
英伟达首席科学家Bill Dally解读“黄氏定律”:替代摩尔定律,定义AI时代?

新智元报道
新智元报道
来源:NVIDIA
编辑:Q,LQ
【新智元导读】英伟达将于12月15日-19日召开GTC中国线上大会,今日的主题演讲由英伟达首席科学家BillDally分享关于AI、计算机图形学、高性能计算、医疗、边缘计算、机器人等领域最前沿的创新以及AI推理、GPU集群加速等最新的研究成果。

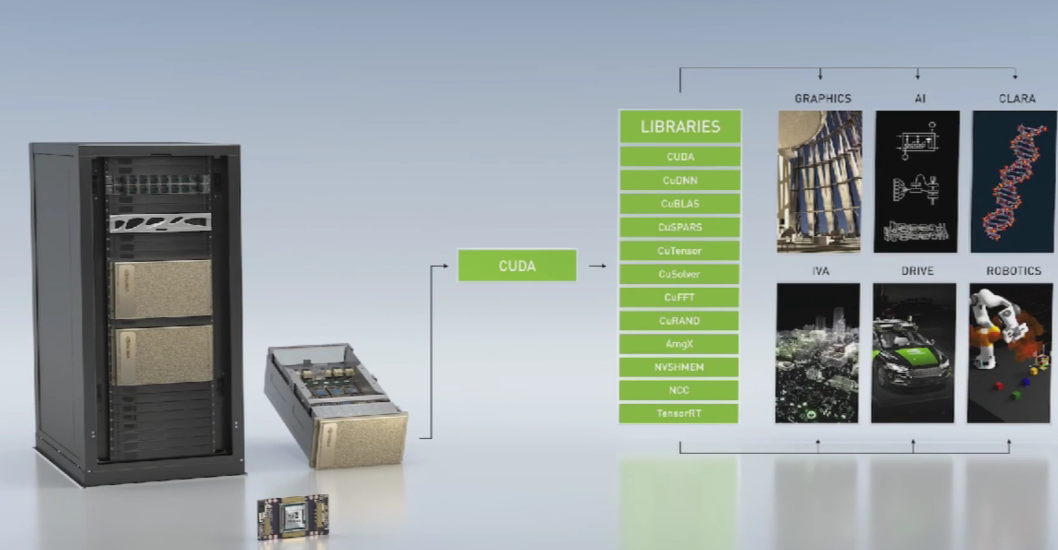
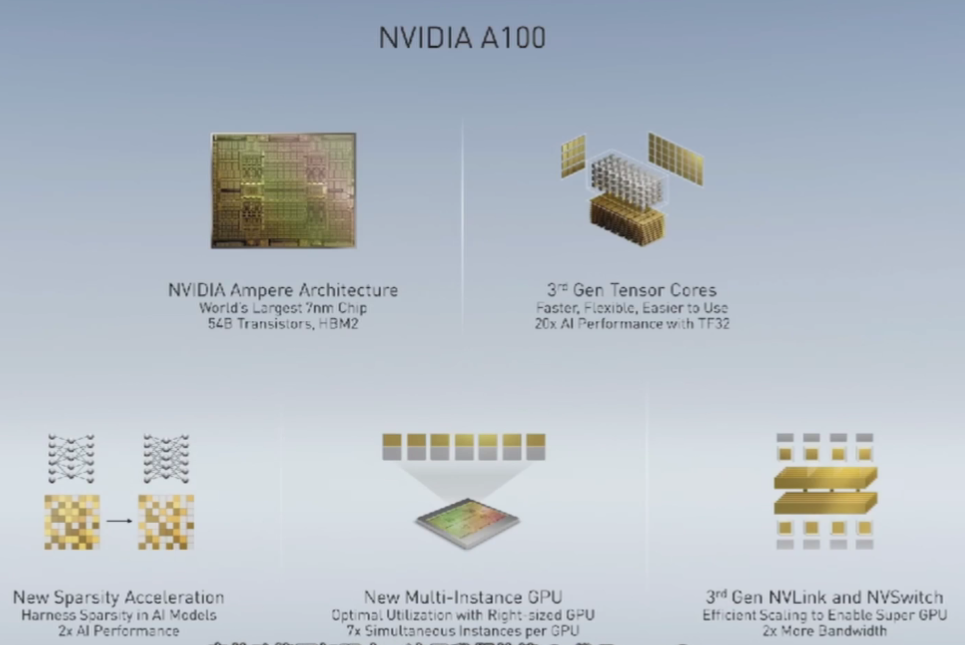
