
DALL·E 从文本到图像,超现实主义的图像生成器
先感受一下DALL·E生成图像,输入文本"牛油果形状的扶手椅。仿梨型的扶手椅。"DALL·E果然生成了类似超现实主义的图片,像真实存在的一样。

01
DALL·E
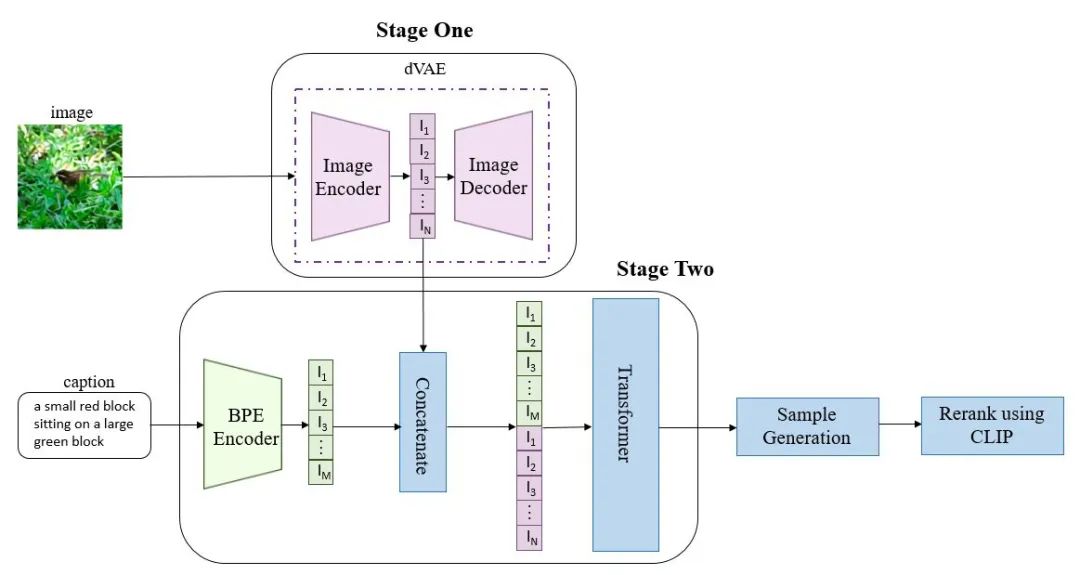
DALL·E的目标是把文本token和图像token当成一个数据序列,通过Transformer进行自回归。由于图片的分辨率很大,如果把单个pixel当成一个token处理,会导致计算量过于庞大,于是DALL·E引入了一个dVAE模型来降低图片的分辨率。
DALL·E的整体流程如下:
1.第一个阶段,先训练一个dVAE把每张256x256的RGB图片压缩成32x32的图片token,每个位置有8192种可能的取值(也就是说dVAE的encoder输出是维度为32x32x8192的logits,然后通过logits索引codebook的特征进行组合,codebook的embedding是可学习的)。
2.第二阶段,用BPE Encoder对文本进行编码,得到最多256个文本token,token数不满256的话padding到256,然后将256个文本token与1024个图像token进行拼接,得到长度为1280的数据,最后将拼接的数据输入Transformer中进行自回归训练。
3.推理阶段,给定一张候选图片和一条文本,可以通过预训练好的CLIP计算出文本和图片的匹配分数,采样越多数量的图片,就可以通过CLIP得到不同采样图片的分数排序。
从以上流程可知,dVAE、Transformer和CLIP三个模型都是不同阶段独立训练的。下面讲一下dVAE、Transformer和CLIP三个部分。
dVAE
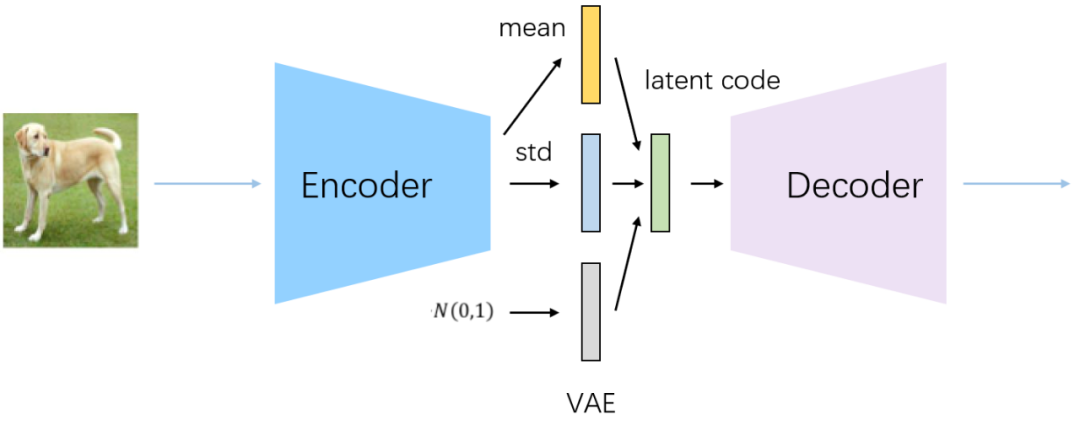
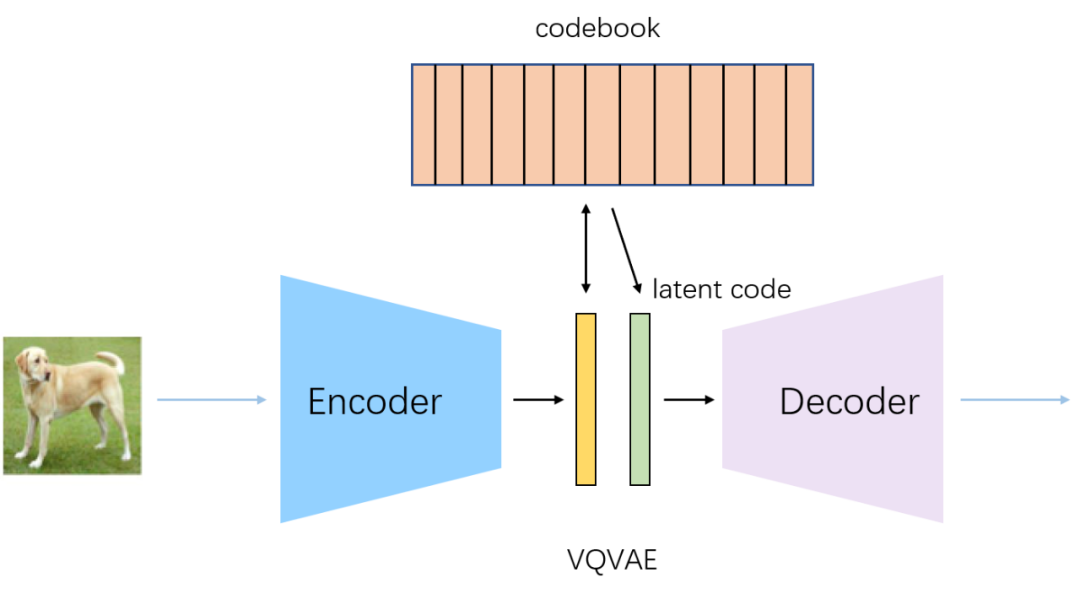
