
Learning to Solve Security-Constrained Unit Commitment Problems
论文阅读笔记,个人理解,如有错误请指正,感激不尽!该文分类到Machine learning alongside optimization algorithms。
01 Security-constrained unit commitment (SCUC)基于安全约束的机组组合优化 (Security-constrained unit commitment, SCUC) 是能源系统和电力市场中一个基础的问题。机组组合在数学上是一个包含0-1整型变量和连续变量的高维,离散,非线性混合整数优化问题。
简单点说呢,就是需要对发电机组进行决策,决定哪些发电机开哪些关,以及开的发电机生产多少电力,从而满足市场的需求。目标是使得发电总成本最小化(当然也有很多其他目标,比如考虑环境影响)。约束主要是要确保安全约束,即每一条传输电的线路,传输的电量不能超过其负荷。当然小编这方面可能不是很专业,详细描述请看文献或者咨询电气专业的比较合适。
考虑一个能源系统,定义如下的参数集合:
- 为公交车集合(消耗电的)
- 为发电机集合
- 为线路的集合
- 为一个时长周期
对于每一个发电机和每一个小时,定义如下的决策变量:
- 为一个0-1变量,表示发电机在时间是否开启
- 为连续的变量,表示发电机在时间所产生的电量
构建SCUC的模型如下(完整模型请参考文献Appendix):
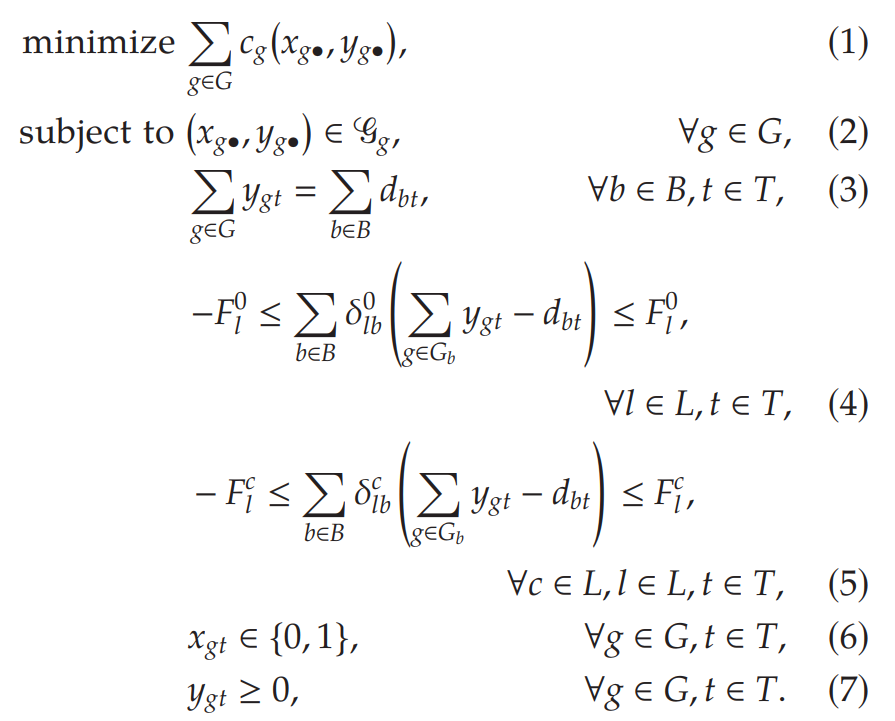
In the objective function, is a piecewise-linear function that includes the startup, shutdown, and production costs for generator . The notation is a shorthand for the vector , where .
Constraint (2)enforces a number of constraints that are local for each generator, including production limits, minimum-up and minimum-down running times, and ramping rates, among others.Constraint (3)enforces that the total amount of power produced equals the sum of the demands at each bus.Constraint (4)enforces the deliverability of power under normal system conditions. The set denotes the set of generators attached to bus . where are real numbers known as injection shift factors (ISFs). Let be its flow limit (in megawatt-hours) under normal conditions and be its flow limit when there is an outage online .Constraints (5)enforce the deliverability of power under the scenario that line has had an outage. The bounds and the ISFs may be different under each outage scenario.
