一键爬取基金历年季度报数据,轻松搞定!附源码
点击“简说Python”,选择“置顶/星标公众号”
福利干货,第一时间送达!

大家好,我是老表
今天分享一篇爬取基金季度报告的文章,比之前爬取基金数据可视化文章含“金”量更高。
爬虫的整体思路比较简单,代码量甚至都没有基金分析那篇的多,很适合入门的朋友参考学习
另外,这篇文章可能介绍的比较细,大家酌情加速阅读
注:文末可获取本节所有源码
正文
目标:通过天天基金网爬取基金历史季度报告,下载对应的季度报告到本地 pdf 文件
首先,登录天天基金网,进入基金季度报告页面
我这里直接选近一年收益率最高的基金为对象:创金合信工业周期股票A,基金代码:005968
报告页面长这样:
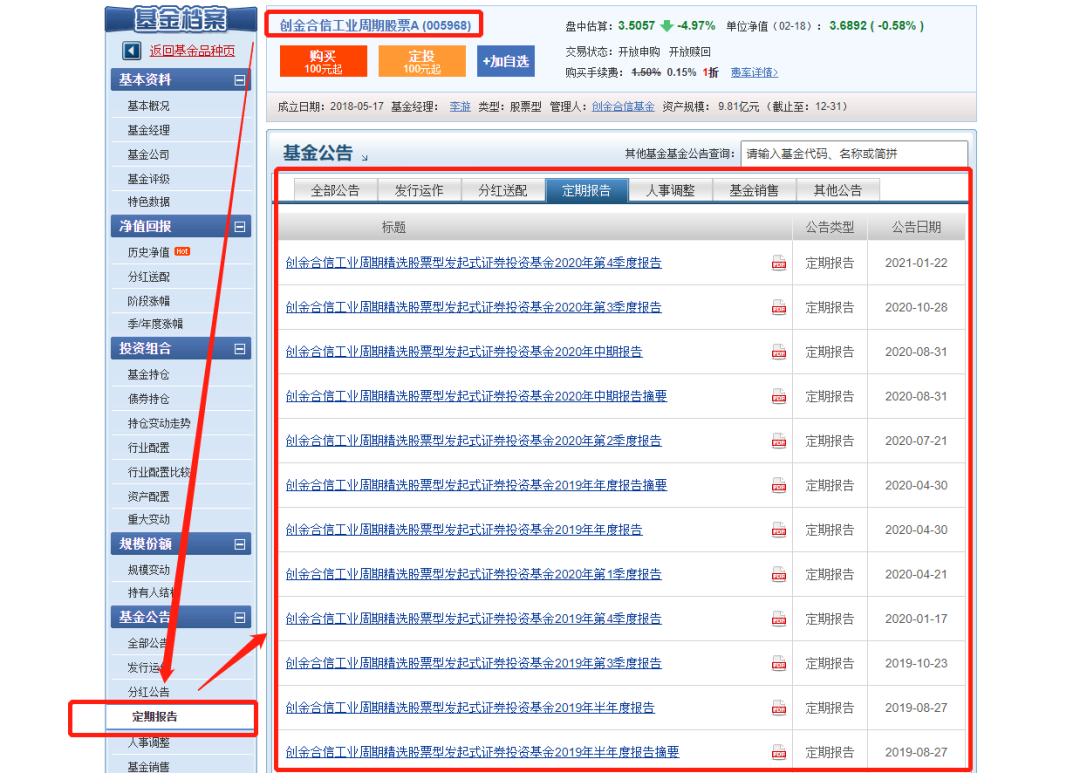
对应的,点击 基金公告菜单的定期报告选项 可以看到所有的季度报告
可以看到此时的 url 链接变成了下面这种:
http://fundf10.eastmoney.com/jjgg_005968_3.html
这个 url 我们通过 前缀+基金代码+后缀 可以直接构造
对于任意的基金报告,只需要改动基金代码就能直接定位到基金报告页。
http://fundf10.eastmoney.com/jjgg_ + 基金代码 + _3.html
另外可以发现,005968 的基金报告是有两页。
调出 F12 窗口,在点击下一页的时候可以发现动态请求的链接
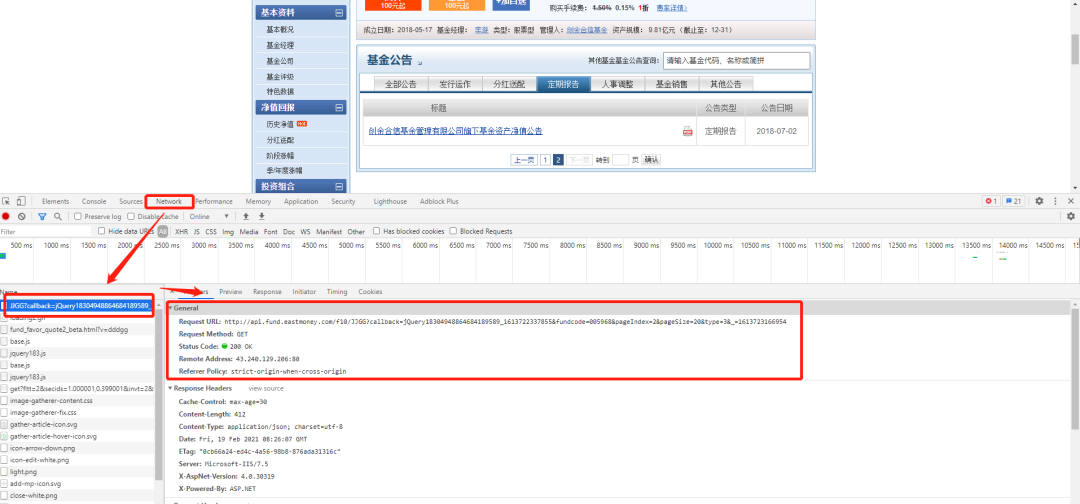
http://api.fund.eastmoney.com/f10/JJGG?callback=jQuery18304948864684189589_1613722337855&fundcode=005968&pageIndex=2&pageSize=20&type=3&_=1613723166954
前面的参数例如:funcode、pageIndex 等表示基金代码、页码等,都可以理解,但是最后一个参数有点奇怪:“&_=1613723166954”
如果删了这个参数或者随便改一个值,出来的结果是这样的:
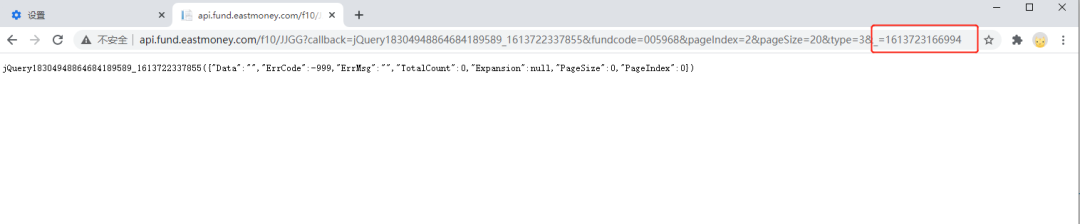
通过多次测试,发现这个参数值会根据时间发生变化,但是又不是简单的时间戳格式
大胆盲猜一下,这个参数应该是平台对应的反爬参数,如果能破解这个参数的生成规则,那么今天的目标就很容易搞定
花了点时间多研究了一下,发现没有很明显的规则,暂时决定放弃。
