
mmdetection最小复刻版(十九):点集表示法RepPoints
AI编辑:深度眸
0 摘要
论文名称:RepPoints: Point Set Representation for Detection
论文地址:https://arxiv.org/abs/1904.11490
推荐解读:
https://zhuanlan.zhihu.com/p/64522910
知乎问答(原作者解读):
https://www.zhihu.com/question/322372759/answer/798327725
上述推荐解读文章我觉得写的非常好了,配合原作者解读,理解RepPoints思想没问题,但是上述两篇文章讲的主要是核心算法思想,主要是阐述了reppoints和dcn的关系,对于大部分细节没有写,故本文先介绍其出发点和核心思想,然后结合代码进行细节说明。推荐在阅读本文前,先读一下知乎推荐解读。
0.0 点集表示法
要理解本文思想,首先要理解本文标题Point Set Representation。矩形bbox表示方法非常多,常用的可以是xywh代表中心点和wh,也可以x1y1x2y2,代表左上和右下点坐标。假设以x1y1x2y2表示,那其实就是将bbox变成了两个点来表征,在anchor-free经典算法cornnernet中就采用l回归2个点heatmap的方式,但是有个比较大的弊端:需要对预测的n个关键点进行分组,而在密集或者重叠场景分组性能有限。
不管采用xywh还是x1y1x2y2的表征方式,都存在一个问题:其bbox表示方式过于粗糙(bbox内部所有点都表征该bbox),因为他无法表示不同物体形状和姿态,采用这种方式进行特征提取会带来大量噪声和无关背景,最终导致性能下降,这是一个能够预见到的现象。
针对这种情况,作者提出了采用语义关键点来表征bbox,如下图所示:
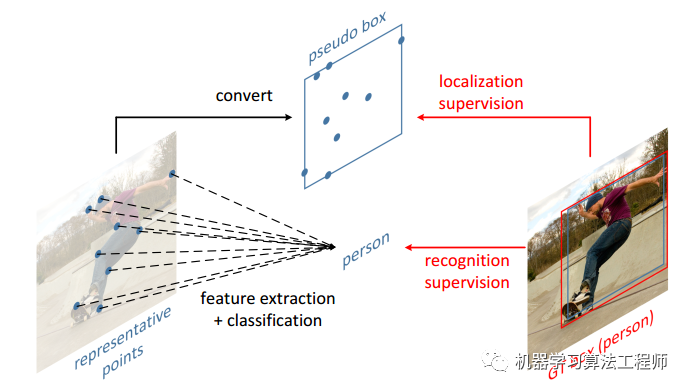
首先我预设每个bbox最多需要9个语义点,这9个关键点是物体独有语义点,如上图所示,9个点会分布在人体的语义位置,这是我们非常希望网络学到的模式。假设我们对数据采用了9个语义点的标注方法,那么在网络训练过程中,可以采用centernet做法,head分成2个分支输出,第一个分支输出是中心点回归热图,第二个分支输出18个通道的9个语义点坐标即可。
0.1 核心思想
9个语义点的表示方法看起来会比xywh和x1y1x2y2更加靠谱,但是因为不同物体9个语义点标注方式很难确定,而且标注工作量太大了的原因,直接标注是肯定不行的。而本文的核心亮点就在于仅仅需要原始bbox标注的监督就可以自动学习出9个语义点坐标。如上图所示,为了能够对9个语义点坐标进行弱bbox监督训练,作者提出了转换函数T即将预测的9个语义点通过某个可微函数转换得到bbox,然后对预测bbox进行Loss监督即可。
实际上2个点就可以,为啥要9个点呢?作者给出的解释是,学习9个点然后去计算bbox更精准更稳定,在这个弱监督的过程中,他发现这9个点经常落在极端点或者对语义表达很有帮助的地方。采用点集表示方法还有个好处:通常对于anchor-base来说,用anchor去覆盖4d空间是困难的,所以一般需要不同尺度和不同长宽比的多种anchor,而且赋予这个anchor box的正负样本属性也相对麻烦,需要计算和ground-truth box的IoU,与之对应的,要覆盖2d空间和赋予类别都很容易,典型的2d表示包括center point,corner point等等。
如果看过前面推荐知乎文章的朋友,可以发现本文设计还有一个突出优点:RepPoints可以看作是deformable ConvNets v3,追求更好的语义对齐和可解释性。正好借助dcn实现,利用采样点(9个学习出来的语义点)来表示物体的几何形态,相比dcnv1 v2系列,本文的offset分支是有约束的,不仅使得dcn的offset具有可解释性,而且训练更加稳定,这才是dcn的正确打开方式,这个思想我个人觉得太牛逼了!
