
面向可解释性的知识图谱推理研究

本文约6600字,建议阅读5分钟 本次演讲主题是面向可解释性的知识图谱推理研究。
报告分为以下 5 个部分:
研究背景
前沿进展
研究动机
近期研究
研究展望
01 研究背景
1. 引言
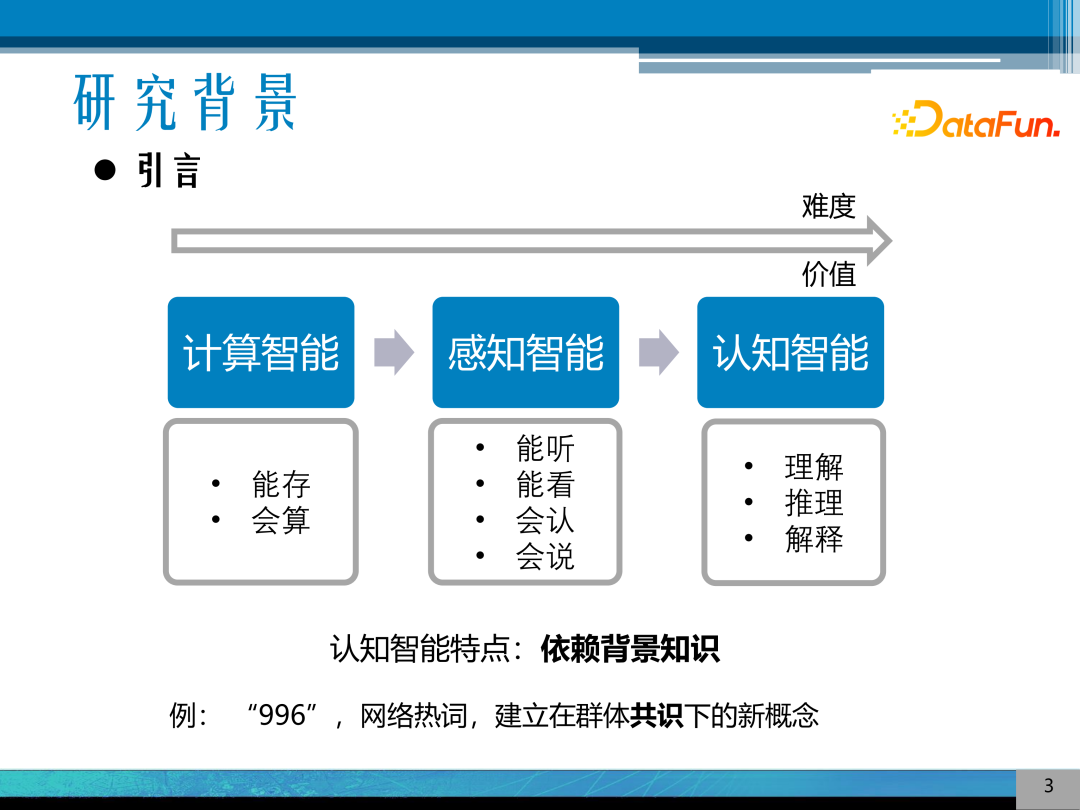
首先,介绍一下背景。人工智能经过 70 多年的发展,已经从计算智能的能存、会算,进步到了感知智能的能听、能看、会认、会说,并已有很多系统在此方面做的很出色,但与理想的认知智能还有很大的距离。认知智能希望机器能够对数据模型、原理进行理解、推理、解释等,这种认知智能很大的特点是依赖背景知识,例如,对于新的网络概念或网络热词,如“996”、“YYDS”等,这种新的概念是建立在群体共识下的,非常依赖背景知识,对这种非常符合认知智能特点的概念的学习和建模是目前的难点,学习和表示这种背景知识是非常关键的技术。
2. 知识图谱
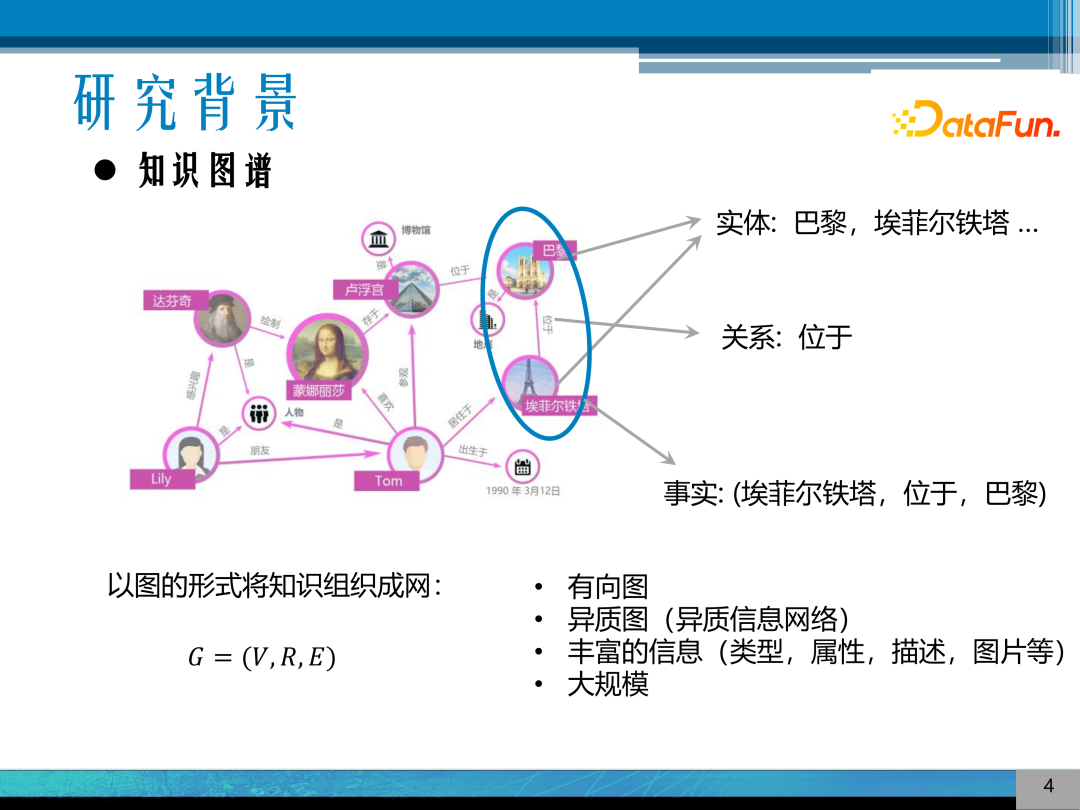
知识图谱即是承载和表示背景知识的技术和工具,以图的形式,将真实世界中的实体、关系组织成网,将知识进行结构化。以上图知识图谱为例,可以知识图谱中的实体和关系抽象为图中的节点和边,其特点是:
它是一个有向图,其边是有向的
它是一个异质图,节点和边有不同的类型,又称为异质信息网络
它具有丰富的信息,可以给节点和边绑定丰富的属性信息,对知识进行更加细致的描述
它通常规模会很大
3. 知识图谱的下游应用

知识图谱在需要背景知识或知识获取中应用比较广泛,比较典型的包括:信息检索、问答/聊天系统,语言、图像理解等。
信息检索,利用知识图谱进行概念之间的智能推理、模糊查询,同时可给关键概念提供知识卡片,方便用户体验。
问答/聊天系统,当和问答助手或聊天系统进行交互时,可解决任务型问答的问题,则知识图谱将发挥比较核心的作用。
语言、图像理解,利用知识图谱实现对语言数据、文本数据、图像数据的理解,利用知识增长的方式帮助学习概念之间的关系,如最近研究比较活跃的VQA、图像关系推理等。
4. 知识图谱推理
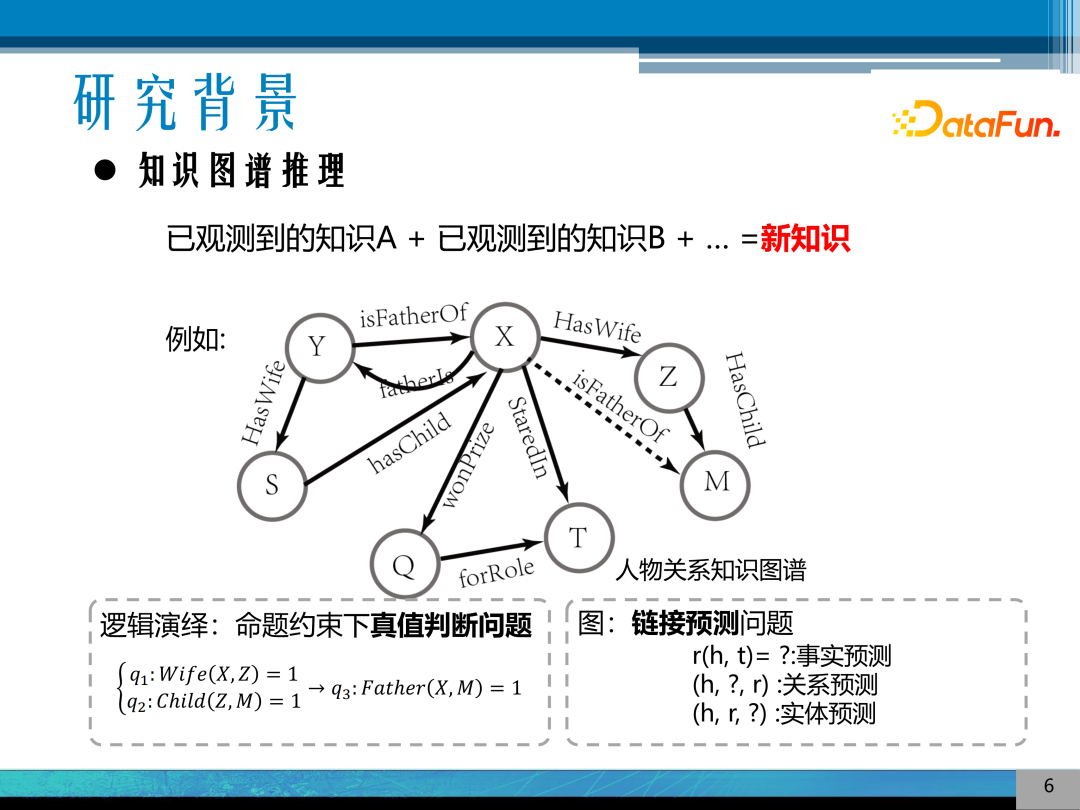
以上提到的应用中,核心的功能就是知识图谱推理。所谓知识图谱推理,就是在知识图谱中根据已有的知识来获得新知识的能力。以上图中人物关系知识图谱为例,已知 X 与 Z、Z 与 M 之间的关系,Z 是 X 的妻子,M 是 Z 的孩子,则系统可以推理出X是M的父亲,这是一种最简单的推理关系。
知识图谱推理可以从两个角度来看,一是从逻辑演绎的角度,它是一个多个命题约束下真值判断的问题。二是可以从图的角度来理解知识图谱推理,可以建模分析链接预测的问题,可根据图中的节点来预测节点之间的关联;如:给出两个实体,预测两者之间有哪种边,即哪种关系;给定某一个实体、某一条边,能预测出哪些实体与这个实体有某种关联。
02 前沿进展
1. 主要方法

