
ICCV2023|目标检测新突破!AlignDet:支持各类检测器完全自监督预训练的框架
点击下方卡片,关注「集智书童」公众号
作者丨Garfield来源丨极市平台编辑丨小书童

论文链接:https://arxiv.org/abs/2307.11077
项目地址:https://github.com/liming-ai/AlignDet
1. 引言
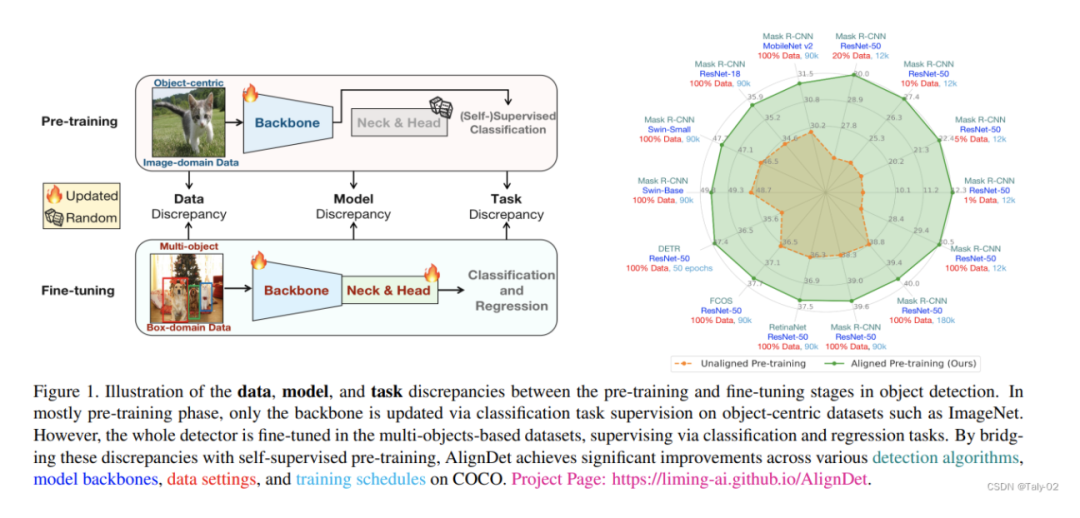
这篇论文主要研究目标检测领域的自监督预训练方法。作者首先指出,当前主流的预训练-微调框架在预训练和微调阶段存在数据、模型和任务上的不一致。具体来说
数据不一致预训练通常在分类数据集上进行,如ImageNet,而微调数据集像COCO包含多个目标物体。数据特征和域的差异会导致预训练偏离下游任务。
模型不一致当前预训练方法主要聚焦在模型的部分模块,如骨干网络,而检测器的其他关键模块如RPN和回归头没有进行预训练。
任务不一致现有预训练只将分类作为预训练任务,没有学习到目标相关的位置上下文信息,如proposal生成、目标分配和框回归。
这些不一致性可能导致目标检测性能的局限、泛化能力差和收敛速度慢的问题。为此,作者提出AlignDet框架,可以调适到不同检测器中,以弥合预训练和微调中的差异。
AlignDet将预训练过程解耦为Image-domain预训练和Box-domain预训练两个阶段。Image-domain预训练优化检测网络的骨干提取高层语义特征,Box-domain预训练则学习实例级语义和任务感知的概念,来初始化骨干以外的模块。具体来说
在Image-domain预训练中,可以用分类器对骨干网络进行监督预训练,也可以用最近出现的自监督方法进行无监督预训练。
在Box-domain预训练中,使用选择性搜索生成伪标签,构建两视图进行对比学习和坐标回归损失计算,以适应检测导向的任务。同时固定骨干网络避免过拟合噪声标签。
那么对于数据、模型和任务存在的不一致性,AlignDet都是怎么解决的呢?首先对于数据不一致性方面,AlignDet通过Box-domain预训练直接在目标检测数据集上进行,而不是仅在分类数据集上预训练。这使得预训练过程可以适应目标检测的数据分布, bridge the gap between pre-training and fine-tuning datasets。