基于上面简单思想,配合作者精妙的算法实现,将本文RepPoints算法境界推到了一个新的高度,而不仅仅是anchor-free,不仅仅是刷mAP,其背后蕴含的思想对后续目标检测算法提出了很大的指导作用,例如VarifocalNet。
github:
https://github.com/hhaAndroid/mmdetection-mini
欢迎star,我加了很多注释在上面,有兴趣的朋友可以看看。本文涉及到代码分析,电脑端阅读体验会更好。
1 算法分析
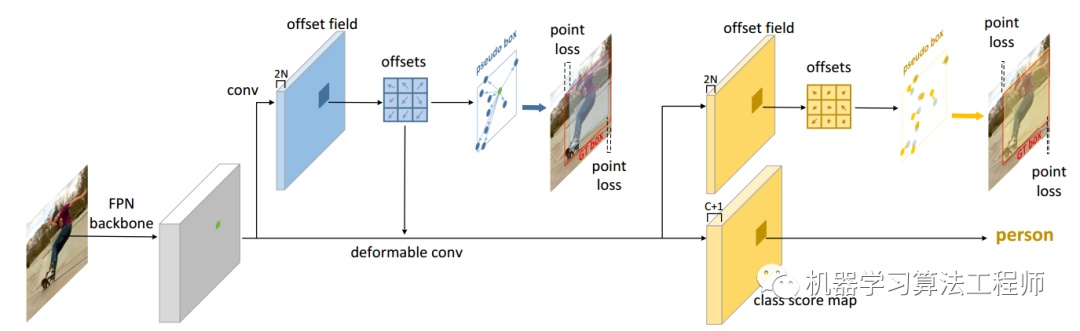
整体算法流程图如上所示。首先本文觉得one-stage的一次回归做法性能始终有限,合理做法应该是采用多阶段refine方式例如cascade rcnn,但是又不想采用roialign这种显式特征裁剪算法,所以可以认为本文属于1.5stage。其核心思想是:对特征图上面任何一点都学习出9个语义关键点坐标offset,同时将offset解码和转换得到原始bbox,即可进行bbox监督了;然后将预测输出offset作为dcn的offset输入进行特征重采样捕获几何位置得到新的特征图;最后对该特征图进行分类和下一步offset精细refine即可,第二步refine分支输出的是相对于第一阶段offset9个点的偏移值。
以上就是本算法核心思想和具体做法了。其最巧妙点包括两个:
(1) 弱bbox监督自动学习9个语义关键点
(2) 将9个语义关键点的输出作为dcn的offset值,进一步捕获几何特征,不仅仅提升性能而且offset还是有监督的,可解释更强
reppoints算法基于retinanet,backbone和neck没有任何改变,故仅仅对head部分进行分析即可。
1.1 head设计
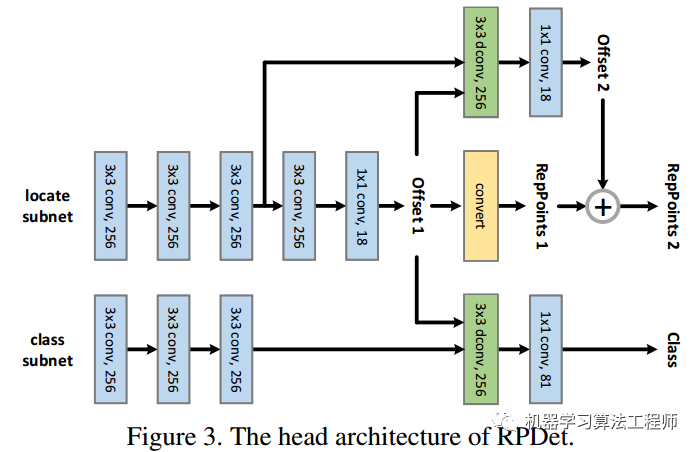
FPN模块输出是5个不同大小的特征图,都需要经过同一个head网络进行分类和回归。上述head网络图绘制的非常清晰,简单来说reppoints的head模块输出3个分支:分类分支、初始表征点回归分支和refine表征点回归分支。
假设是reppoints表征模式(use_grid_points=False,具体后面会写),对于任何一条分支的前向流程是:
(1) 对FPN输出的某个特征图,分成分类特征图和回归特征图两条分支,然后分别经过3个卷积进行特征提取
cls_feat = xpts_feat = xfor cls_conv in self.cls_convs:cls_feat = cls_conv(cls_feat)for reg_conv in self.reg_convs:pts_feat = reg_conv(pts_feat)
(2) 对pts_feat进行3x3+1x1的卷积,输出通道为18的offset,即特征图上每个点都回归9个语义点的xy坐标
pts_out_init = self.reppoints_pts_init_out(self.relu(self.reppoints_pts_init_conv(pts_feat)))
(3) 初始pts_out_init分支梯度乘上系数,目的是希望降低该分支的梯度权重self.gradient_mul=0.1
pts_out_init_grad_mul = (1 - self.gradient_mul) * pts_out_init.detach() + self.gradient_mul * pts_out_init
(4) 利用offset预测值,减掉每个特征图上kernel所对应的9个点base坐标([-1,-1],[0,-1],...),作为dcn的offset输入值
dcn_offset = pts_out_init_grad_mul - dcn_base_offset(5) 应用dcn对分类分支和refine回归分支进行特征自适应,得到新的特征图,然后经过两个1x1卷积得到最终输出,分类分支输出通道是num_class,而refine回归分支是18