上面的模型中,一个比较显著的特点是,Constraint (4)和Constraints (5) (Transmission Constraints) 对模型的求解有着非常关键的影响。这两个约束的数量是传输路线数的平方,而大型的能源一般拥有超过10000条的传输线路,这样一来,两个约束的总数量就可能超过一亿了。
To make matters worse, these constraints are typically very dense, which makes adding them all to the formulation impractical for large-scale instances not only because of degraded MIP performance but also because of memory requirements.
Fortunately, it has been observed that enforcing only a very small subset of these constraints is already sufficient to guarantee that all the remaining constraints are automatically satisfied.
02 Setting and Learning Strategies上面已经介绍了SCUC的模型以及模型的一些特点。目前求解SCUC的方法还是MIP (Mixed-Integer Programming) 为主,但是由于前面提到的难点,MIP在大规模问题上的表现一般。基于此,作者在文章中结合machine learning (ML) 提出了一种新的优化框架,该框架主要包含了三个ML的模型:
- The first model is designed to predict, based on statistical data, which constraints are necessary in the formulation and which constraints can be safely omitted.
- The second model constructs, based on a large number of previously obtained optimal solutions, a (partial) solution that is likely to work well as a warm start.
- The third model identifies,with very high confidence, a smaller-dimensional affine subspace where the optimal solution is likely to lie, leading to the elimination of a large number of decision variables and significantly reducing the complexity of the problem.
在开始之前,先介绍一些设置的参数。Assume that every instance of SCUC is completely described by a vector of real-valued parameters . These parameters include only the data that are unknown to the market operators the day before the market-clearing process takes places. For example, they may include the peak system demand and the production costs for each generator. In this work, we assume that network topology and the total number of generators are known ahead of time, so there is no need to encode them via parameters. We may therefore assume that , where is fixed. We are given a set of training instances that are similar to the instance we expect to solve during actual market clearing.
2.1 Learning Violated Transmission Constraints
如同前面提到的,求解SCUC的MIP时,较大的挑战就是如何处理数量巨大的Transmission Constraints,即模型中的Constraint (4)和Constraints (5)。因此第一个ML model要做的就是预测哪些Transmission Constraints需要在初始时就添加到SCUC的relaxation中而哪些又可以直接忽略(即这些约束不会被违背)。
在此之前,作者先使用了Xavier et al. (2019)其实就是他自己。。。提出的一个有效求解SCUC的iterative contingency screening algorithm:
The method works by initially solving a relaxed version of SCUC where no transmission or N − 1 security constraints are enforced. At each iteration, all violated constraints are identified, but only a small and carefully selected subset is added to the relaxation. The method stops when no further violations are detected, in which case the original problem is solved.
基于此,作者修改了上面的方法,加入了一个ML predictor。令为传输线的集合,模型中关于Transmission Constraints如下:
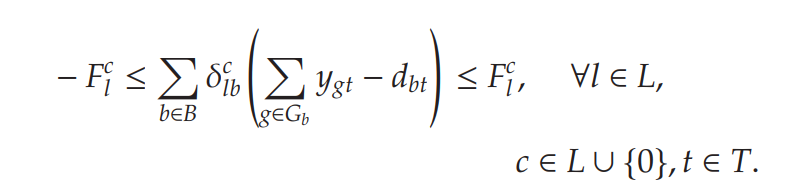
假设定制的MIP solver接受来自ML predictor的指示:
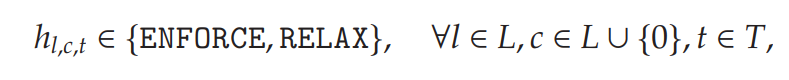
indicating whether the thermal limits of transmission line , under contingency scenario (normal conditions对应约束(4),而outage online对应约束(5) ), at time t, are likely to be binding in the optimal solution. Given these hints, the solver proceeds as described in Algorithm 1.