至于模型不一致性方面,AlignDet可以预训练检测器中的所有模块,而不仅仅是骨干网络。这确保了检测头等关键模块可以得到良好的初始化,有利于迁移到下游任务。从任务不一致性的方面来看,AlignDet构建了检测导向的预训练任务,既包含分类也包含回归。这使得预训练不仅学习语义信息,还学习物体的坐标信息,更贴近目标检测的实际任务。进一步来说,AlignDet通过Image-domain和Box-domain解耦设计,可以充分利用现有预训练的骨干网络,提升预训练效率。同时,它也是第一个支持各种检测器完全自监督预训练的框架。
从实验结果来看,AlignDet可以显著提升各种检测器在不同训练策略和数据量下的性能。例如,在COCO上使用12个epoch预训练,FCOS精度提升5.3 mAP,Mask R-CNN提升3.3 mAP。这充分验证了AlignDet可以有效解决目标检测预训练与微调中的差异,并取得显著的性能改进。
2. 方法
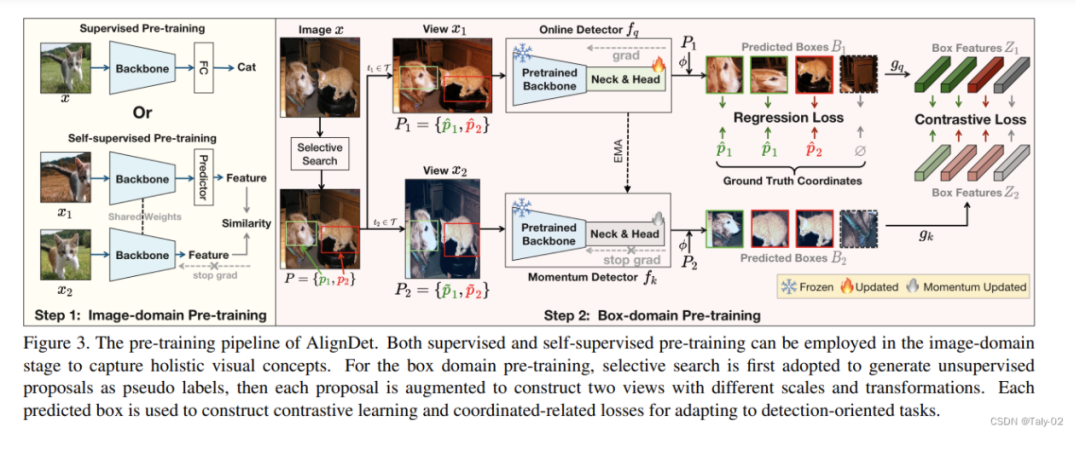
这篇论文提出了AlignDet框架,以解决目标检测中预训练和微调过程中的数据、模型和任务的不一致性问题。该框架包含Image-domain预训练提取语义特征和Box-domain预训练学习实例级语义的两个阶段。Box-domain预训练利用选择性搜索生成伪标签,并通过对比学习和坐标回归任务进行检测导向的预训练。
2.1 Image-domain Pre-training
在AlignDet框架中,Image-domain预训练主要针对骨干网络,以提取语义特征。该过程可以使用监督或自监督方式进行。
以自监督预训练为例,给定输入图像x,可以通过数据增强构建两个视图x1和x2。然后骨干网络backbone可以学习到视角不变的表示:
具体而言,可以使用对比学习方法SimSiam,它通过预测器predictor和停 gradient阻断梯度反向传播,最大化不同视图表示的相似性,获得泛化能力更强的特征:
这里的predictor通常是一个小的MLP,stopgrad表示停止梯度回传。
通过在大规模图像分类数据集上预训练,骨干网络可以学到语义特征,为后续的Box-domain预训练提供输入。这种监督或自监督的Image-domain预训练可以有效提取视角不变的特征表示,是AlignDet框架的第一步。
2.2 Box-domain Pre-training