这个参数确实比较重要,有兴趣的可以研究下平台的生成规则,
ok,通过接口的方案获取数据暂时行不通,那就换种方式:selenium
关于 selenium 的使用在老早的一篇文章中就有说过,我还特意去看了一下,发现当时写的巨详细,墙裂推荐:小白学爬虫-进阶-selenium 获取数据
所以,下面是文章的重点:通过 selenium 爬取数据
老规矩,先说流程:
进入季度报页面,获取翻页页面进行循环 循环体中执行以下两个操作 解析当前页的内容,保存页面数据 点击下一页 遍历所有数据,筛选报告中的季度报 调用下载函数,下载对应的基金报告,保存 pdf 在本地
具体的,在解析每一页的内容时,可拿到 基金报告的标题、下载链接、发布时间 等
流程不难,代码操作也比较简单,往下看 
1. 构造基金报告页 url
很简单,两句话
code = '005968'
url = 'http://fundf10.eastmoney.com/jjgg_{0}_3.html'.format(code)
2. 初始化 selenium
为了方便使用,直接封装在函数里面
具体代码如下:
from selenium import webdriver
def init_selenium():
"""
初始化 selenium
@return:
"""
executable_path = "D:\software\install\chromedriver_win32\chromedriver.exe"
# 设置不弹窗显示
# chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
# browser = webdriver.Chrome(chrome_options=chrome_options, executable_path=executable_path)
browser = webdriver.Chrome(executable_path=executable_path)
return browser
运行之前需要手动改一下自己的 chromedriver.exe 的本地路径。
3. 获取报告页码
如图所示,4 个 label 标签分别对应:上一页、1、2、下一页,页码为 2
所以:页码即为 label 的长度-2
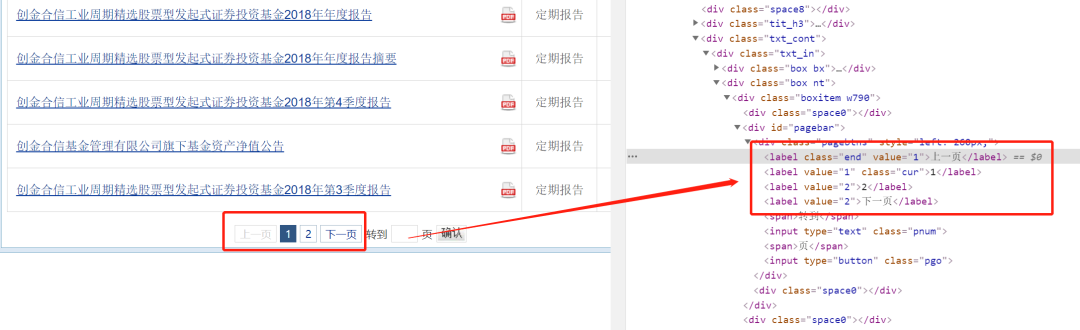
具体页码的获取通过 BeautifulSoup 对页面进行解析即可
browser.get(url)
content = browser.page_source