In the first iteration, only the transmission constraints specified by the hints are enforced. For the remaining iterations, the solver follows exactly the same strategy as the baseline method and keeps adding small subsets of violated constraints until no further violations are found.
If the predictor is successful and correctly predicts a superset of the binding transmission constraints, then only one iteration is necessary for the algorithm to converge.
If the predictor fails to identify some necessary constraints, the algorithm may require additional iterations but still returns the correct solution.
For this prediction task, we propose a simple learning strategy based on kNN. Let be the training parameters. During training, the instances are solved using Algorithm 1, where the initial hints are set to RELAX for all constraints. During the solution of each training instance , we record the set of constraints that was added to the relaxation by Algorithm 1. During the test, given a vector of parameters , the predictor finds a list of k vectors that are the closest to and sets = ENFORCE if appears in at least p% of the sets , where p is a hyperparameter.
本文设置,因为少添加一个正确的Transmission Constraints所来带的损失要比多添加一堆不正确的Transmission Constraints要低得多(少添加后面加回去就行了,而多添加了,每次都slow down模型的求解速度)。
2.2 Learning Warm Starts
求解SCUC的另一个挑战就是如何获得高质量的可行初始解,作者吸收了很多文献中的方法的精髓。Our aim is to produce, based on a large number of previous optimal solution, a (partial) solution that works well as a warm start.
Let be the training parameters, and let be their optimal solutions. In principle, the entire list of solutions could be provided as warm starts to the solver.
We propose instead the use of kNN to construct a single (partial and possibly infeasible) solution, which should be repaired by the solver. The idea is to set the values only for the variables that we can predict with high confidence and to let the MIP solver determine the values for all the remaining variables. To maximize the likelihood of our warm starts being useful, we focus on predicting values for the binary variables ; all continuous variables are determined by the solver.
Given a test parameter , first we find the k solutions corresponding to the k nearest training instances .
Then, for each variable , we verify the average of the values . If , where is a hyperparameter, then the predictor sets to 1 in the warm start solution. If , then the value is set to 0. In any other case, the value is left undefined.
2.3 Learning Affine Subspaces
在实际的操作中,工人凭借着以往的经验,知道很多特征。比如,他们知道每天有多少电量必然会被消耗的,人工操作的时候,这些是非常显而易见的。但是,一旦建模成MIP,利用solver来求解的时候,这些就完全丢掉了。
Given the fixed characteristics of a particular power system and a realistic parameter distribution, new constraints probably could be safely added to the MIP formulation of SCUC to restrict its solution space without affecting its set of optimal solutions. In this subsection, we develop a ML model for finding such constraints automatically, based on statistical data.

文中没有给出的具体含义,小编猜想应该是对应的是中的gt,即哪些变量;而对应的是的取值,即上面的式子(8)、(9)、(10)。这个模型的主要功能是通过添加上面的约束,进一步限制解的空间,从而加快算法的速度。但是得保证,砍掉的那部分不会出现在最优解中。更详细的描述请看论文。
03 Computational Experiments测试算例以下网址可以获得:
https://zenodo.org/record/3648686
3.1 Evaluation of Transmission Predictor
zerocorresponds to the case where no ML is used.tr:nearest, we add to the initial relaxation all constraints that were necessary during the solution of the most similar training variation.tr:all, we add all constraints that were ever necessary during training.tr:knn:kcorrespond to the method outlined in Section 3.1, where is the hyperparameter describing the number of neighbors.tr:perfshows the performance of the theoretically perfect predictor, which can predict the exact set of constraints found by the iterative method, with perfect accuracy, under zero running time.
