
PP-YOLO何许模型?竟然超越了YOLOv4
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
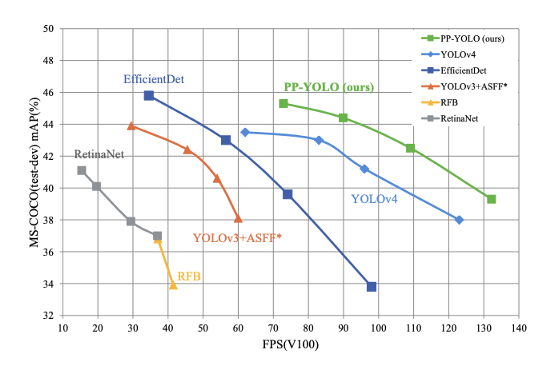
PP-YOLO评估显示出更快的推断(x轴)和更好的准确性(y轴)
PP-YOLO评估指标显示出比现有的最新对象检测模型YOLOv4更高的性能。但是,提出者百度却谦虚的声明:
无意介绍一种新颖的物体检测器。它更像一个配方,它告诉我们如何逐步构建更好的检测器。
接下来让我们来介绍一下PP-YOLO
YOLO发展历程
YOLO最初是由约瑟夫·雷德蒙(Joseph Redmon)创作的,用于检测物体。物体检测是一种计算机视觉技术,它通过在对象周围绘制边框并标识给定框也属于的类标签来对对象进行定位和标记。与大型NLP不同,YOLO设计得很小,可以为设备上的部署提供实时推理速度。
YOLO-9000是约瑟夫·雷德蒙发布的第二个“ YOLOv2”物体检测器,它改进了检测器并强调了该检测器能够推广到世界上任何物体的能力。之后,YOLOv3进一步完善了检测网络,并开始将物体检测过程纳入主流。但是,出于某些原因,约瑟夫·雷德蒙退出了物体检测的游戏。不过,技术的进步不会因为一个人的退出而停止,开源社区接过接力棒,并继续推动YOLO技术向前发展。YOLOv4于今年春天由Alexey AB在YOLO Darknet存储库中发布。YOLOv4主要是其他已知计算机视觉技术的集合,并通过研究过程进行了组合和验证。然后,就在几个月前,发布了YOLOv5。YOLOv5采用了Darknet(基于C)的培训环境,并将网络转换为PyTorch。改进的训练技术进一步提高了模型的性能,并创建了一个出色的,易于使用的开箱即用的对象检测模型。

正在对PP-YOLO进行识别不同果蝇的训练
PP代表什么?
PP是PaddlePaddle(由百度编写的深度学习框架)的缩写。百度提供了他的下载和安装方式,具体地址为:https://www.paddlepaddle.org.cn/,下图是官网的安装界面。

如果PaddlePaddle对您来说是新手,那么我们在同一条船上。PaddlePaddle主要是用Python编写的,看起来类似于PyTorch和TensorFlow。对PaddlePaddle框架的深入研究很有趣,但超出了本文的范围。
PP-YOLO贡献
PP-YOLO的读取方式与YOLOv4非常相似,因为它是计算机视觉中已知的技术的汇总。新颖的贡献是证明这些技术的集成可以提高性能,并提供消融研究,以了解每个步骤对模型的帮助程度。
在我们深入探讨PP-YOLO的贡献之前,有必要回顾一下YOLO检测器的架构。
YOLO检测器的解剖
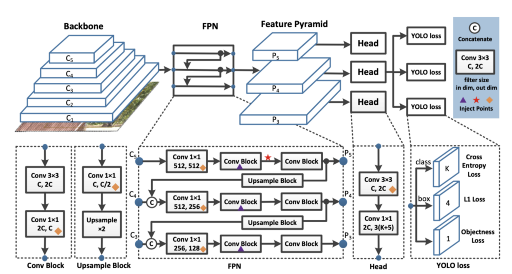
YOLO检测器分为三个主要部分。
YOLO骨架 — YOLO骨架是一个卷积神经网络,它将图像像素合并以形成不同粒度的特征。主干通常在分类数据集(通常为ImageNet)上进行预训练。
YOLO脖子— YOLO脖子(上面选择了FPN)在传递到预测头之前对ConvNet图层表示进行组合和混合。
YOLO头部 —这是网络中进行边界框和类预测的部分。它由关于类,框和对象的三个YOLO损失函数指导。
现在让我们深入了解PP YOLO贡献
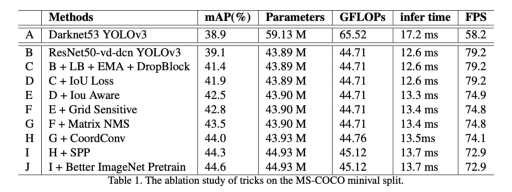
PP-YOLO中的每种技术都会提高边际mAP准确度性能
更换骨架
第一种PP YOLO技术是用Resnet50-vd-dcn ConvNet主干替换YOLOv3 Darknet53主干。Resnet是一个更流行的主干,它的执行优化了更多的框架,并且其参数少于Darknet53。交换此主干可以看到mAP的改进,这对PP YOLO来说是一个巨大的胜利。
模型参数的EMA
PP YOLO跟踪网络参数的指数移动平均值,以维持预测时间的模型权重的阴影。已经证明这可以提高推理精度。
批量更大
PP-YOLO的批量大小从64增加到192。当然,如果您有GPU内存限制,这很难实现。
