
终于有人把联邦学习讲明白了
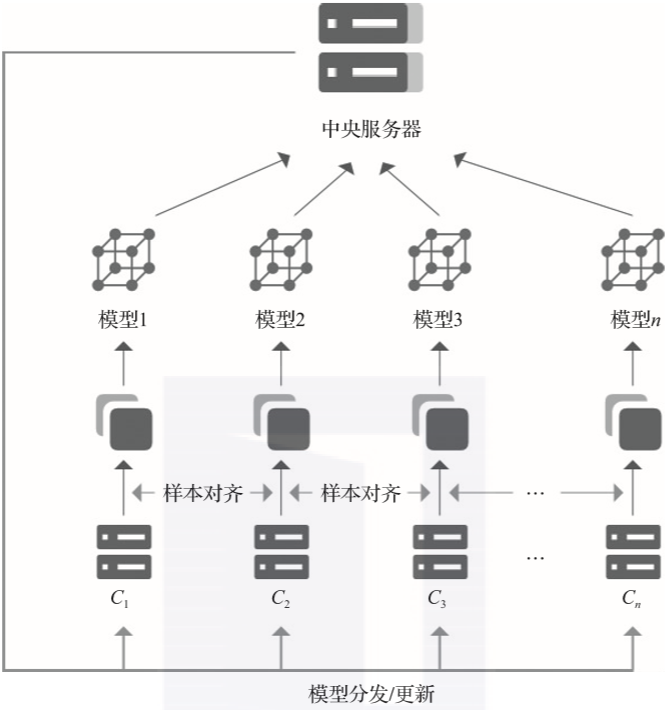
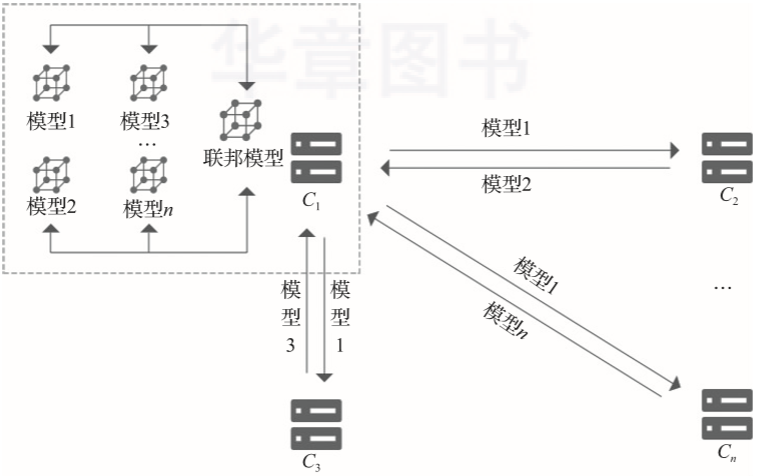
协调方建立基本模型,并将模型的基本结构与参数告知各参与方; 各参与方利用本地数据进行模型训练,并将结果返回给协调方; 协调方汇总各参与方的模型,构建更精准的全局模型,以整体提升模型性能和效果。
针对联合多方用户的联邦学习场景,一般采用的是客户端/服务器架构,企业作为服务器,起着协调全局模型的作用; 而针对联合多家面临数据孤岛困境的企业进行模型训练的场景,一般可以采用对等架构,因为难以从多家企业中选出进行协调的服务器方。
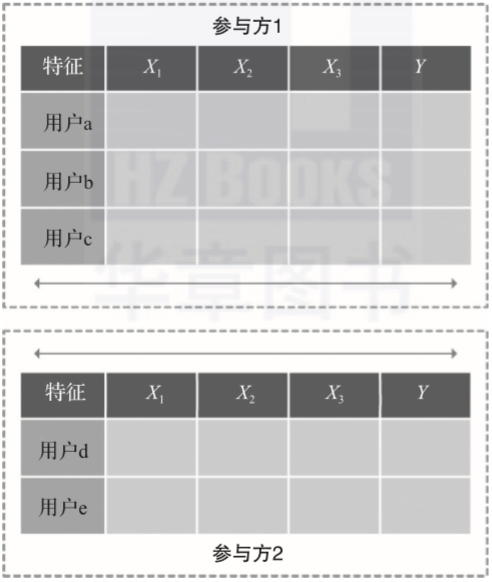
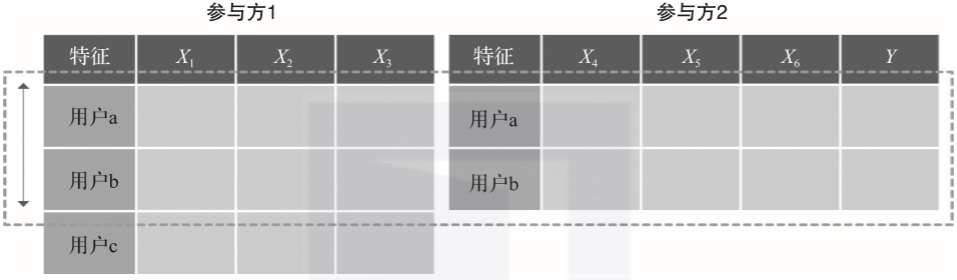
在智慧金融领域中,可以根据多方数据建立更准确的业务模型,从而实现合理定价、定向业务推广、企业风控评定等; 在智慧城市中,实现各政府机构之间、企业与政府之间的联合,实现更准确的实时交通预测,更简化的机关办事步骤,更高效的信息内容查询,更全面的安全防控检测等; 在智慧医疗中,联邦学习可以综合各医院之间的数据,提高医疗影像诊断的准确性,预警病人的身体情况等。
(欢迎大家加入数据工匠知识星球获取更多资讯。)

扫描二维码关注我们

我们的使命:发展数据治理行业、普及数据治理知识、改变企业数据管理现状、提高企业数据质量、推动企业走进大数据时代。
我们的愿景:打造数据治理专家、数据治理平台、数据治理生态圈。
我们的价值观:凝聚行业力量、打造数据治理全链条平台、改变数据治理生态圈。
了解更多精彩内容
长按,识别二维码,关注我们吧!
数据工匠俱乐部
微信号:zgsjgjjlb
专注数据治理,推动大数据发展。
评论