
联邦学习(Federated Learning)详解以及示例代码

来源:DeepHub IMBA 本文约6000字,建议阅读15分钟
本文为你介绍联邦学习的详细讲解及示例代码。
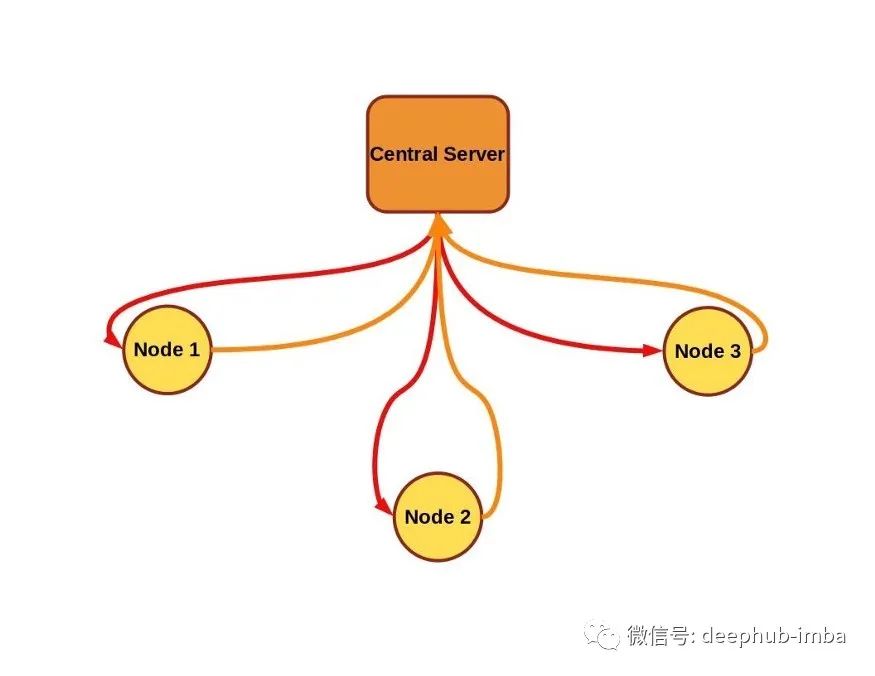
联邦学习也称为协同学习,它可以在产生数据的设备上进行大规模的训练,并且这些敏感数据保留在数据的所有者那里,本地收集、本地训练。在本地训练后,中央的训练协调器通过获取分布模型的更新获得每个节点的训练贡献,但是不访问实际的敏感数据。
手机输入法的下一个词预测(e.g. McMahan et al. 2017, Hard et al. 2019) 健康研究(e.g. Kaissis et al. 2020, Sadilek et al. 2021) 汽车自动驾驶(e.g. Zeng et al. 2021, OpenMined 的文章) “智能家居”系统(e.g. Matchi et al. 2019, Wu et al. 2020)
联邦学习简介
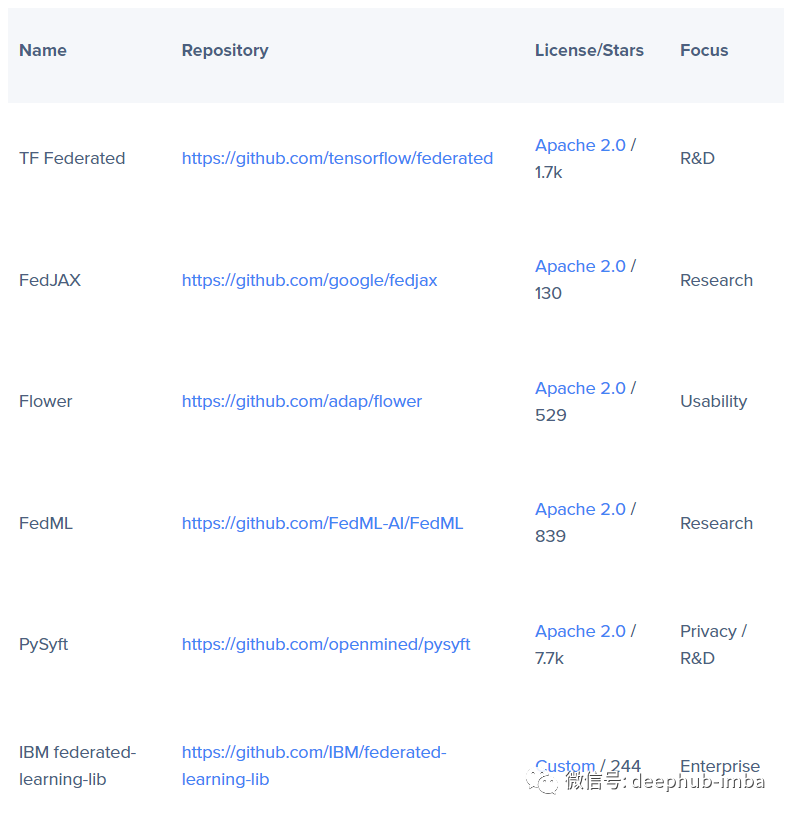
联邦学习代码实现
virtualenv flower_env python==python3
source flower_env/bin/activate
pip install flwr==0.17.0# I'm running this example on a laptop (no gpu)
# so I am installing the cpu only version of PyTorch
# follow the instructions at https://pytorch.org/get-started/locally/
# if you want the gpu optionpip install torch==1.9.1+cpu torchvision==0.10.1+cpu \
-f https://download.pytorch.org/whl/torch_stable.htmlpip install scikit-learn==0.24.0
import argparse
import flwr as fl
import torch
from pt_client import get_data, PTMLPClient
def get_eval_fn(model):
# This `evaluate` function will be called after every round
def evaluate(parameters: fl.common.Weights):
loss, _, accuracy_dict = model.evaluate(parameters)
return loss, accuracy_dict
return evaluate
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-r", "--rounds", type=int, default=3,\
help="number of rounds to train")
args = parser.parse_args()
torch.random.manual_seed(42)
model = PTMLPClient(split="val")
strategy = fl.server.strategy.FedAvg( \
eval_fn=get_eval_fn(model),\
)
fl.server.start_server("[::]:8080", strategy=strategy, \
config={"num_rounds": args.rounds})
class PTMLPClient(fl.client.NumPyClient, nn.Module):
def __init__(self, dim_in=4, dim_h=32, \
num_classes=3, lr=3e-4, split="alice"):
super(PTMLPClient, self).__init__()
self.dim_in = dim_in
self.dim_h = dim_h
self.num_classes = num_classes
self.split = split
self.w_xh = nn.Parameter(torch.tensor(\
torch.randn(self.dim_in, self.dim_h) \
