
(附代码)总结 | 卷积网络压缩方法
点击左上方蓝字关注我们

链接 | https://www.zhihu.com/people/tang-fen-44-49
01
一般地,行阶梯型矩阵的秩等于其“台阶数”-非零行的行数。
 ,若能将其表示为若干个低秩矩阵的组合,即
,若能将其表示为若干个低秩矩阵的组合,即  , 其中
, 其中  为低秩矩阵,其秩为
为低秩矩阵,其秩为  , 并满足
, 并满足  ,则其每一个低秩矩阵都可分解为小规模矩阵的乘积,
,则其每一个低秩矩阵都可分解为小规模矩阵的乘积,  ,其中
,其中  ,
,  。当 取值很小时,便能大幅降低总体的存储和计算开销。
。当 取值很小时,便能大幅降低总体的存储和计算开销。1.1,总结
02
2.1,总结
03
,首先将其转化为向量形式:  。之后对该权重向量的元素进行
。之后对该权重向量的元素进行  个簇的聚类,这可借助于经典的 k-均值(k-means)聚类算法快速完成:
个簇的聚类,这可借助于经典的 k-均值(k-means)聚类算法快速完成: 个聚类中心(
个聚类中心(  ,标量)存储在码本中,而原权重矩阵则只负责记录各自聚类中心在码本中索引。如果不考虑码本的存储开销,该算法能将存储空间减少为原来的
,标量)存储在码本中,而原权重矩阵则只负责记录各自聚类中心在码本中索引。如果不考虑码本的存储开销,该算法能将存储空间减少为原来的  。基于 均值算法的标量量化在很多应用中非常有效。参数量化与码本微调过程图如下:
。基于 均值算法的标量量化在很多应用中非常有效。参数量化与码本微调过程图如下: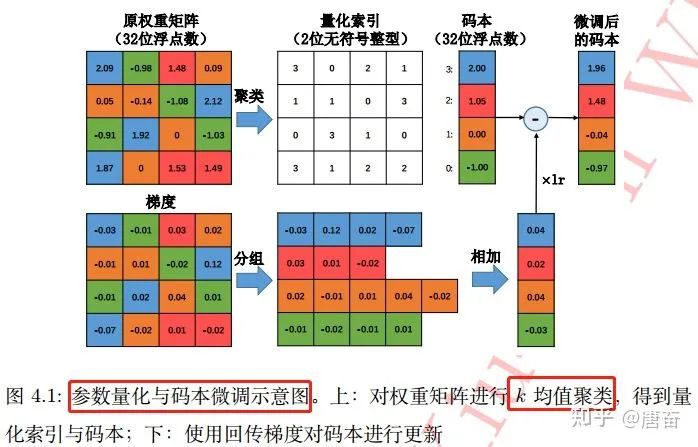
3.1,总结
04
def residual_unit(data, num_filter, stride, dim_match, num_bits=1):"""残差块 Residual Block 定义"""bnAct1 = bnn.BatchNorm(data=data, num_bits=num_bits)conv1 = bnn.Convolution(data=bnAct1, num_filter=num_filter, kernel=(3, 3), stride=stride, pad=(1, 1))convBn1 = bnn.BatchNorm(data=conv1, num_bits=num_bits)conv2 = bnn.Convolution(data=convBn1, num_filter=num_filter, kernel=(3, 3), stride=(1, 1), pad=(1, 1))if dim_match:shortcut = dataelse:shortcut = bnn.Convolution(data=bnAct1, num_filter=num_filter, kernel=(3, 3), stride=stride, pad=(1, 1))return conv2 + shortcut
4.1,二值网络的梯度下降
利用决定化方式(sign(x)函数)把 Weight 量化为 +1/-1, 以0为阈值 利用量化后的 Weight (只有+1/-1)来计算前向传播,由二值权重与输入进行卷积运算(实际上只涉及加法),获得卷积层输出。 反向传播 Backward Pass: 把梯度更新到浮点的 Weight 上(根据放松后的符号函数,计算相应梯度值,并根据该梯度的值对单精度的权重进行参数更新) 训练结束:把 Weight 永久性转化为 +1/-1, 以便 inference 使用
4.2,两个问题
直接根据权重的正负进行二值化:
 。符号函数 sign(x) 定义如下:
。符号函数 sign(x) 定义如下:

进行随机的二值化,即对每一个权重,以一定概率取  。
。
 来代替
来代替  。当 x 在区间 [-1,1] 时,存在梯度值 1,否则梯度为 0 。
。当 x 在区间 [-1,1] 时,存在梯度值 1,否则梯度为 0 。4.3,二值连接算法改进

 为该层的输入张量,
为该层的输入张量,  为该层的一个滤波器,
为该层的一个滤波器,  为该滤波器所对应的二值权重。
为该滤波器所对应的二值权重。 来对二值滤波器卷积后的结果进行放缩。而
来对二值滤波器卷积后的结果进行放缩。而  的取值,则可根据优化目标:
的取值,则可根据优化目标: 得到
得到  。二值连接改进的算法训练过程与之前的算法大致相同,不同的地方在于梯度的计算过程还考虑了 的影响。由于 这个单精度的缩放因子的存在,有效降低了重构误差,并首次在 ImageNet 数据集上取得了与 Alex-Net 相当的精度。如下图所示:
。二值连接改进的算法训练过程与之前的算法大致相同,不同的地方在于梯度的计算过程还考虑了 的影响。由于 这个单精度的缩放因子的存在,有效降低了重构误差,并首次在 ImageNet 数据集上取得了与 Alex-Net 相当的精度。如下图所示: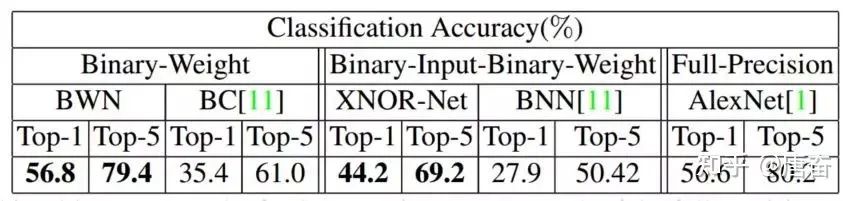