cls_out = self.reppoints_cls_out(self.relu(self.reppoints_cls_conv(cls_feat, dcn_offset)))# refine点offset输出pts_out_refine = self.reppoints_pts_refine_out(self.relu(self.reppoints_pts_refine_conv(pts_feat, dcn_offset)))
(6) refine加上初始预测就可以得到refine后的输出9个点坐标
pts_out_refine = pts_out_refine + pts_out_init.detach()注意两个阶段的offset预测值的范围都是原图wh除以其stride,也就是[0,特征图wh],此时就得到了三个分支的输出cls_out, pts_out_init, pts_out_refine。
1.2 正负样本定义
在得到cls_out, pts_out_init, pts_out_refine输出后,需要对每个特征图位置的三个输出分支都定义正负样本。
(1) 第一阶段offset回归
对于回归问题而言,其仅仅是对正样本进行训练即可。其采用的正负样本分配配置为:
init=dict(assigner=dict(type='PointAssigner', scale=4, pos_num=1),allowed_border=-1,pos_weight=-1,debug=False),
其核心操作是:遍历每个gt bbox,利用类似fpn中提到的重映射规则,将该gt bbox映射到特定特征图层,其中心点所处位置即为正样本,其余位置全部忽略,非常类似centernet做法,公式为:

配置中的pos_num表示每个gt bbox所选择的正样本个数,默认是1。PointAssigner代码的核心流程为:
1.计算gt bbox宽高落在哪个尺度,也就是上述公式
gt_bboxes_lvl = ((torch.log2(gt_bboxes_wh[:, 0] / scale) +torch.log2(gt_bboxes_wh[:, 1] / scale)) / 2).int()points_lvl = torch.log2(points_stride).int()lvl_min, lvl_max = points_lvl.min(), points_lvl.max()gt_bboxes_lvl = torch.clamp(gt_bboxes_lvl, min=lvl_min, max=lvl_max)
2.遍历每个gt bbox,找到其所属的特征图层;为了通用性,先计算特征图上任何一点距离gt bbox中心点坐标的距离;然后利用topk算法选择出前pos_num个距离gt bbox最近的特征图点,这pos_num个都算正样本
points_gt_dist = ((lvl_points - gt_point) / gt_wh).norm(dim=1)min_dist, min_dist_index = torch.topk(points_gt_dist, self.pos_num, largest=False)min_dist_points_index = points_index[min_dist_index]
3.还需要特别考虑的是:假设topk的k为1,也就是仅仅gt bbox落在特征图的位置为正样本,假设有两个gt bbox的中心点重合且映射到同一个输出层,那么会出现后遍历的gt bbox覆盖前面gt bbox;但是如果topk取得比较大,可能会出现fcos里面描述的模糊样本,对于这类样本的处理办法就是其距离哪个gt bbox中心最近就负责预测谁