soup = BeautifulSoup(content, 'html.parser')
# 获取页码数
soup_pages = soup.find_all('div', class_='pagebtns')[0].find_all('label')
page_size = len(soup_pages)-2
4. 获取页面内容
页面内容中主要包括:报告标题、报告文件链接和公告日期
需要注意的是,部分报告的文件下载链接为空,需要特殊处理
部分报告文件是报告摘要,需要过滤掉
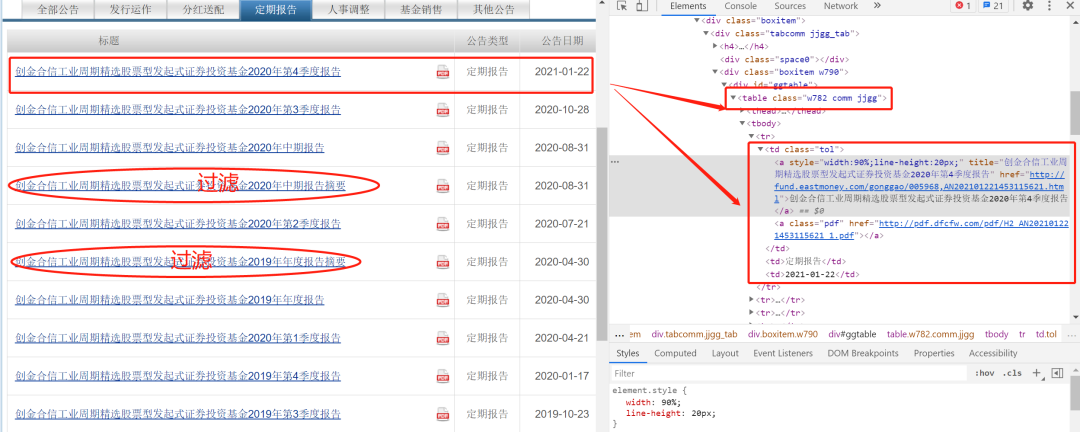
具体代码如下:
list_result = []
"""获取内容"""
soup_tbody = soup.find_all('table', class_='w782 comm jjgg')[0].find_all('tbody')[0]
for soup_tr in soup_tbody.find_all('tr'):
soup_a = soup_tr.find_all('td')[0].find_all('a')
title = soup_a[0].get_text()
# 文件下载链接为空的处理
if len(soup_a) == 2:
link = soup_a[1].get('href')
else:
link = None
date_str = soup_tr.find_all('td')[2].get_text()
if title.endswith("报告"):
list_result.append([title, link, date_str])
df_result = pd.DataFrame(list_result, columns=['报告标题', '报告pdf链接', '公告日期'])
5. 翻页操作
翻页操作在 selenium 中操作非常方便,定位+点击
对应的需要先确定翻页的按钮,也就是对应的页码 1/2/3/4 等,然后调用 click 函数
具体代码如下:
# 点击下一页按钮
browser.find_element_by_xpath("//div[@class='pagebtns']/label["+str(index+2)+"]").click()
time.sleep(random.randint(5, 10))
非常建议大家在每一个翻页中设置合适的休眠时间
上次基金的文章开源之后,可能有人把休眠时间去掉了,短时间内频繁爬取,导致官方做了反爬