这里将前沿进展的主要方法分为 4 个部分,一是演绎逻辑及规则;二是基于图结构的推理;三是知识图谱嵌入表示;四是深度神经网络模型。
2. 演绎逻辑及规则

该方法是非常经典且常见的方法。将自然语言查询转化为逻辑操作符的组合,通过组合来表达这种查询,再以具体的编程语言进行实现得到查询,比较著名图的查询的实现包括 SPARQL、Cypher、Datalog 等语言的归纳逻辑编程。基于演绎逻辑推理的特点是:
推理的准确性非常好
可解释性好,其是具有逻辑性的
其需要专家制定大量的推理规则
对于不知道规则的泛化性能力比较差
近期研究的一个热点和热门是,如何利用机器学习和深度学习,自动地发掘推理的规则。
3. 基于图结构的推理
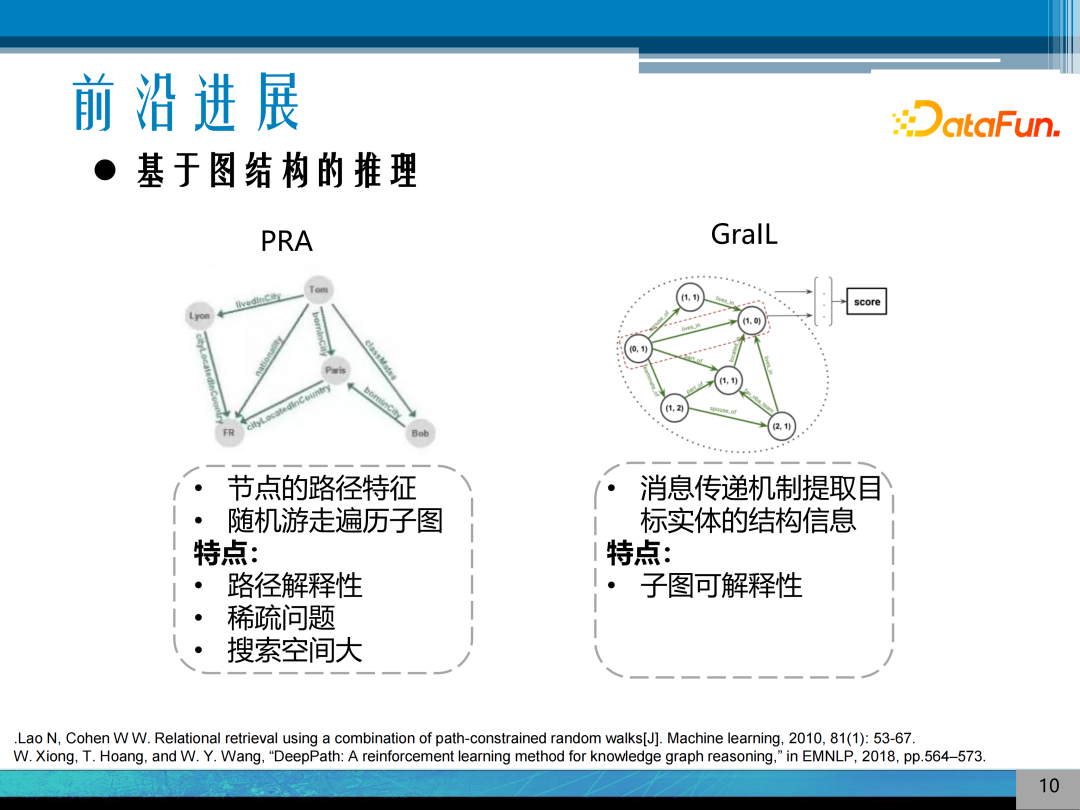
这里认为图结构有两个特征:一是路径特征,代表算法是 PRA 及扩展算法,通过图的遍历算法或随机游走方法来提取节点间的路径特征,通过路径特征来对节点连接进行预测,其特点是在推理的同时提供路径可解释性,但其问题是对于推理节点没有连接的问题就不能解决。基于传统的方法,其搜索空间比较大。二是基于图结构的方法,代表方法是 Grall,利用消息传递机制提取目标实体的结构信息,提供子图可解释性;但目前子图结构的方式还不是很成熟,因知识图谱通常很大,如果遍历图中所有的子图结构,遍历的方式方法非常重要。
4. 知识图谱嵌入表示
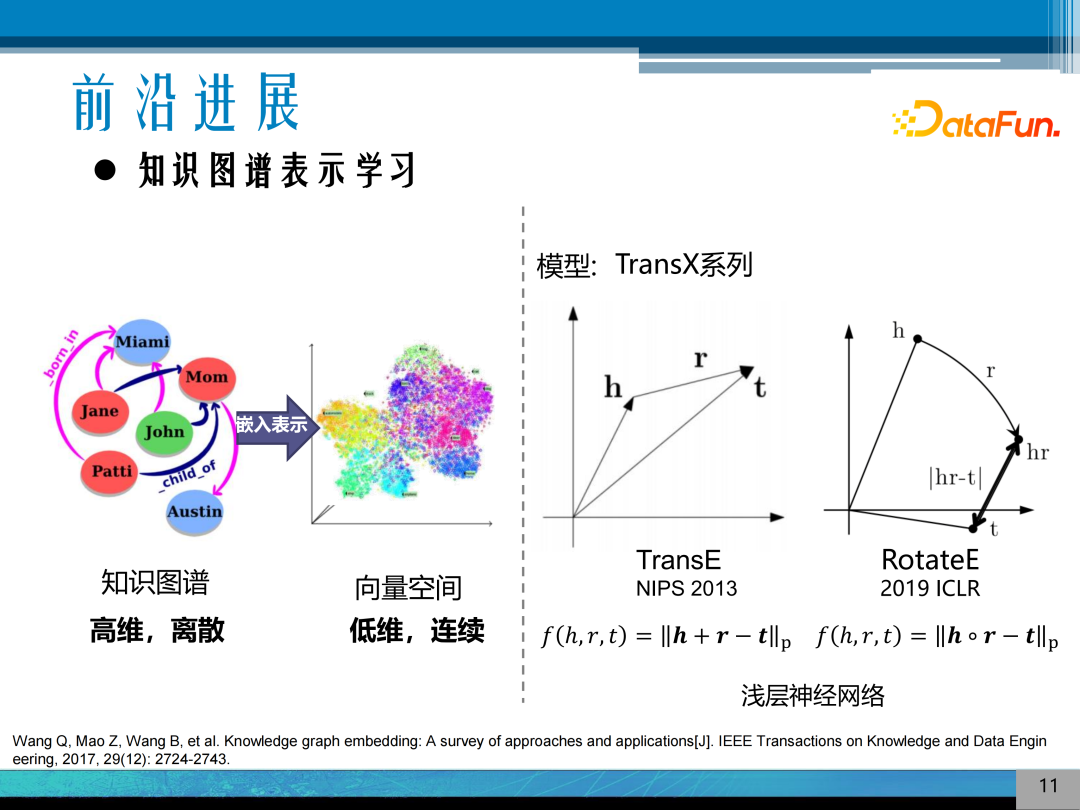
将知识图谱高维、离散的数据,通过设计某种得分函数,将高维知识图谱嵌入到低纬连续的向量空间之中,将实体和关系表示成数值型的向量进行计算,其代表性的模型为 TransE 类型,近期研究的事 RotateE 模型或在双曲空间中嵌入的模型,其方法的特点是浅层的神经网络,通过特定的嵌入空间的结构实现知识图谱语义的表示。
5. 深度神经网络模型
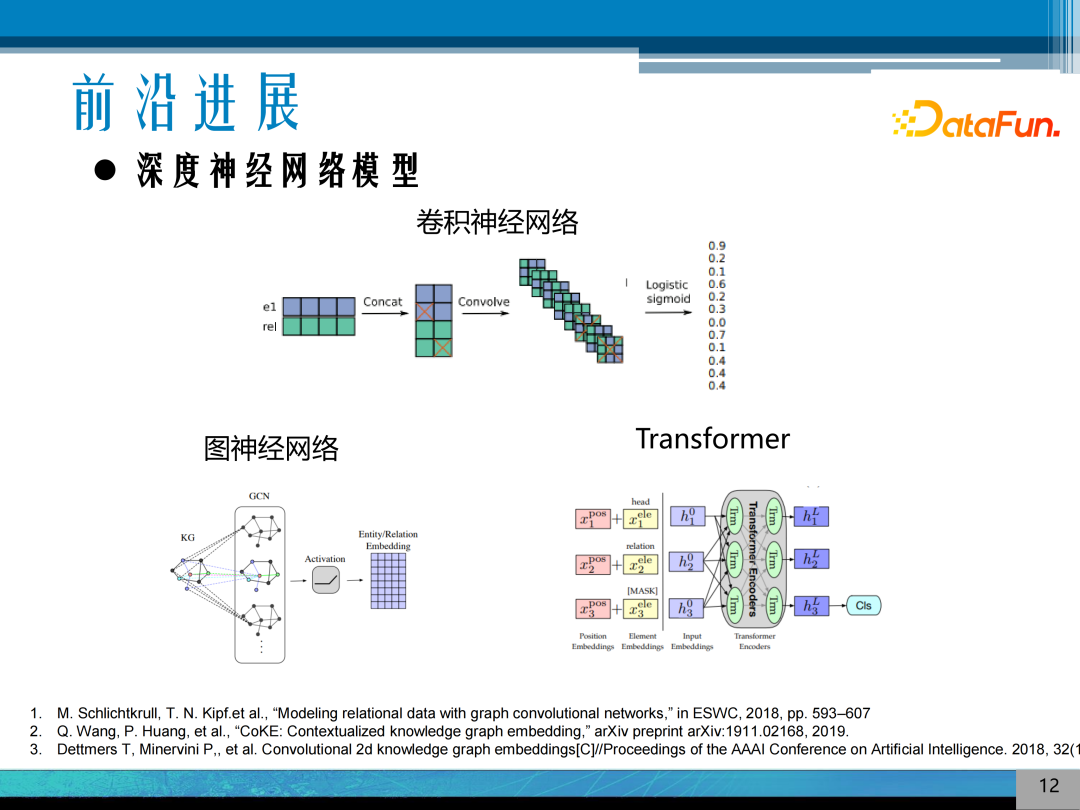
深度神经网络模型是通过将实体和关系设计成查询对,通过查询对与实体、关系的匹配,通过深度神经网络得到推理的相似度得分,来进行推理的判断。近期研究的热点是 Transformer 或图神经网络。
知识图谱嵌入模型和深度网络模型都视为神经网络模型,其相同点是都会设计一个得分函数,通过数据驱动的方式,以梯度反向传播方法进行训练。其优点是泛化性能比较好,易于数值计算及并行化,规模性好,可以有效缓解图结构维度灾难的问题。其缺点是只能看到输入和输出数值的相似度,缺乏可解释性,不知道模型内部发生了什么,是一个黑盒的过程,因此可解释性差,对噪音的鲁棒性不强,只能进行单步的推理。
6. 现有方法总结
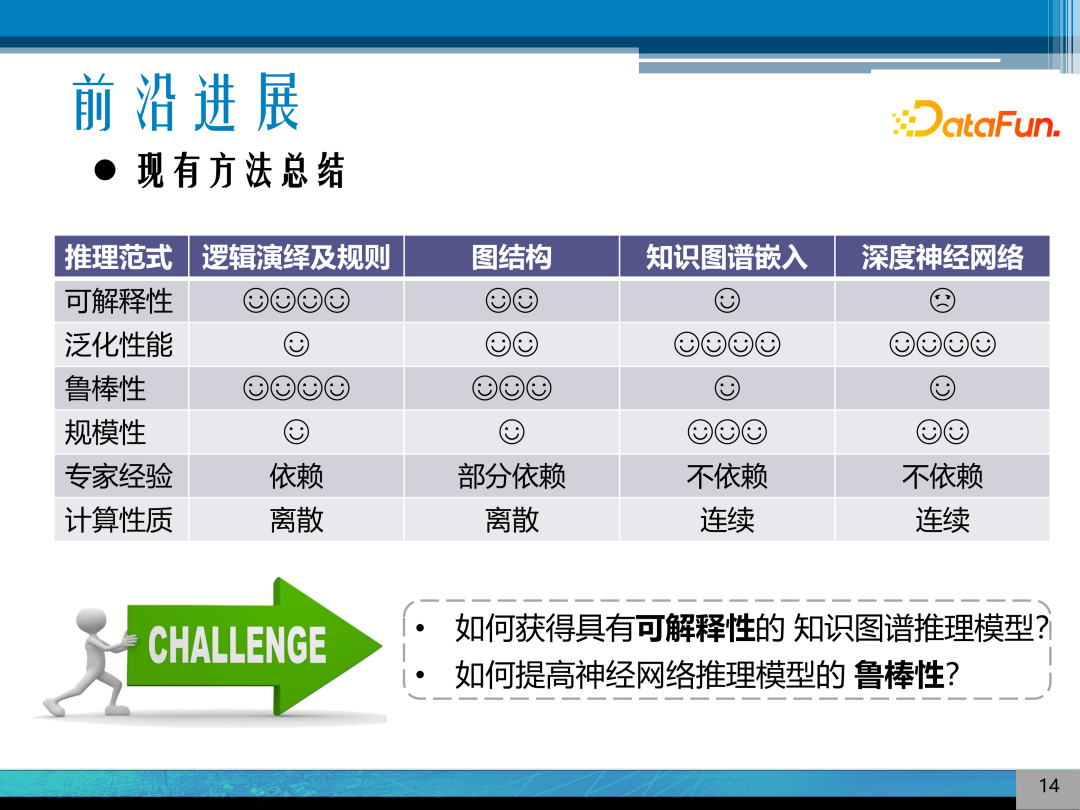
这里对主要的推理方法进行一个总结,可以发现基于逻辑演绎规则和图结构的方法都是是基于符号的方法,其可解释性比较好,但泛化性能比较差,都是离线的计算方式。基于知识图谱嵌入和深度神经网络模型,其泛化性能比较好,但可解释性比较差。
近期研究的重点是如何将符号主义和连接主义的模型进行融合来获得具有可解释性的知识图谱推理模型。
03 研究动机
1. 知识图谱推理的可解释性
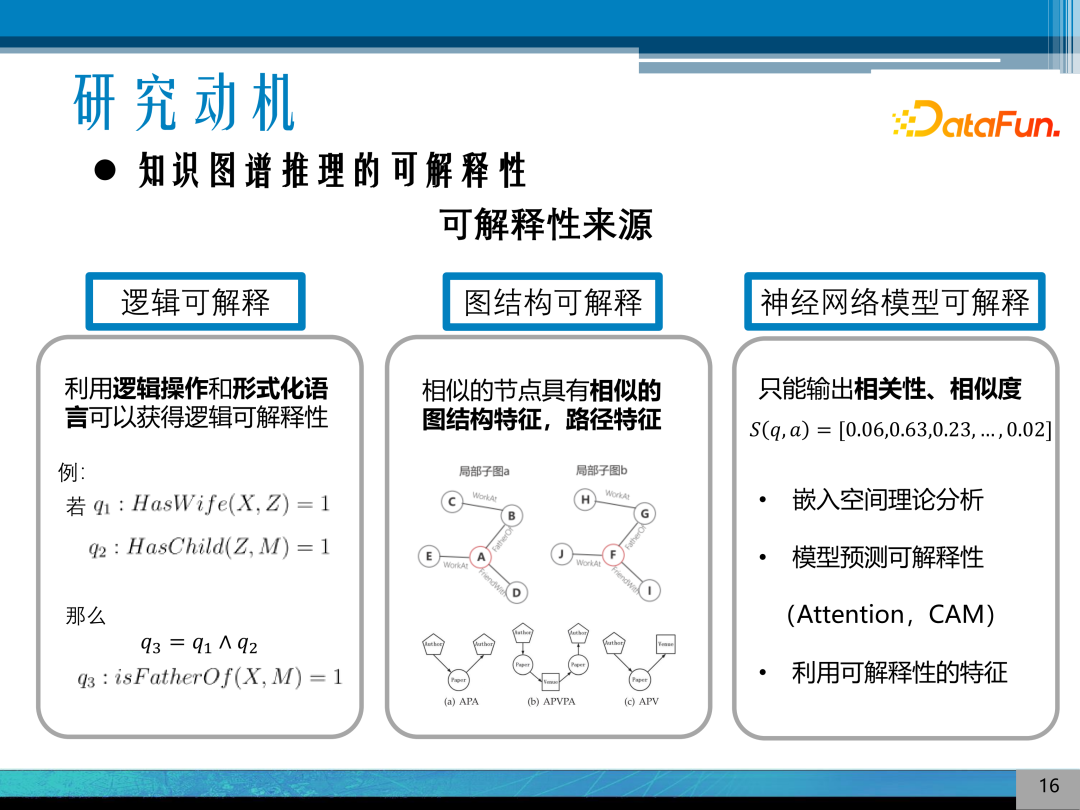
对知识图谱推理的可解释性来源进行了分类:
逻辑可解释性:是天然的知识图谱可解释性来源,可以提供逻辑解释依据。
