
神经网络的可解释性综述!
本文以 A Survey on Neural Network Interpretability 读后感为主,加上自身的补充,浅谈神经网络的可解释性。
本文按照以下的章节进行组织:
人工智能可解释性的背景意义 神经网络可解释性的分类 总结
01
解释(Explanations),是指需要用某种语言来描述和注解
可解释的边界(Explainable Boundary),是指可解释性能够提供解释的程度
可理解的术语(Understandable Terms),是指构成解释的基本单元
高可靠性的要求
伦理/法规的要求
作为其他科学研究的工具
02

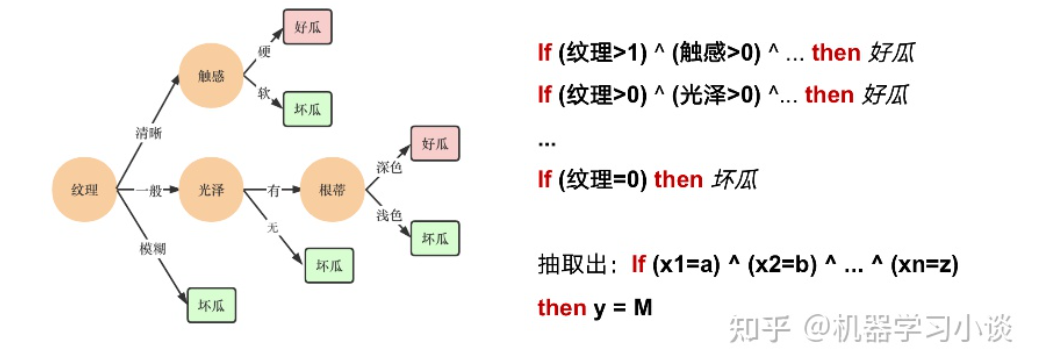
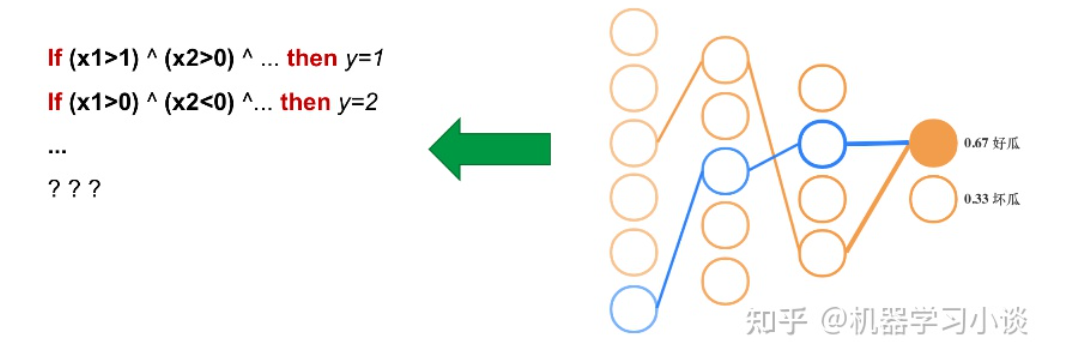

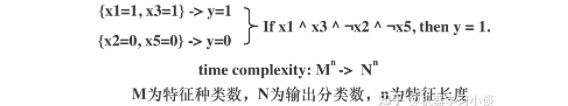
