
终于有人把监督学习讲明白了
导读:在机器学习的各种方法中,监督学习是迄今为止成果最令人印象深刻的一种。本文介绍监督学习解决像肺炎诊断这类问题的基本原理。
作者:保罗·佩罗塔(Paolo Perrotta)
来源:大数据DT(ID:hzdashuju)

01 什么是监督学习
要进行监督学习,我们需要从一组样本数据开始,每个样本都带有计算机可以学习的标签。例如:

如你所见,样本可以是很多不同的东西:数据、文本、声音、视频等。此外,标签可以是数值,也可以是类型。数值标签只是一个数值,就像温度–柠檬水转换器一样。类型标签表示预先定义的集合中的某个类别,例如在犬种检测器的例子中。
使用一些想象力,你可以想出很多其他例子来预测一些事物,根据数值或者类型的标签来预测其他事物。
我们假设已经收集了一些标记过的样本。现在可以进行监督学习的两个阶段:
阶段1:训练阶段
我们将带有标签的样本提供给一个用于发现模式的算法。例如,该算法可能会注意到,所有的肺炎扫描图片都具有某些共同的特征(可能是某些不透明的区域),而这些特征在非肺炎扫描图片中是没有的。这个阶段称为训练阶段,因为算法会一遍又一遍地观看样本数据,并学习识别这些模式。
阶段2:预测阶段
现在算法已经知道了肺炎的样子,于是切换到预测阶段。我们可以在这个阶段收获训练工作的成果。向训练过的算法展示未被标注的X光扫描图片,算法会告诉我们它是否具有肺炎特征。
这里还有关于监督学习的另一个例子——一种可以识别动物类型的系统。每个输入数据是一张关于某种动物的图片,每个样本的标签是图片中动物的物种。在训练阶段,我们向算法展示带标签的图像。在预测阶段,我们向算法展示一张未被标注的不带标签的图像,要求算法对该图像的标签进行猜测。
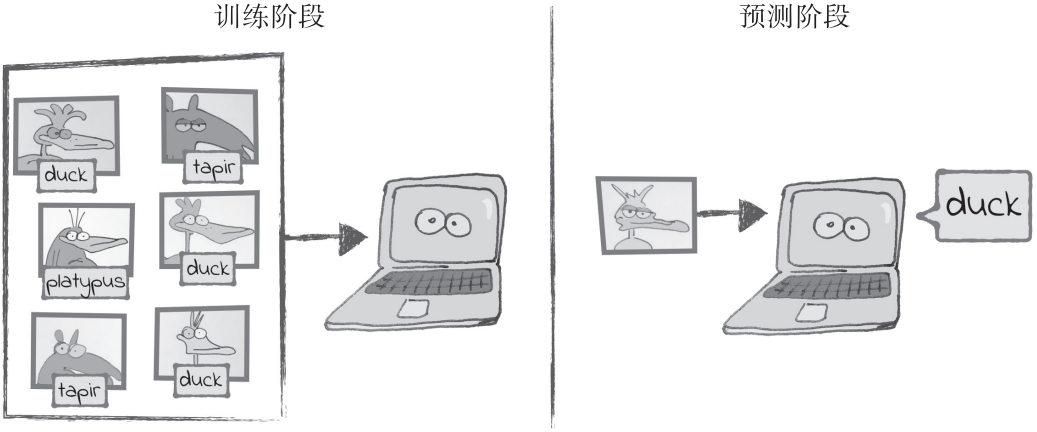
前面已经说过,计算机程序可以在机器学习的过程中“算出”数据。监督学习就是这种过程的一个例子。在传统的编程过程中,可以编写一个程序让计算机由输入算出输出;在监督学习中,只要给出程序输入和输出的样本数据,计算机就能自己学会如何从一个输入算出一个输出。
既然你已经阅读了关于监督学习的一种高屋建瓴的解释,那么可能会有比初学时更多的问题。我们说过,监督学习程序在样本数据中“注意共同的特征”,并“发现模式”—但它是如何做到的呢?让我们从一个抽象的层次开始,看看这个魔法是如何实现的。
02 魔法背后的数学原理
监督学习系统使用函数拟合这一数学概念来理解样本数据与其标签之间的关系。下面我们结合具体实例来介绍这个数学概念的基本原理。
想象一下,你家屋顶上有一块太阳能板。你就像是一个监督学习系统一样,学习太阳能板如何产生能量,并预测在未来某个时间段内产生能量的大小。
预测太阳能板的能量输出需要时间、天气等变量。时间应该是一个重要变量,所以你决定专注于时间这个变量。对于真正的监督学习过程,你应该从收集每天不同时段太阳能板所产生能量大小的样本数据开始。经过几周时间的随机取样之后,你得到了如下数据列表:

上表中的每一行都是包含输入变量(时间)与标签(产生的能量值)的样本数据,就像那个识别动物的系统一样,动物图片是输入,动物名称是标签。
如果你将这些样本数据绘成一幅图表,那么就能很形象地看到时间与太阳能板产能值之间的关系:
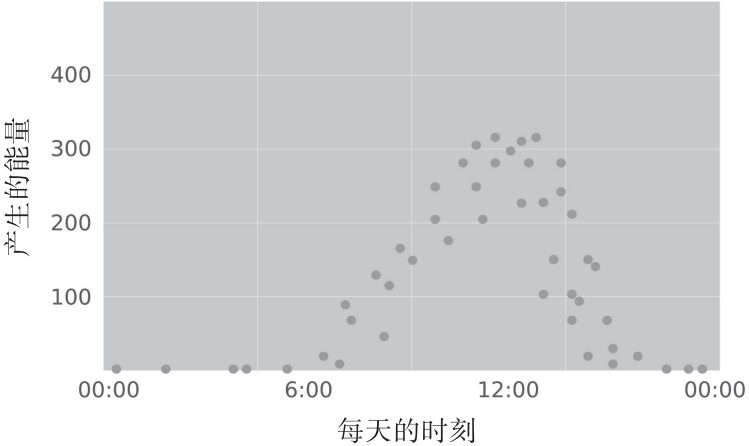
我们一看就知道,太阳能板不会在夜间产生能量,并且能量值在中午的时间达到了顶峰。如下图所示,虽然监督学习系统没有人脑那样机敏,但是它能够将样本数据近似拟合成某个函数,由此实现对数据的理解。
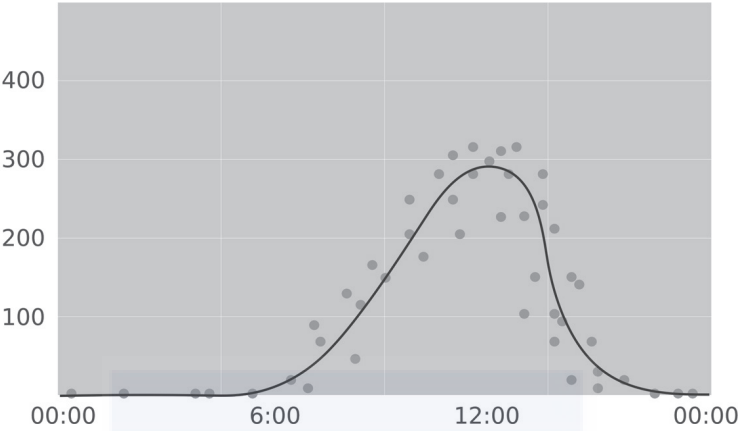
寻找与样本数据比较接近的拟合函数并不是一件容易的事情。但是,随后的预测阶段就要简单得多。系统会忘记所有的样本信息,并使用找到的拟合函数来预测太阳能板在未来某个时间所产生的能量,例如在正午时产生的能量如下图所示:
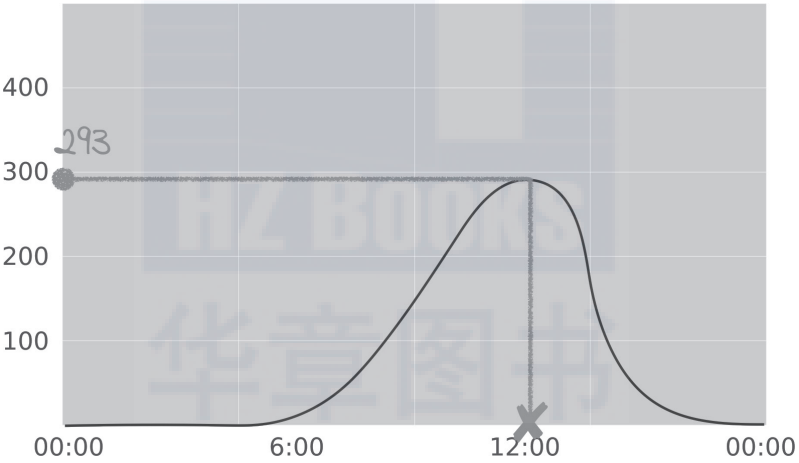
这就是我所说的监督学习通过函数拟合的方式实现算法功能。监督学习系统接收的实际样本数据通常是混乱且不完整的。在数据训练阶段,我们通常需要构造一个比较简单的函数来近似拟合比较复杂的实际数据。在预测阶段,则使用所构造的拟合函数实现对未知数据的预测。
作为一名程序员,你已经习惯于考虑很多有可能出错的情形。因此,你可能已经在考虑将样本数据的处理复杂化的方法。例如,太阳能电池板的能量输出除了与时间有关之外,还会受到其他因素的影响,比如云层或月份的影响。
如果收集了所有这些变量的数据,那么我们将会得到一个多维的点云,将无法使用一个简单的图表对这些点云数据进行可视化表示。同样,对于太阳能电池板,我们需要预测的是数值标签。你可能想知道如何将这种数值标签转换成非数值标签(如动物的名称),即类别标签。
你现在只需要知道一点:不管你在上面叠加了多少复杂的东西,监督学习的基本思想就和我们刚才所描述的一样——找一堆样本数据,再找到一个可以近似拟合这些样本数据的函数。
现代监督学习系统非常擅长这种拟合工作。事实上,这种拟合功能可以强大到足以拟合出极其复杂的函数关系——例如X光扫描图片和诊断结论之间的关系。当然,用于拟合这些对应关系的函数对于我们人类而言会是非常复杂的。然而,对于计算机系统而言则是小菜一碟。
本文摘编自《机器学习编程:从编码到深度学习》,经出版方授权发布。(ISBN:978-7-111-68091-8)

《机器学习编程:从编码到深度学习》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:语言幽默,举例生动,适合零基础读者学习机器学习。适合作为智能科学与技术、数据科学与大数据技术、计算机科学与技术以及相关专业的本科生或研究生的机器学习入门教材,也可供工程技术人员和自学读者学习参考。

划重点👇
干货直达👇
更多精彩👇
在公众号对话框输入以下关键词
查看更多优质内容!
读书 | 书单 | 干货 | 讲明白 | 神操作 | 手把手
大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化
AI | 人工智能 | 机器学习 | 深度学习 | NLP
5G | 中台 | 用户画像 | 数学 | 算法 | 数字孪生
据统计,99%的大咖都关注了这个公众号
👇
评论