图结构的可解释性:图结构具有路径特征,如metapath和子图的结构特征。
神经网络模型可解释性:事后可解释性,可以通过神经网络的一些事后可解释性手段来分析特征的显著性。其代表方法是Attention机制的可视化,这种方法目前还不是很成熟;另一种是 CAM 或图 CAM 方法;还有一种是利用嵌入空间理论分析方法,其中 RotateE 或双曲空间其嵌入空间理论分析做的非常好,但是不能很好地解释参数的变化。
2. 强化学习
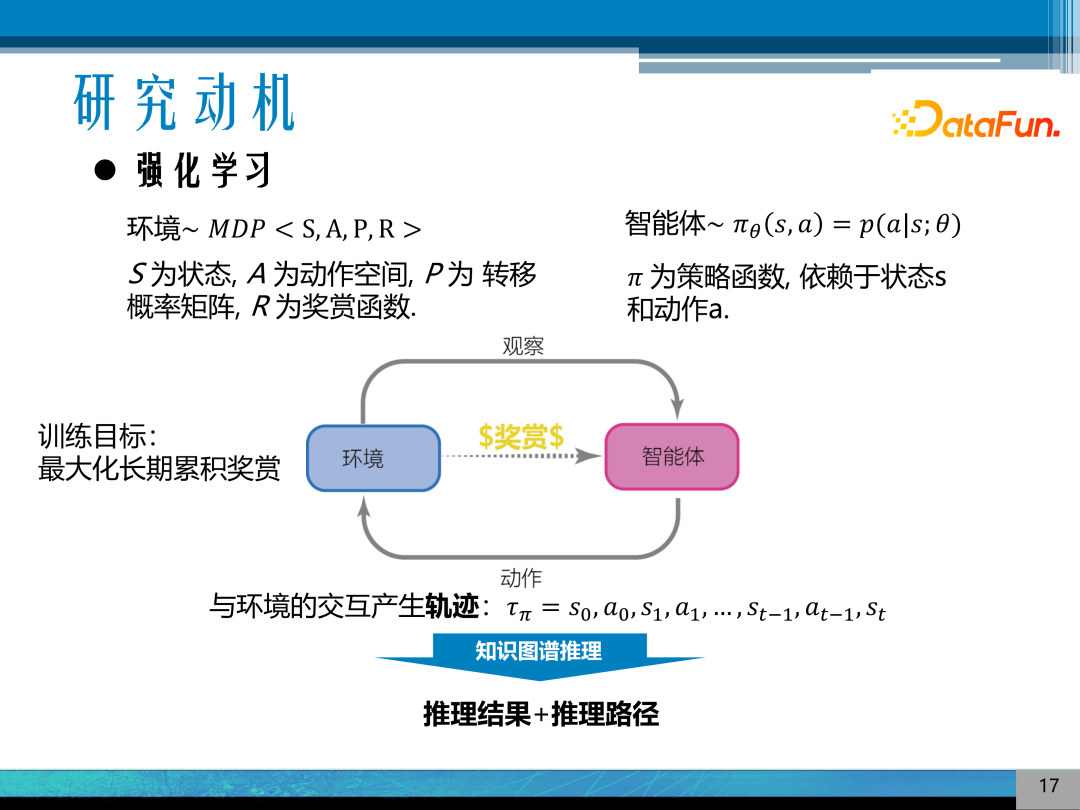
如何对符号主义和连接主义的模型进行有效的融合是近期的研究热点。这里研究的重点是将强化学习融入到知识推理中。
强化学习是近 10 年来非常受关注的模型,在控制、游戏、机器人中得到了广泛应用。其是将一个学习过程建模成马尔科夫过程,通过智能体和环境的互相交互,通过最大化长期累积的奖赏来训练模型。与环境交互时会产生轨迹,如果将知识图谱建模为一个强化学习的过程,那么既可以得到推理的结果,也可以得到推理的路径,通过推理路径来解释知识图谱推理。
3. 基于强化学习的知识图谱推理
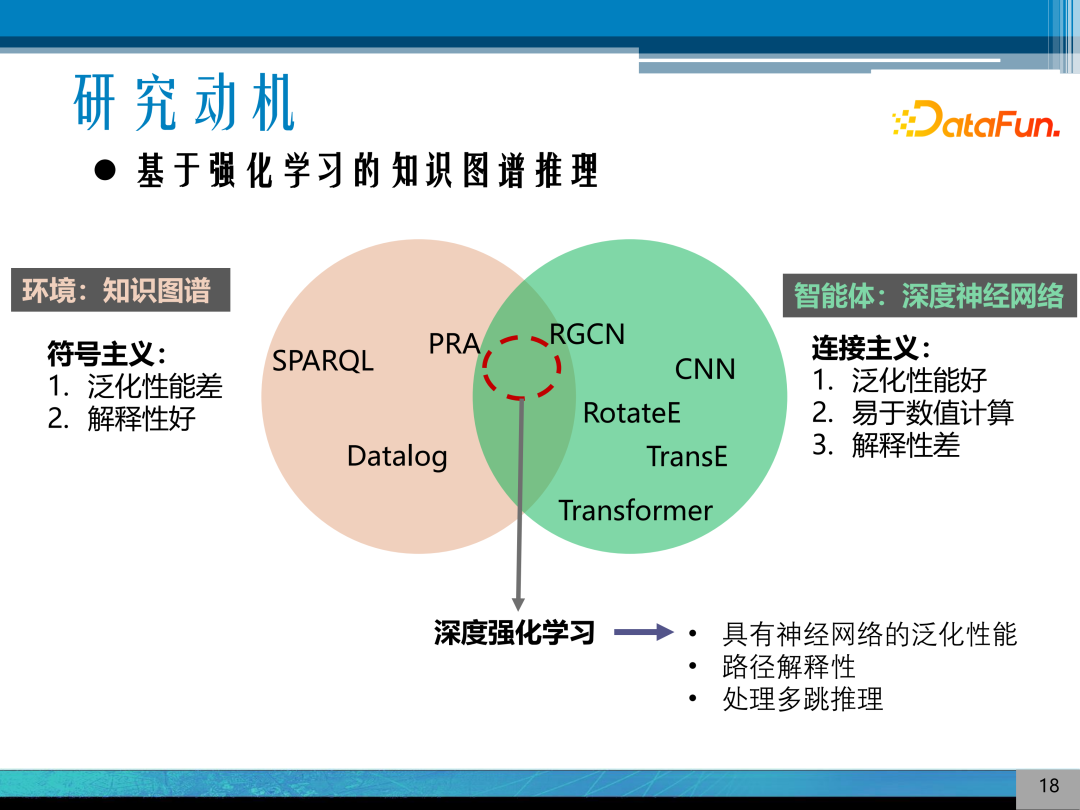
具体的融合方法是将知识图谱视为一个环境,将智能体建模成一个深度神经网络,结合符号主义和连接主义的优缺点,做到取长补短,让模型同时具备神经网络的泛化性能和路径可解释性,同时由于深度强化学习是一个序列过程,可以处理多跳推理的过程。
04 近期研究
1. 基于层次强化学习的知识图谱推理
第一个进行的工作就是基于层次强化学习的知识图谱推理模型。
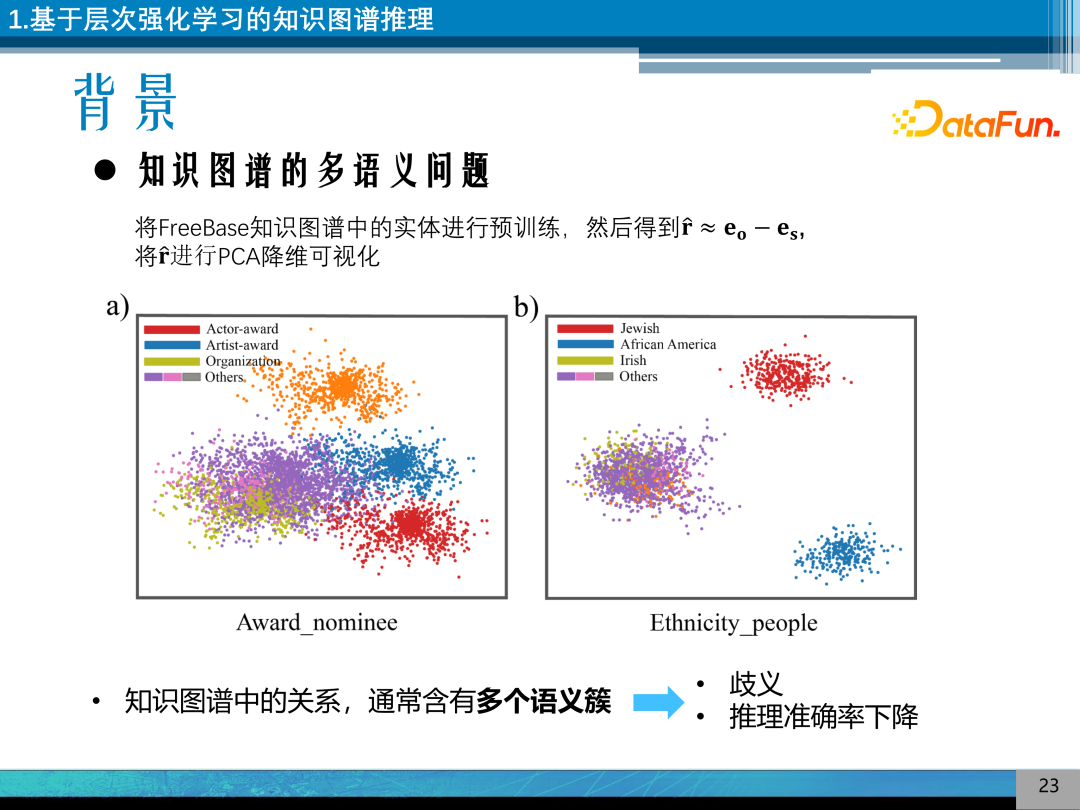
其研究的背景是解决知识图谱多语义问题。以图为例,将 FreeBase 知识图谱中的实体用 TransE 进行预训练,将相关联的实体相减得到关系的表示,将表示进行 PCA 降维可视化,可以看到关系具有多个语义簇,代表关系模型在预训练模型中出现的模式。多个语义簇会造成歧义的现象,造成推理准确率下降。
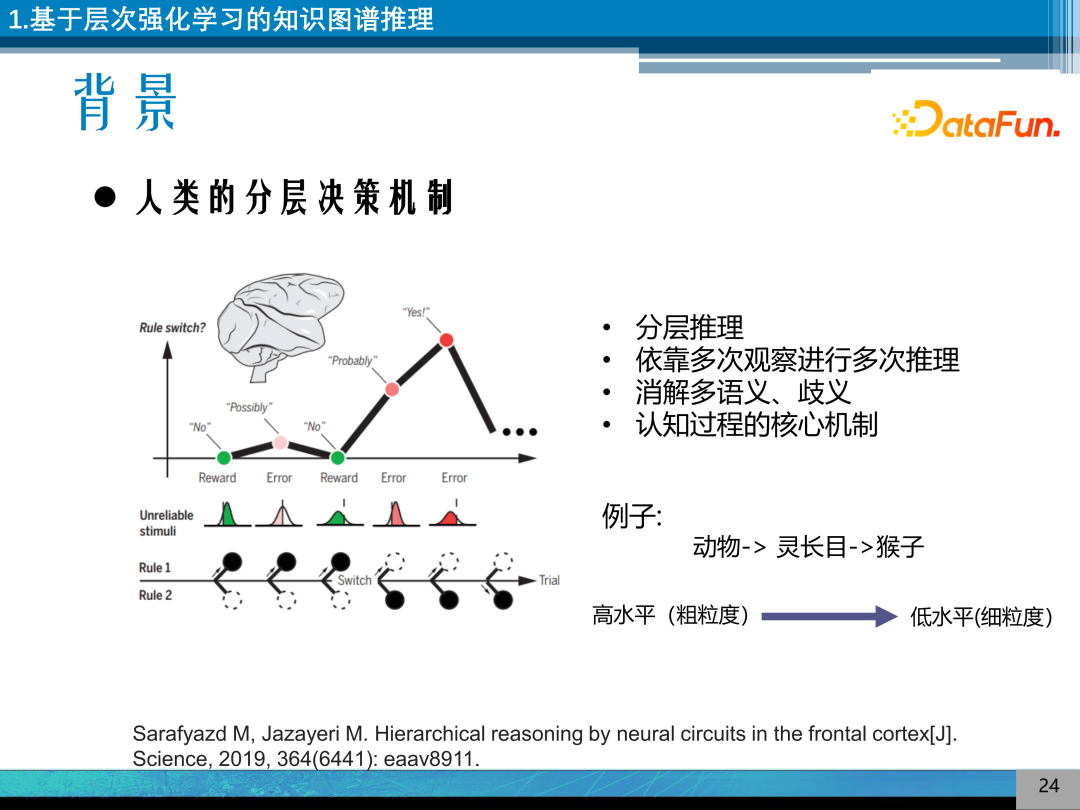
如何解决知识图谱推理多语义问题呢?结合近期神经科学的发现,发表在 Science 上的文章表明人类或高级动物其决策的过程是一个分层推理的过程,是一个潜意识的过程,通过多次观察、多次推理,逐步去消解多语义和歧义,来得到推理的结构。分层决策的机制是认知过程的核心机制,是该论文的结论。例如,人在识别一只金丝猴的过程中的一个潜意识过程是先识别是一个动物,是一个灵长目的动物,再识别它是一只金丝猴。这是一个从高水平到低水平、从概念上粗粒度到细粒度的过程,该过程就是一个分层的机制。
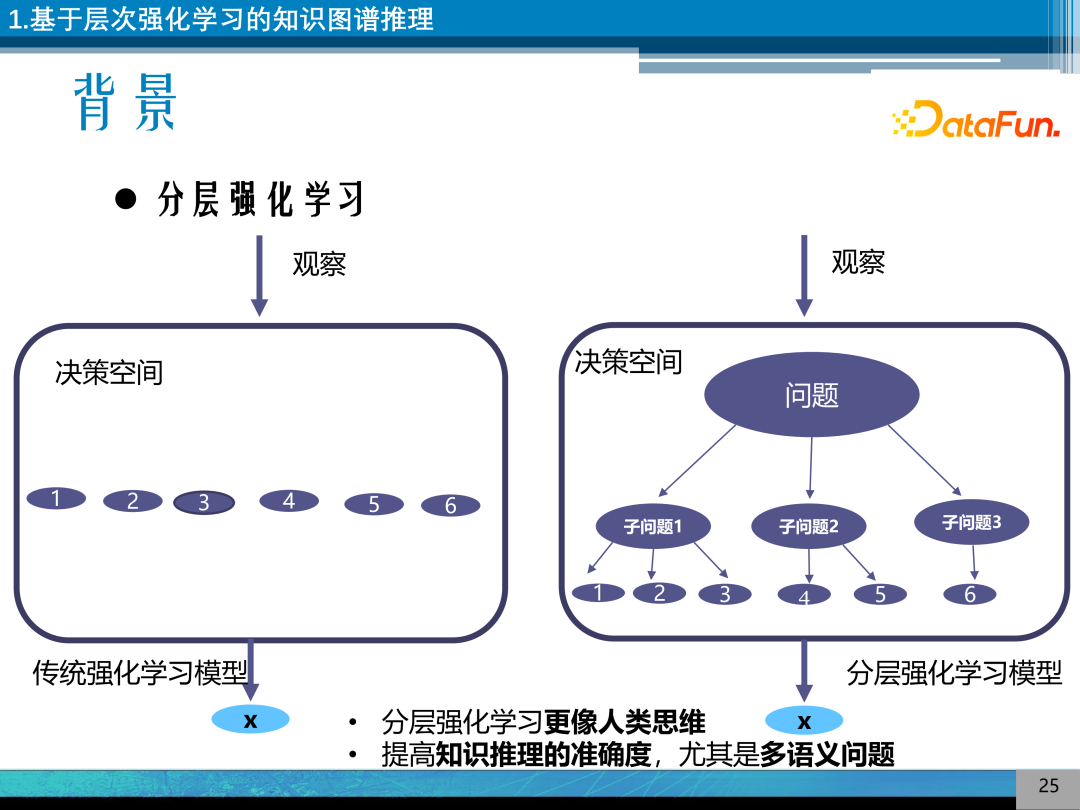
分层强化学习与传统强化学习模型的区别是,分层强化学习将决策空间进行了进一步的结构化,将问题分解为若干个子问题来进行决策。分层强化学习更像人类思维,能够提高知识推理的准确度,解决多语义问题。
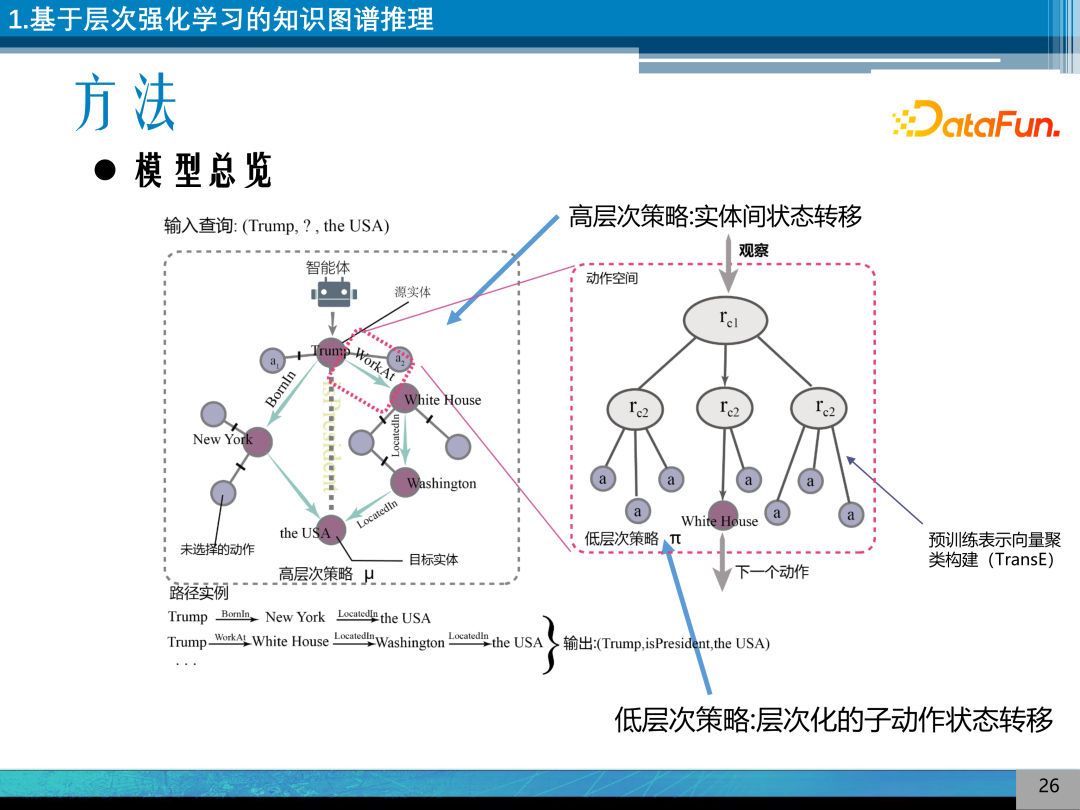
具体实现分层强化学习的方法是设计两个互相嵌套的强化学习,一个是高层次的策略函数,一个是低层次策略函数。高层次策略控制知识图谱实体间的状态转移,低层次策略控制语义簇之间的转移,语义簇是用 TransE 的嵌入来构建。