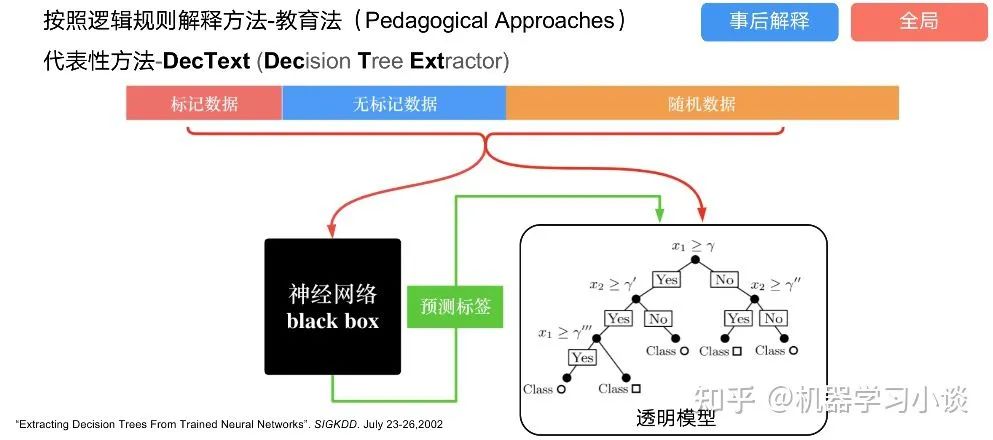

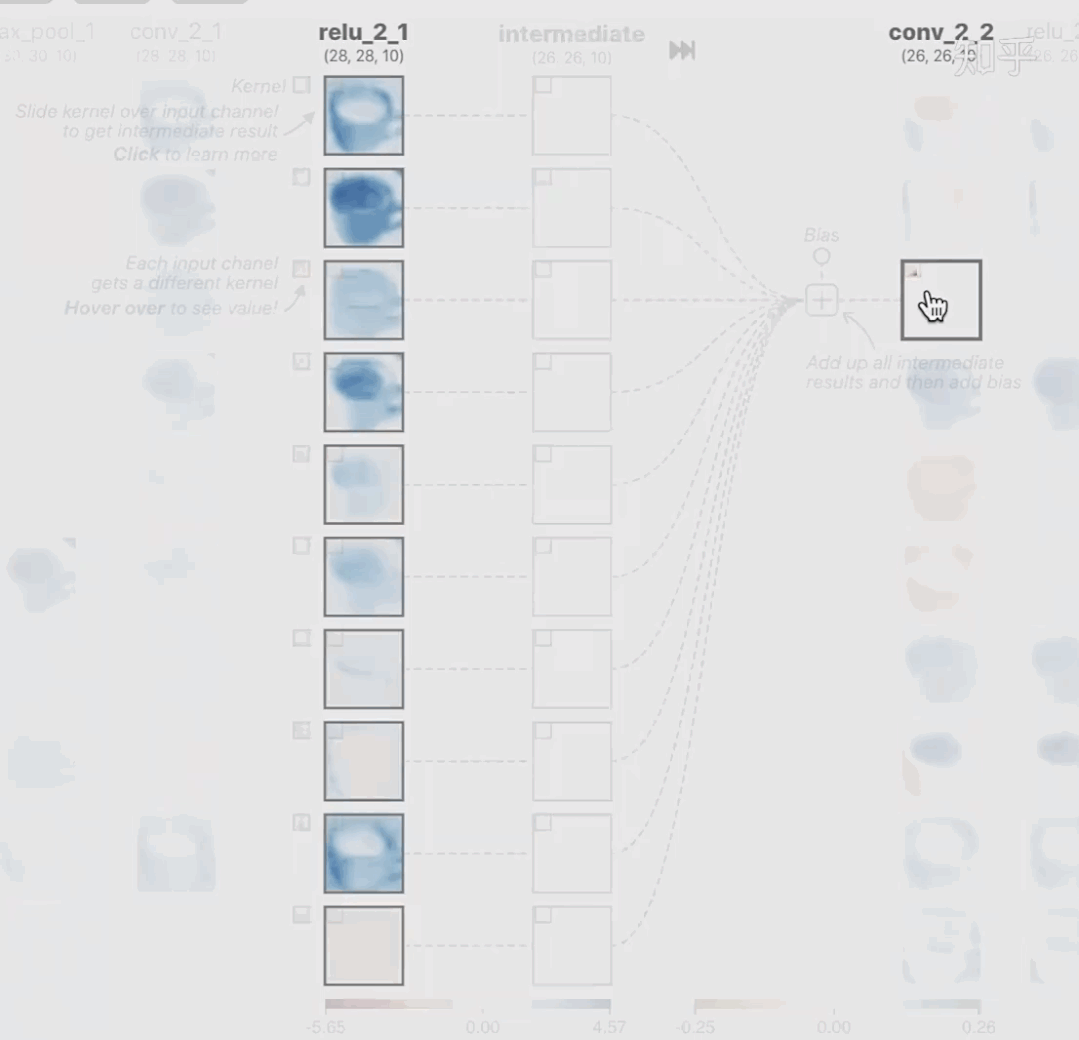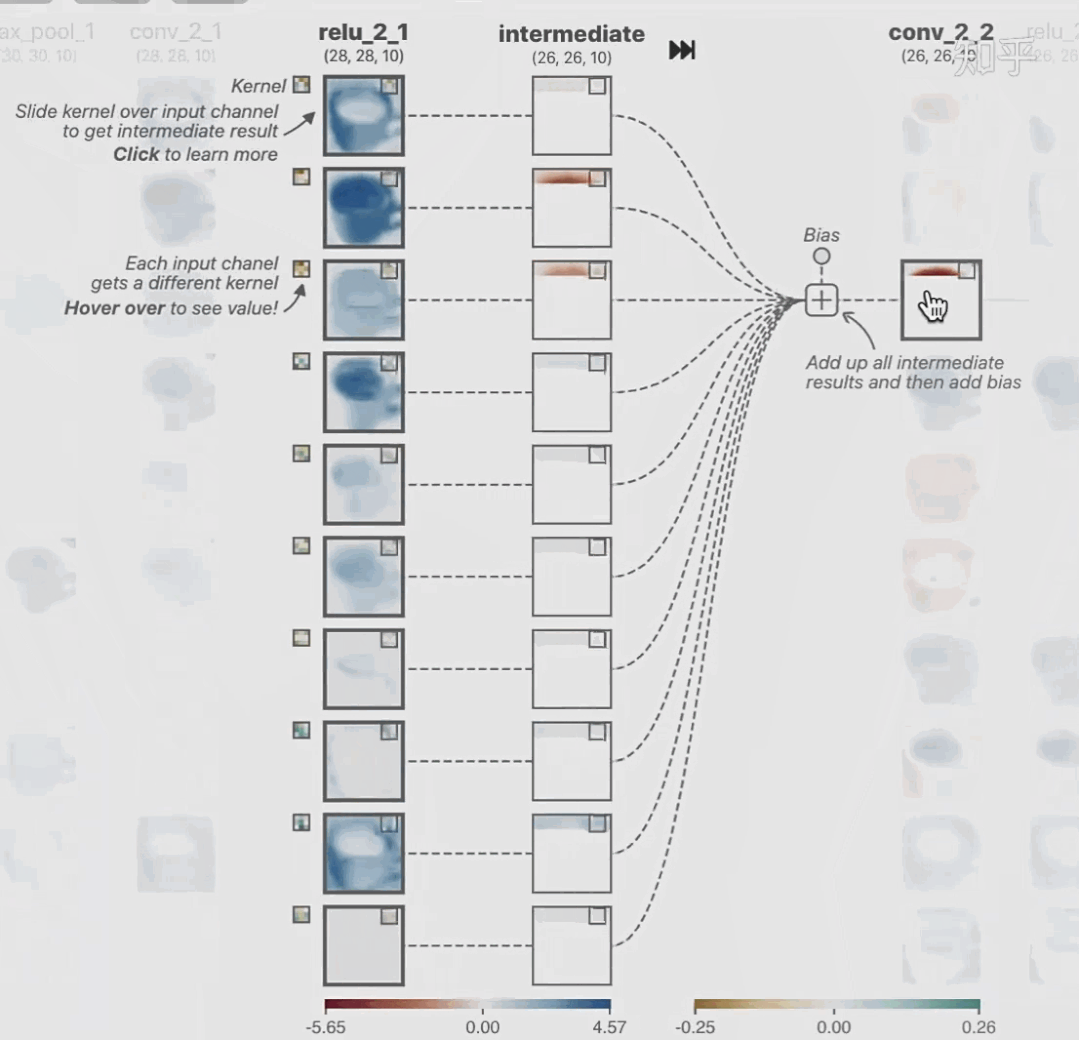