先简单讲一下VAE的原理,VAE就是在AntoEncoder的基础上给lantent vector添加限制条件,让其服从高斯分布,这样我们通过训练得到的decoder就可以直接使用,将随机生成的一个高斯分布喂给decoder就能生成图片,如上面第一张图所示(关于VAE可以看我之前的文章漫谈VAE和VQVAE,从连续分布到离散分布)。
相比于普通的VAE,dVAE有两点区别:
1.和VQVAE方法相似,dVAE的encoder是将图像的patch映射到8192的词表中,论文中将其分布设为在词表向量上的均匀分类分布,这是一个离散分布,由于不可导的问题,此时不能采用重参数技巧,DALL·E使用Gumbel Softmax trick来解决这个问题(简单来说就是arg max不可导,可以用softmax来近似代替max,而arg softmax是可导的,后面补一篇Gumbel Softmax的文章)。
2、在重建图像时,真实的像素值是在一个有界区间内,而VAE中使用的Gaussian
分布和Laplace分布都是在整个实数集上,这造成了不匹配的问题。为了解决这个问题,论文中提出了logit-Laplace分布,如下式所示:
Transformer
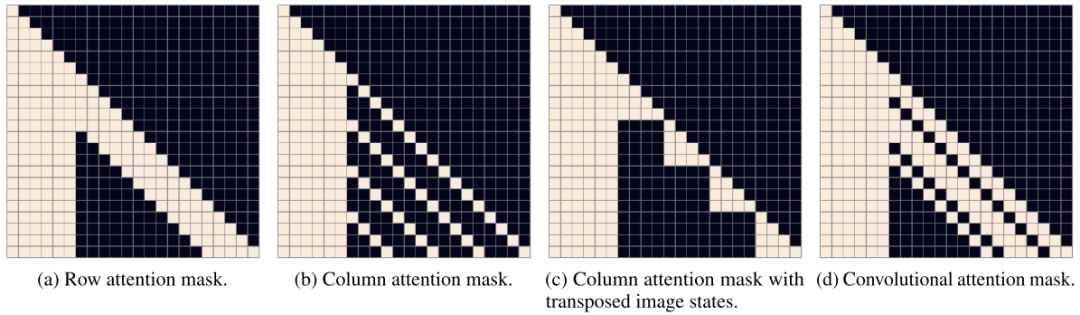
DALL·E中的Transformer结构由64层attention层组成,每层的注意力头数为62,每个注意力头的维度为64,因此,每个token的向量表示维度为3968。如图所示,attention层使用了行注意力mask、列注意力mask和卷积注意力mask三种稀疏注意力。
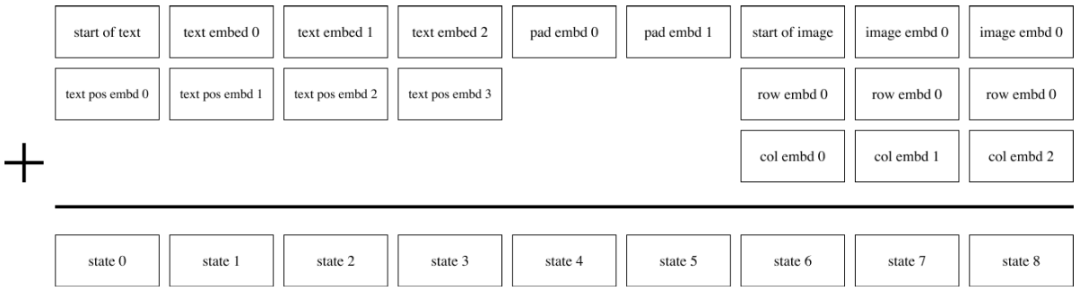
Transformer的输入如图所示,文本不满256个token时,使用pad embed填充,文本token需要加上pos embed,图片token需要加上行列的embed,这些embed都是可学习的。
CLIP
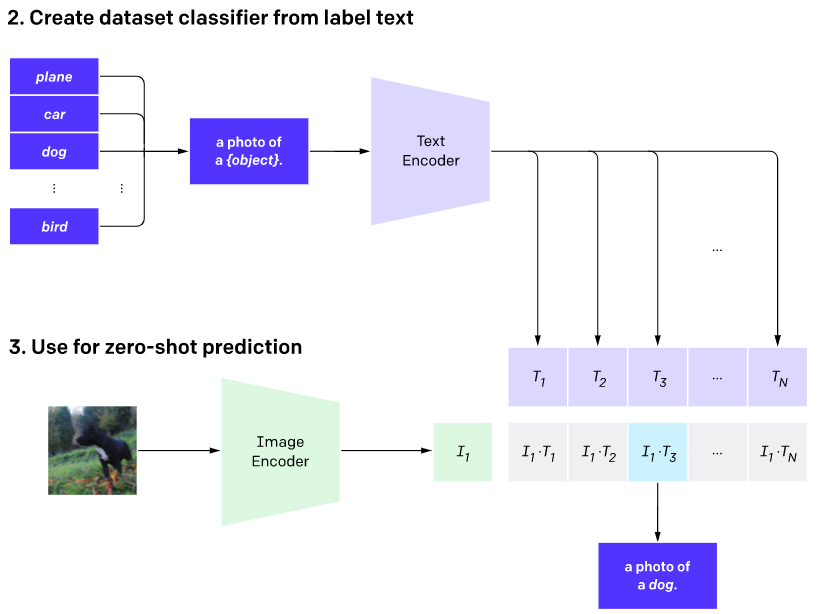
