
RepPointv2:使用点集合表示来做目标检测
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


作者:Nabil MADALI
编译:ronghuaiyang
无anchor方法中效果很好的一种。
目标检测的目的是定位图像中的目标,并提供它们的类标签。作为计算机视觉中最基本的任务之一,它是许多视觉应用的关键组成部分,包括实例分割、人体姿态分析和视觉推理。目标检测问题的重要性以及深度神经网络的快速发展导致了近年来的重大进展。
RepPoint和RepPointv2是近年来提出的目标检测模型。这两篇检测论文让我最大的收获是对无锚目标检测算法的性能优势有了一定的解读,并朝着无锚目标检测算法的方向进行探索。
RepPointv2认为,虽然基于锚点的目标检测算法近年来表现出了良好的性能,但仍然过于粗糙。主要表现为检测头和分类头从bbox中提取的特征可能受到背景和杂乱语义信息的影响。
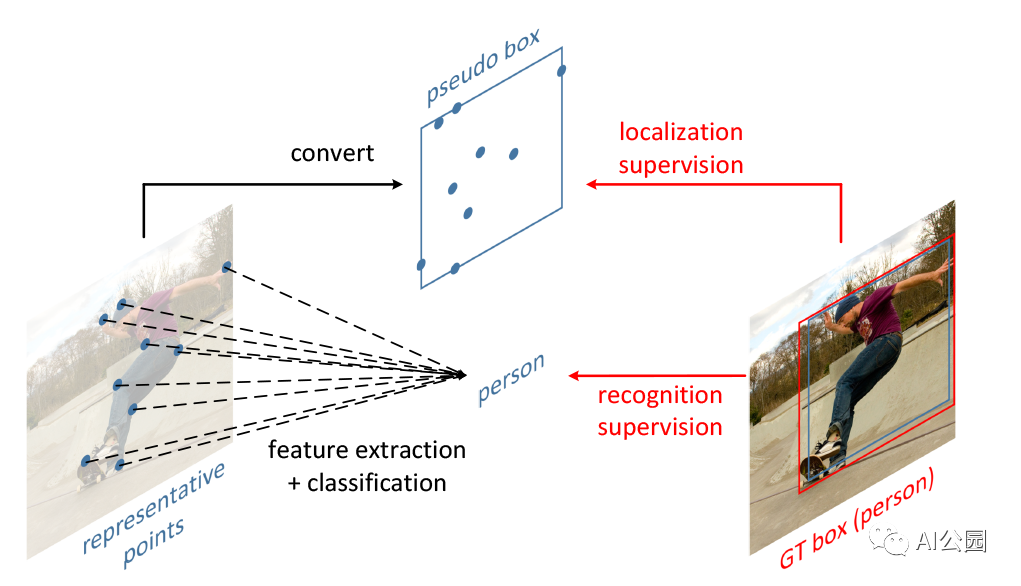
RepPoints是一种新的目标检测表示,它由一组点组成,这些点表示目标的空间范围和语义上重要的局部区域。该表示法通过基于矩形地形图的弱定位监督和隐式识别反馈来学习。基于更丰富的RepPoints表示,我们开发了一个无锚目标检测器,与使用边界框相比,它能产生更好的性能。
假设我们正在对人体进行标记并进行人体检测。如果这个人张开双臂,为了尽可能地把人的目标框起来,标记好的bbox会介绍很多背景信息。此外,如果人体区域周围有大量的其他人或行人重叠,标记的方框就会包含大量的误导性信息。
因此提出了RepPoint的结构,通过在锚点中建立一系列自适应采样点来代替完全采样,即在正采样区域中学习一组自适应采样点来寻找表示。
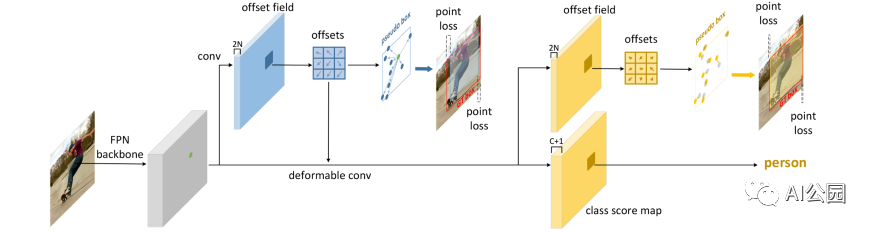
我们采用特征金字塔网络(feature pyramid networks, FPN)作为骨干网络,为了便于说明,我们只绘制了FPN特征图的一个比例的后续管道。注意FPN特征映射的所有尺度共享相同的后面的网络结构和相同的模型权重。
首先,使用主干+FPN提取输入图像的多层特征,然后对FPN中的每个像素点位置,使用RepPoint结构获取FPN中的每个像素点位置采样点的偏移量,利用所述RepPoint组获得的采样点位置确定目标的粗定位检测帧,然后将所述第一个RepPoint结构获得的偏移量转移到第二个RepPoint结构。两个RepPoint结构获得的偏移量相对于第一个RepPoint的偏移量叠加,得到的是每个位置的最终采样点。并根据最终采样点得到目标的最小边界矩形。分类基于第一个RepPoint结构提供的采样点所形成的目标边界矩形。
解释说,在FPN中使用FPN的意义在于,不同尺度的目标自然会归于不同层次的特征图,对于小目标使用更高的分辨率的特征图,它还减少了两个同样尺度的目标落在同一个中心点的概率,因此大大减少了目标中心点重叠的发生。
在RepPointV2中,作者希望继续提高网络的回归性能,从而提高整个网络的性能。
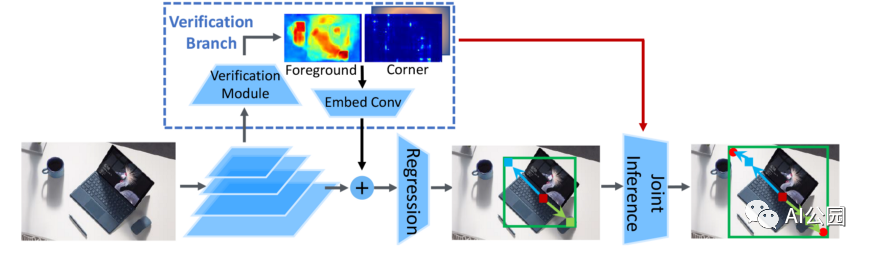
与V1版本的改进相比,作者首先参照验证算法得到当前输入图像的前背景热图和角点图像,然后利用这个辅助分支与之前RPDet计算的主分支相结合来提高性能,类似于FCOS的objectness分支。
然而,两者之间也有差异。FCOS中的objectness分支是对最终网络生成的多个定位帧的加权筛选,目的是去除冗余的假阳性定位帧,而REpPointv2中的auxiliary分支考虑到RepPoint结构是在一定范围内选择特征点。
总结
相对于v1论文,RepPointv2论文主要通过增加辅助分支来加强定位能力。辅助分支所做的主要工作是提高RepPoint提取采样特征点的能力。所采用的方法是通过生成的前背景和角落热度图来达到参考索引的效果。

英文原文:https://medium.com/@nabil.madali/point-set-representation-for-object-detection-ae1cc132095a
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!