具体来讲,高水平策略函数是一个基于 GRU 的可以保存历史向量的策略函数,其奖赏函数是一个γ衰减的奖赏函数。低水平策略函数是一个将状态空间层次化分解的过程,其奖赏函数是一个 0、1 奖赏。

其训练的目标是使其奖赏最大化,利用梯度策略优化来训练模型。由于该模型高水平策略和低水平策略互相嵌套的模型,使用交替固定优化的方式,通过蒙特卡洛采样轨迹的方式来训练推理模型。

使用的评价指标是平均准确率、平均排序分数和 Hit@X。数据集是常识知识图谱 FB15K、NELL995、WN18RR,其中 FB15K 的多语义现象比较严重。
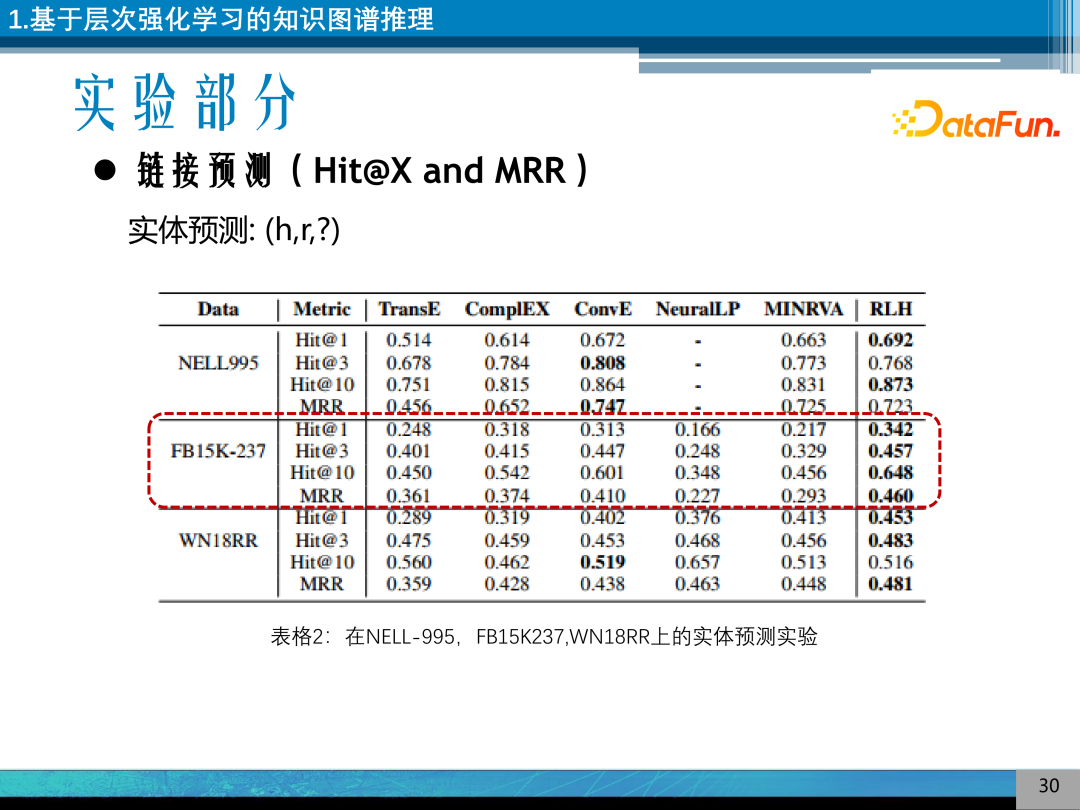
进行链接预测的实验,图为实体预测的实验结果,可以发现模型在大部分数据集上表现的都比较好,同时在多语义的数据集上表现的更好一点。
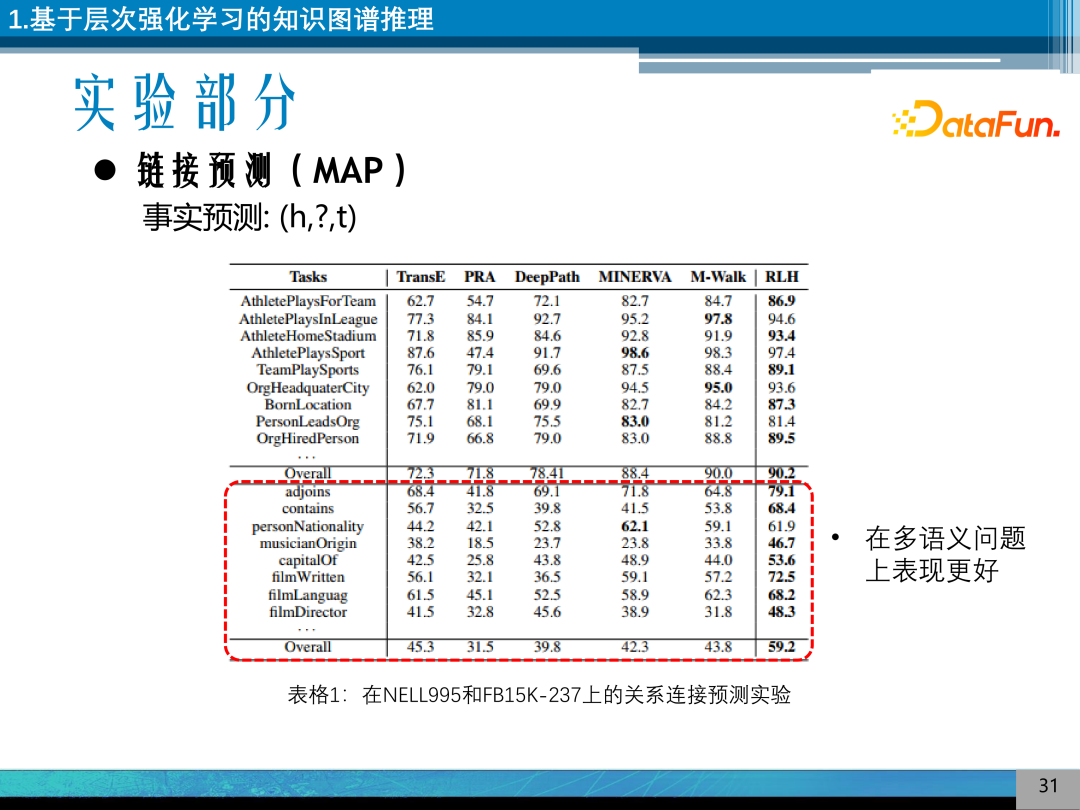
第二个是事实预测的实验,给定两个实体,预测它们之间是否存在某种关系,是一个二分类的问题,模型在 FB15K-237 上表现更好一些。

