
全球GPU缺口超40万张!算力之困,中国大模型有解了

新智元报道
新智元报道
【新智元导读】大模型时代,玩家如何掘金?最近,这套大模型智算软件栈OGAI,竟吸引了国内几十家参与「百模大战」的企业围观。


大模型,怎样才能玩得起

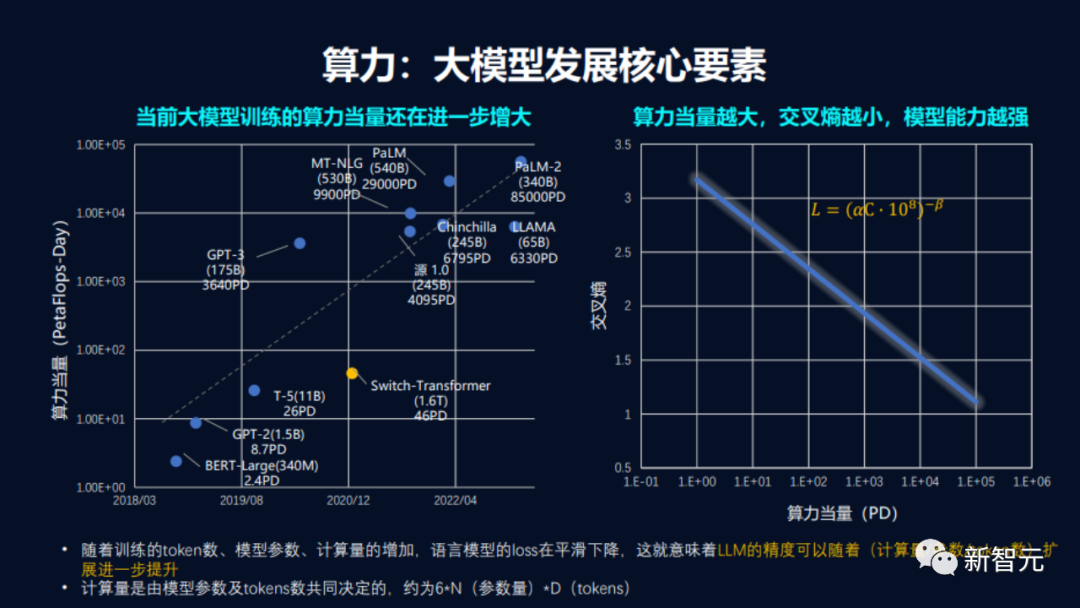