AlignDet框架中的Box-domain预训练主要针对检测器中除骨干网络之外的模块,以学习实例级语义和任务感知的先验知识。Box-domain预训练包含以下几个关键步骤:
Box-domain Pre-training:Box-domain Pre-training的目的是生成用于后续预训练的伪标签。它使用选择性搜索算法从图像中生成多个区域proposal,作为预训练时的伪真值框标签。这可以提供多对象和不同位置、尺度的样本,使预训练数据更贴近目标检测场景。实现方式是:对输入图像执行选择性搜索,获得proposal集P。同时构建图像的两增强视图,proposal集也做相应变换,获得P1和P2。检测器的回归模块预测两视图的框坐标B1和B2。
给定输入图像x,使用选择性搜索生成区域proposal集P = {p1, p2, ..., pn}作为伪标签。对x进行数据增强构建两视图x1和x2,proposal集也同时进行变换生成P1和P2。检测器的回归相关模块freg预测两视图的框坐标:
这里φ表示目标分配操作,如计算IoU匹配。每视图的预测框坐标为b = (x, y, w, h, l)。
Box-domain Contrastive Learning:目的是学习实例级的语义特征表示。它利用预测的框坐标,最大化同一proposal在两视图中特征的相似度,实现对比学习。实现方式是:基于预测框B1和B2,提取两视图的特征表示Z1和Z2。定义正负样本,通过InfoNCE对比损失拉近正样本距离,推远负样本距离。
基于预测的框坐标,可以提取特征向量用于对比学习:
这里
表示特征提取模块,
是投影头。通过最大化同一proposal在两视图中的特征相似度,进行对比学习:
其中
是查询框的特征,
是正样本特征集,
是负样本特征集,
是温度参数。
Overall Loss:Box-domain预训练的总损失为对比损失和坐标回归损失之和:
这里
表示不同检测器的坐标回归损失。

3. 实验
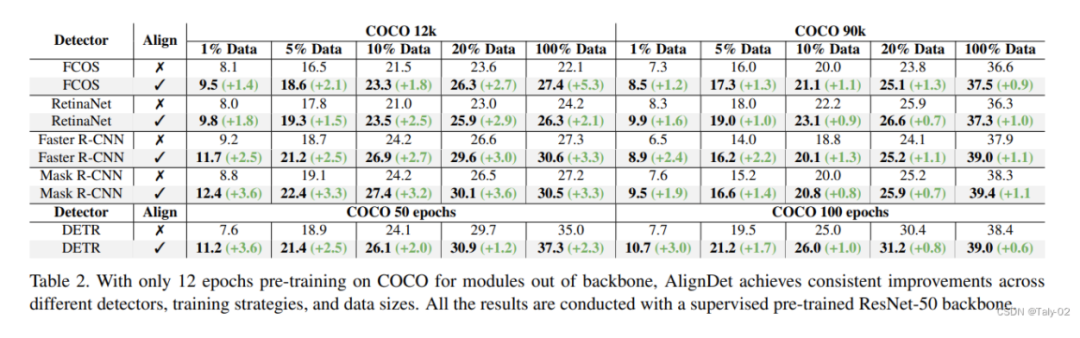
从Table 2的实验结果可以看出,AlignDet与只进行Image-domain预训练的方法相比,在不同的检测器、训练策略和数据量设置下都获得了显著的性能提升。在数据量方面,随着训练数据的减少,AlignDet的提升越明显。例如在只有1%数据的情况下,AlignDet分别为FCOS、RetinaNet、Faster R-CNN和Mask R-CNN带来了1.4、1.8、2.5和3.6 mAP的提升。这说明AlignDet学到的知识可以缓解数据不足的问题。