分层强化推理可以提供可解释性的推理路径,如图,在推理过程中相比于 MINERVA可以提供更好的推理路径。

小结:提出了一个分层强化学习的知识推理模型,这个模型模仿了人类的思维方法,这个模型可以学习到知识图谱中关系的层次化语义簇,从而有助于解决推理过程的多语义问题。实验表明,这个模型可以在标准的数据集上取得竞争性的结果,在多语义问题上表现更好。该工作发表于 2020 年 IJCAI 上。
2. 基于贝叶斯强化学习的知识图谱推理
第二个是进行的关于贝叶斯强化学习的知识图谱推理模型。
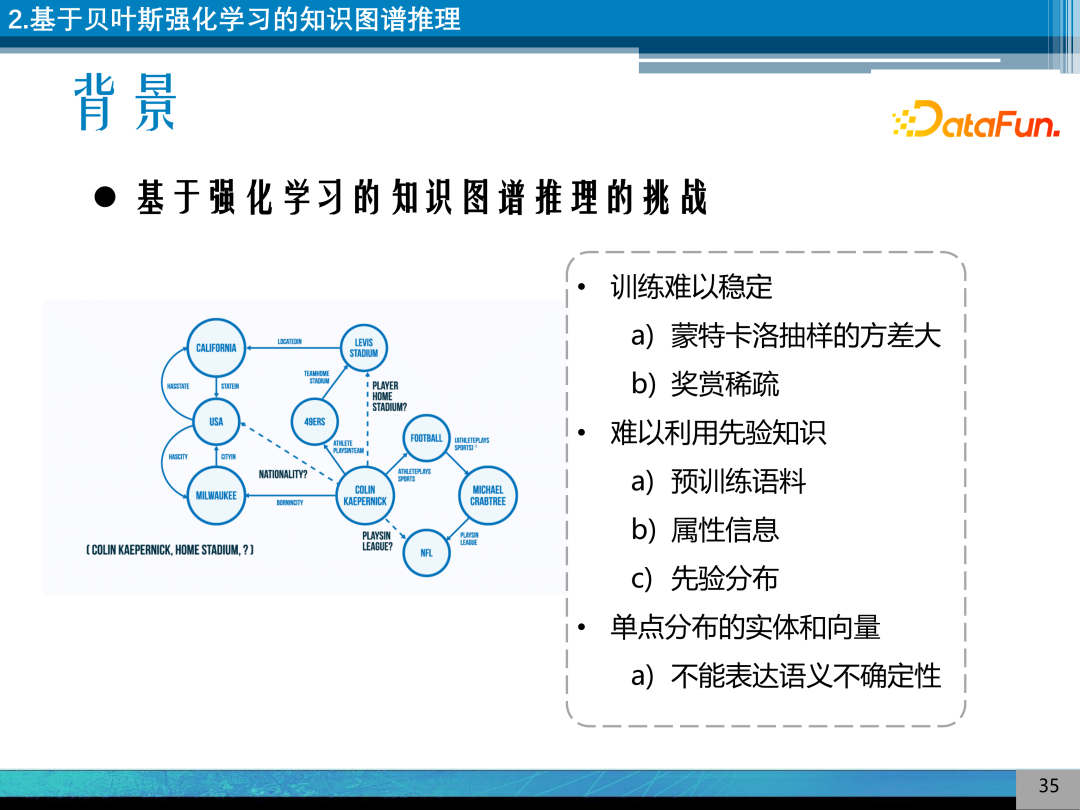
研究发现,基于强化学习的知识图谱推理很大的问题是:
训练难以稳定,其蒙特卡洛抽样的方差比较大,奖赏稀疏。
难以利用先验知识,如利用预训练语料、属性信息、关系和实体的先验分布。
单点分布的实体和向量,不能表达语义的不确定性。
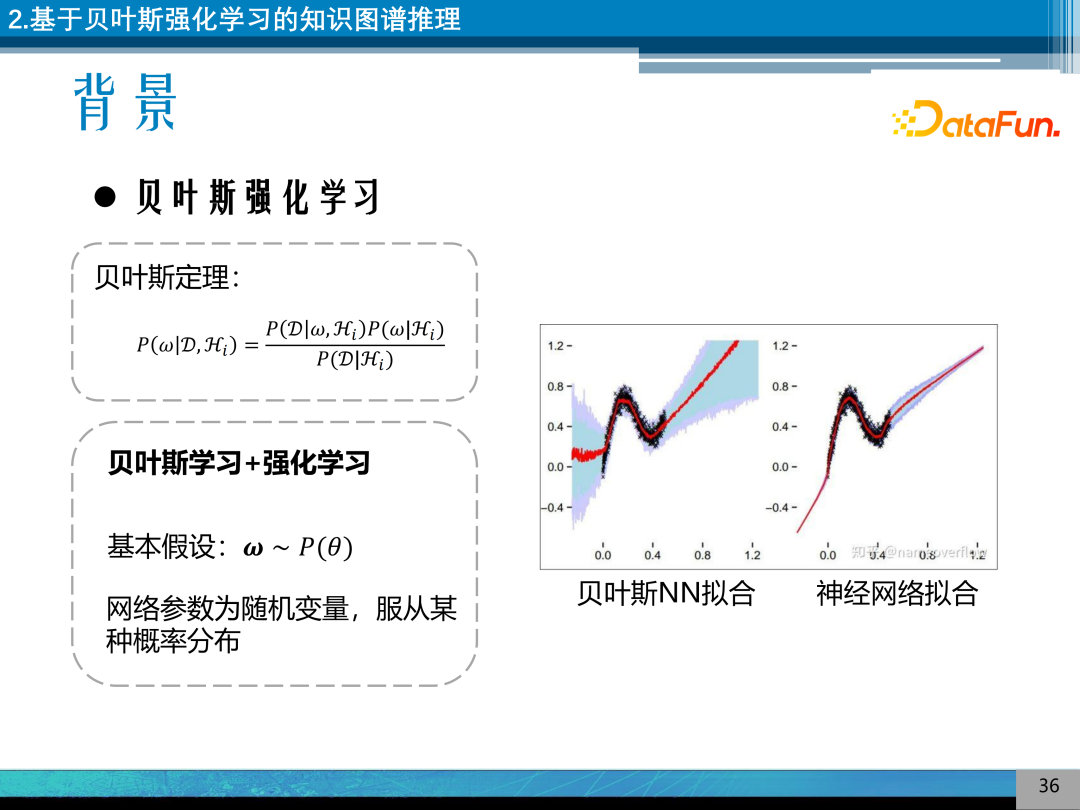
利用贝叶斯强化学习工具来建模不确定性推理。假设参数服从某种概率分布,右图显示了贝叶斯学习的有点是可以表达不确定性。
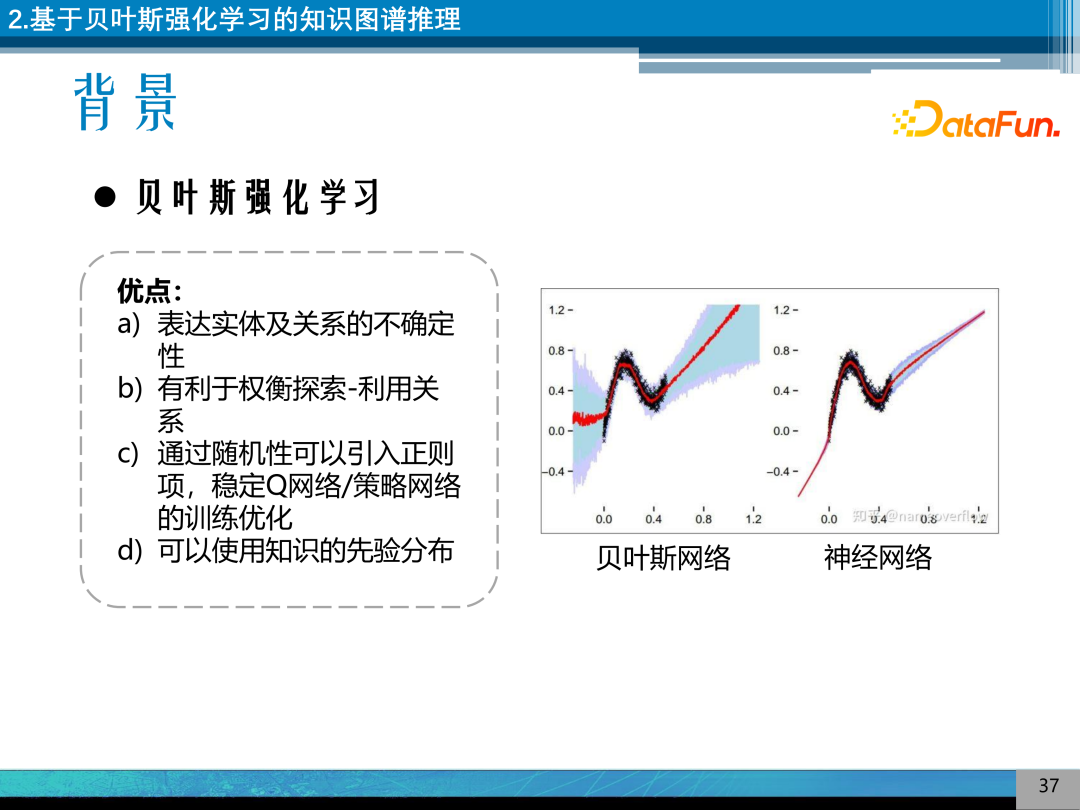
利用贝叶斯强化学习其优点是可以表达实体及关系的不确定性,这种不确定性有利于权衡探索-利用关系,通过随机性可以引入正则项,来稳定 Q 网络/策略网络的训练优化,同时贝叶斯强化的机制可以利用知识的先验分布。
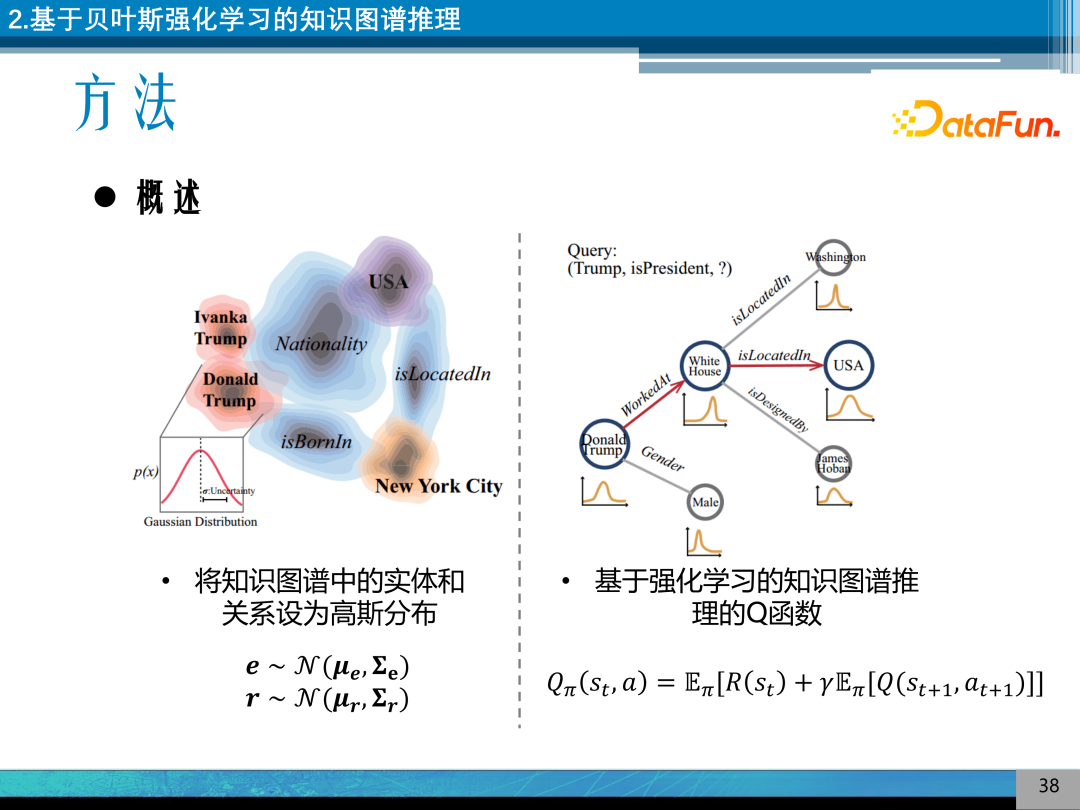
其方法比较简单,就是将知识图谱中的实体和关系假设为高斯分布,通过设计合理的知识图谱 Q 函数来进行推理。

将知识图谱推理定义成马尔可夫决策过程,其环境是知识图谱,状态是实体在知识图谱中所处的位置,动作是这个位置可能连接的实体集合,策略函数是基于最大 Q 值的执行策略,奖赏函数是 0、1 奖赏。

Q 函数的定义就是一个状态动作值的定义,在 St 是状态时,对未来推理 Q 的奖赏的期望。直接求解 Q 函数通常比较困难,是通过神经网络进行拟合。具体实现方式是通过 BayesianLSTM 来拟合 Q 函数的隐状态,通过贝叶斯线性回归网络输出 Q 值。

具体的执行策略和优化策略有两种,是异策略的方式,即优化策略与执行策略函数不同。优化策略是采取贪心策略,来保证训练的利用。执行策略是通过 Tompson 采样,通过 Q 值随机化生成来保证环境的探索。