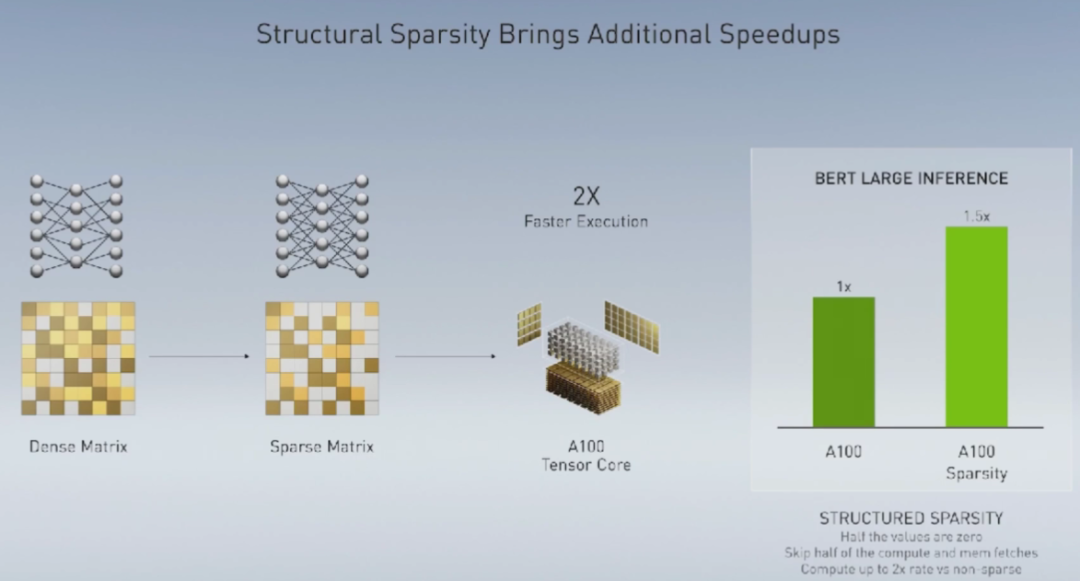
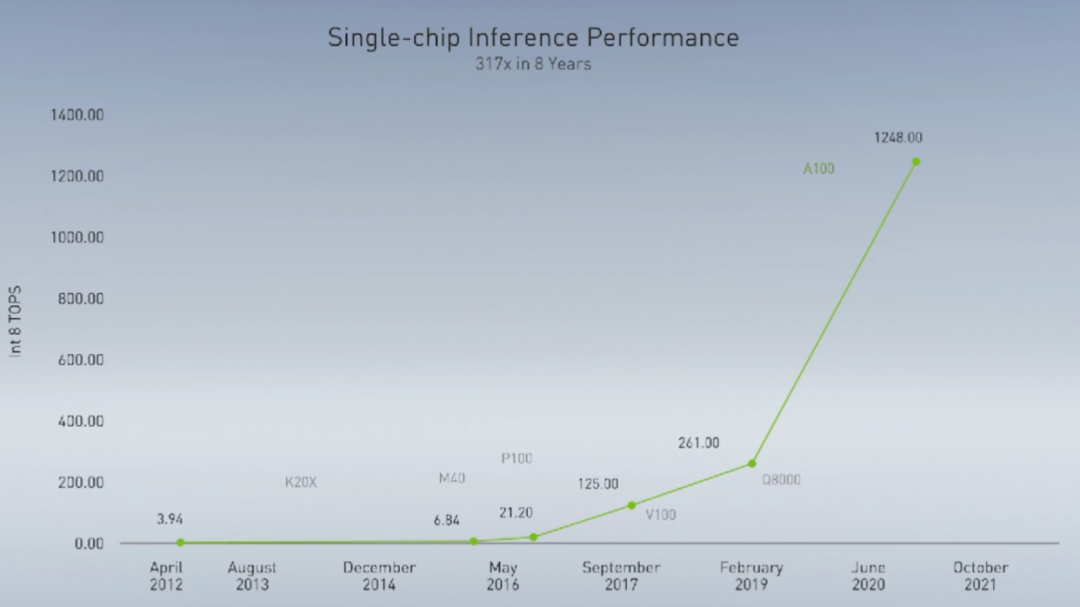
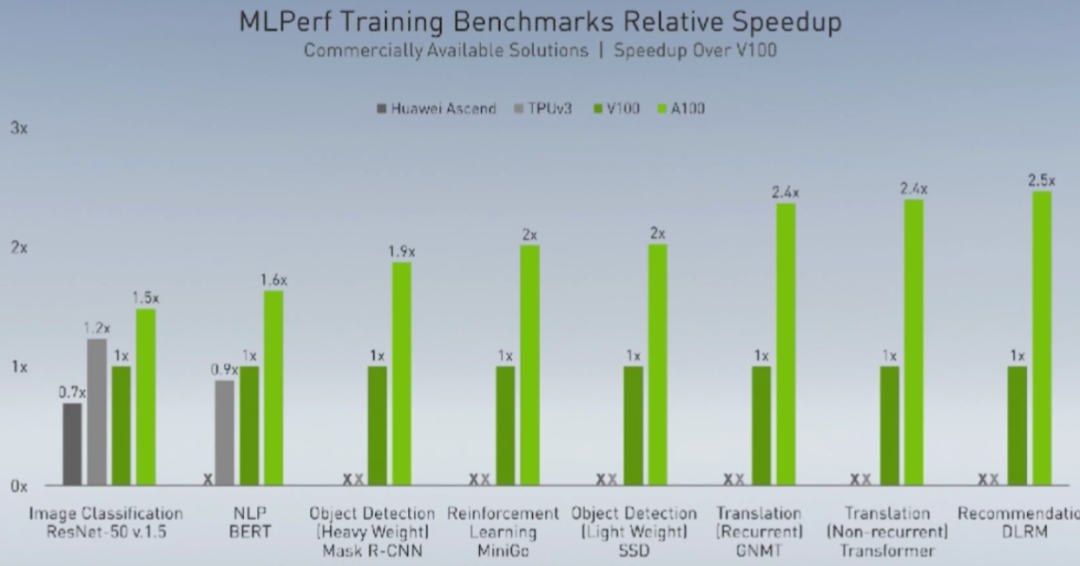