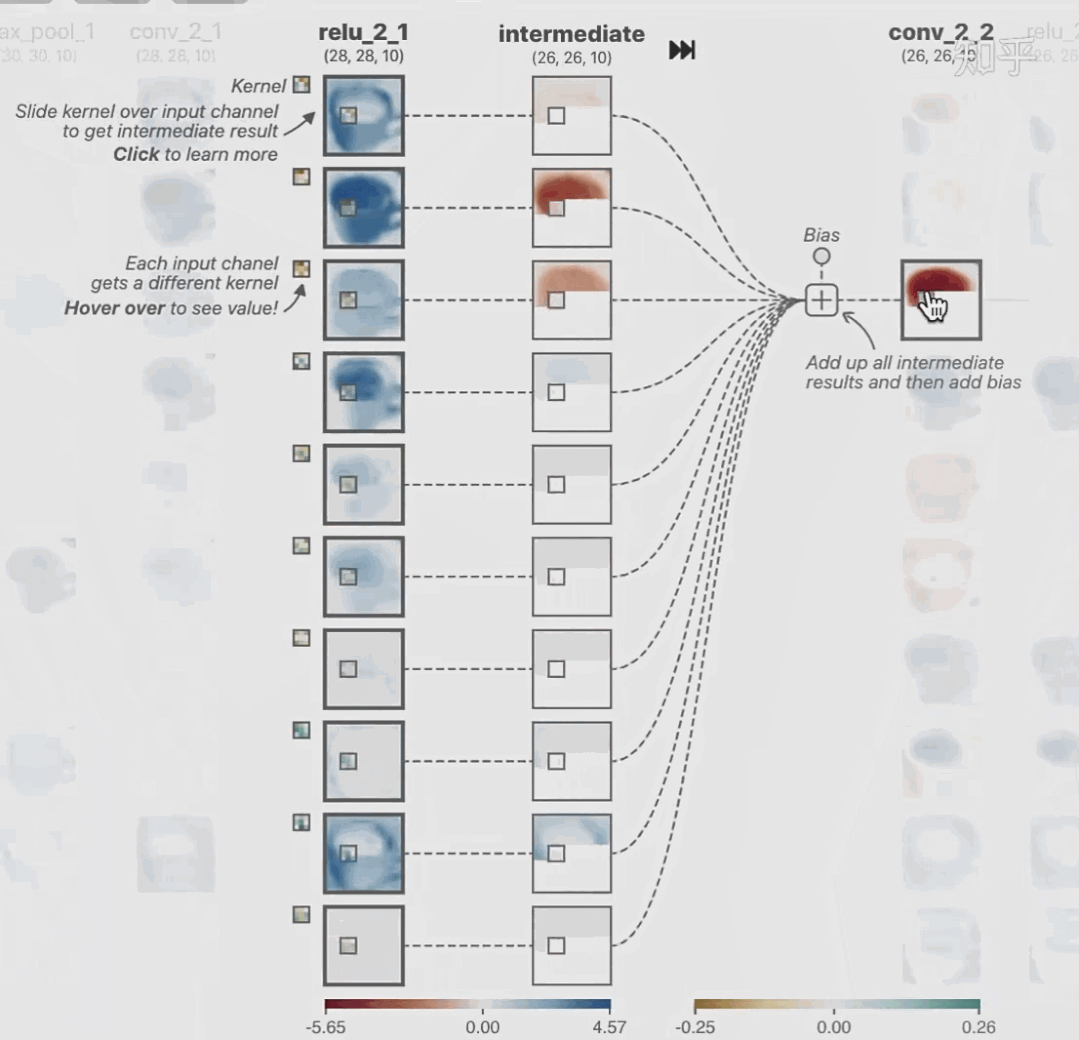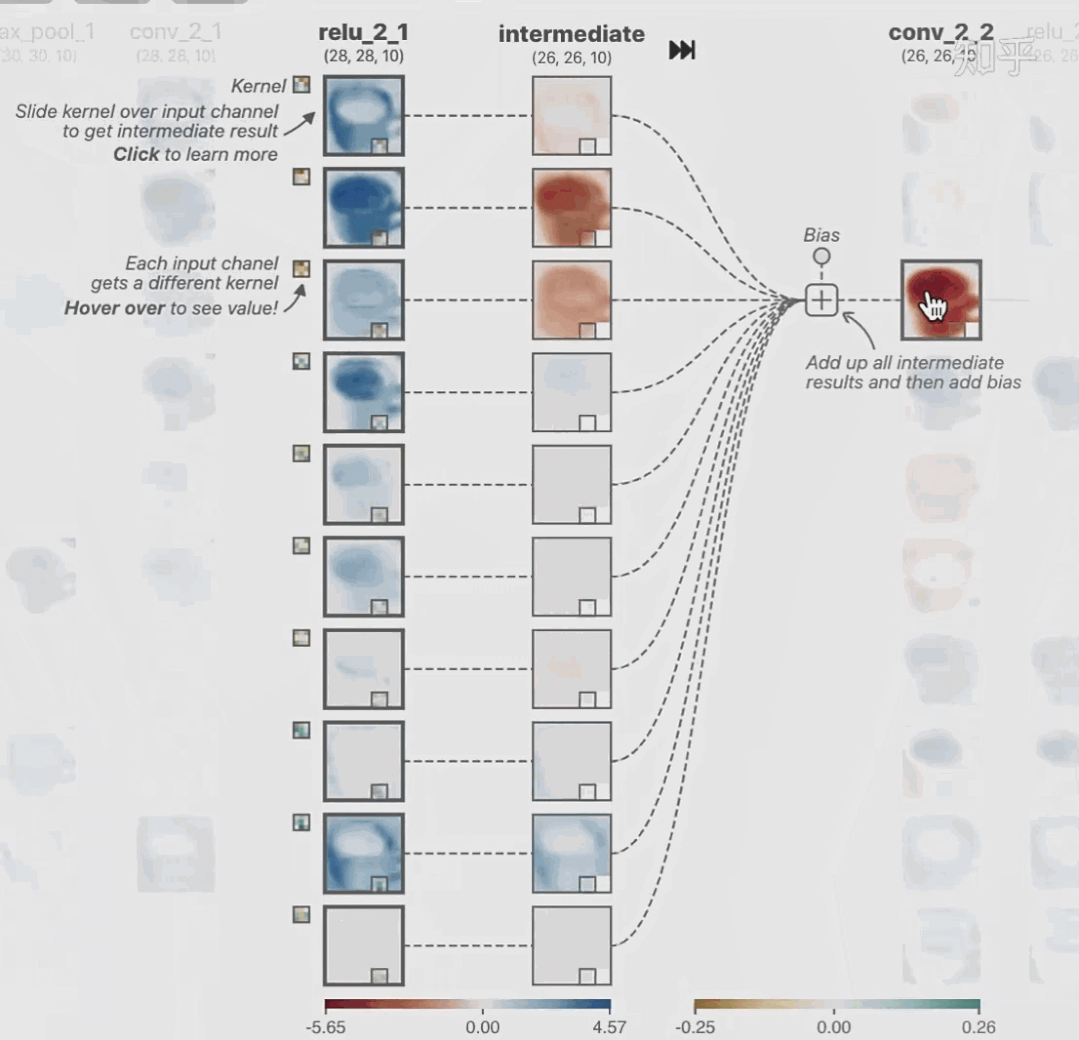

featuremap_layout
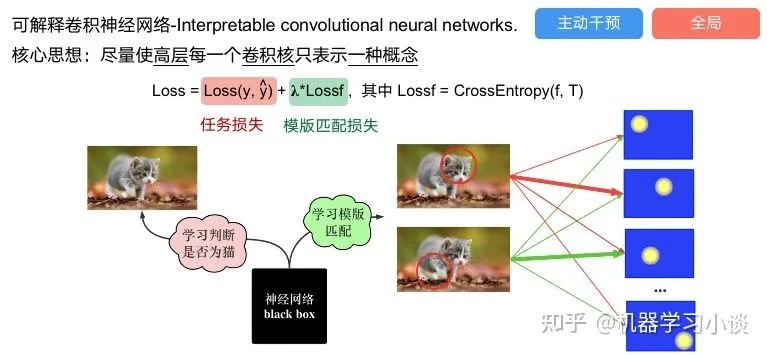