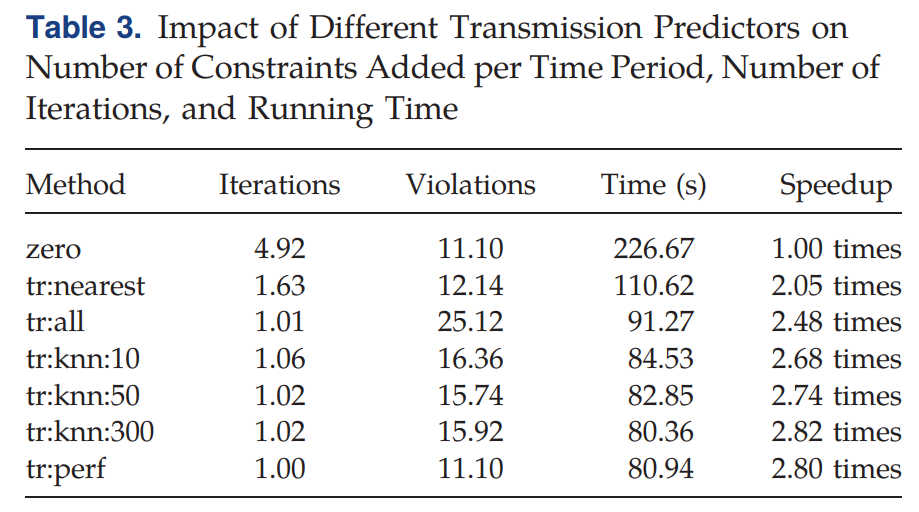
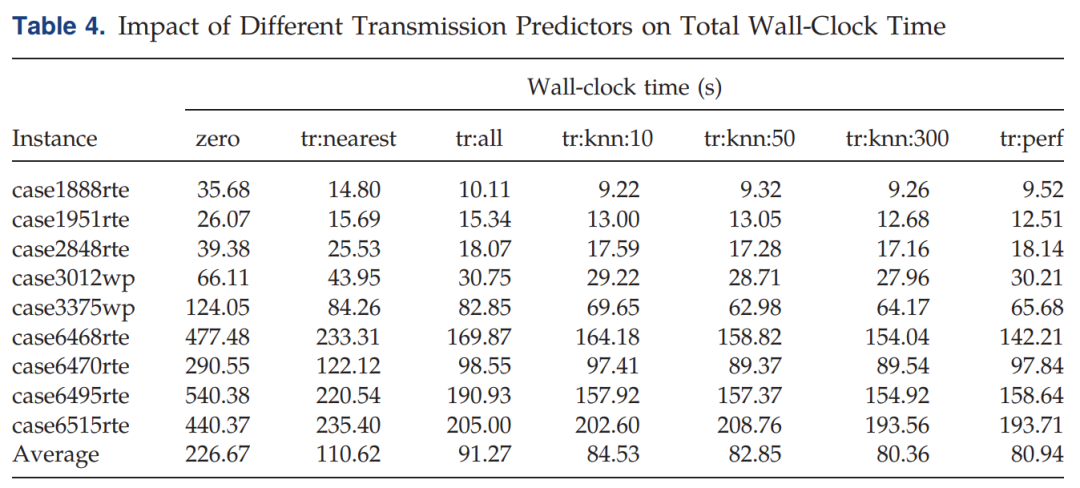
以zero为基准,使用了ML的基本速度都快了2-3倍不等。
3.2 Evaluation of the Warm-Start Predictor
Strategy tr:knn:300, as introduced in Section 4.3, is included as a baseline and only predicts transmission constraints and not warm starts. All other strategies presented in this section are built on top of tr:knn:300; that is, prediction of transmission constraints is performed first, using tr:knn:300, and then prediction of warm starts is performed.
In strategies ws:collect:n, we provide to the solver warm starts, containing the optimal solutions of the nearest training variations.
Strategies ws:knn:k : p, for and , correspond to the strategy described in Section 3.2.
