
终于有人把监督学习讲明白了
导读:在机器学习的各种方法中,监督学习是迄今为止成果最令人印象深刻的一种。本文介绍监督学习解决像肺炎诊断这类问题的基本原理。


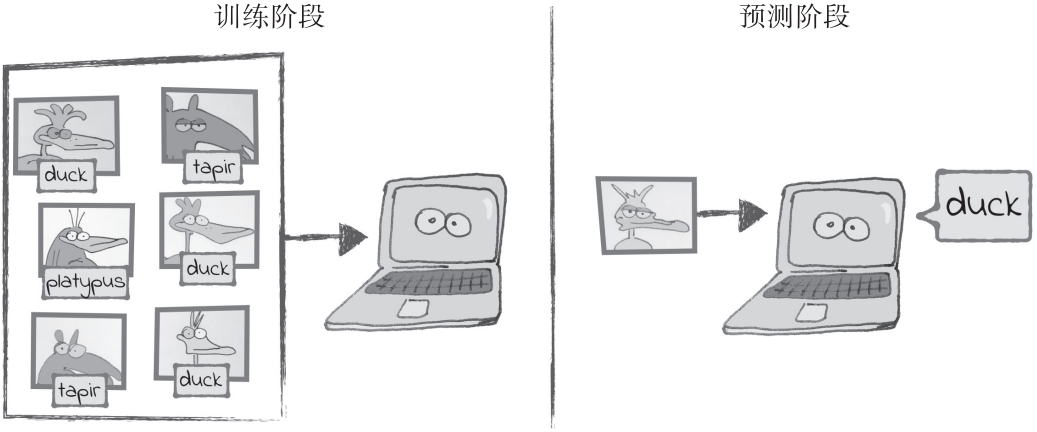
阶段1:训练阶段
阶段2:预测阶段

◆ ◆ ◆ ◆ ◆
麟哥新书已经在当当上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前当当正在举行活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
猜你喜欢 ● 你相信逛B站也能学编程吗
评论