
【论文解读】EfficientNet强在哪里
文章共3200字,预计阅读时间12min
什么是EfficientNet
模型复合缩放方法
把问题用数学来描述
实验内容
模型复合缩放方法
EfficientNet的基线模型
英语过关的小伙伴也许可以挑战一下?哈哈
模型扩展Model scaling一直以来都是提高卷积神经网络效果的重要方法。
比如说,ResNet可以增加层数从ResNet18扩展到ResNet200。这次,我们要介绍的是最新的网络结构——EfficientNet,就是一种标准化的模型扩展结果,通过下面的图,我们可以i只管的体会到EfficientNet b0-b7在ImageNet上的效果:对于ImageNet历史上的各种网络而言,可以说EfficientNet在效果上实现了碾压
什么是EfficientNet
一般我们在扩展网络的时候,一般通过调成输入图像的大小、网络的深度和宽度(卷积通道数,也就是channel数)。在EfficientNet之前,没有研究工作只是针对这三个维度中的某一个维度进行调整,因为没钱啊!!有限的计算能力,很少有研究对这三个维度进行综合调整的。
EfficientNet的设想就是能否设计一个标准化的卷积网络扩展方法,既可以实现较高的准确率,又可以充分的节省算力资源。因而问题可以描述成,如何平衡分辨率、深度和宽度这三个维度,来实现拘拿及网络在效率和准确率上的优化
模型复合缩放方法
compound scaling methd
EfficientNet给出的解决方案是提出了这个模型复合缩放方法
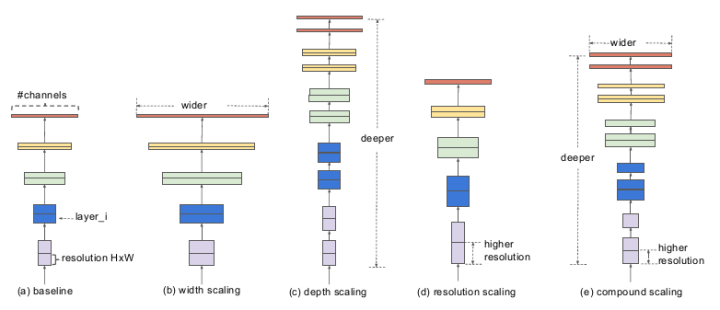
图a是一个基线网络,也就是我们所说的baseline,图b,c,d三个网络分别对该基线网络的宽度、深度、和输入分辨率进行了扩展,而最右边的e图,就是EfficientNet的主要思想,综合宽度、深度和分辨率对网络进行符合扩展。
把问题用数学来描述
首先,我们把整个卷积网络称为N,他的第i个卷积层可以看作下面的函数映射:
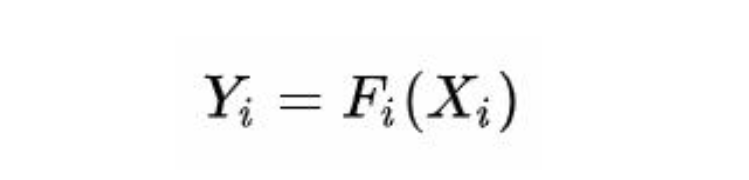
Yi是输出张量,Xi是输入张量,假设这个Xi的维度是

通常情况,一个神经网络会有多个相同的卷积层存在,因此,我们称多个结构相同的卷积层为一个stage。举个例子:ResNet可以分为5个stage,每一个stage中的卷积层结构相同(除了第一层为降采样层),前四个stage都是baseblock,第五个stage是fc层。现在构建神经网络也讲究模块化嘛。
总之,我们以stage为单位,将上面的卷积网络N改成为: 其中,下表1...s表示stage的讯号,Fi表示对第i层的卷积运算,Li的意思是Fi在第i个stage中有Li个一样结构的卷积层。
其中,下表1...s表示stage的讯号,Fi表示对第i层的卷积运算,Li的意思是Fi在第i个stage中有Li个一样结构的卷积层。
Li就是深度,Li越大重复的卷积层越多,网络越深; Ci就是channel数目,也就是网络的宽度 Hi和Wi就是图片的分辨率
就算如此,这也有三个参数要调整,搜索空间也是非常的大,因此EfficientNet的设想是一个卷积网络所有的卷积层必须通过相同的比例常数进行统一扩展 ,这句话的意思是,三个参数乘上常熟倍率。所以个一个模型的扩展问题,就用数学语言描述为:

其中,d、w和r分别表示网络深度、宽度和分辨率的倍率。这个算式表现为在给定计算内存和效率的约束下,如何优化参数d、w和r来实现最好的模型准确率。
实验内容
上面问题的难点在于,三个倍率之间是由内在联系的,比如更高分辨率的图片就需要更深的网络来增大感受野的捕捉特征。因此作者做了两个实验(实际应该是做了很多的实验)来说明:(1) 第一个实验,对三个维度固定了两个,只方法其中一个,得到的结果如下:

从左到右分别是只放大了网络宽度(width,w为放大倍率)、网络深度(depth,d为放大倍率)和图像分辨率(resolution, r为放大倍率)。我们可以看到,单个维度的放大最高精度只有80左右,本次实验,作者得出一个管带你:三个维度中任一维度的放大都可以带来精度的提升,但是随着倍率的越来越大,提升越来越小。
(2)于是作者做了第二个实验,尝试在不同的d,r组合下变动w,得到下图: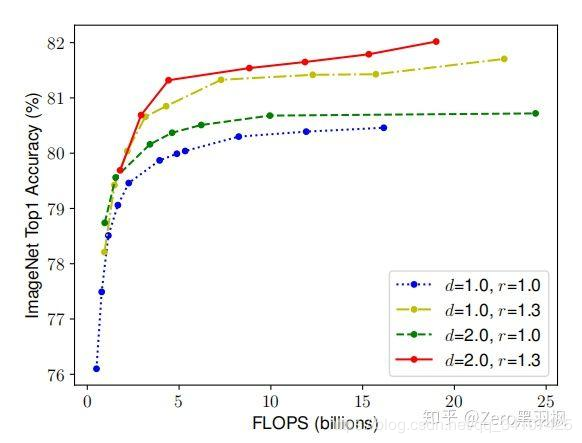 从实验结果来看,最高精度相比之前已经有所提升,突破了80大关。而且组合不同,效果不同。作者又得到了一个观点:得到了更高的精度以及效率的关键是平衡网络的宽度,网络深度,网络分辨率三个维度的缩放倍率
从实验结果来看,最高精度相比之前已经有所提升,突破了80大关。而且组合不同,效果不同。作者又得到了一个观点:得到了更高的精度以及效率的关键是平衡网络的宽度,网络深度,网络分辨率三个维度的缩放倍率
模型复合缩放方法
这时候作者提出了这个方法
EfficientNet的规范化复合调参方法使用了一个复合系数,来对三个参数进行符合调整: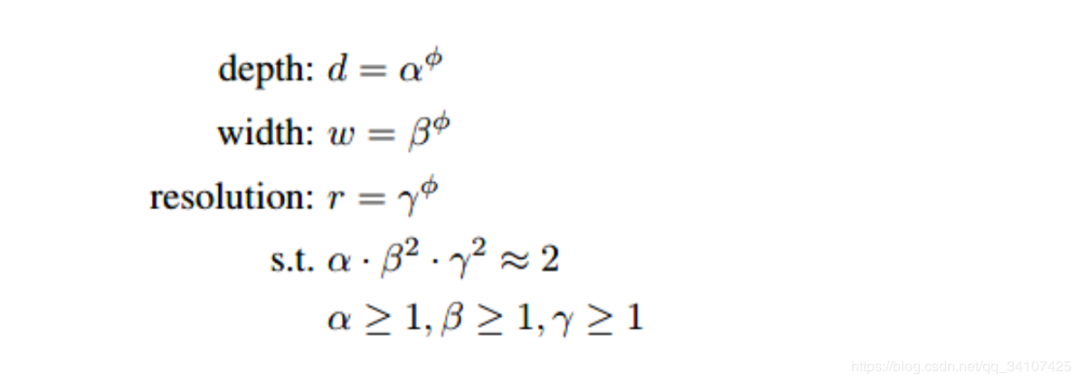 其中的都是常数,可以通过网格搜索获得。复合系数通过人工调节。考虑到如果网络深度翻番那么对应的计算量翻番,网络宽度和图像分辨率翻番对应的计算量会翻4番,卷积操作的计算量与成正比,。在这个约束下,网络的计算量大约是之前的倍
其中的都是常数,可以通过网格搜索获得。复合系数通过人工调节。考虑到如果网络深度翻番那么对应的计算量翻番,网络宽度和图像分辨率翻番对应的计算量会翻4番,卷积操作的计算量与成正比,。在这个约束下,网络的计算量大约是之前的倍
以上就是EfficientNet的复合扩展的方式,但是这仅仅是一种模型扩展方式,我们还没有讲到EfficientNet到底是一个什么样的网络。
EfficientNet的基线模型
EfficientNet使用了MobileNet V2中的MBCConv作为模型的主干网络,同时也是用了SENet中的squeeze and excitation方法对网络结构进行了优化。
总之呢,综合了MBConv和squeeze and excitation方法的EfficientNet-B0的网络结构如下表所示: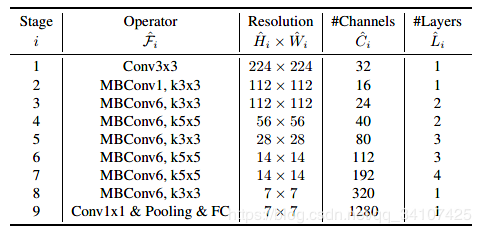
对于EfficientNet-B0这样的一个基线网络,如何使用复合扩展发对该网络进行扩展呢?这里主要是分两步走:还记得这个规划问题吗?
(1)第一步,先将复合系数固定为1,先假设有两倍以上的计算资源可以用,然后对进行网络搜索。对于EfficientNet-B0网络,在约束条件为
时,分别取1.2,1.1和1.15时效果最佳。第二步是固定,通过复合调整公式对基线网络进行扩展,得到B1到B7网络。于是就有了开头的这一张图片,EfficientNet在ImageNet上的效果碾压,而且模型规模比此前的GPipe小了8.4倍。

普通人来训练和扩展EfficientNet实在过于昂贵,所以对于我们来说,最好的方法就是迁移学习,稍后我会写一个Pytorch如何使用EfficientNet进行迁移学习的教程:
- END -往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):