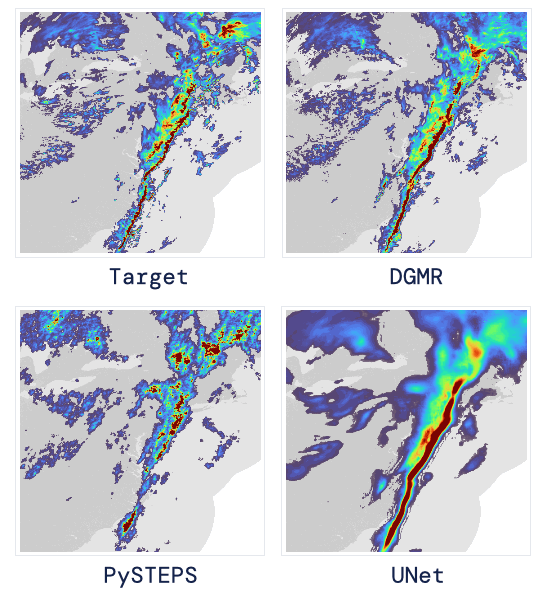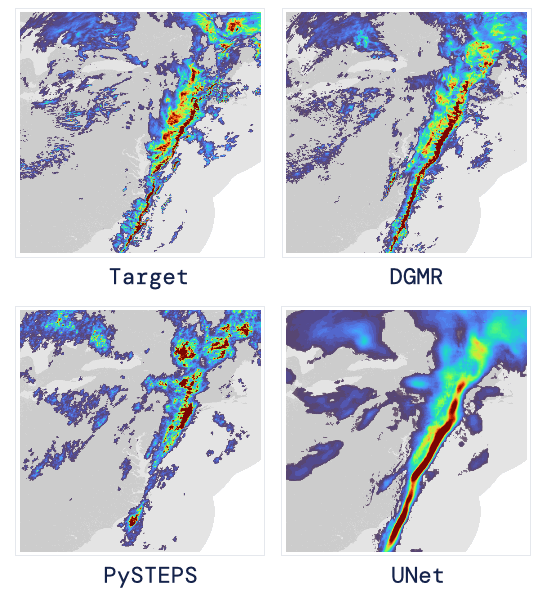
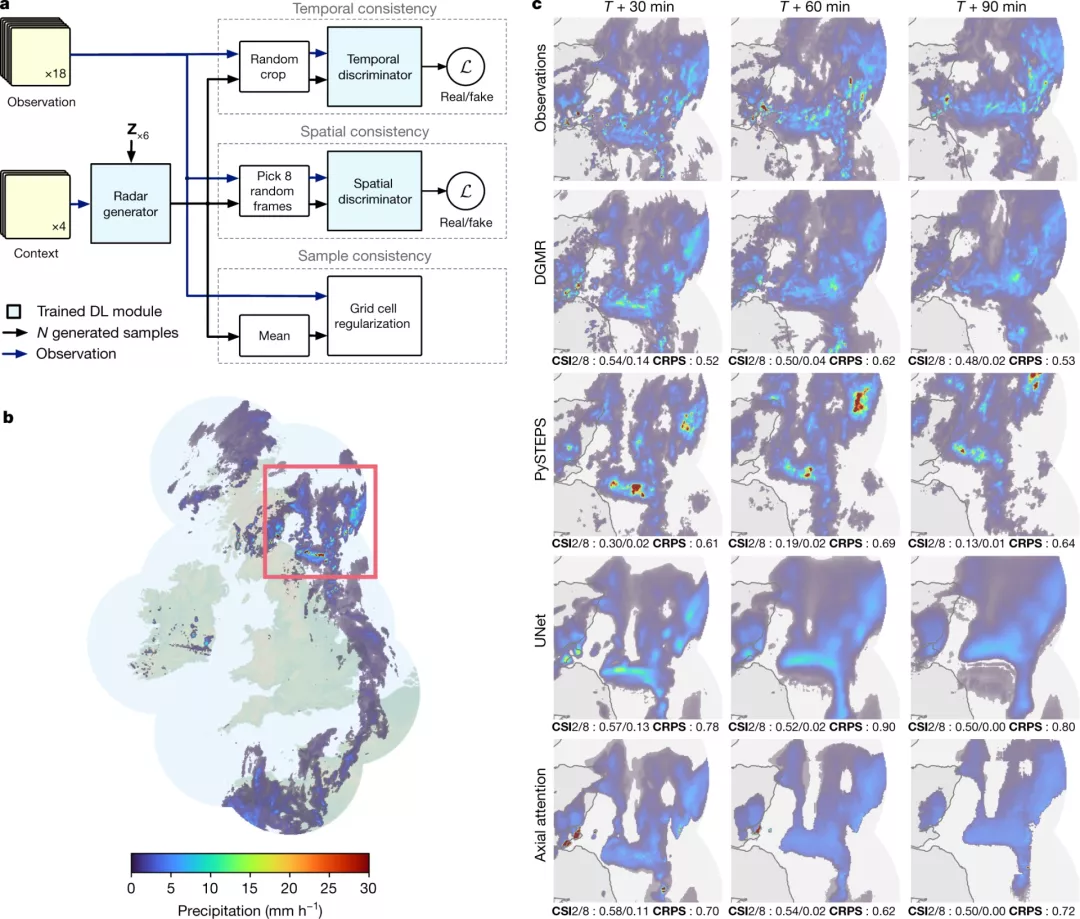
现如今,AI技术突飞猛进,每年都会诞生很多优秀的论文。想知道2021年有哪些paper是你不能错过的吗?这不,在GitHub上,有一位小哥放出了这样一个项目,目前,里面总结了33篇今年必看论文,堪称「良心宝藏」。https://github.com/louisfb01/best_AI_papers_2021这个项目的名称是「2021年充满惊喜的人工智能论文综述」,作者是Louis-François Bouchard(GitHub名为louisfb01),上线一天就收获314个star(持续上涨中)。Louis-François Bouchard来自加拿大蒙特利尔,我目前在École de Technologie Supérieure攻读人工智能-计算机视觉硕士学位,同时在designstripe兼职做首席人工智能研究科学家。值得一提的是,Louis还在YouTube上有自己的频道「What's AI」。What's AI主页:https://www.louisbouchard.ai/Louis之所以在YouTube上做「What's AI」这个频道,是希望用简单的语言分享和解释人工智能,为大家分享新的研究和应用。YouTube What's AI 频道:https://www.youtube.com/c/WhatsAI/featuredLouis想为所有人揭开人工智能「黑匣子」的神秘面纱,让人们意识到使用它的风险。Louis是一个很有分享精神的人,喜欢学习和分享他所学到的东西。他写了不少文章,也在自己的频道更新视频,在GitHub上也正在做一些有趣的项目。其实,「2021年充满惊喜的AI论文综述」已经是Louis更新「AI论文综述」系列的第二年了。在2020年,Louis也上线了「2020年充满惊喜的AI论文综述」项目,里面是按发布日期排列的AI最新突破的精选列表,带有清晰的视频解释,更深入文章的链接和源代码。https://github.com/louisfb01/Best_AI_paper_2020下面,就来看看「2021年充满惊喜的AI论文综述」里面到底有哪些让人惊喜的AI最新研究成果吧!尽管世界仍在慢慢复苏,但研究并没有放缓其步伐,尤其是在人工智能领域。此外,2021年还强调了许多重要的方面,如道德方面、重视偏见、治理、透明度等等。人工智能和我们对人脑的理解及其与AI的联系正在不断发展,在不久的将来,也许有希望改善我们的生活质量。