瓶颈之下,算力利用率变得尤为重要
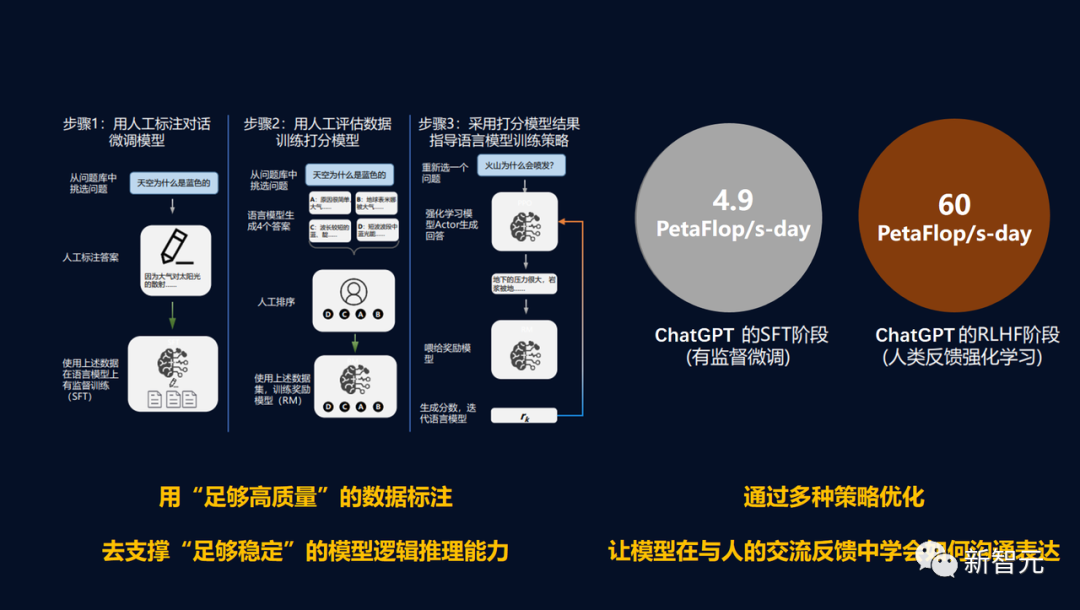
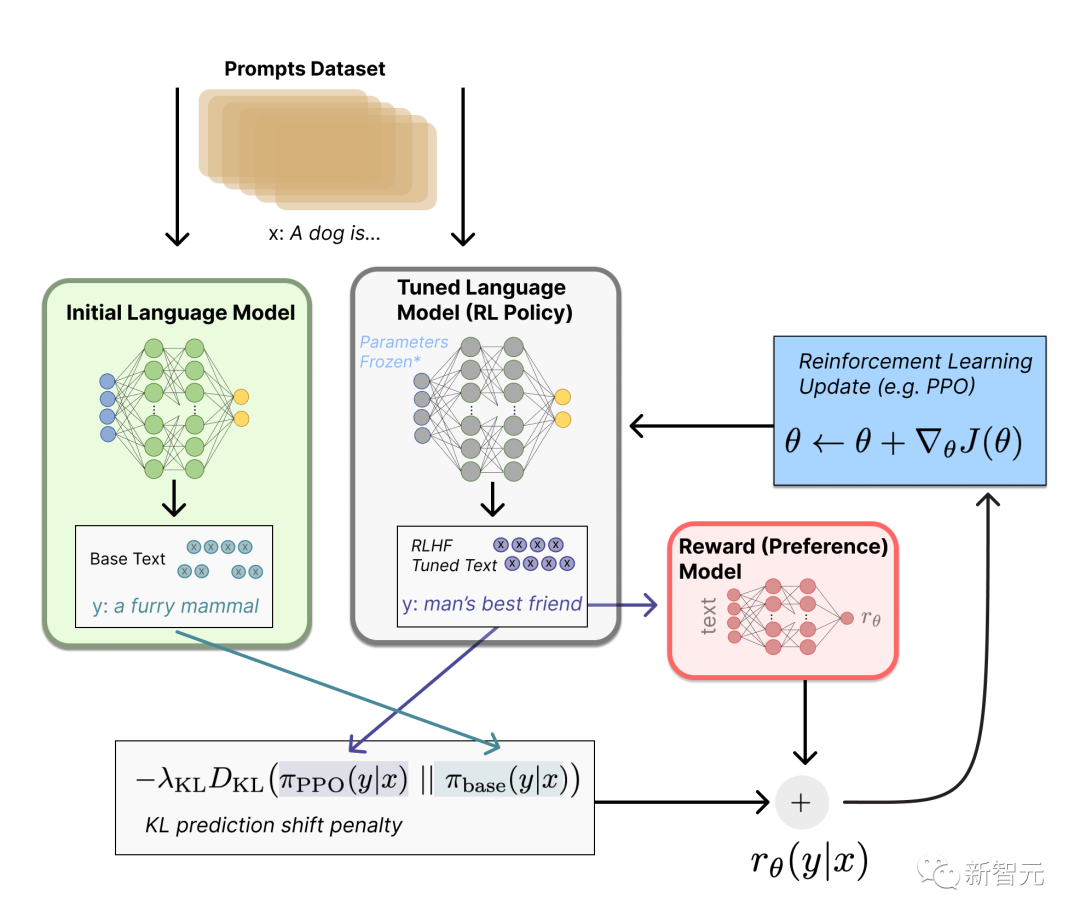
从数据到算法再到RLHF,过程冗长

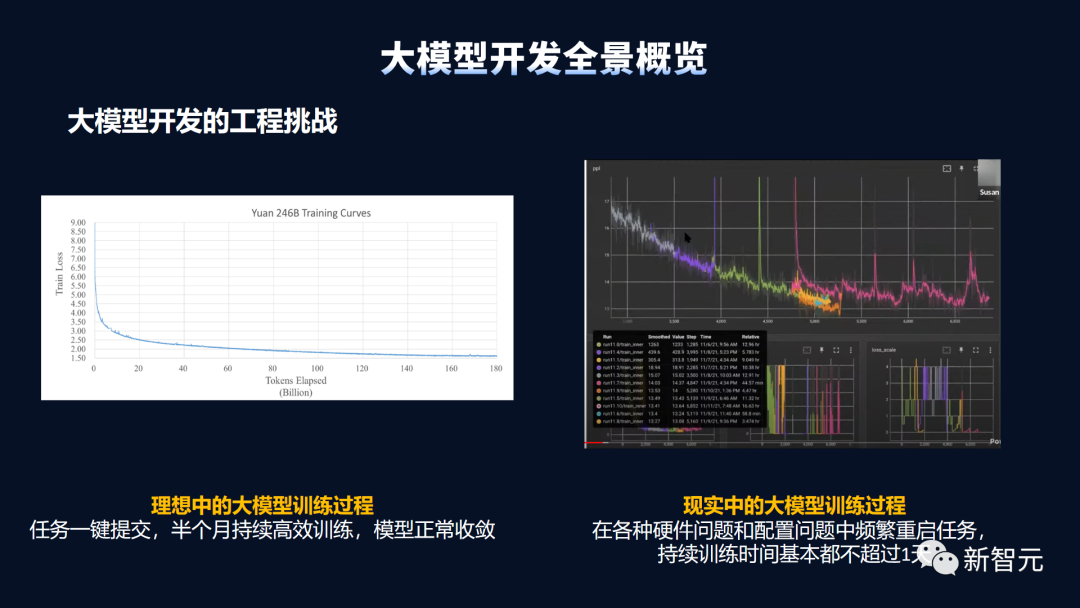