DropBlock正则化
PP YOLO在FPN脖子上实现DropBlock正则化(过去,这通常发生在主干中)。DropBlock在网络中的给定步骤中随机删除了一部分训练功能,以指示模型不依赖于关键特征进行检测。
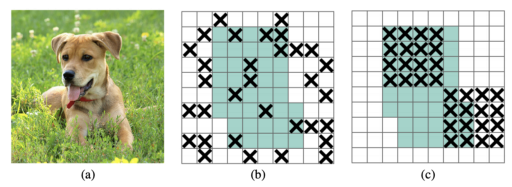
IoU损失
YOLO损失函数不能很好地转换为mAP度量,该度量在计算中大量使用了Union上的Intersection。因此,考虑到此结束预测来编辑训练损失函数很有用。此编辑也出现在YOLOv4中。
IoU意识
PP-YOLO网络添加了一个预测分支,以预测给定对象的模型估计的IOU。在做出是否预测对象的决策时包括IoU意识会提高性能。
网络敏度
旧的YOLO模型不能很好地在锚框区域的边界附近进行预测。定义盒子坐标稍有不同是很有用的,以避免此问题。YOLOv4中也存在此技术。
矩阵NMS
非最大抑制是一种删除候选对象的提议以进行分类的技术。矩阵NMS是一项技术,可以对这些候选预测进行并行排序,从而加快了计算速度。
协调转换
CoordConv受ConvNets仅将(x,y)坐标映射到一个热像素空间所遇到的问题的激励。CoordConv解决方案使卷积网络可以访问其自己的输入坐标。CoordConv干预措施上方标有黄色菱形。有关更多详细信息,请参见CordConv文件。
SPP
空间金字塔池化是主干层之后的一个额外块,用于混合和合并空间特征。也已在YOLOv4和YOLOv5中实现。
更好的预训练骨架
PP YOLO的作者提炼出更大的ResNet模型作为骨干。更好的预训练模型显示也可以改善下游转移学习。
PP-YOLO是最先进的吗?
PP-YOLO胜过2020年4月23日发布的YOLOv4结果。
作者的意图似乎不只是“引入一种新颖的新型检测器”,而是展示了仔细调整对象检测器以最大化性能的过程。在此引用作者原文的介绍:
本文的重点是如何堆叠一些几乎不会影响效率的有效技巧以获得更好的性能……本文无意介绍一种新颖的目标检测器。它更像一个食谱,它告诉您如何逐步构建更好的检测器。我们发现了一些对YOLOv3检测器有效的技巧,可以节省开发人员的反复试验时间。最终的PP-YOLO模型以比YOLOv4更快的速度将COCO的mAP从43.5%提高到45.2%
上面的PP-YOLO贡献参考将YOLOv3模型在COCO对象检测任务上从38.9 mAP提升到44.6 mAP,并将推理FPS从58增加到73。论文中显示了这些指标,胜过了YOLOv4和EfficientDet的当前发布结果。
在以YOLOv5为基准对PP-YOLO进行基准测试时,似乎YOLOv5在V100上仍具有最快的推理准确度(AP与FPS)折衷。但是,YOLOv5论文仍然有待发布。此外,已经表明,在YOLOv5 Ultralytics存储库上训练YOLOv4体系结构的性能要优于YOLOv5,并且,以过渡方式,使用YOLOv5贡献进行训练的YOLOv4的性能将胜过此处发布的PP-YOLO结果。这些结果仍有待正式发布,但可以追溯到GitHub(https://github.com/ultralytics/yolov5/issues/6)上的讨论。
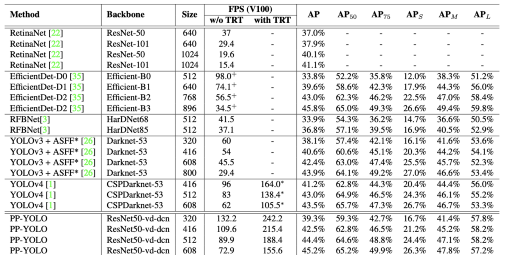
在V100 GPU上对COCO数据集的PP-YOLO评估(请注意AP_50列)
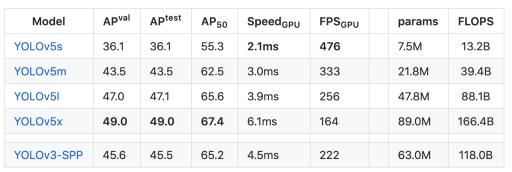
在V100 GPU上对COCO数据集的YOLOv5评估(请注意AP_50列)
值得注意的是,在YOLOv4中使用的许多技术(例如体系结构搜索和数据增强)在PP YOLO中并未使用。这意味着随着更多的这些技术被组合和集成在一起,在物体检测领域中仍存在发展的空间。
毋庸置疑,这是实施计算机视觉技术的激动人心的时刻。
我应该从YOLOv4或YOLOv5切换到PP-YOLO吗?
PP-YOLO模型显示了最先进的对象检测技术的前景,但是与其他对象检测器相比,这些改进是渐进的,并且是在一个新的框架中编写的。在此阶段,最好的办法是通过在自己的数据集上训练PP-YOLO来开发自己的经验结果。