1、DALL-E:Zero-Shot Text-to-Image Generation,来自OpenAI论文地址:https://arxiv.org/pdf/2102.12092.pdf一个Emoji的小企鹅,带着蓝帽子,红手套,穿着黄裤子示例GPT-3表明,语言可以用来指导大型神经网络执行各种文本生成任务。而Image GPT表明,同样类型的神经网络也可以用来生成高保真度的图像。这个突破说明通过文字语言来操纵视觉概念现在已经触手可及。OpenAI成功地训练了一个能够从文本标题生成图像的网络。它非常类似于GPT-3和Image GPT,并产生了惊人的结果。和GPT-3一样,DALL-E也是一个Transformer语言模型。它同时接收文本和图像作为单一数据流,其中包含多达1280个token,并使用最大似然估计来进行训练,以一个接一个地生成所有的token。这个训练过程不仅允许DALL-E可以从头开始生成图像,而且还可以重新生成现有图像的任何矩形区域,与文本提示内容基本一致。2、Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows论文地址:https://arxiv.org/pdf/2103.14030.pdf这篇文章介绍了一种新的、可以应用于计算机视觉里的Transformer,Swin Transformer。Transformer解决计算机视觉问题的挑战主要来自两个领域:图像的比例差异很大,而且图像具有很高的分辨率,在有些视觉任务和如语义分割中,像素级的密集预测对于Transformer来说是难以处理的,因为其self-attention的计算复杂度与图像大小成二次关系。为了克服这些问题,Swin Transformer构建了分层Transformer特征图,并采用移位窗口计算。移位窗口方案通过将self-attention计算限制在不重叠的局部窗口(用红色标出),同时还允许跨窗口连接,带来了更高的效率。Swin Transformer通过从小尺寸的面片(用灰色勾勒)开始,并逐渐合并更深的Transformer层中的相邻面片来构建分层表示。这种分层体系结构可以灵活地在各种尺度上建模,并且在图像大小方面具有线性计算复杂度。线性计算复杂度是通过在分割图像的非重叠窗口(用红色标出)内局部计算自我注意来实现的。 每个窗口中的面片数量是固定的,因此复杂度与图像大小成线性关系。Swin Transformer在图像分类、目标检测和语义分割等识别任务上取得了很好的性能,在三个任务中,Swin Transformer的时间延迟与ViT,DeiT和ResNeXt模型相似,但性能却得到了大幅提升:COCO test-dev 58.7 box AP和51.1 mask AP,力压之前的最先进结果2.7 box AP和2.6 mask AP。 