
联邦学习技术应运而生!
联邦学习作为一种强调数据安全和隐私保护的分布式机器学习技术,在人工智能广泛发挥作用的背景下,受到广泛关注。
人工智能技术不断发展,在不同前沿领域体现出强大活力。然而,现阶段人工智能技术的发展受到数据的限制,公众对于数据隐私更为敏感。数据孤岛和隐私问题的出现使人工智能技术发展受限,同时各机构、企业所拥有的数据又有极大的潜在应用价值。那么,如何在满足数据安全和合规要求的前提下,利用多方异构数据进一步学习以推动人工智能的发展呢?
为了解决这个问题,联邦学习技术应运而生。
什么是联邦学习
联邦学习是一种带有隐私保护、安全加密技术的分布式机器学习框架,旨在让分散的各参与方在满足不向其他参与者披露隐私数据的前提下,协作进行机器学习的模型训练。
联邦学习架构
联邦学习的架构分为两种,一种是中心化联邦(客户端/服务器)架构,一种是去中心化联邦(对等)架构。
1.客户端/服务器架构
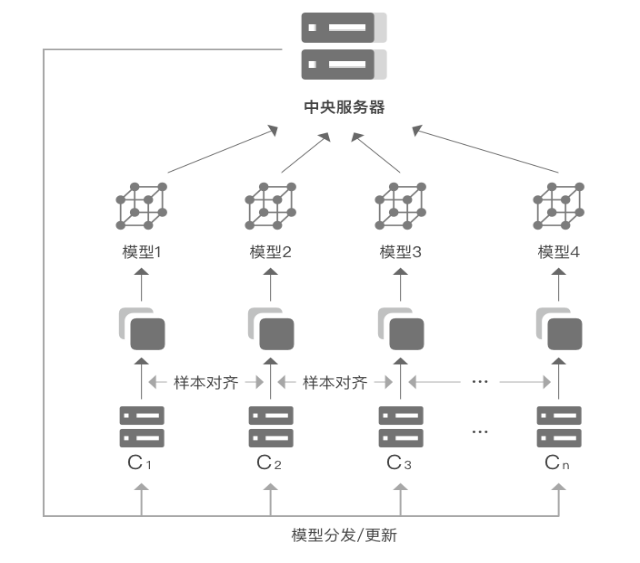
在客户端/服务器架构中,各参与方须与中央服务器合作完成联合训练,如图1所示,过程如下:
(1)中央服务器先将初始模型分发给各参与方,然后各参与方根据本地数据集分别对所得模型进行训练。
(2)接着,各参与方将本地训练得到的模型参数加密上传至中央服务器。
(3)中央服务器对所有模型梯度进行聚合,再将聚合后的全局模型参数加密传回至各参与方。
2.对等架构
在对等架构中,不存在中央服务器,所有交互都是参与方之间直接进行的,如图2所示:
在对等架构中,由于没有第三方服务器的参与,参与方之间直接交互。因此,当参与方对原始模型训练后,需要将本地模型参数加密传输给其余参与联合训练的数据持有方。

联邦学习行业解决方案
联邦学习可以在不同机构间发挥作用,兼具模型质量无损、数据隐私安全的优势,具有广泛的应用场景。
1. 联邦学习+智慧金融
金融行业加速数字化转型的过程中,银行、保险、投资等行业都面临着有效数据欠缺与隐私保护安全的双重挑战。
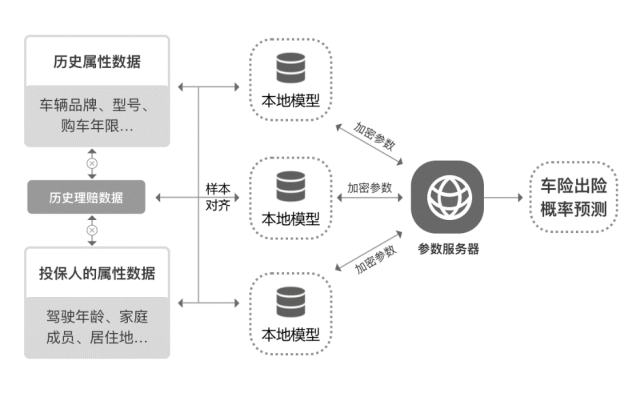
以车险为例, 对于车辆的出险概率预测可以根据车辆的属性数据(如车辆型号等)、车辆历史理赔数据以及车辆所有人的属性数据(如投保人驾驶年龄等)。这些数据涉及用户隐私,分布在不同组织机构内,因此车辆出险概率的构想实际落地非常困难。
