
CV岗位面试题:输入图片尺寸不匹配CNN网络input时候的解决方式?(三种以上)

文 | 七月在线
编 | 小七
解析:
1. two-fixed方法:直接对输入图片Resize缩放;
2. one-fixed方法: 固定一边,缩放另一条边;
3. free方法:去掉FC全连接层加入全局池化层,或者使用卷积层替换全连接层;
网络之所以要输入固定大小的图片,主要是因为网络中存在FC全连接层,而且全连接层的一个缺点是参数量大容易导致过拟合,关于这部分解释说明可以参考第9题“如果最后一个卷积层和第一个全连接层参数量太大怎么办?”
卷积层替换全连接层
在经典分类网络,比如LeNet、AlexNet中,在前面的卷积层提取特征之后都串联全连接层来做分类。目前很多网络比如YOLO系列、SSD以及Faster RCNN的RPN,MTCNN中的PNet等都使用卷积层来代替全连接层,一样可以做到目标分类的效果,而且具有以下优点:
1. 更灵活,不需要限定输入图像的分辨率;
2. 更高效,只需要做一次前向计算;
全连接层和卷积层只要设置好了对应的参数,可以在达到相同输入输出的效果,在这个意义上,在数学上可以认为它们是可以相互替换的。
将全连接操作转化成卷积操作,也就是卷积最后一层的feature map 如果使用卷积操作是将每个神经元 Flatten之后dense连接到后面的若干神经元,以AlexNet为例,最后一层为256x7x7,得到后面的4096个神经元,但是如果使用7X7的卷积核对前面的FeatureMap进行继续卷积(padding=0),不也可以得到 4096X1X1的向量吗,如果图片大一些,例如384x384,那没AlexNet最后一层的大小就是256X12X12经过一个7x7的卷积核之后就是4096x6x6了,这时候这6x6=36个神经元就有了位置信息。如下图所示:
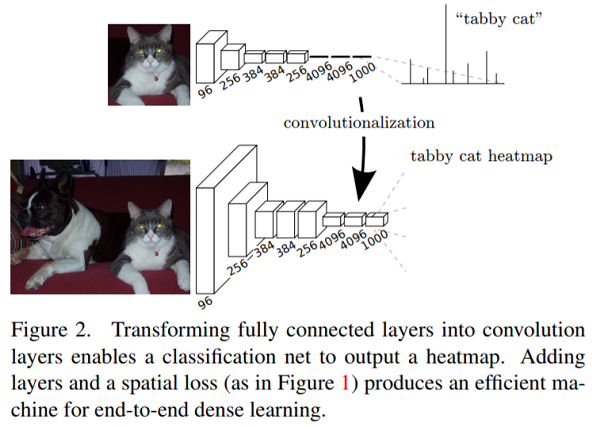
卷积替代全连接的优点:
1. 对输入分辨率的限制
如果网络后面有全连接层,而全连接层的输入神经元个数就是固定的,那么反推上层卷积层的输出是固定的,继续反推可知输入网络的图片的分辨率是固定的。例如,LetNet由于由全连接层,输入就只能是28 x 28的。
如果网络中的全连接层都用卷积层替代,网络中只有卷积层,那么网络的输出分辨率是随着输入图片的分辨率而来的,输出图中每一个像素点都对应着输入图片的一个区域(可以用stride,pooling来反算)。
2. 计算效率比较
同样以LeNet来做例子,如果一个图片是280 x 280的分辨率,为了识别图片中所有的数字(为了简单,假设每个数字都是在这个大图划分为10 x 10的网格中),那么为了识别这100个位置数字,那么至少需要做100次前向;而全卷积网络的特点就在于输入和输出都是二维的图像,并且输入和输出具有相对应的空间结构,我们可以将网络的输出看作是一张heat-map,用热度来代表待检测的原图位置出现目标的概率,只做一次前向就可以得到所有位置的分类概率。
评论