最后的目标函数是最小化 Q 函数网络的变分自由能,通过轨迹采样方式来进行优化,采用蒙特卡洛梯度进行近似优化,具体实现是通过贝叶斯反向传播的方法来训练贝叶斯神经网络。
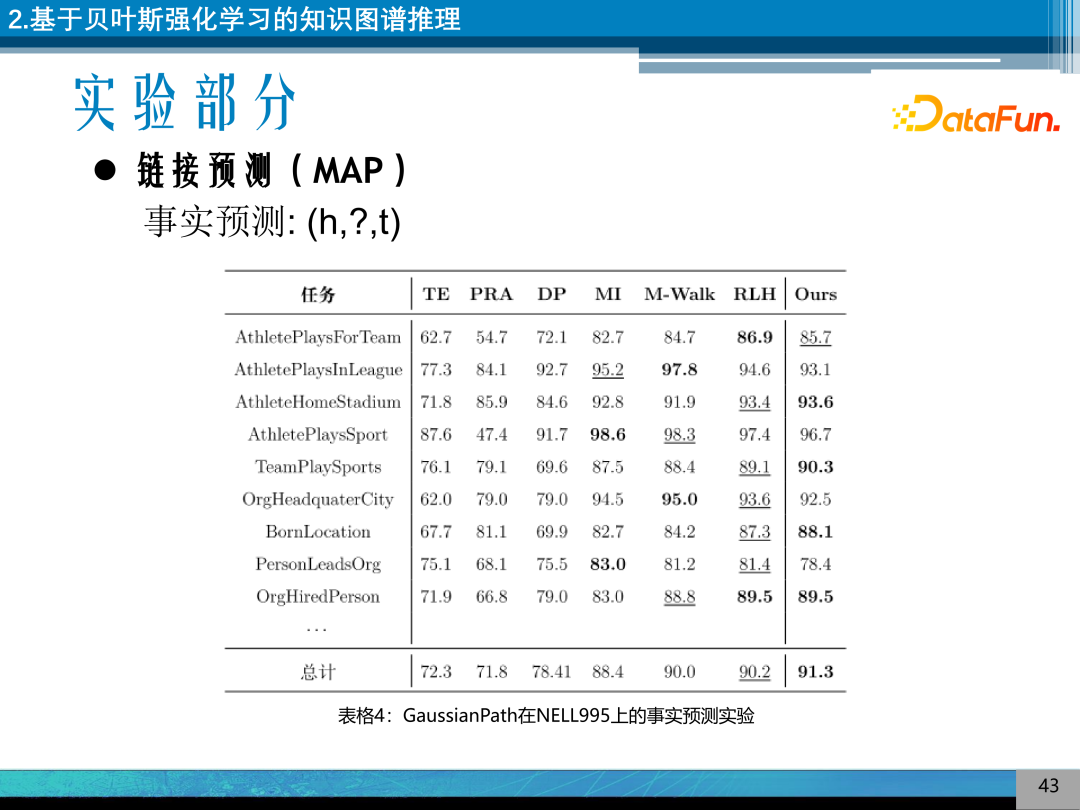
在知识图谱进行的实验,图为事实预测的实验结果,是一个二分类预测,给定两个实体预测其关系的实验。可以发现模型在 NELL995 上大部分取得了比较好的领先。
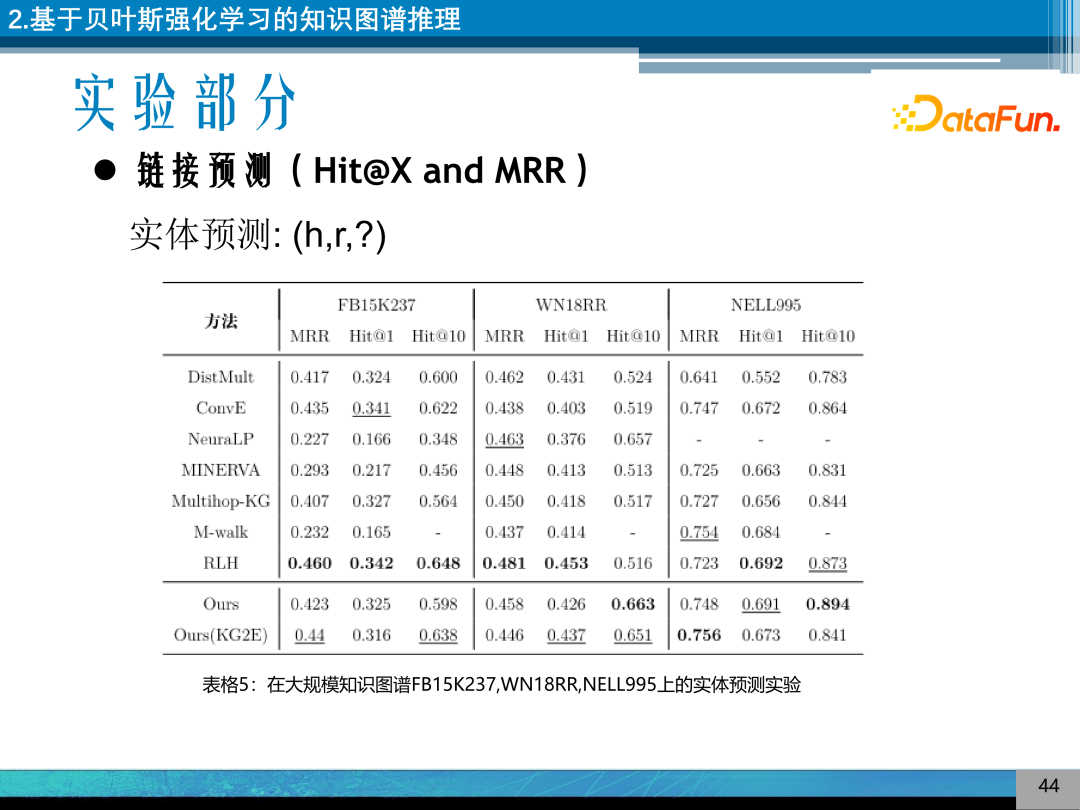
实体预测的实验,可以发现模型可以取得较优的结果。
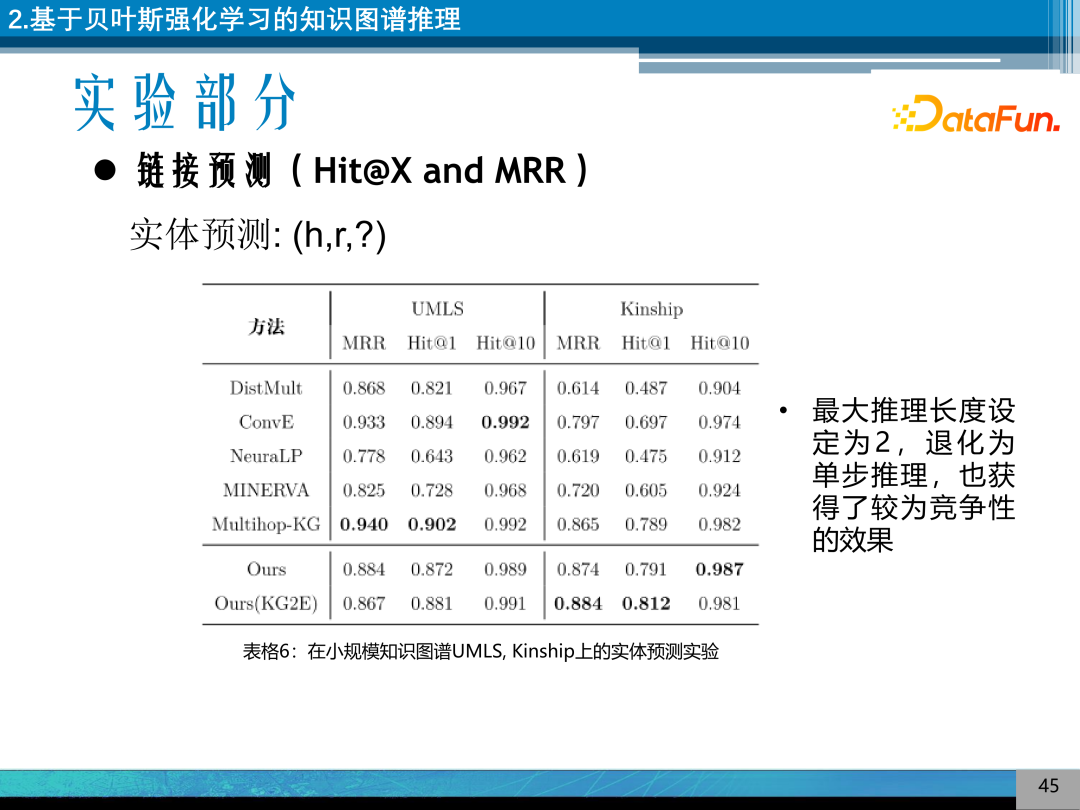
在小规模知识图谱上的链接预测实验,在小规模知识图谱,上的实验将最大推理长度设定为 2,设定为单步推理,也取得了一定的效果。
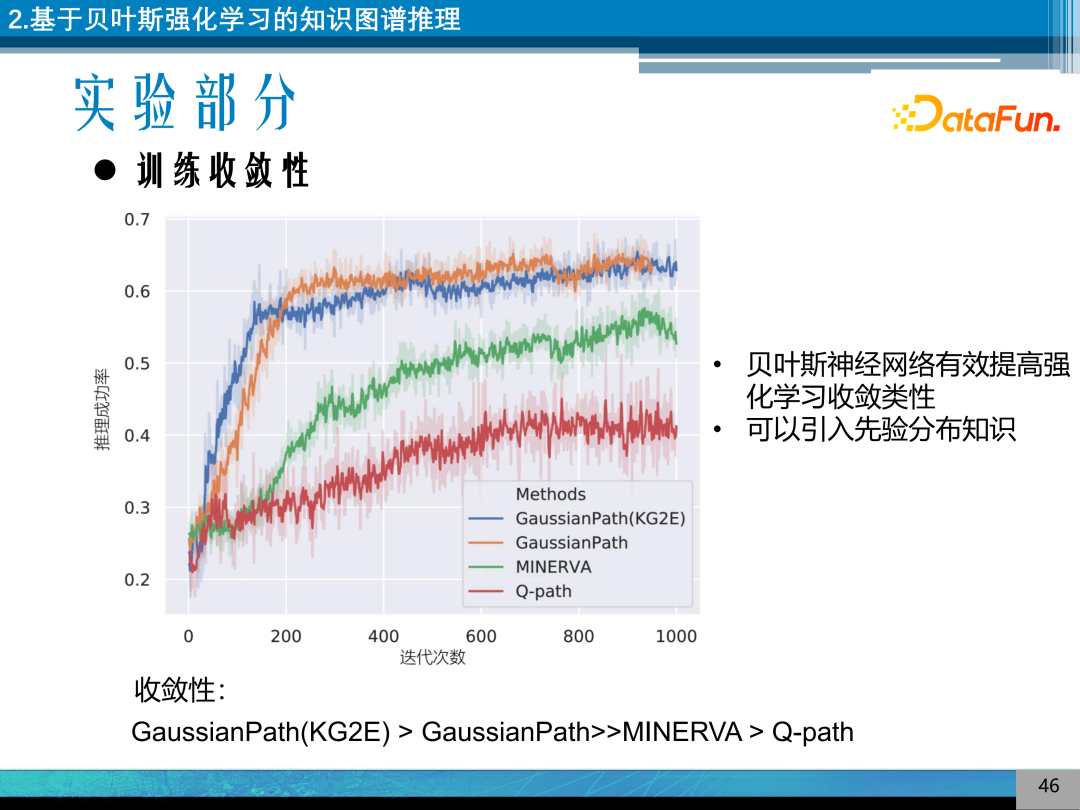
贝叶斯强化学习模型,没有采用随机分布的方式,与 MINERVA 进行对比,可以发现贝叶斯强化学习模型收敛的更快一些,可以引入先验分布,通过对实体的高斯分布的预训练,叶斯强化学习模型收敛的结果更好一些。
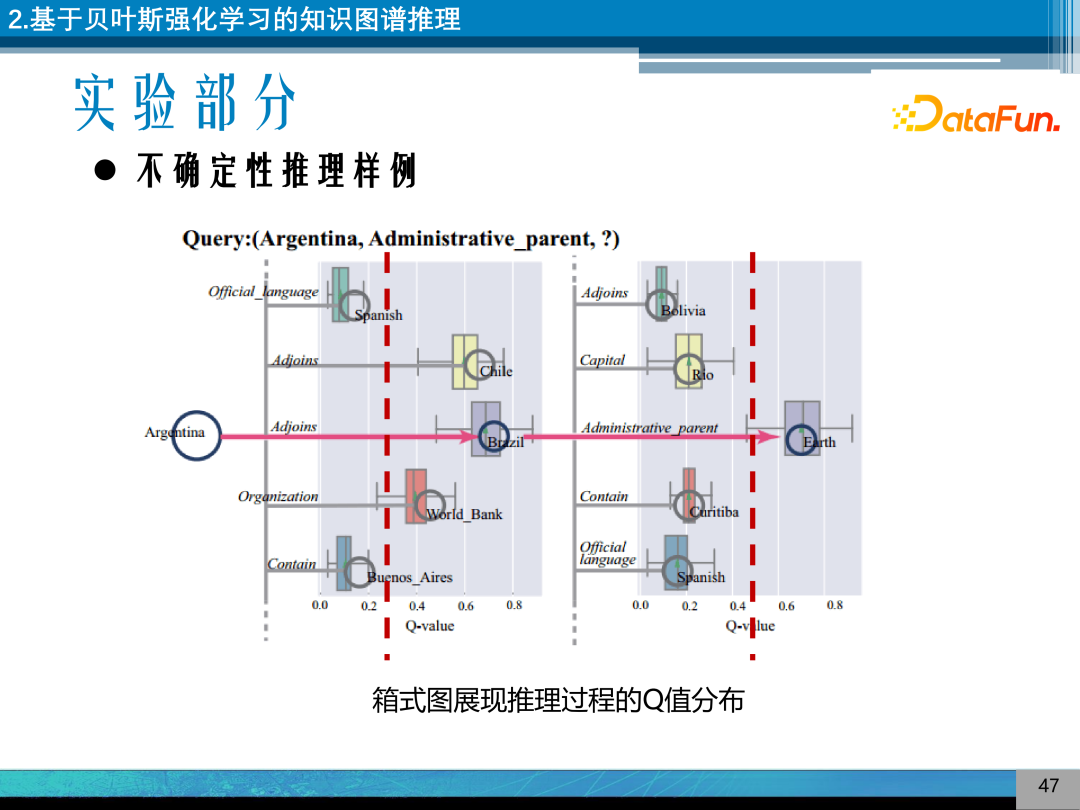
对推理的过程进行箱式图可视化,如图示例中,推理阿根廷是在哪里的?可以不确定性推理,实现 Q 值分布的不确定性,来实现不确定性推理。