模型训练:周期长、效率低,断点问题严峻
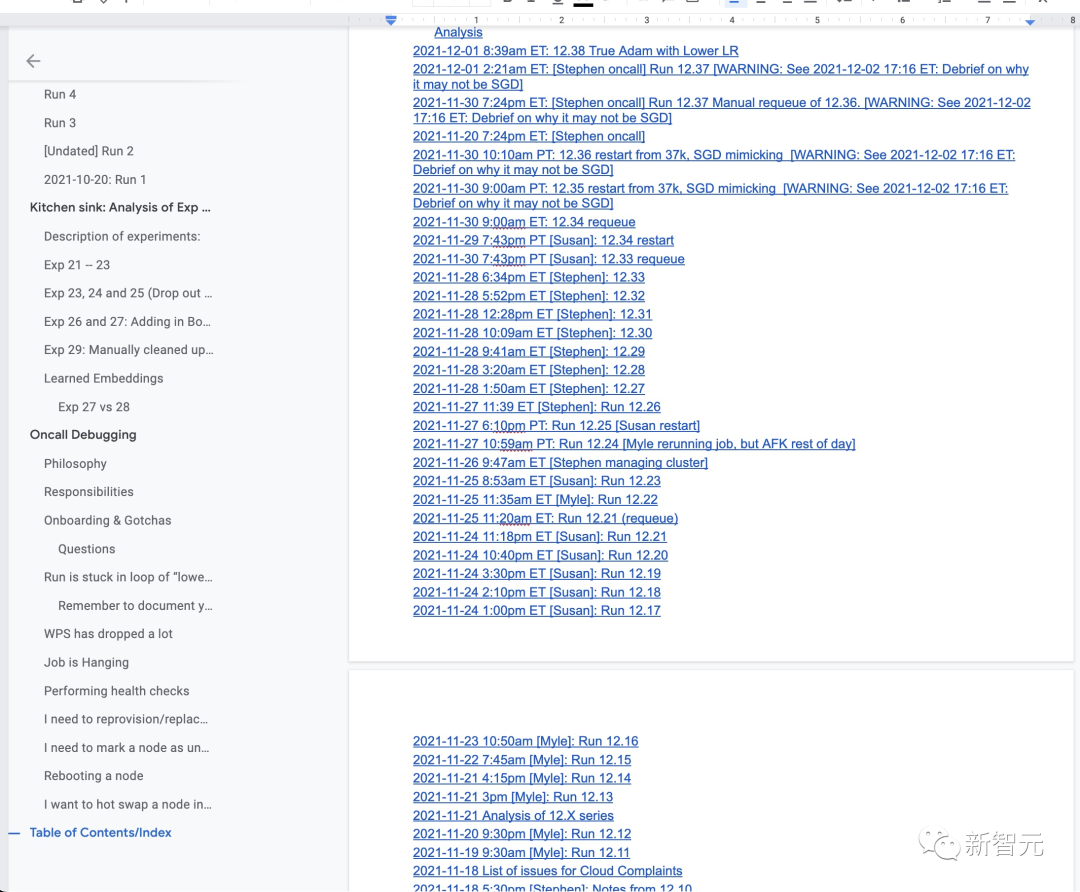
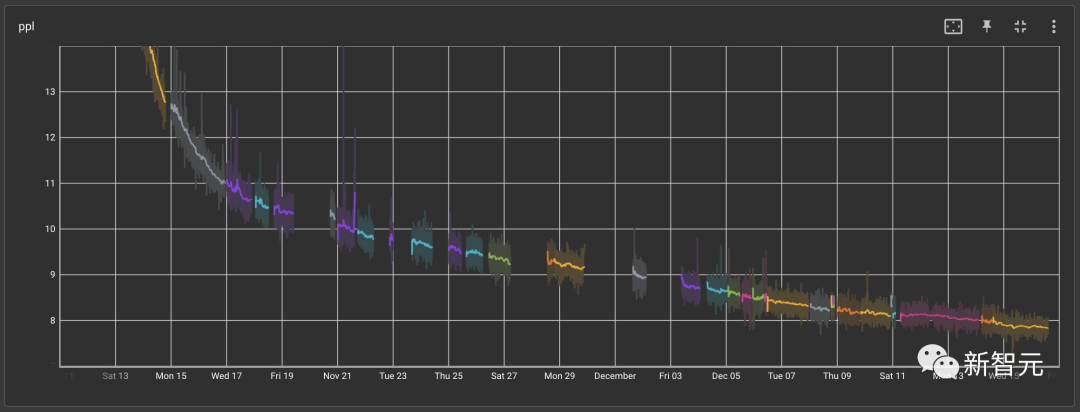
总而言之,解决基础设施问题占据了团队最后两周的大部分时间,因为这些硬件问题可能会在一天中的任何时间导致训练中断几个小时。