在训练策略方面,在训练轮数较少(12k iters)的情况下,AlignDet同样带来显著提升,例如Mask R-CNN在12k iters下提升3.2 mAP。这证明AlignDet加速了模型收敛速度。
在检测器方面,AlignDet对一阶段模型FCOS和RetinaNet、两阶段模型Faster R-CNN、query基础模型DETR都取得明显的效果提升。这展示了AlignDet的普适性。即使在充足数据(100% COCO)和充分训练迭代(90k iters)下,AlignDet仍可带来约1.0 mAP的提升。这进一步证明了AlignDet的有效性。与其他方法相比,AlignDet对各类检测器都获得显著且一致的效果改进,尤其是在低数据量或训练迭代较少的困难设置下,而其他方法的提升则相对较小且局限。这充分证明AlignDet可以有效地解决预训练和微调过程中的差异,为各类检测方法提供强有力的预训练方案。
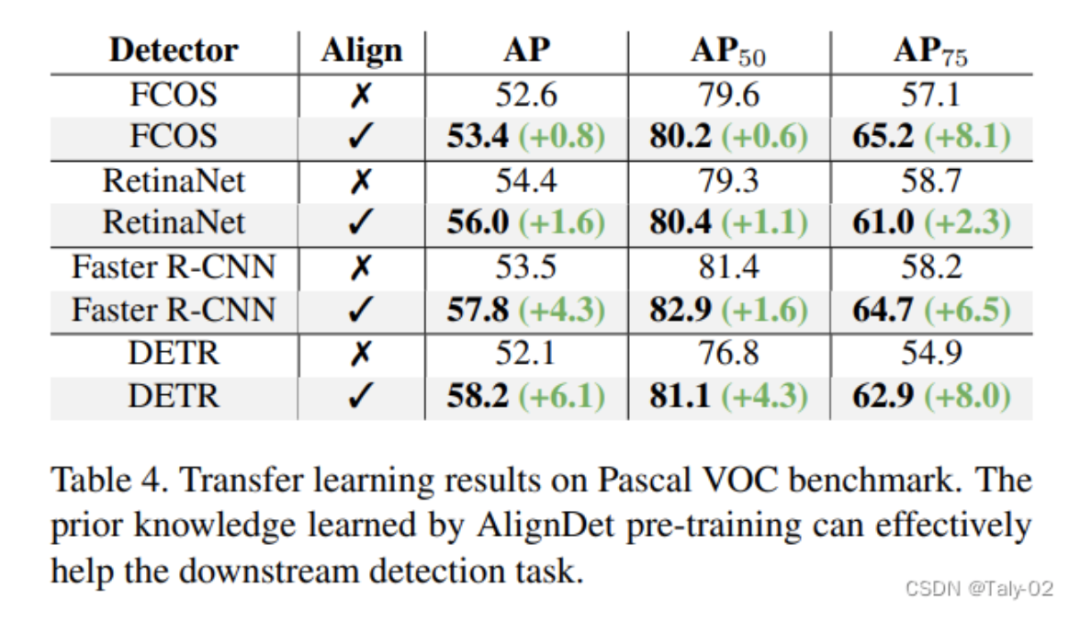
从Table 4的迁移学习结果可以看出,AlignDet在COCO数据集上进行预训练后,可以有效地迁移至Pascal VOC数据集并提升下游检测性能。具体来看:AlignDet在所有检测器上都获得了显著的AP提升,特别是高阈值metric AP75的提升非常明显。例如Faster R-CNN的AP75提升了6.5。对于RetinaNet和FCOS等一阶段检测器而言,AlignDet预训练主要增强了分类能力,即AP50指标获得明显提升。这与一阶段检测器更依赖分类的特点一致。对于两阶段检测器Faster R-CNN,AlignDet预训练主要提升了回归准确度,即AP75指标明显增强。这与两阶段检测器同时优化分类和回归的流程吻合。而DETR这样的query基础检测器,AlignDet在分类和回归两个指标上都取得显著提升。
也就是说,AlignDet学到的知识能有效迁移到下游检测任务和数据集上,提升不同检测器的分类和回归能力。这进一步证明了AlignDet学习到的语义和坐标信息对目标检测任务具有普适的优化作用。这表明AlignDet不仅适用于COCO等多对象检测,也适用于VOC等较简单的少类检测。