4.4,二值网络设计注意事项
不要使用 kernel = (1, 1) 的 Convolution (包括 resnet 的 bottleneck):二值网络中的 weight 都为 1bit, 如果再是 1x1 大小, 会极大地降低表达能力 增大 Channel 数目 + 增大 activation bit 数 要协同配合:如果一味增大 channel 数, 最终 feature map 因为 bit 数过低, 还是浪费了模型容量。同理反过来也是。 建议使用 4bit 及以下的 activation bit, 过高带来的精度收益变小, 而会显著提高 inference 计算量
05
本文只简单介绍这个领域的开篇之作-Distilling the Knowledge in a Neural Network,这是蒸 "logits"方法,后面还出现了蒸 "features" 的论文。想要更深入理解,中文博客可参考这篇文章-知识蒸馏是什么?一份入门随笔(https://zhuanlan.zhihu.com/p/90049906)。
知识蒸馏(knowledge distillation)(https://arxiv.org/abs/1503.02531),是迁移学习(transfer learning)的一种,简单来说就是训练一个大模型(teacher)和一个小模型(student),将庞大而复杂的大模型学习到的知识,通过一定技术手段迁移到精简的小模型上,从而使小模型能够获得与大模型相近的性能。
在知识蒸馏的实验中,我们先训练好一个 teacher 网络,然后将 teacher 的网络的输出结果  作为 student 网络的目标,训练 student 网络,使得 student 网络的结果
作为 student 网络的目标,训练 student 网络,使得 student 网络的结果  接近 ,因此,student 网络的损失函数为
接近 ,因此,student 网络的损失函数为  。这里 CE 是交叉熵(Cross Entropy),
。这里 CE 是交叉熵(Cross Entropy),  是真实标签的 onehot 编码, 是 teacher 网络的输出结果, 是 student 网络的输出结果。
是真实标签的 onehot 编码, 是 teacher 网络的输出结果, 是 student 网络的输出结果。
但是,直接使用 teacher 网络的 softmax 的输出结果 q,可能不大合适。因此,一个网络训练好之后,对于正确的答案会有一个很高的置信度。例如,在 MNIST 数据中,对于某个 2 的输入,对于 2 的预测概率会很高,而对于 2 类似的数字,例如 3 和 7 的预测概率为 10−6 和 10−9。这样的话,teacher 网络学到数据的相似信息(例如数字 2 和 3,7 很类似)很难传达给 student 网络,因为它们的概率值接近0。因此,论文提出了 softmax-T(软标签计算公式)公式,如下所示:

这里  是 student 网络学习的对象(soft targets),
是 student 网络学习的对象(soft targets), 是 teacher 网络 softmax 前一层的输出 logit。如果将
是 teacher 网络 softmax 前一层的输出 logit。如果将  取 1,上述公式变成 softmax,根据 logit 输出各个类别的概率。如果 接近于 0,则最大的值会越近 1,其它值会接近 0,近似于 onehot 编码。
取 1,上述公式变成 softmax,根据 logit 输出各个类别的概率。如果 接近于 0,则最大的值会越近 1,其它值会接近 0,近似于 onehot 编码。
所以,可以知道 student 模型最终的损失函数由两部分组成:
第一项是由小模型(student 模型)的预测结果与大模型的“软标签”所构成的交叉熵(cross entroy);
第二项为小模型预测结果与普通类别标签的交叉熵。
这两个损失函数的重要程度可通过一定的权重进行调节,在实际应用中, T 的取值会影响最终的结果,一般而言,较大的 T 能够获得较高的准确度,T(蒸馏温度参数) 属于知识蒸馏模型训练超参数的一种。T 是一个可调节的超参数、T 值越大、概率分布越软(论文中的描述),曲线便越平滑,相当于在迁移学习的过程中添加了扰动,从而使得学生网络在借鉴学习的时候更有效、泛化能力更强,这其实就是一种抑制过拟合的策略。知识蒸馏的整个过程如下图:
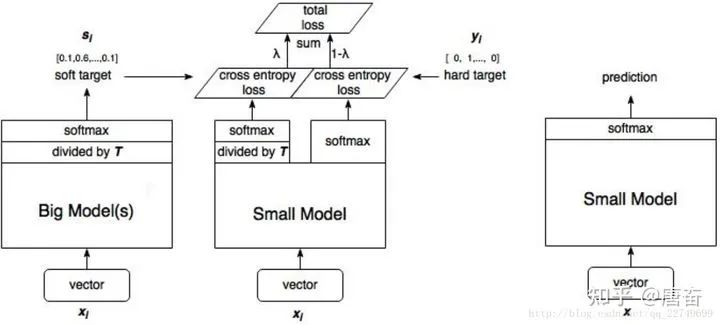
student 模型的实际模型结构和小模型一样,但是损失函数包含了两部分,分类网络的知识蒸馏 mxnet 代码示例如下:
# -*-coding-*- : utf-8"""本程序没有给出具体的模型结构代码,主要给出了知识蒸馏 softmax 损失计算部分。"""import mxnet as mxdef get_symbol(data, class_labels, resnet_layer_num,Temperature,mimic_weight,num_classes=2):backbone = StudentBackbone(data) # Backbone 为分类网络 backbone 类flatten = mx.symbol.Flatten(data=conv1, name="flatten")fc_class_score_s = mx.symbol.FullyConnected(data=flatten, num_hidden=num_classes, name='fc_class_score')softmax1 = mx.symbol.SoftmaxOutput(data=fc_class_score_s, label=class_labels, name='softmax_hard')import symbol_resnet # Teacher modelfc_class_score_t = symbol_resnet.get_symbol(net_depth=resnet_layer_num, num_class=num_classes, data=data)s_input_for_softmax=fc_class_score_s/Temperaturet_input_for_softmax=fc_class_score_t/Temperaturet_soft_labels=mx.symbol.softmax(t_input_for_softmax, name='teacher_soft_labels')softmax2 = mx.symbol.SoftmaxOutput(data=s_input_for_softmax, label=t_soft_labels, name='softmax_soft',grad_scale=mimic_weight)group=mx.symbol.Group([softmax1,softmax2])group.save('group2-symbol.json')return group
tensorflow代码示例如下:
# 将类别标签进行one-hot编码one_hot = tf.one_hot(y, n_classes,1.0,0.0) # n_classes为类别总数, n为类别标签# one_hot = tf.cast(one_hot_int, tf.float32)teacher_tau = tf.scalar_mul(1.0/args.tau, teacher) # teacher为teacher模型直接输出张量, tau为温度系数Tstudent_tau = tf.scalar_mul(1.0/args.tau, student) # 将模型直接输出logits张量student处于温度系数Tobjective1 = tf.nn.sigmoid_cross_entropy_with_logits(student_tau, one_hot)objective2 = tf.scalar_mul(0.5, tf.square(student_tau-teacher_tau))"""student模型最终的损失函数由两部分组成:第一项是由小模型的预测结果与大模型的“软标签”所构成的交叉熵(cross entroy);第二项为预测结果与普通类别标签的交叉熵。"""tf_loss = (args.lamda*tf.reduce_sum(objective1) + (1-args.lamda)*tf.reduce_sum(objective2))/batch_size
tf.scalar_mul 函数为对 tf 张量进行固定倍率 scalar 缩放函数。一般 T 的取值在 1 - 20 之间,这里我参考了开源代码,取值为 3。我发现在开源代码中 student 模型的训练,有些是和 teacher 模型一起训练的,有些是 teacher 模型训练好后直接指导 student 模型训练。
06
参考资料
1. https://www.cnblogs.com/dyl222/p/11079489.html
2.https://github.com/chengshengchan/model_compression/blob/master/teacher-student.py
3. https://github.com/dkozlov/awesome-knowledge-distillation
4. https://arxiv.org/abs/1603.05279
5. 解析卷积神经网络-深度学习实践手册
6. https://zhuanlan.zhihu.com/p/81467832
END