虽然我们充分意识到这些问题会在这种规模的训练过程中反复出现,但考虑到在2021年底之前完成一个175B模型训练全部工作时间非常紧迫,我们别无选择,只能通过不停重启的方式,看看如果没有额外的训练工具的帮助我们能走多远。
OGAI:你可能要踩的坑,他们都替你踩过了
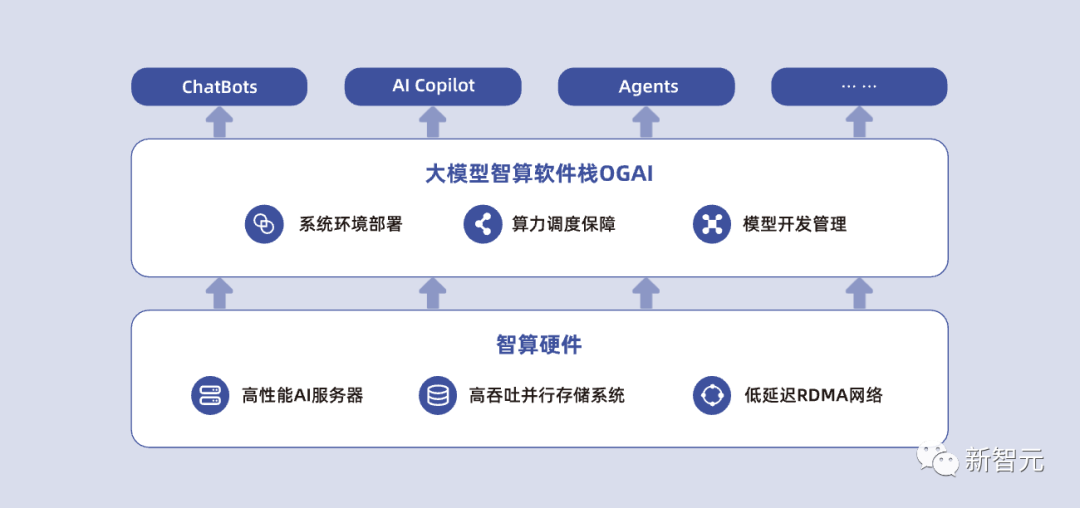

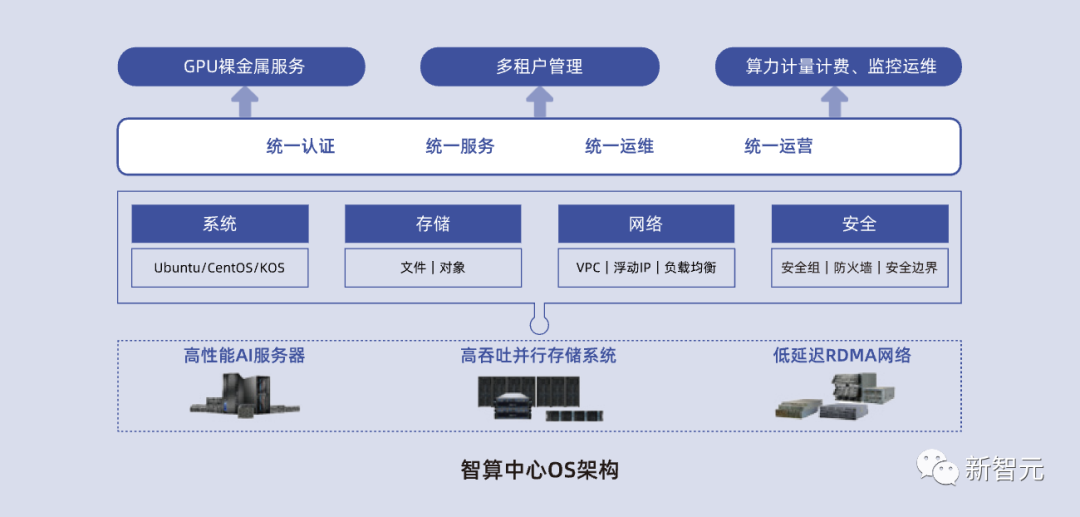
L0层智算中心OS:面向大模型算力服务的智能算力运管平台,满足多租户以裸金属为主的弹性AI算力运管需求。