4. 讨论
这篇论文的一大优点在于作者针对目标检测预训练与微调之间的数据、模型和任务不一致性难题,提出了一套统一且全面的AlignDet框架进行检测导向的预训练。该框架通过分别解决数据、模型和任务上的差异,成功地在有效性、效率和迁移能力上取得明显改进和突破。此外,该方法的普适性也很强,可以广泛应用于各类检测器和骨干网络。这可以说是一个具有重要意义的里程碑性工作。
但是,这篇论文也存在一些可以改进的地方。比如Box-domain预训练目前需要依赖选择性搜索生成伪标签,这可能会带来一定局限性,我们可以探索端到端的无监督框检测方法来获得proposal。此外,当前方法主要在COCO数据集验证,可以考虑在更多检测数据集和场景下进行评估。
展望未来,这项工作为目标检测的预训练研究打开了新的大门。我们可以基于该框架,继续探索无监督、弱监督proposal生成和Box-domain预训练技术,以进一步降低人工标注和计算成本。另一方面,如何将该框架扩展到其他密集预测任务也是一个有趣的方向。总之,这项工作为更好地解决预训练与下游任务的不一致提供了重要启发,是目标检测和计算机视觉领域一个高质量的工作。
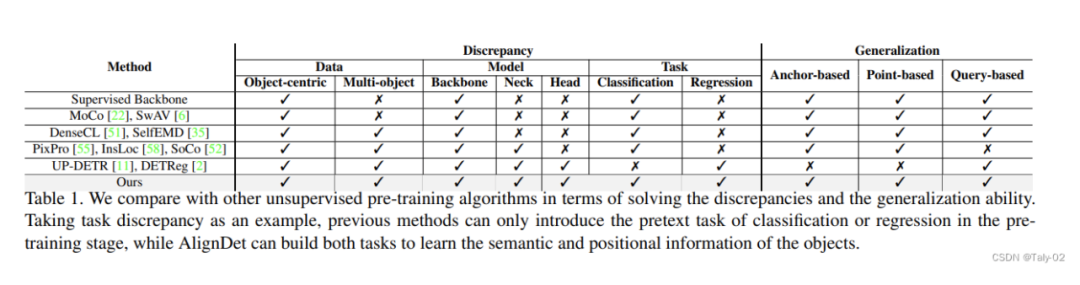
从表1可以看出,AlignDet与其他目标检测预训练方法的主要区别在于:
数据方面,AlignDet不仅适用于单对象的数据集,也能够在多对象的数据集上进行预训练,更贴近下游任务。
模型方面,AlignDet可以预训练检测模型中的所有模块,而不仅是骨干网络,确保各模块初始化良好。
任务方面,AlignDet同时引入了分类和回归两种预训练任务,学习语义和坐标信息,更符合目标检测的需求。
效果方面,AlignDet对各类检测器都能取得显著提升,展示了更强的普适性。
效率方面,AlignDet只需要12个epoch在COCO上预训练即可取得稳定收益,训练时间上也更为高效。
创新方面,AlignDet支持各类检测器的完全自监督预训练,是第一个实现这一目标的方法。
综上所述,AlignDet相比其他方法更充分地解决了预训练和微调过程中的数据、模型和任务差异,使检测器获得了显著和一致的性能改进。这说明了AlignDet的有效性、普适性以及创新性。
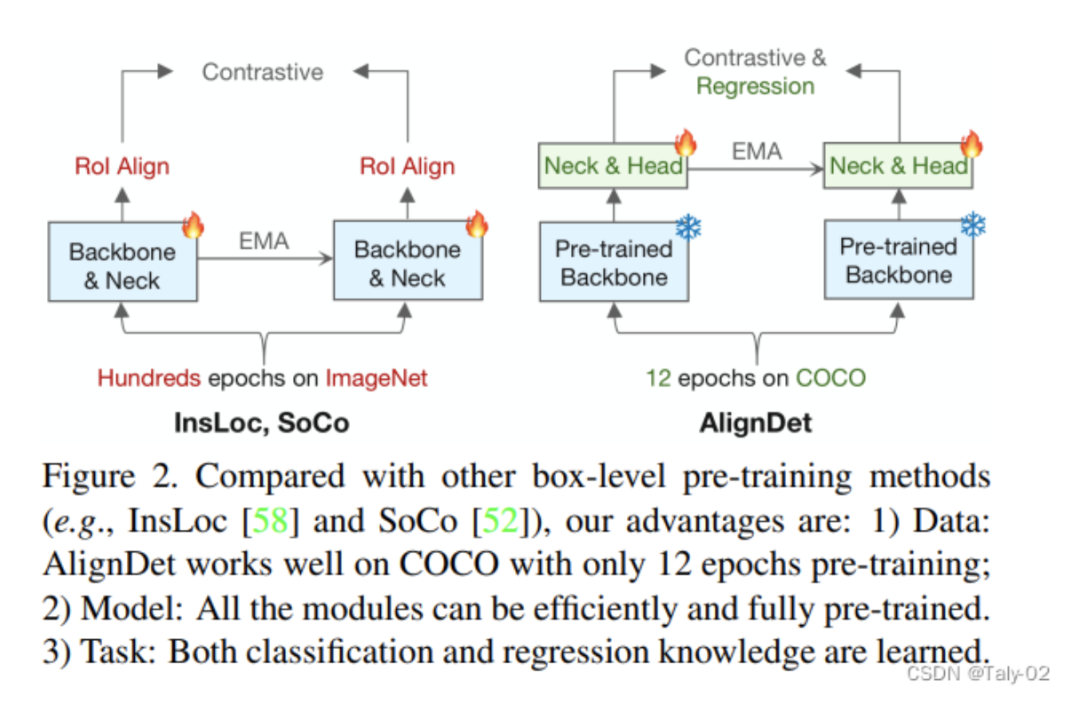