图为 GaussianPath 模型在推理过程中产生了一些可解释性的推理路径。

小结:提出一个贝叶斯强化学习的知识推理模型,该模型可以表达多跳推理路径的不确定性;该模型可以利用贝叶斯网络的特性引入先验知识从而加速及稳定强化学习的网路训练。实验表明,该模型可以在标准的数据集上取得竞争性的结果。该工作发表于 2021 年 AAAI 上。
3. 异质信息网络的自动元路径挖掘
第三个工作是基于强化学习的知识图谱推理的应用,就是在异质信息网络的自动元路径挖掘。
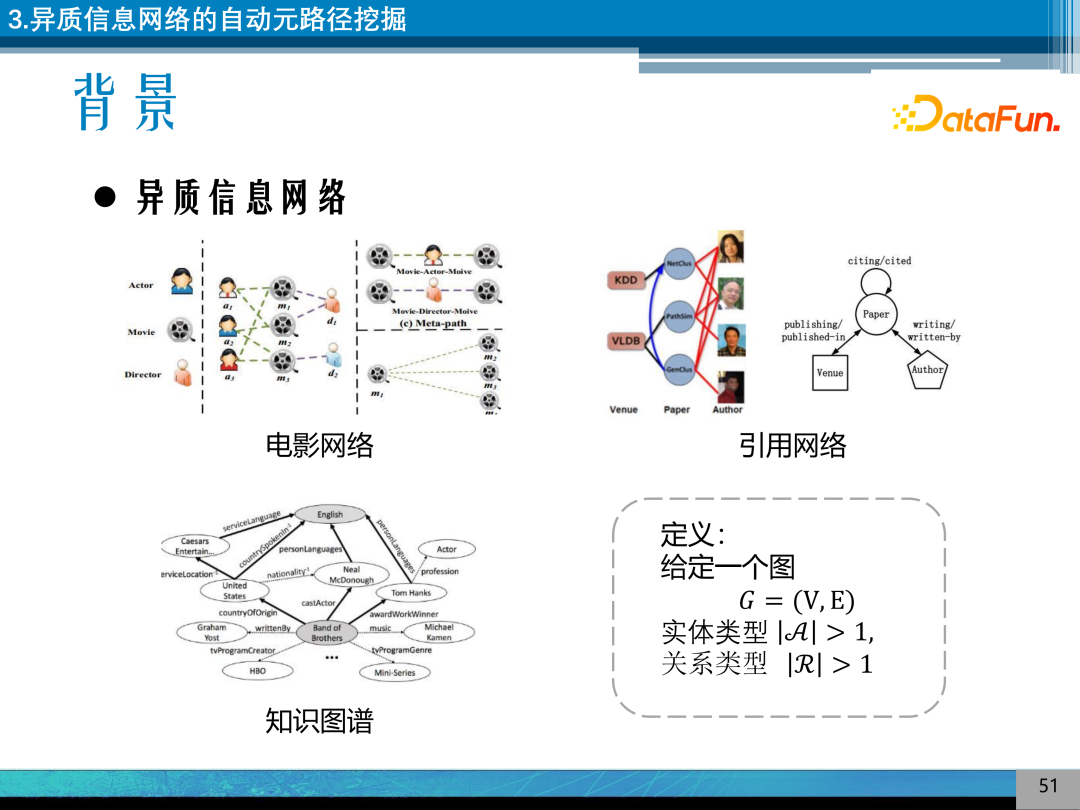
异质信息网络是指图上的节点、关系的种类大于 1 的网络,其定义比知识图谱更加广泛。常见的异质信息网络有电影网络、引用网络、知识图谱等。
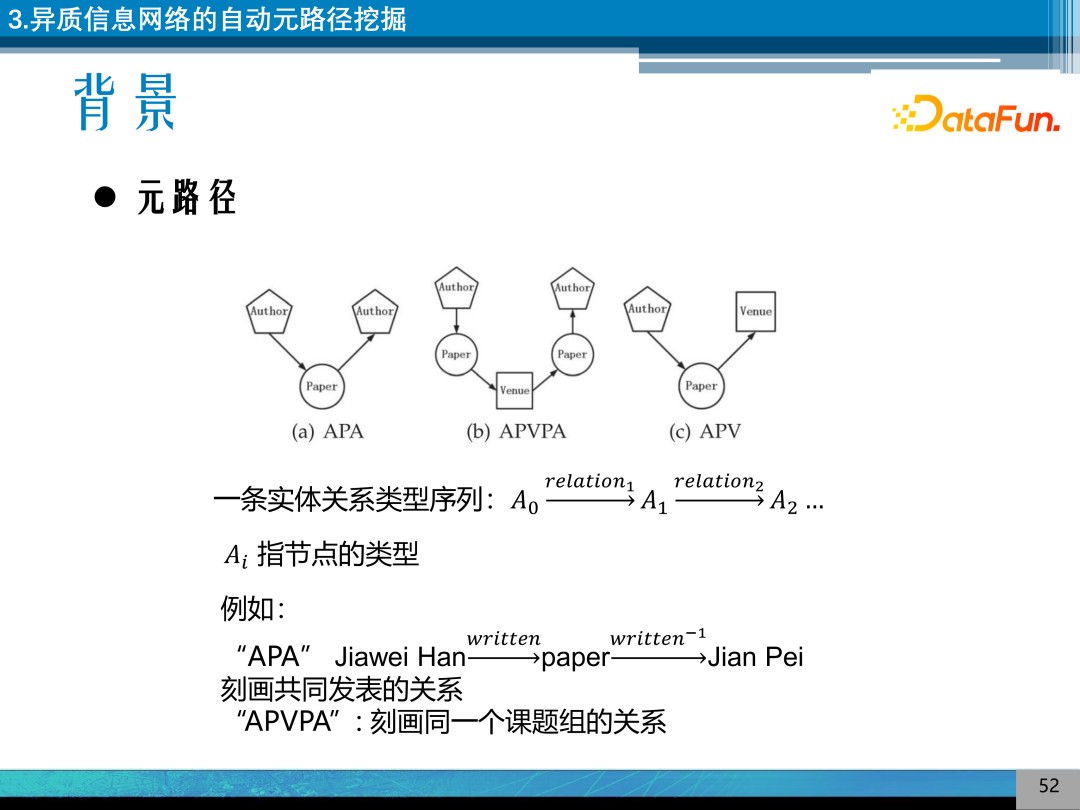
元路径是异质信息网路上非常常用的手段,是实体关系的序列,可以表达实体之间的语义特征,如,“APA”可以刻画共同发表的关系,“APVPA”可以刻画同一个课题组的关系。其在图数据挖掘中产生了一系列非常经典的工作。
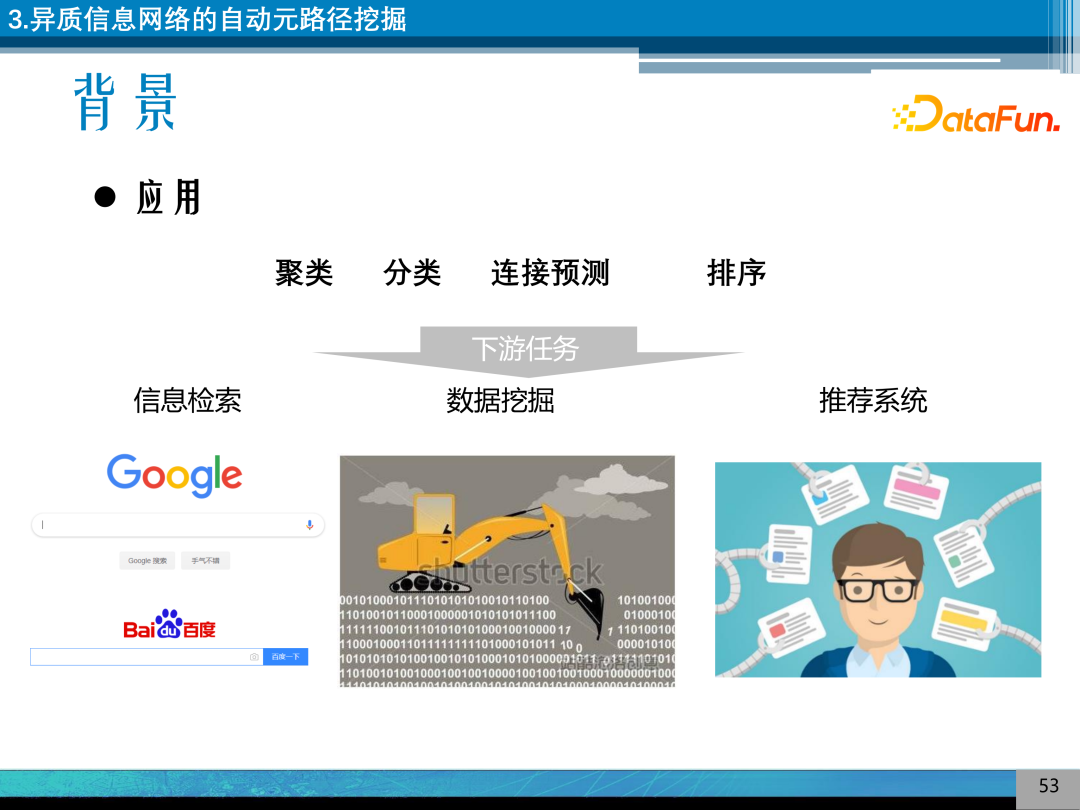
元路径(Meta Path)应用非常广泛,在信息检索、数据挖掘、推荐系统中广泛应用。

元路径优点是,语义表达准确,效率较高,含有图的结构特征,可解释性好。缺点是,需要人工设计,人工构造 Meta Path,是非端到端的方法,对于长序列元路径设计比较困难。
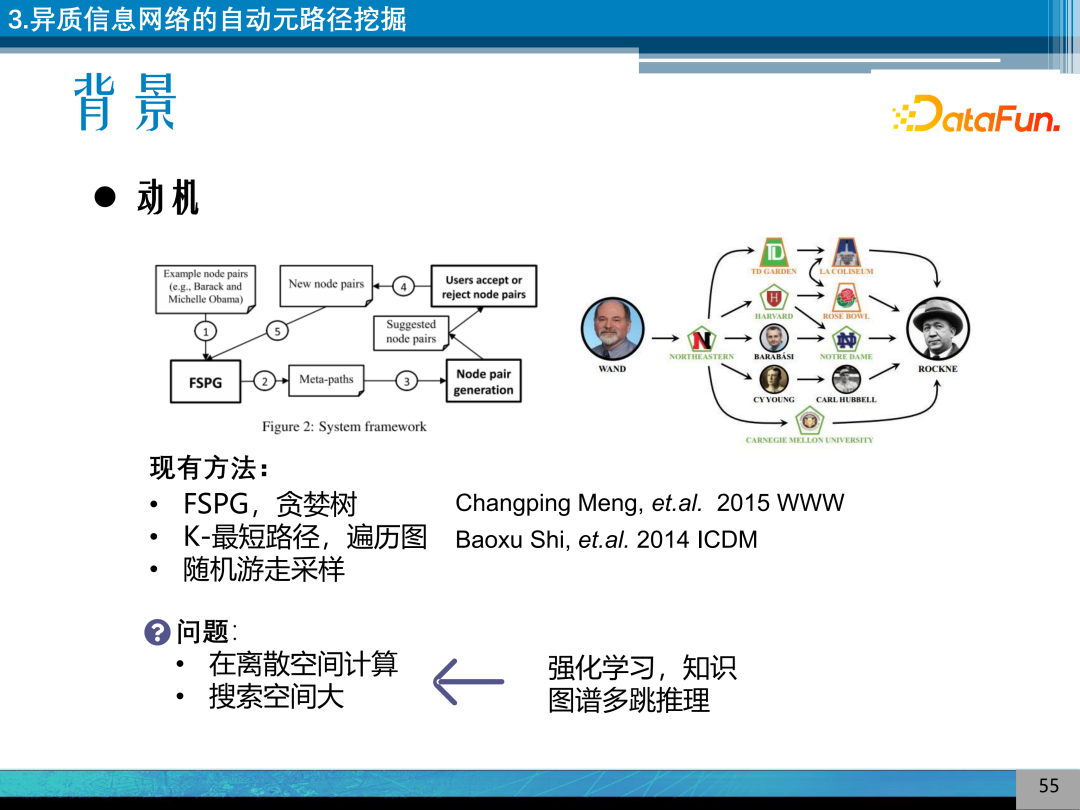
自动得到元路径的方法是基于贪婪树的方法、K-最短路径、图遍历的方式得到 Meta Path。其存在的问题是在离散空间计算,搜索空间比较大。我们研究的异质信息网络的自动元路径挖掘模型,利用强化学习,在推理过程中得到推理路径模式,来得到元路径。
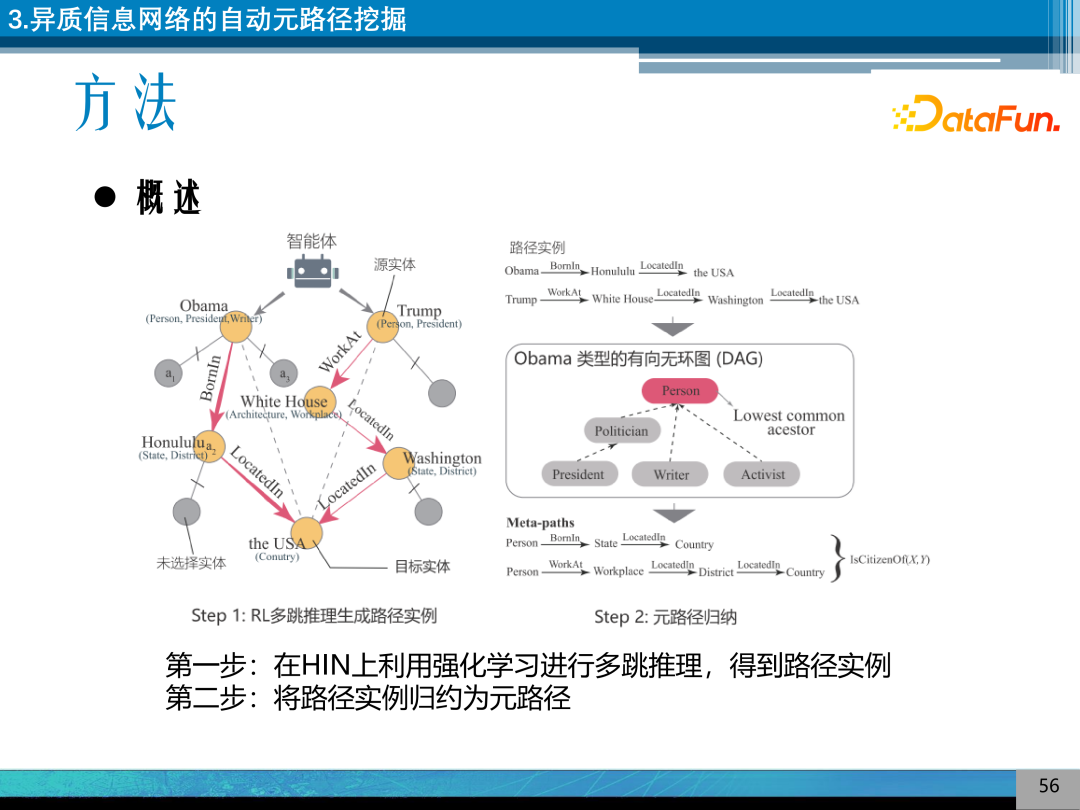
异质信息网络的自动元路径挖掘方法,在 HIN 上利用强化学习进行多跳推理,得到路径实例;在类型有向图上进行规约,得到元路径。