在ADE20K语义分割任务中,Swin Transformer在验证集上获得了53.5 mIoU,比以前的最先进水平(SETR)提高了3.2 mIoU。 在ImageNet-1K图像分类中,它也达到了87.3%的最高精度,充分展现Transformer模型作为新视觉backbone的潜力。该论文一作刘泽是中科大的学生,在微软亚洲研究院实习。他于2019年获中国科技大学学士学位,并以最高荣誉获得郭沫若奖学金。个人主页介绍,其2篇论文和1篇Oral被ICCV2021接收。个人主页:https://zeliu98.github.io/3、StyleCLIP: Text-driven manipulation of StyleGAN imagery论文地址:https://arxiv.org/pdf/2103.17249.pdf这是一项来自以色列的研究人员的工作StyleCLIP,可以使用基于人工智能的生成对抗性网络对照片进行超逼真的修改,并且只需要让用户输入他们想要的东西的描述即可,无需输入特定的图片。这个模型也会产生一些非常搞笑的结果。例如可以给Facebook 的CEO马克 · 扎克伯格的脸随意修改,例如让他看起来秃顶,戴上眼镜,或者在下巴上扎上山羊胡。StyleCLIP模型主要由StyleGAN和CLIP模型组成。StyleGAN可以在不同领域(domain)生成高度真实图像,最近也有大量的工作都集中在理解如何使用StyleGAN的隐空间来处理生成的和真实的图像。但发现语义上潜在有意义的操作通常需要对多个自由度进行细致的检查,这需要耗费大量的人工操作,或者需要为每个期望的风格创建一个带注释的图像集合。既然基于注释,那多模态模型CLIP(Contrastive Language-Image Pre-training)的能力是否就可以利用上,来开发一个不需要手动操作的基于文本的StyleGAN图像处理。例如输入可爱的猫(cute cat),眯眼睛的猫就被放大了眼睛,获取了所有可爱小猫的特征,还可以老虎变狮子等等。4、GitHub Copilot & Codex: Evaluating Large Language Models Trained on Code论文地址:https://arxiv.org/pdf/2107.03374.pdfOpenAI在2020年,曾推出1750亿参数的GPT-3,参数规模直逼人类神经元的数量。GPT-3使用了在2019年之前的互联网上的几乎所有公开的书面文本进行训练,所以它对于自然语言是有一定理解能力的,能作诗、聊天、生成文本等等。Codex基于GPT-3进行训练,接受了从GitHub中提取的TB级公开代码以及英语语言示例的训练。只要你对Codex发号施令,它就会将英语翻译成代码。