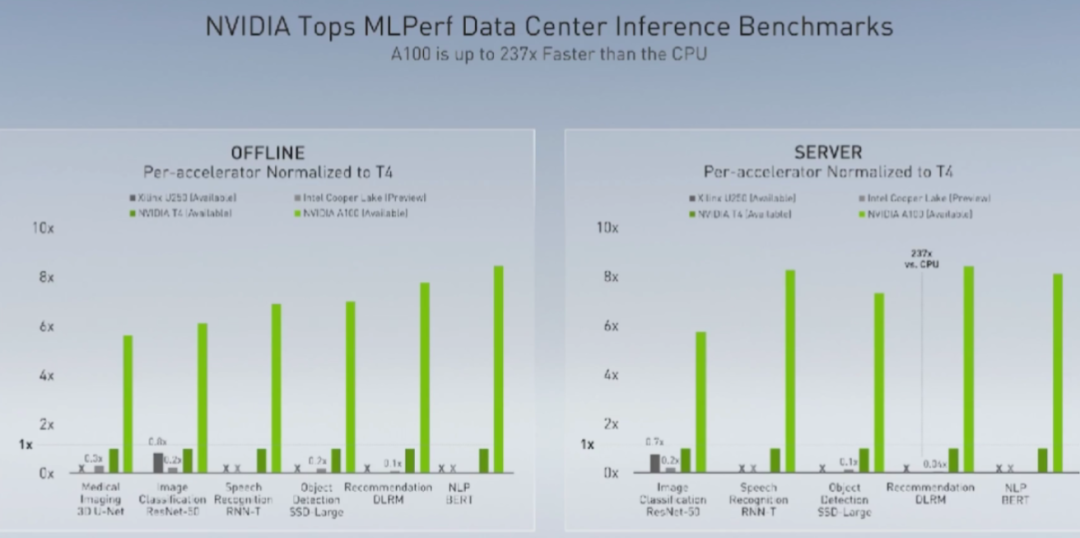
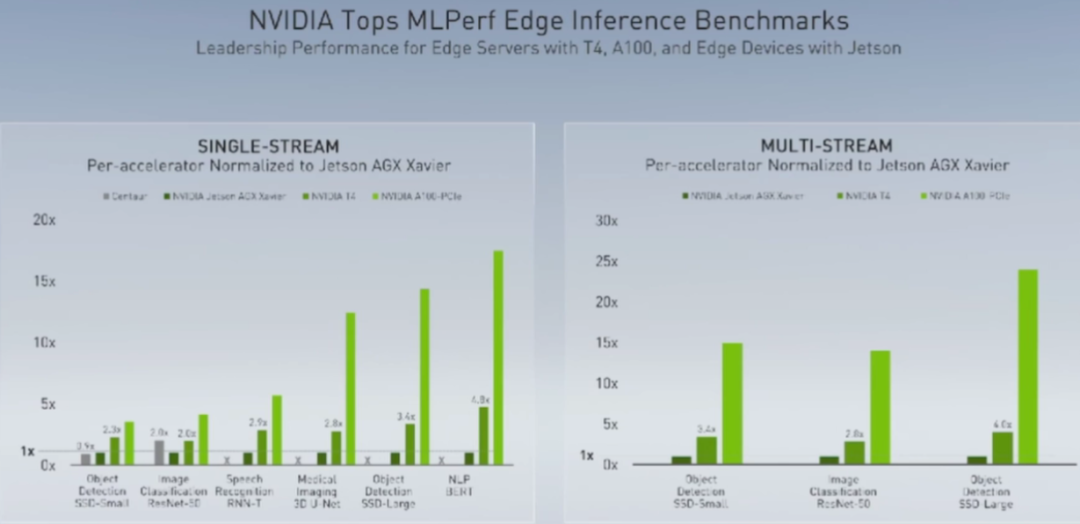
关于Ampere架构、A100和黄氏法则的一切