# 哪个距离小就谁负责谁less_than_recorded_index = min_dist < assigned_gt_dist[min_dist_points_index]min_dist_points_index = min_dist_points_index[less_than_recorded_index]assigned_gt_inds[min_dist_points_index] = idx + 1assigned_gt_dist[min_dist_points_index] = min_dist[less_than_recorded_index]
此时就可以得到任何一个特征图上面的点正样本属性和其所负责的gt bbox了
(2) 第二阶段offset回归
其配置如下:
refine=dict(assigner=dict(type='MaxIoUAssigner',pos_iou_thr=0.5,neg_iou_thr=0.4,min_pos_iou=0,ignore_iof_thr=-1),
其定义规则和retinanet完全相同,MaxIoUAssigner的输入肯定是anchor和gt bbox,然后基于最大iou原则定义正负样本,所以第二阶段refine的输入不是offset,而是经过第一个阶段预测的offset解码还原后的初始bbox。
(3) 分类
分类分支采用的是(2) 第二阶段offset回归里面的MaxIoUAssigner准则。MaxIoUAssigner的含义前参考以前解读文章,本文不再赘述。
所以可以发现本文的1.5stage算法,采用了两种正负样本定义策略,后续对比实验中有实验:当两个阶段都采用同一个MaxIoUAssigner分配策略时候效果会差一点点。
1.3 reppoints转换为bbox
为了能够对预测的9个语义点坐标进行loss监督,需要将9个语义点坐标转化得到bbox,作者提出三种做法,性能非常类似:minmax、partial_minmax和moment。
(1) minmax
非常简单,就是对9个offset去xy方向的最大和最小就可以构成bbox
(2) partial_minmax
相比minmax其仅仅选择前4个点进行minmax操作
(3) moment
moment是中心矩的意思,意思是通过这9个点,先求均值得到xy方向的均值即为gt bbox的中心坐标;对9个点求标准差操作然后通过可学习的transfer参数进行指数还原:
# 均值和方差就是gt bbox的中心点pts_y_mean = pts_y.mean(dim=1, keepdim=True)pts_x_mean = pts_x.mean(dim=1, keepdim=True)pts_y_std = torch.std(pts_y - pts_y_mean, dim=1, keepdim=True)pts_x_std = torch.std(pts_x - pts_x_mean, dim=1, keepdim=True)# self.moment_transfer也进行梯度增强操作moment_transfer = (self.moment_transfer * self.moment_mul) + (self.moment_transfer.detach() * (1 - self.moment_mul))moment_width_transfer = moment_transfer[0]moment_height_transfer = moment_transfer[1]# 解码代码half_width = pts_x_std * torch.exp(moment_width_transfer)half_height = pts_y_std * torch.exp(moment_height_transfer)bbox = torch.cat([pts_x_mean - half_width, pts_y_mean - half_height,pts_x_mean + half_width, pts_y_mean + half_height],dim=1)
看起来比较复杂,但是实际上就是某种变换关系而已。
1.4 bbox编解码