/ np.sqrt(self.dim_in * self.dim_h))\
)
self.w_hh = nn.Parameter(torch.tensor(\
torch.randn(self.dim_h, self.dim_h) \
/ np.sqrt(self.dim_h * self.dim_h))\
)
self.w_hy = nn.Parameter(torch.tensor(\
torch.randn(self.dim_h, self.num_classes) \
/ np.sqrt(self.dim_h * self.num_classes))\
)
self.lr = lr
def get_parameters(self):
my_parameters = np.append(\
self.w_xh.reshape(-1).detach().numpy(), \
self.w_hh.reshape(-1).detach().numpy() \
)
my_parameters = np.append(\
my_parameters, \
self.w_hy.reshape(-1).detach().numpy() \
)
return my_parameters
def set_parameters(self, parameters):
parameters = np.array(parameters)
total_params = reduce(lambda a,b: a*b,\
np.array(parameters).shape)
expected_params = self.dim_in * self.dim_h \
+ self.dim_h**2 \
+ self.dim_h * self.num_classes
start = 0
stop = self.dim_in * self.dim_h
self.w_xh = nn.Parameter(torch.tensor(\
parameters[start:stop])\
.reshape(self.dim_in, self.dim_h).float() \
)
start = stop
stop += self.dim_h**2
self.w_hh = nn.Parameter(torch.tensor(\
parameters[start:stop])\
.reshape(self.dim_h, self.dim_h).float() \
)
start = stop
stop += self.dim_h * self.num_classes
self.w_hy = nn.Parameter(torch.tensor(\
parameters[start:stop])\
.reshape(self.dim_h, self.num_classes).float()\
)
self.act = torch.relu
self.optimizer = torch.optim.Adam(self.parameters())
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, x):
x = self.act(torch.matmul(x, self.w_xh))
x = self.act(torch.matmul(x, self.w_hh))
x = torch.matmul(x, self.w_hy)
return x
def get_loss(self, x, y):
prediction = self.forward(x)
loss = self.loss_fn(prediction, y)
return loss
def fit(self, parameters, config=None, epochs=10):
self.set_parameters(parameters)
x, y = get_data(split=self.split)
x, y = torch.tensor(x).float(), torch.tensor(y).long()
self.train()
for ii in range(epochs):
self.optimizer.zero_grad()
loss = self.get_loss(x, y)
loss.backward()
self.optimizer.step()
loss, _, accuracy_dict = self.evaluate(self.get_parameters())