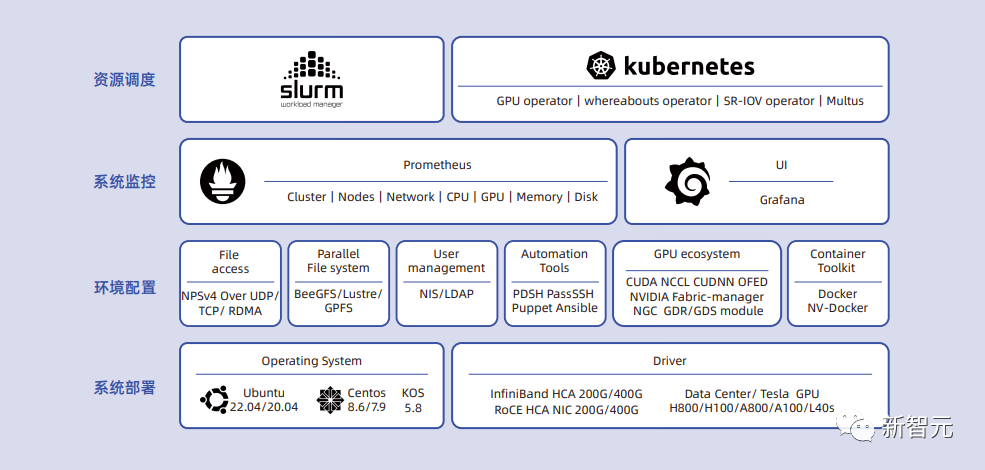
L1层PODsys:开源、高效、兼容、易用的智算集群系统环境部署方案。



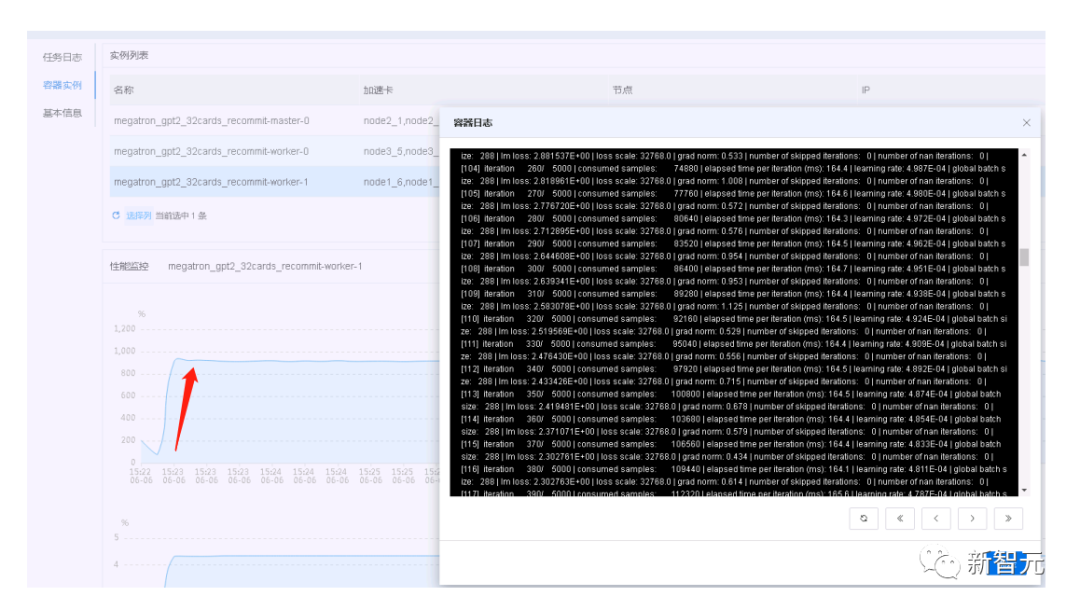
L2层AIStation:面向大模型开发的商业化人工智能算力调度平台。