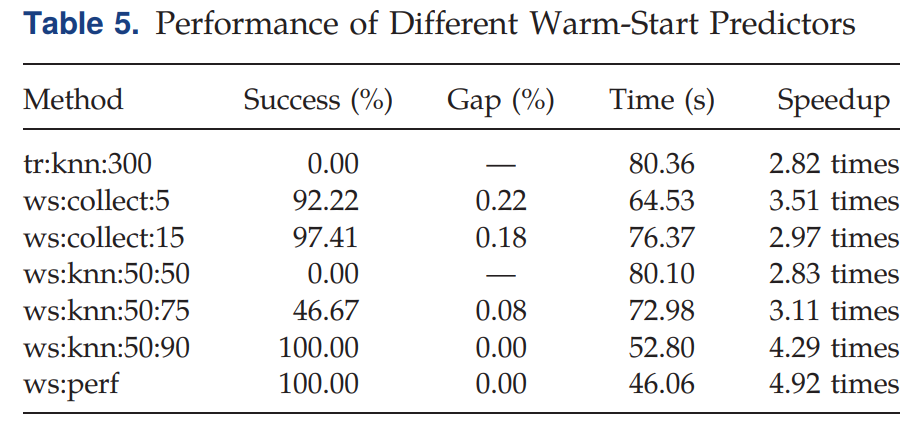
在Table 5中:
- Success(%): 表示Warm-Start Predictor给出一个可行解的成功率
- Gap (%): 表示Warm-Start Predictor给出的解和最优解的差距,越低越好,为0表示Warm-Start Predictor初始时给出了最优解。
- Time (s): 求解时间
Table 6中的tr:knn:50写错了,应该是tr:knn:300。。。
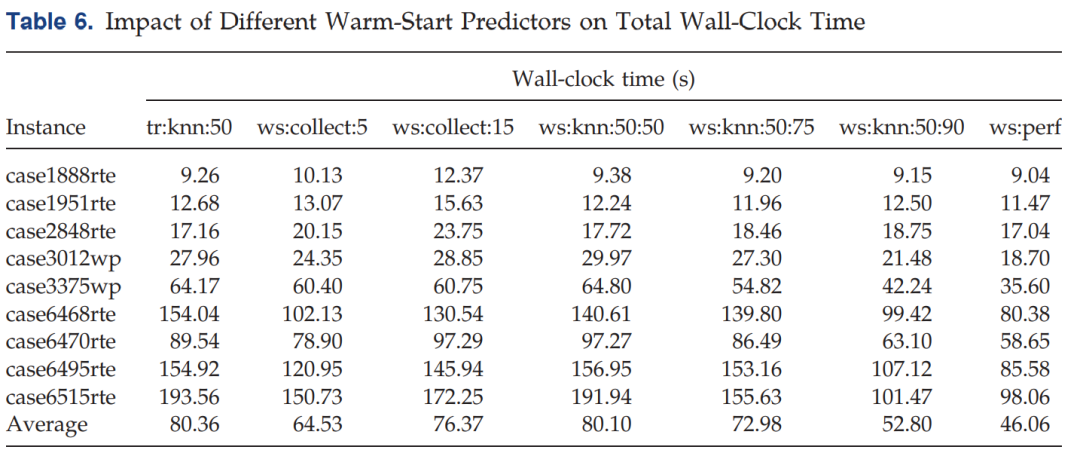
可以看到,结合第一个model,加了Warm-Start Predictor以后,速度有显著提升,相对于tr:knn:300.
3.3 Evaluation of the Affine Subspace Predictor
同样, Method tr:knn:300 is the kNN predictor for transmission constraints. This predictor does not add any hyperplanes to the relaxation and is used only as a baseline. All the following predictors were built on top of tr:knn:300.