return self.get_parameters(), len(y), \
{"loss": loss, "accuracy": \
accuracy_dict["accuracy"]}
def evaluate(self, parameters, config=None):
self.set_parameters(parameters)
val_x, val_y = get_data(split="val")
val_x = torch.tensor(val_x).float()
val_y = torch.tensor(val_y).long()
self.eval()
prediction = self.forward(val_x)
loss = self.loss_fn(prediction, val_y).detach().numpy()
prediction_class = np.argmax(\
prediction.detach().numpy(), axis=-1)
accuracy = sklearn.metrics.accuracy_score(\
val_y.numpy(), prediction_class)
return float(loss), len(val_y), \
{"accuracy":float(accuracy)}
def get_data(split="all"):
x, y = sklearn.datasets.load_iris(return_X_y=True)
np.random.seed(42); np.random.shuffle(x)
np.random.seed(42); np.random.shuffle(y)
val_split = int(0.2 * x.shape[0])
train_split = (x.shape[0] - val_split) // 2
eval_x, eval_y = x[:val_split], y[:val_split]
alice_x, alice_y = x[val_split:val_split + train_split], y[val_split:val_split + train_split]
bob_x, bob_y = x[val_split + train_split:], y[val_split + train_split:]
train_x, train_y = x[val_split:], y[val_split:]
if split == "all":
return train_x, train_y
elif split == "alice":
return alice_x, alice_y
elif split == "bob":
return bob_x, bob_y
elif split == "val":
return eval_x, eval_y
else:
print("error: split not recognized.")
return None
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-s", "--split", type=str, default="alice",\
help="The training split to use, options are 'alice', 'bob', or 'all'")
args = parser.parse_args()
torch.random.manual_seed(42)
fl.client.start_numpy_client("localhost:8080", client=PTMLPClient(split=args.split))
import argparse
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.metrics
import torch
import torch.nn as nn
from functools import reduce
import flwr as fl
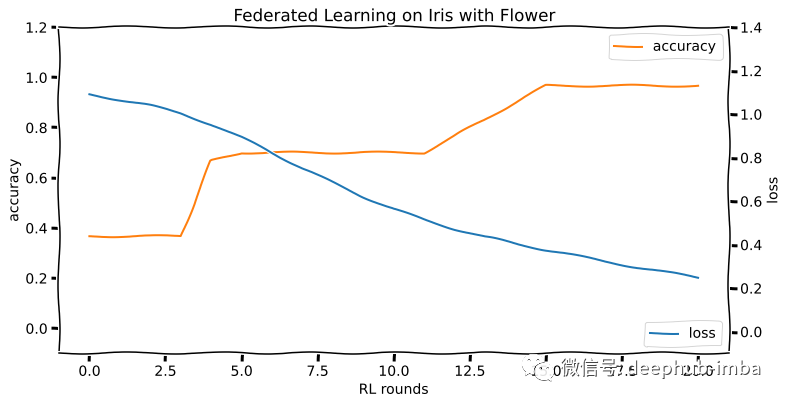
python -m pt_server -r 40python -m pt_client -s alicepython -m pt_client -s bob
联邦学习的未来
编辑:王菁
校对:汪雨晴
评论