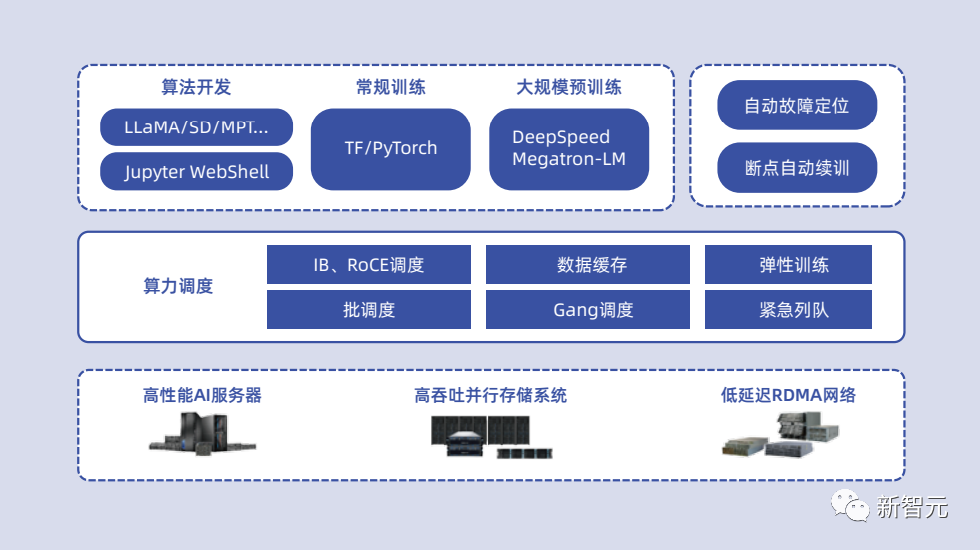
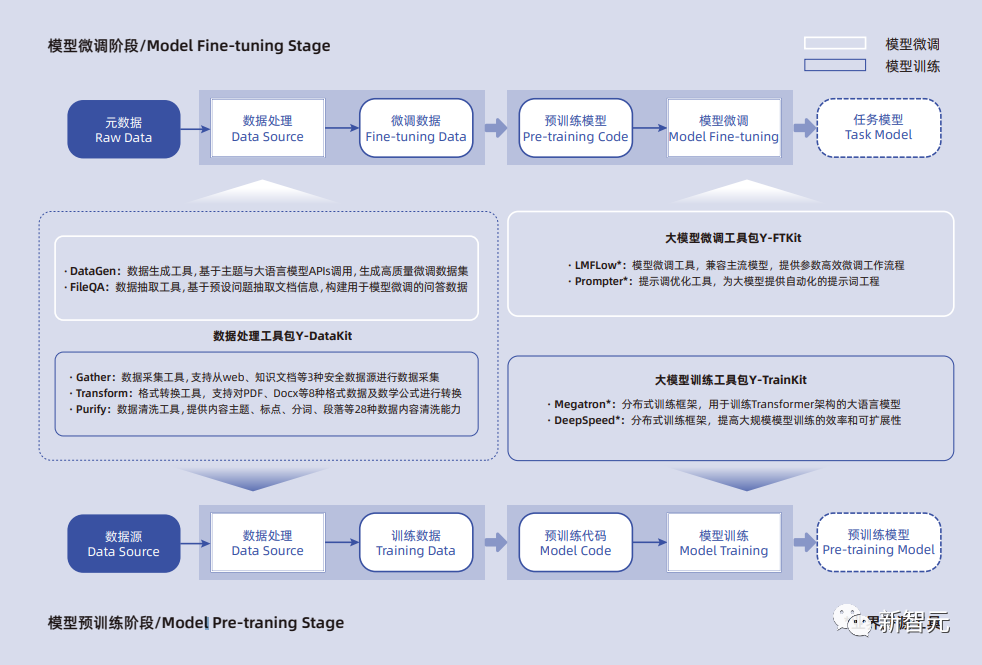
L3层YLink:面向大模型数据治理、预训练、微调的高效工具链。
L4层MModel:提供多模型接入、服务、评测等功能的纳管平台。
大模型掘金的「秘密武器」






评论