5. 结论
总结而言,这篇题为“AlignDet: Aligning Pre-training and Fine-tuning for Object Detection”的论文研究了目标检测中预训练和微调过程中的数据、模型和任务不一致性问题。论文指出现有预训练范式存在上述三方面差异,导致检测性能受限、泛化能力差且收敛速度慢。为解决这一问题,论文提出了AlignDet框架,可以适配各种检测器以弥合预训练和微调的差异。该框架分为Image-domain预训练提取语义特征和Box-domain预训练学习实例级语义与任务感知先验。实验结果展示,AlignDet可以显著提升各类检测器在不同数据量、训练策略及迁移学习下的性能。例如在COCO上12轮预训练,FCOS精度提升5.3 mAP,Mask R-CNN提升3.3 mAP。可以说AlignDet是第一个支持各类检测器完全自监督预训练的框架,对推进目标检测预训练研究具有重要意义。总之,本论文不仅指出了目标检测中存在的预训练与微调不一致性问题,也设计了AlignDet框架进行有效的检测导向预训练,为该领域的研究做出了重要贡献。

TensorRT部署系列 | 如何将模型从 PyTorch 转换为 TensorRT 并加速推理?

大众 7 亿美元入股小鹏,合作 2 款纯电车;Meta Q2 营收超过预期,达到 320 亿美元
广汽丰田被曝裁员千人,赔偿N+3;微信手机号可一键登QQ;HarmonyOS 4定档8月;RISC-V成Debian官方支持架构
扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)




想要了解更多:
前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
行业技术方案👉「AI安防、AI医疗、AI自动驾驶」
AI模型部署落地实战👉「CUDA、TensorRT、NCNN、OpenVINO、MNN、ONNXRuntime以及地平线框架」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!
免责声明
凡本公众号注明“来源:XXX(非集智书童)”的作品,均转载自其它媒体,版权归原作者所有,如有侵权请联系我们删除,谢谢。
点击下方“阅读原文”,
了解更多AI学习路上的「武功秘籍」