还是建议大家理性爬数据,善待每一个目标网站。
6. 下载文件
上上一步已经拿到了每一个基金报告的标题和链接,直接遍历下载即可
下载 pdf 文件直接使用 requests 即可
具体代码如下:
import requests
# 设置下载路径
file_path = os.path.join(dirpath, title + '.pdf')
# 下载文件
res = requests.get(link)
with open(file_path, 'wb') as f:
f.write(res.content)
ok,具体的流程和代码已经介绍完毕
正常情况下,你的代码点击运行后自动打开 chrome 浏览器:
同时,编译器终端会是这样的:
下载后的基金季度报告文件是这样的:
以上就是本次爬虫的所有内容
最后的最后,还是建议大家理性爬数据,在每一个翻页中设置合适的休眠时间,善待每一个目标网站
另外,本着互相学习、交流思路的目的,本节所有代码开源
长按下方二维码,在添加老表微信好友 即可在最新朋友圈评论区获取所有源码,欢迎大家评论交流。
扫码查看我朋友圈
获取最新学习资源
代码开源的目的主要是互相学习、交流思路
比如有更好的方法爬取基金报告数据的,也都可以一起交流讨论
说个小小的拓展,对于基金季度报 pdf 文件,可以通过 Python 对收益情况、业绩表现、投资情况等做一个更细致的对比分析
【图书推荐】
文末推荐一本《Python数据科学实践》,本书是由狗熊会推出的一本利用Python介绍数据科学基本过程的著作。本书以Python语言为基础,介绍利用Python进行数据科学研究与商业分析的全貌。其核心的设计理念是通过经典的商业应用案例对数据爬取、数据存储、数据清洗、数据建模的核心Python模块做相应的介绍。👇👇👇

【赠书规则】
本文留言说说你阅读本文后的思考,留言字数需要超过15个字,我将选三位留言最走心的朋友,赠送图书《Python数据科学实践》一本。
活动截止时间:2021.5.1 20:00
注意:公众号留言仅展示前100条留言;活动截止前一天内的留言不入选;与留言主题无关留言或者留言字数不足15字的中奖无效,顺延至相关留言;最终排名顺序以我的截图为准。
另外,为了让更多读者获得赠书,本公众号读者一个月内只能通过赠书活动获得一次赠书;赠书阅读后欢迎大家写学习笔记投稿给本公众号,每投稿两次可以获得赠书一本。
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
“点赞”传统美德不能丢