不管其第一阶段还是第二阶段的loss计算其需要将reppoints转换为bbox,故对于loss函数而言其面对的始终是bbox,而不是9个关键点。
在得到bbox后,作者实际上没有采用啥高级的bbox编解码策略,而只是简单的对原图gt bbox的x1y1x2y2除以4*stride而已,从后面介绍的loss计算可以看出来。
1.5 Loss设计
loss_cls=dict(type='FocalLoss',use_sigmoid=True,gamma=2.0,alpha=0.25,loss_weight=1.0),loss_bbox_init=dict(type='SmoothL1Loss', beta=0.11, loss_weight=0.5),loss_bbox_refine=dict(type='SmoothL1Loss', beta=0.11, loss_weight=1.0),
可以看出分类分支是focal loss,两个回归分支都是smooth l1 loss。
(1) 分类分支
分类分支loss计算非常简单
labels = labels.reshape(-1)label_weights = label_weights.reshape(-1)cls_score = cls_score.permute(0, 2, 3,1).reshape(-1, self.cls_out_channels)cls_score = cls_score.contiguous()loss_cls = self.loss_cls(cls_score,labels,label_weights,avg_factor=num_total_samples_refine)
(2) 第一阶段回归分支
1.首先对预测的9个offset采用*1.4 reppoints转换为bbox*小节解码为bbox格式
bbox_pred_init = self.points2bbox(pts_pred_init.reshape(-1, 2 * self.num_points), y_first=False)
2.对预测框和gt bbox都除以4*stride,稳定训练过程,仅仅计算正样本loss
normalize_term = self.point_base_scale * strideloss_pts_init = self.loss_bbox_init(bbox_pred_init / normalize_term,bbox_gt_init / normalize_term,bbox_weights_init,avg_factor=num_total_samples_init)
(3) 第二阶段回归分支
和上面操作完全相同。
loss_pts_refine = self.loss_bbox_refine(bbox_pred_refine / normalize_term,bbox_gt_refine / normalize_term,bbox_weights_refine,avg_factor=num_total_samples_refine)
需要注意前面说过head网络前向输出的offset值是特征图尺度的,但是这里计算loss时候的bbox_pred_init、bbox_pred_refine是原图尺度,故在将reppoints转换为bbox前需要将9个预测的offset还原到原图尺度self.offset_to_pts,核心操作是:
pts = xy_pts_shift * self.point_strides[i_lvl] + pts_centerxy_pts_shift是前面预测出来的特征图尺度offset,乘上stride就变成了原图尺度,加上特征图上的点在原图上的起始点坐标就可以得到9个点在原图上面的坐标了。pts_center的计算方法为(get_point函数实现):