先讲一下CLIP的推理过程:
1.先将预训练好的CLIP迁移到下游任务,如图(2)所示,先将下游任务的标签构建为一批带标签的文本(例如 A photo of a {plane}),然后经过Text Encoder编码成一批相应的word embedding。
2.然后将没有见过的图片进行zero-shot预测,如图(3)所示,通过Image Encoder将一张小狗的图片编码成一个feature embedding,然后跟(2)编码的一批word embedding先归一化然后进行点积,最后得到的logits中数值最大的位置对应的标签即为最终预测结果。
在DALL·E中,CLIP的用法跟上述过程相反,提供输入文本和一系列候选图片,先通过Stage One和Stage Two生成文本和候选图片的embedding,然后通过文本和候选图片的匹配分数进行排序,最后找到跟文本最匹配的图片。
CLIP部分可以看我之前写的文章ViLD:超越Supervised的Zero-Shot检测器
02
生成结果
下面看几个DALL·E图像生成效果
输入文本:一个穿着芭蕾舞裙的小白萝卜遛狗的插图

输入文本:一个专业高质量的颈鹿乌龟嵌合体插画。模仿乌龟的长颈鹿。乌龟做的长颈鹿。

超现实主义,DALL·E对于文本的理解,非常的逻辑自洽,太夸张了
03
总结
如今,AI在一些细分领域逐渐向人类发起挑战,如围棋(AlphaZero)、蛋白质结构预测(AlphaFold)等等,DALL·E则是对绘画、设计领域向人类发起挑战。
未来中低端画师、设计师可能会源源不断的被AI替代,只有高端画师、设计师能够继续保持自身的竞争力,越来越卷了!
Reference
[1] Zero-Shot Text-to-Image Generation
[2] https://www.zhihu.com/question/447757686/answer/1764970196
一网打尽Pandas中的各种索引 iloc,loc,ix,iat,at,直接索引