该工作强化学习的框架,与前面两个工作类似,就是在状态、动作设定上略有不同。在状态上加入了 vd 实体的元组;在动作上,是实体在异质信息网络的停留,其动作空间就是与其连接的边和实体;奖赏是基于 γ 的衰减的奖赏函数。
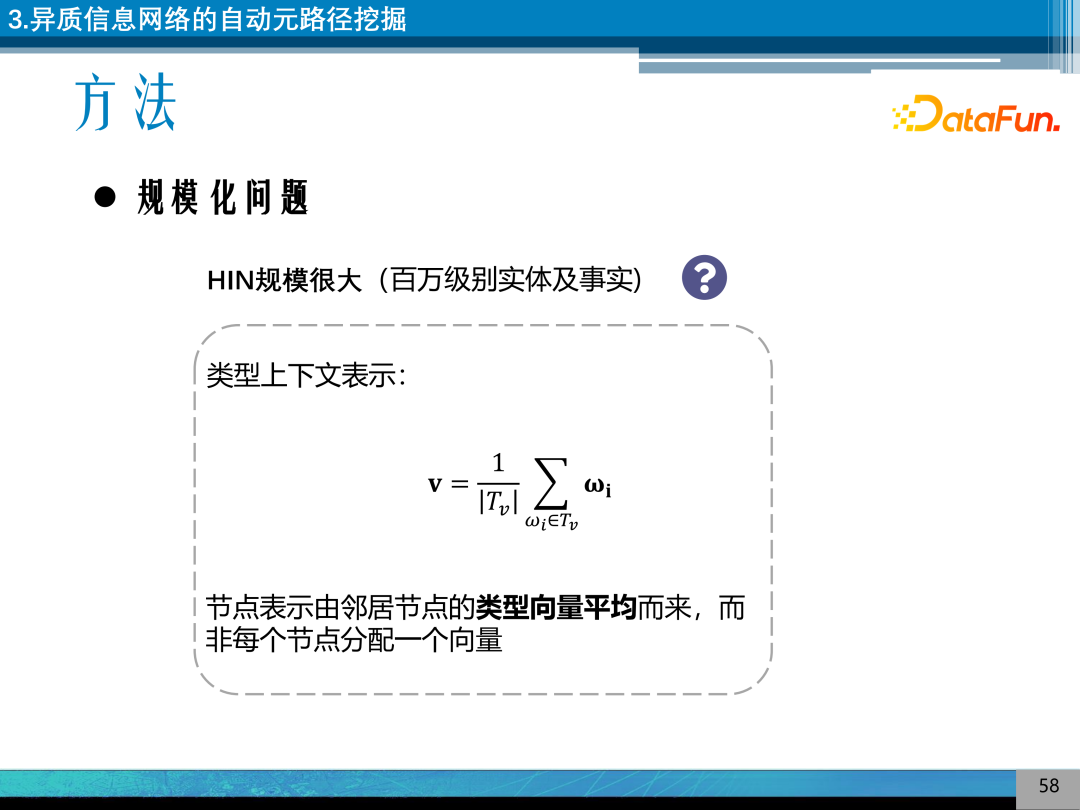
知识图谱的规模通常很大,是百万级别的实体及事实,直接给每个实体分配表向量通常会消耗非常大的存储资源和计算资源。这项工作提出一种基于类型上下文表示的方式,通过将类型向量平均来表示实体,有效减少实体向量存储的问题。

具体路径实例规约方法是基于最低祖先方法,通过在类型图上进行根节点的搜索得到元路径。如,实体类型的 DAG 如图,通过最低祖先搜索的方法得到其是 Person 的类型,最后得到类型及类型的组合,得到元路径。
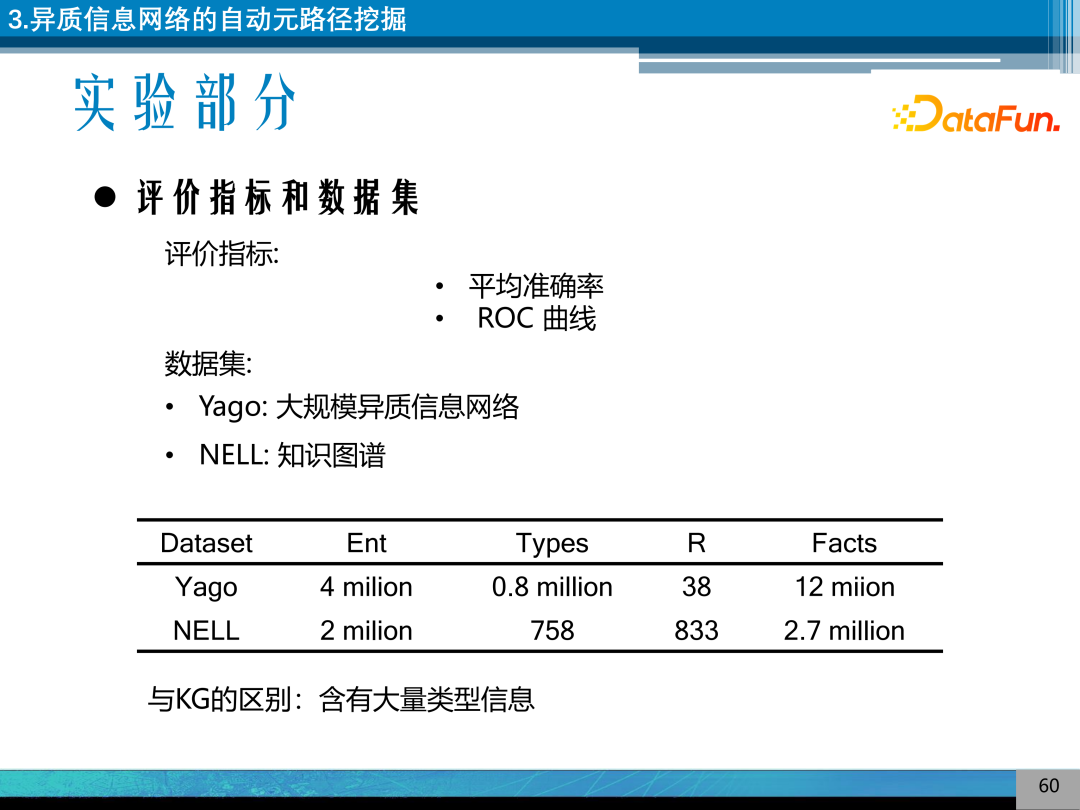
实验部分采用挖掘得到的元路径进行链接预测。采用的数据集是 Yago 和 NELL,即大规模异质信息网络或知识图谱。Yago 和 NELL 具有上百万的实体,Yago 中具有 80 多万个类型;NELL 具有 700 多个类型。与 KG 的区别是具有大量的类型信息。
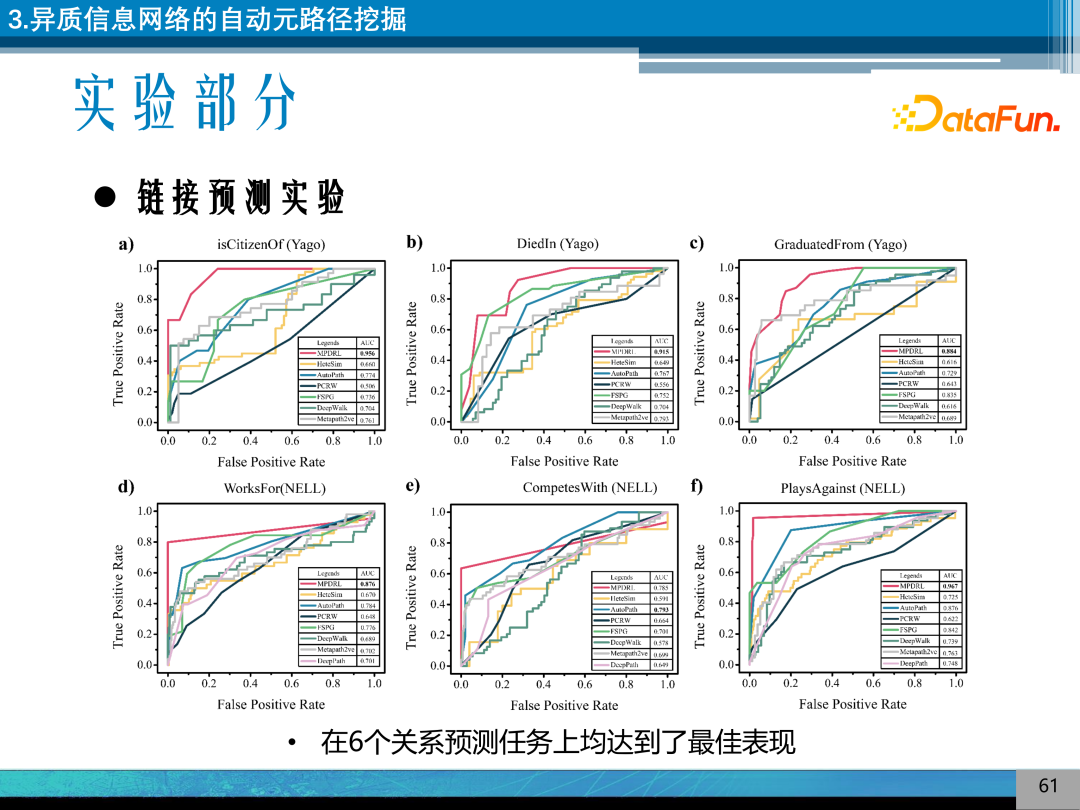
根据链接预测的实验,可以发现通过强化学习挖掘得到的路径,尽管其是一个比较简单的路径特征的线性回归,都可以取得比较好的效果。
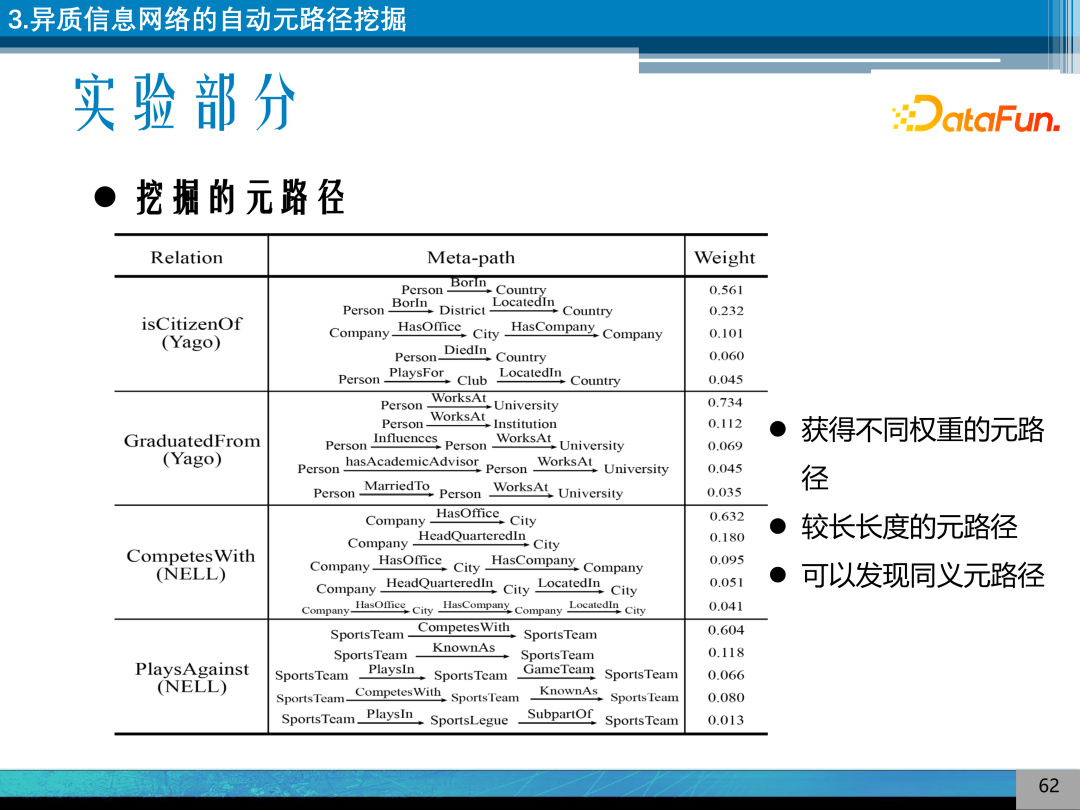
同时,可以通过强化学习推理的回归的 Weight 获得元路径的权重,如,在 Yago 数据集中表示公民的关系,可以由 Person BorIn Country、Person BorIn District LocatedIn Country 主要刻画 isCitizenOf 的关系。该模型可以获得不同权重的元路径,也可以挖掘得到较长长度的元路径,还可以通过元路径的比较发现同义的元路径。

小结:提出一个强化学习的模型,该模型可以在大规模异质信息网络上挖掘元路径,利用上下文表示可以大大缓解异质信息网络的规模性问题。实验表明,即使利用简单的线性回归,挖掘得到的元路径也可以在大规模异质信息网络表现较好。表明异质信息网络核心的限制就是元路径的质量。该工作发表于 2020 年 AAAI 上。
05 总结和展望


深度学习和神经网路的研究进入下一阶段,需要对神经网络的可解释性、鲁棒性进行更加深入的研究。
未来研究知识图谱可解释性的方法可以结合一阶逻辑推理和神经网络,让知识图谱推理可以符合逻辑性,来提高知识图谱的可解释性。
结合进一步的实际查询任务,例如问答系统、信息检索,实现端到端的可解释性知识推理。
利用分解模型或 GNNExplainer 等一些方法,建立现有模型的一些事后可解释性手段。
06 Q&A 问答环节
Q:如何评估生成解释的可理解能力?
A:解释的可解释能力,一般在事后可解释性比较多,如可信度等。在这里研究工作中,更多是事前可解释性的方法。具体可解释性的能力是比较主观的,现有的评估可解释性的方法更多的用于事后可解释性。
今天的分享就到这里,谢谢大家。
分享嘉宾

万国佳,武汉大学计算机学院博士后,目前感兴趣的研究方向为知识图谱推理、图神经网络等在,在AAAI,IJCAI,WWWJ等期刊会议上发表论文6篇。
编辑:王菁
校对:林亦霖