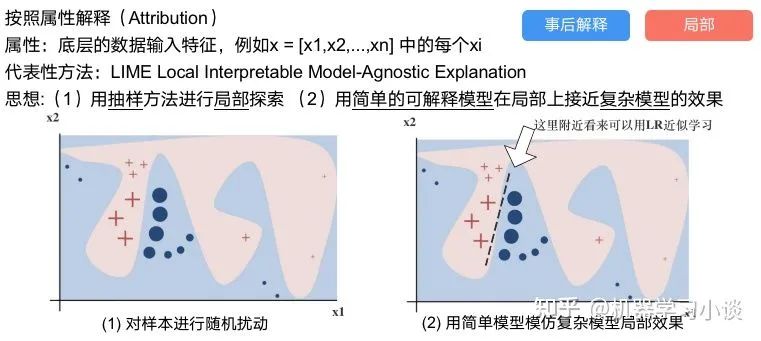
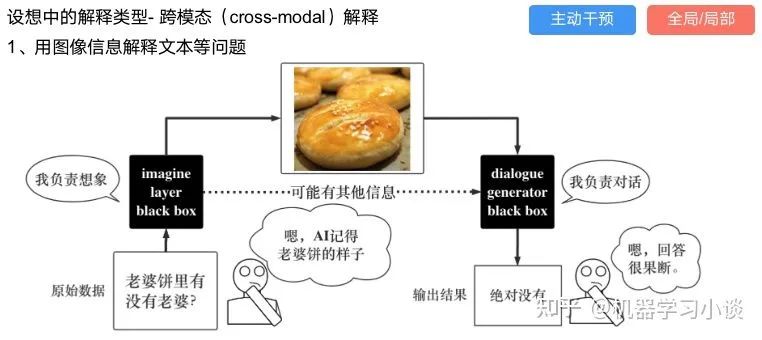
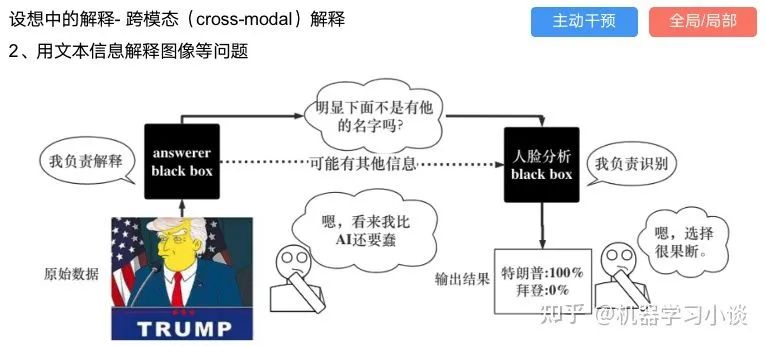
03


评论