几个aff:的Predictor不同主要在于内部设置的一些参数不同,详细看论文好了。在Table 7中:
- Feasible (%): 表示加了该hyperplanes以后(即缩小了解空间),所生成的解可行的百分比
- Gap (%): 以95%下的0.07为例,表示有95%的问题变体(加入hyperplanes以后)得出来的gap与最优解相差0.07
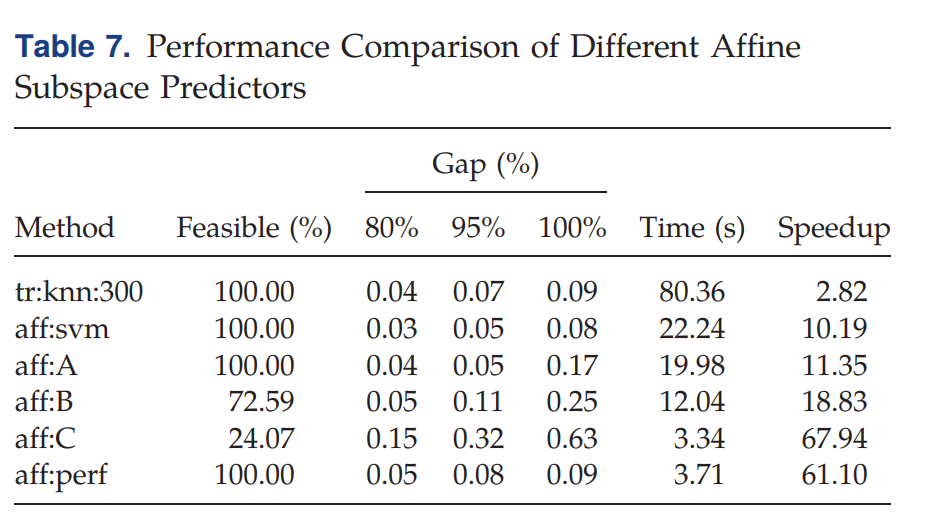
Four different strategies are presented: no ML (0), transmission prediction (tr:knn:300), transmission plus warm-start prediction (ws:knn:50:90), and transmission plus affine subspace prediction (aff:svm).
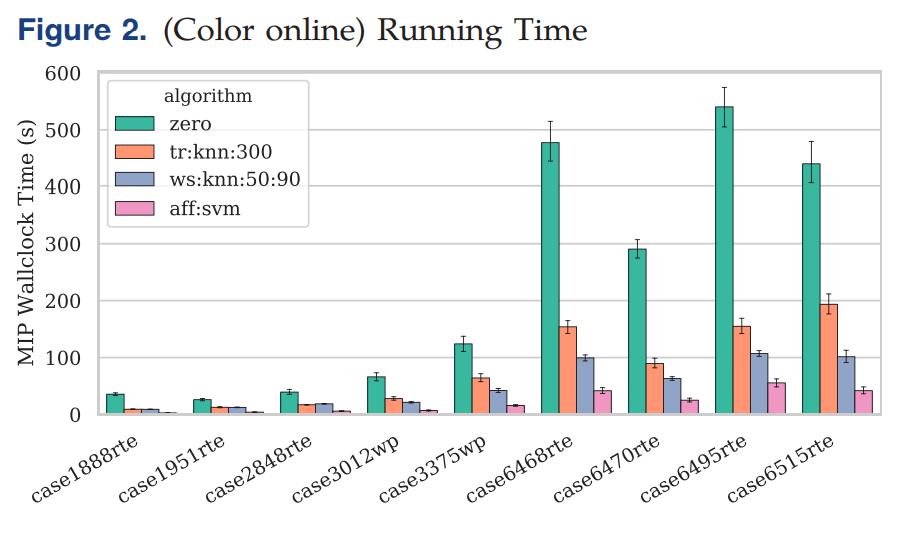
可以看到aff:svm的时间是最短的。Overall, using different ML strategies, we were able to obtain a 4.3 times speedup while maintaining optimality guarantees (ws:knn:50:90) and a 10.2 times speedup without guarantees but with no observed reduction in solution quality (aff:svm).
[1] Álinson S. Xavier, Feng Qiu, Shabbir Ahmed (2020) Learning to Solve Large-Scale Security-Constrained Unit Commitment Problems. INFORMS Journal on Computing
推荐阅读:
干货 | 学习算法,你需要掌握这些编程基础(包含JAVA和C++)
记得点个在看支持下哦~