# 为特征图的每个点生成相对原图左上角坐标(没有偏移0.5),额外stack上stridefeat_h, feat_w = featmap_sizeshift_x = torch.arange(0., feat_w, device=device) * strideshift_y = torch.arange(0., feat_h, device=device) * strideshift_xx, shift_yy = self._meshgrid(shift_x, shift_y)stride = shift_x.new_full((shift_xx.shape[0], ), stride)shifts = torch.stack([shift_xx, shift_yy, stride], dim=-1)
我觉得偏移0.5应该会更好理解吧。
1.6 附加内容
在复现模型中有如下对比实验:
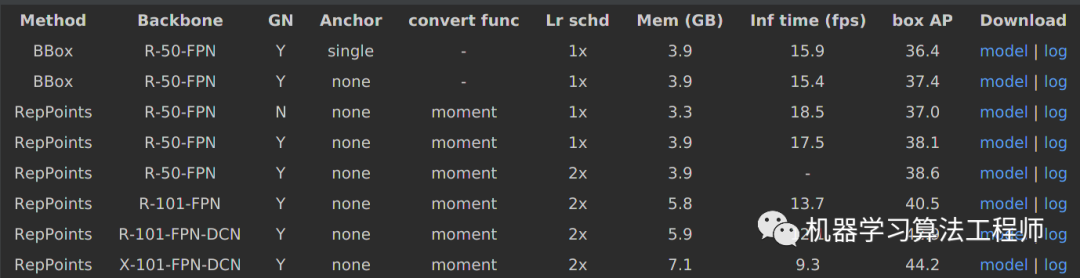
reppoints就是上面分析的情况,但是前两行的Method是BBox,且Anchor分为single和None,下面分析下这两种模式的区别:
(1) BBox-Single
这行效果对应的配置文件是:bbox_r50_grid_fpn_gn-neck+head_1x_coco.py,其配置如下:
(2) BBox-none
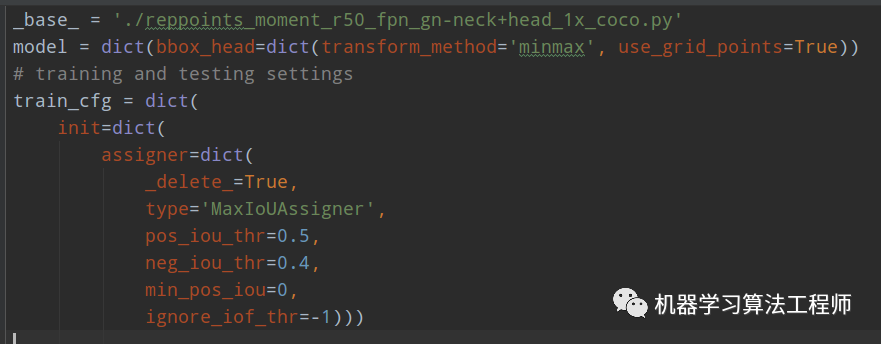
这行效果对应的配置文件是:bbox_r50_grid_center_fpn_gn-neck+head_1x_coco.py,其配置如下:
_base_ = './reppoints_moment_r50_fpn_gn-neck+head_1x_coco.py'model = dict(bbox_head=dict(transform_method='minmax', use_grid_points=True))
对比可以发现BBox和RepPoints的差别就在于use_grid_points,为True表示bbox模式,而Single和None的差别在于第一个offset回归分支的正负样本定义规则,None模式表示采用的依然是MaxIoUAssigner,下面讲解具体差别。
(1) Single vs None
默认是None模式,也就是我们分析的场景,对于single模式可以发现其第一阶段匹配规则是MaxIoUAssigner而不是PointAssigner,为了能够采用MaxIoUAssigner,需要提供anchor,故其对特征图上面每个点生成了anchor,对应代码是centers_to_bboxes,非常简单:
scale = self.point_base_scale * self.point_strides[i_lvl] * 0.5bbox_shift = torch.Tensor([-scale, -scale, scale,scale]).view(1, 4).type_as(point[0])bbox_center = torch.cat([point[i_lvl][:, :2], point[i_lvl][:, :2]], dim=1)bbox.append(bbox_center + bbox_shift)
对特征图上面任何一点,首先在分析的get_points函数中变成原图尺度,然后在这里加上指定的宽高即可,可以看出相当于anchor个数为1的正方形。
(2) RepPoints vs BBox
reppoints表示的是9个语义点模式,而bbox模式就是常规的deltaxywh模式,也就是说在bbox模式下,输出通道不是18,而是4,和原始retinanet的回归分支输出含义完全相同。设置这个对比实验是为了说明在完全相同的训练模式下,reppoint的表征方式更加靠谱。
pts_out_dim = 4 if self.use_grid_points else 2 * self.num_points除了改这里还不够,因为不想改训练loss部分代码,仅仅希望改输出形式而已,也就是说这里输出的虽然是delta xywh模式,但是我希望前向时候输出的依然是9个点模式,这样整个loss层面代码就不需要改动了。