随后,你的双手离开键盘,Codex会自动编程,火箭就自己动起来了。而Copilot正是建立在OpenAI强大的Codex算法之上,获得了「海纳百川」的代码积累和前所未有的代码生产能力。Copilot不仅仅可以模仿它见过的代码,而且还会分析利用函数名、方法名、类名和注释的上下文来生成和合成代码,为开发人员提供编辑器中整行代码或函数的建议。它能减少工程师通过API文档做苦工的时间,还能帮忙编写测试代码。5、Skillful Precipitation Nowcasting using Deep Generative Models of Radar论文地址:https://www.nature.com/articles/s41586-021-03854-z今天的天气预测是由强大的数值天气预报(NWP)系统驱动的。通过解决物理方程,数值天气预报系统可以提前数天得到地球尺度的预测。然而,它们很难在两小时内产生高分辨率的预测。即时预报填补了这一关键时间区间的性能空白。气象传感的进步使高分辨率雷达可以高频地(在1公里分辨率下每5分钟)提供测量出的地面降水量数据。过去20分钟的观测雷达被用来提供未来90分钟的概率预测已有的短期预测方法,如STEPS和PySTEPS,沿用NWP的方法来考虑不确定性,但按照带有雷达信息的平流方程对降水进行建模。基于深度学习的方法则不需要对平流方程的依赖,但现有方法侧重于特定地点的预测,而不是对整个降水场的概率预测,这使其无法在多个空间和时间集合中同时提供一致的预测结果,限制了实用性。为此,DeepMind使用深度生成模型(DGMR)为概率预报开发了一种观测驱动的方法。DGMR是学习数据概率分布的统计模型,可以从学习到的分布中轻松生成样本。由于生成模型从根本上是概率性的,可以从给定的历史雷达的条件分布中模拟许多样本,生成预测集合。此外,DGMR既能从观测数据中学习,又能表示多个空间和时间尺度上的不确定性。结果表明,DeepMind的深度生成模型可以提供更好的预测质量、预测一致性和预测价值。模型在1,536公里×1,280公里的区域内产生了逼真且时空一致的预测,提前期为5-90分钟。 DGMR能更好地预测较长时段的空间覆盖和对流,同时不会高估强度通过50多位气象专家的系统评估,与其他两种竞争方法相比,DeepMind的生成模型以89%的绝对优势在准确性和实用性两方面排名第一。其他有意思的论文都可以在Louis的GitHub主页上找到,目前这个项目仍在更新中,收藏一波,继续追更!
参考资料:
https://github.com/louisfb01/best_AI_papers_2021
长按或扫描下方二维码,后台回复:加群,可申请入群。一定要备注:入群+地点+学习/公司。例如:入群+上海+复旦。
感谢你的分享,点赞,在看三连