若引入了联邦学习的车险出险概率预测方法,可以在各方数据不出本地的情况下,联合各方数据进行训练,包括车辆的属性数据、车辆历史理赔数据以及车辆所有人的属性数据,进行车辆出险概率的预测,进而使车辆承保、定价更加合理。
2. 联邦学习+智慧城市
智慧城市建设是国家数字战略的关键组成部分,在包括零售、交通、物流、政府在内的智慧城市场景中,存在数据利用率低、模型精确度低等问题。
以零售为例,传统零售企业只拥有本地门店消费记录,无法整体把握行业态势。但各企业、机构单纯的数据融合是无法保障数据安全和用户隐私的,如何解决这些问题成为实现数字化新零售的重点。
现拟建立基于联邦学习的商家洞察系统,其结构如图4所示。在这一智慧零售场景中,有4个数据持有方:社交平台,拥有用户个性化特征;电商平台,拥有用户详细的线上消费记录;零售商和品牌商,拥有用户在本地的消费记录。在联邦学习过程中,各方根据本地数据训练本地模型,然后与协调方通信以获得最新模型参数,并以此在本地做出调整。

3. 联邦学习+智慧医疗
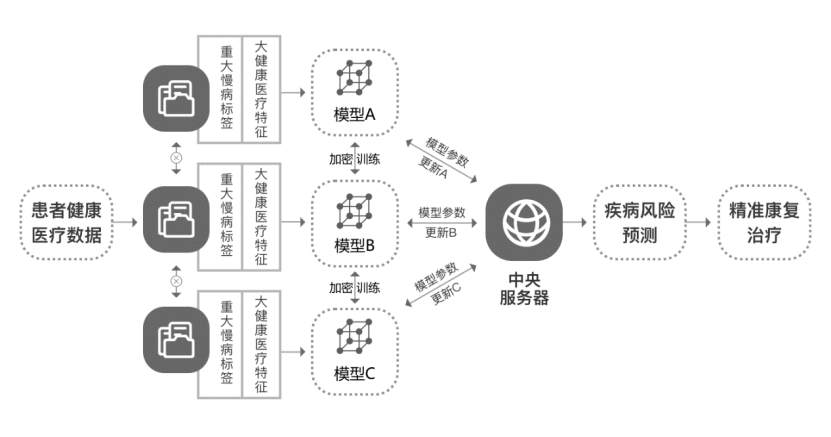
在医疗领域,人工智能有着巨大的潜力和市场。例如 "疾病风险预测模型"常被用来预测某种疾病在未来发病的可能性,从而能针对性地对康复项目进行调整。然而,由于患者的隐私数据受到严格保护,各医疗机构间无法轻易共享,这使医疗领域中AI与数据的结合变得尤为困难。
联邦学习技术可以在本地医院端加密患者样本,通过加密协议在各方传递加密之后的模型梯度等参数信息,各个医疗机构通过对全局下发的加密信息进行客户端解密,实现模型参数更新,从而在保护双方原始数据不被暴露的前提下,联合双方用户特征进行疾病预测模型的训练。
这种基于联邦学习技术和先验医学知识的疾病风险预测体系,成功解决了面向训练过程中的隐私保护难题,其提供的疾病预测结果为医疗健康应用的快速落地,如癌症早筛等,提供了新的契机。
以上内容摘自《深入浅出联邦学习:原理与实践》,经出版方授权发布
本书从多角度角度出发介绍了联邦学习的理论,并且在联邦学习实战部分也详细叙述了联邦学习开源框架的安装指南、测试样例和实操部署流程,详情请参考《深入浅出联邦学习:原理与实践》。