故作者的解决办法是:首先利用delta xywh预测值和预设的特征图尺度anchor,还原得到特征图尺度的bbox;然后对bbox进行均匀采样得到9个网格规则点,这9个点就相当于reppoints的输出形式,后面代码就不用改了。
# 先还原出特征图尺度bboxgrid_topleft = bxy + bwh * reg[:, :2, ...] - 0.5 * bwh * torch.exp(reg[:, 2:, ...])grid_wh = bwh * torch.exp(reg[:, 2:, ...])# 得到x1y1x2y2grid_wh = bwh * torch.exp(reg[:, 2:, ...])grid_left = grid_topleft[:, [0], ...]grid_top = grid_topleft[:, [1], ...]grid_width = grid_wh[:, [0], ...]grid_height = grid_wh[:, [1], ...]# 在bbox内部均匀采样9个点输出即可intervel = torch.linspace(0., 1., 3).view(1, 3, 1, 1).type_as(reg)grid_x = grid_left + grid_width * intervelgrid_x = grid_x.unsqueeze(1).repeat(1, self.dcn_kernel, 1, 1, 1)grid_x = grid_x.view(b, -1, h, w) # b,9,h,wgrid_y = grid_top + grid_height * intervelgrid_y = grid_y.unsqueeze(2).repeat(1, 1, self.dcn_kernel, 1, 1)grid_y = grid_y.view(b, -1, h, w)grid_yx = torch.stack([grid_y, grid_x], dim=2)grid_yx = grid_yx.view(b, -1, h, w)# 变成xyxy格式regressed_bbox = torch.cat([grid_left, grid_top, grid_left + grid_width, grid_top + grid_height], 1)
2 实验分析
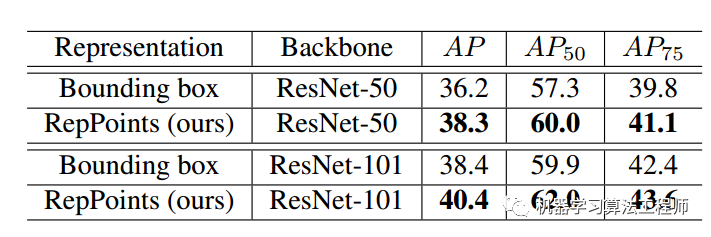
上图可以发现本文所提的reppoint模式效果比bbox好很多,原因是reppoints会提取9个语义点,在结合dcn操作可以有效捕获几何信息。
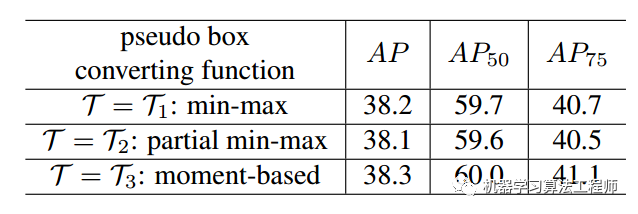
上图可以看出采用何种转换函数影响不是很大,但是moment方法会好一点,原因应该是9个点始终都有梯度,如果是minmax或者部分minmax,其实没有利用到所有信息。
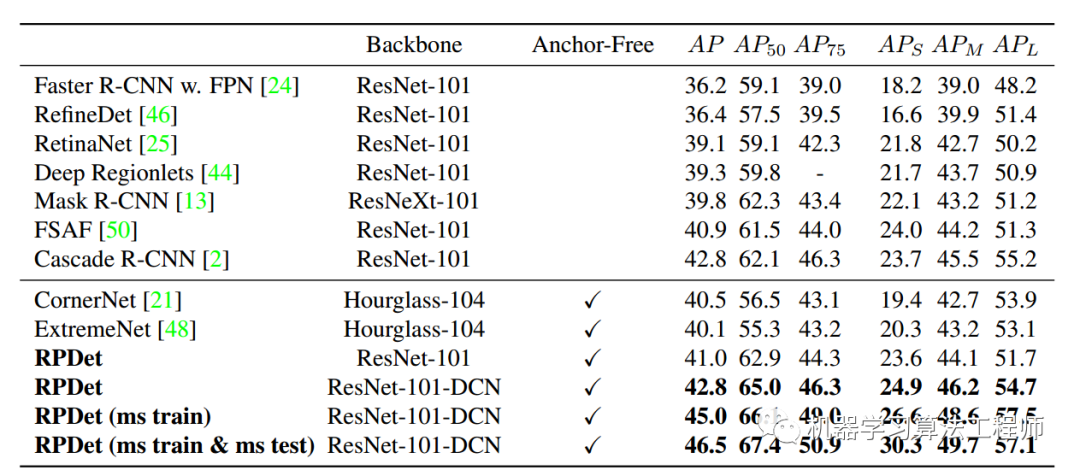
总的性能还是蛮好的。

从9个语义点可视化效果来看,还是蛮符合预期的,说明本文思想是正确的。
3 总结
其实这篇文章我好早以前就读过一次,那时候觉得也就那样吧,看不出啥特别来,可能是当时水平不行(当然现在也不行),现在再读一遍发现这思想老厉害了,再结合代码我算是佩服了。整个算法设计非常巧妙,实现方面也是非常好,很容易理解,不得不佩服呀!同时这篇文章所提的学习有具体含义的offset然后作为dcn的输入,为后面的很多目标检测算法提供了思路。
厉害了,微软亚研院!
github:
https://github.com/hhaAndroid/mmdetection-mini
欢迎star
推荐阅读
mmdetection最小复刻版(六):FCOS深入可视化分析
mmdetection最小复刻版(二):RetinaNet和YoloV3分析
机器学习算法工程师
一个用心的公众号
