今天要跟大家分享的内容是一篇联邦学习领域方面比较全面的综述文章:Advances and Open Problems in Federated Learning。该文章发表于2021年,由来自麻省理工、斯坦福、谷歌等25所国际知名高校(机构)的学者联合所著,共调研了400余篇文献,内容非常丰富。由于篇幅所限,这里聚焦于几个基础方面进行分享,并进行一定的补充。
Federated learning is a machine learning setting where multiple entities (clients) collaborate in solving a machine learning problem, under the coordination of a central server or service provider. Each client’s raw data is stored locally and not exchanged or transferred; instead, focused updates intended for immediate aggregation are used to achieve the learning objective.
(1)数据集1. EMNIST数据集: 原始数据由671,585个数字图像和大小写英文字符(62个类)组成。联邦学习的版本将数据集拆分到3,400个不平衡Clients,每个Clients上的数字/字符为同一人所写,由于每个人都有独特的写作风格,因此数据是非同分布的。来源:Gregory Cohen, Saeed Afshar, Jonathan Tapson, and Andre ́ van Schaik. EMNIST: an extension of MNIST to handwritten letters. arXiv preprint arXiv:1702.05373, 2017.2.Stackoverflow数据集: 该数据集由Stack Overflow的问答组成,并带有时间戳、分数等元数据。训练数据集包含342,477多个用户和135,818,730个例子。其中的时间戳信息有助于模拟传入数据的模式。下载地址:https://www.kaggle.com/stackoverflow/stackoverflow3.Shakespeare数据集: 该数据是从The Complete Works of William Shakespeare获得的语言建模数据集。由715个字符组成,其连续行是Client数据集中的示例。训练集样本量为16,068,测试集为2,356。来源:Sebastian Caldas, Peter Wu, Tian Li, Jakub Konecˇny ́, H Brendan McMahan, Virginia Smith, and Ameet Talwalkar. LEAF: A benchmark for federated settings. arXiv preprint arXiv:1812.01097, 2018.(2)开源软件包1.TensorFlow Federated: TensorFlow框架,专门针对研究用例,提供大规模模拟功能来控制抽样。支持在模拟环境中加载分散数据集,每个Client的ID对应于TensorFlow数据集对象。来源:The TFF Authors. TensorFlow Federated, 2019. URL:https://www.tensorflow.org/federated.2.PySyft: PyTorch框架,使用PyTorch中的联邦学习。适用于考虑隐私保护的机器学习,采用差分隐私和多方计算(MPC)将私人数据与模型训练分离。来源:Theo Ryffel, Andrew Trask, Morten Dahl, Bobby Wagner, Jason Mancuso, Daniel Rueckert, and Jonathan Passerat-Palmbach. A generic framework for privacy preserving deep learning, 2018.
除此以外,文章也提供了其他软件实现以及数据源供研究使用。
参考文献
Bellet, A., Guerraoui, R., Taziki, M., and Tommasi, M. (2018), “Personalized and private peer-to-peer machine learning,” in International Conference on Artificial Intelligence and Statistics, PMLR, pp. 473–481.Colin, Igor, Aurélien Bellet, Joseph Salmon, and Stéphan Clémençon. "Gossip dual averaging for decentralized optimization of pairwise functions." In International Conference on Machine Learning, pp. 1388-1396. PMLR, 2016.Lan, Guanghui. "An optimal method for stochastic composite optimization." Mathematical Programming 133, no. 1 (2012): 365-397.Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Bennis, M., Bhagoji, A. N., Bonawitz, K., Charles, Z., Cormode, G., Cummings, R., DOliveira, R. G. L., Eichner, H., Rouayheb, S. E., Evans, D., Gardner, J., Garrett, Z., Gascn, A., Ghazi, B., Gibbons, P. B., Gruteser, M., Harchaoui, Z., He, C., He, L., Huo, Z., Hutchinson, B., Hsu, J., Jaggi, M., Javidi, T., Joshi, G., Khodak, M., Konecn, J., Korolova, A., Koushanfar, F., Koyejo, S., Lepoint, T., Liu, Y., Mittal, P., Mohri, M., Nock, R., zgr, A., Pagh, R., Qi, H., Ramage, D., Raskar, R., Raykova, M., Song, D., Song, W., Stich, S. U., Sun, Z., Suresh, A. T., Tramr, F., Vepakomma, P., Wang, J., Xiong, L., Xu, Z., Yang, Q., Yu, F. X., Yu, H., and Zhao, S. (2021), “Advances and Open Problems in Federated Learning,” Foundations and Trends in Machine Learning, 14, 1–210.Li, Yuzheng, Chuan Chen, Nan Liu, Huawei Huang, Zibin Zheng, and Qiang Yan. "A blockchain-based decentralized federated learning framework with committee consensus," IEEE Network 35, no. 1 (2020): 234-241.McMahan, B., Moore, E., Ramage, D., Hampson, S., and y Arcas, B. A. (2017), “Communication-efficient learning of deep networks from decentralized data,” in Artificial Intelligence and Statistics, PMLR, pp. 1273–1282.Stich, Sebastian U. "Local SGD converges fast and communicates little. (2018)" arXiv preprint arXiv:1805.09767.Karimireddy, Sai Praneeth, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. (2020), "Scaffold: Stochastic controlled averaging for federated learning," In International Conference on Machine Learning, pp. 5132-5143. PMLR.Tang, H., Lian, X., Yan, M., Zhang, C., and Liu, J. (2018), “Decentralized training over decentralized data,” in International Conference on Machine Learning, PMLR, pp. 4848–4856.Vanhaesebrouck, P., Bellet, A., and Tommasi, M. (2017), “Decentralized collaborative learning of personalized models over networks,” in Artificial Intelligence and Statistics, PMLR, pp. 509–517.Xiangru Lian, Ce Zhang, Huan Zhang, Cho-Jui Hsieh, Wei Zhang, and Ji Liu. “Can Decentralized Algorithms Outperform Centralized Algorithms? A Case Study for Decentralized Parallel Stochastic Gradient Descent,” In NIPS, 2017.Xiang Li, Kaixuan Huang, Wenhao Yang, Shusen Wang, and Zhihua Zhang. “On the convergence of FedAvg on non-IID data,” arXiv preprint arXiv:1907.02189, 2019.


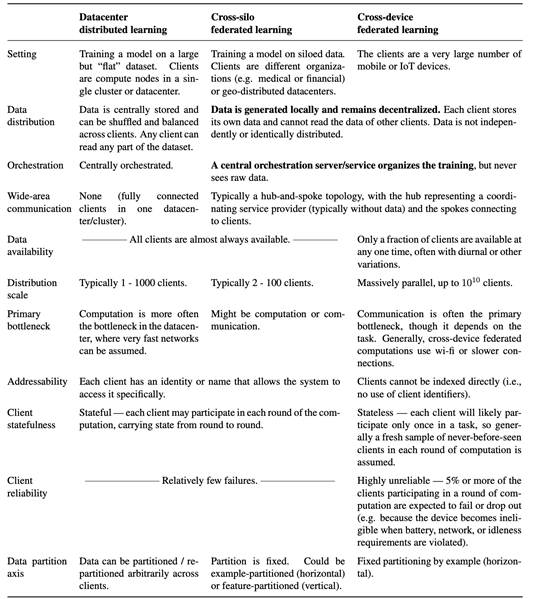
 表 1 经典联邦学习和去中心化联邦学习的主要差异比较
表 1 经典联邦学习和去中心化联邦学习的主要差异比较