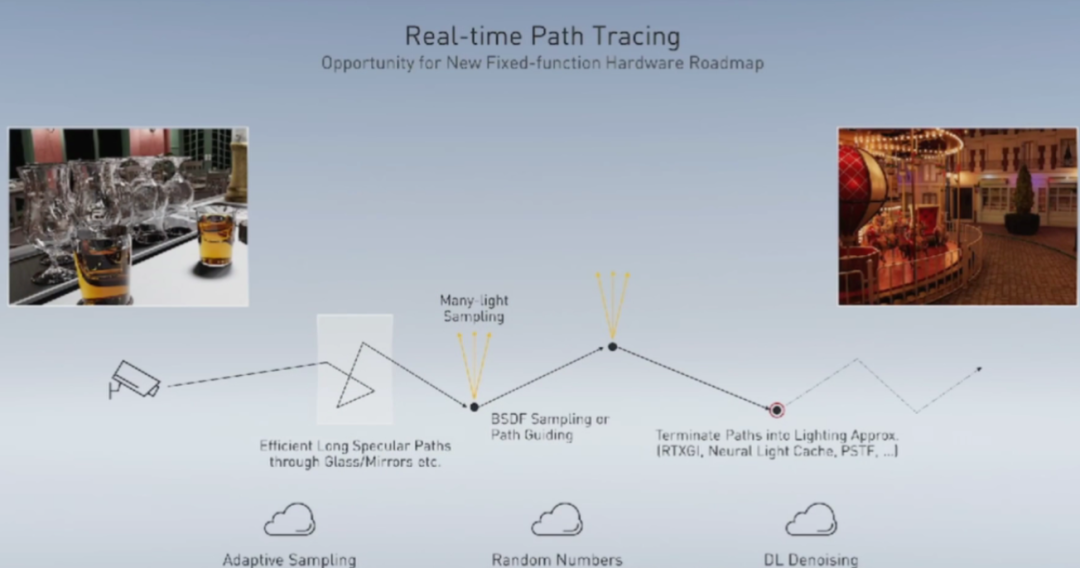
从RTXDI到光线追踪,英伟达改变的不只是游戏




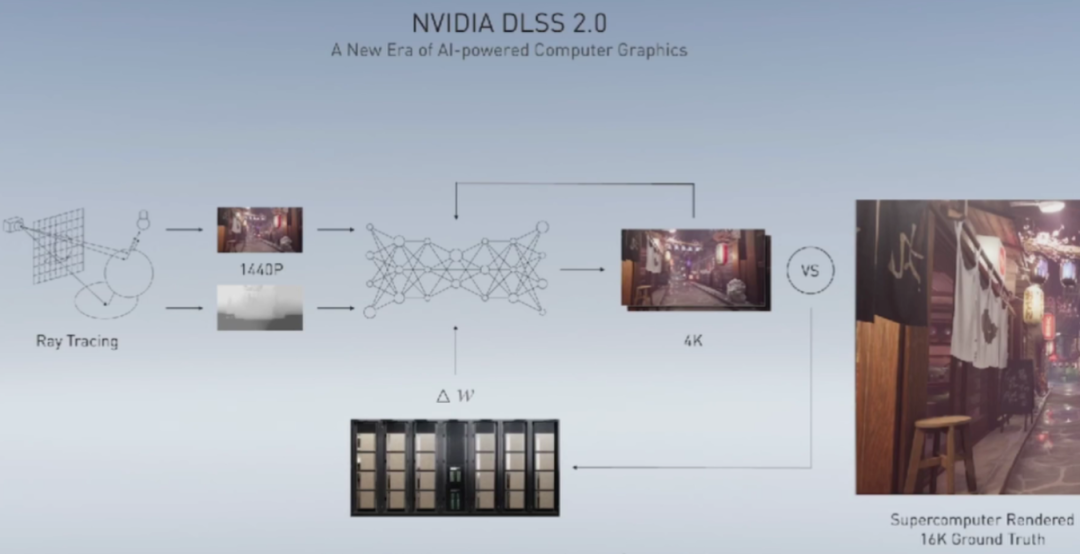


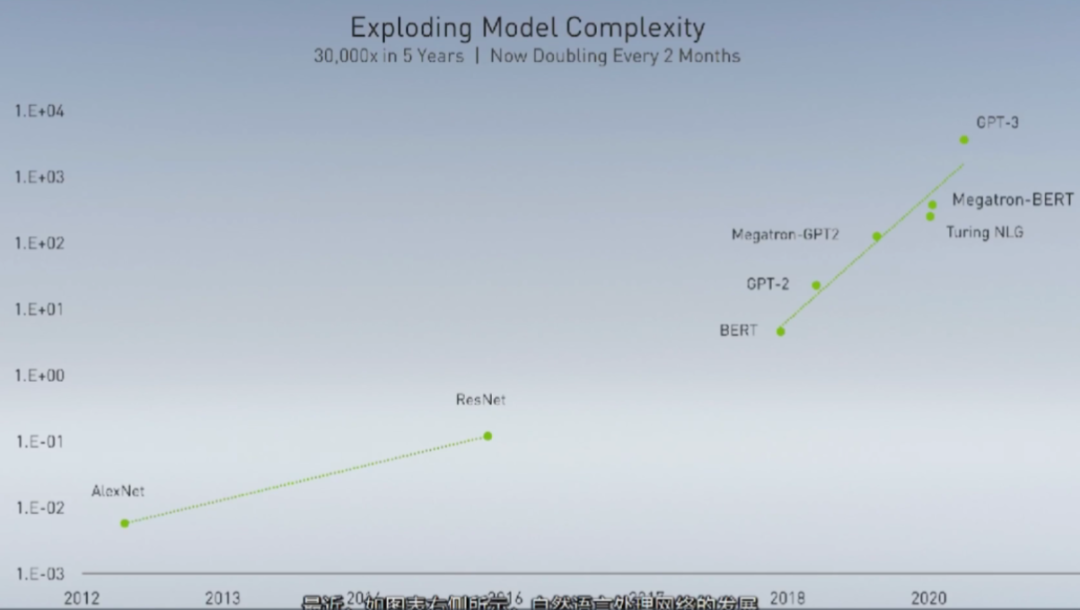
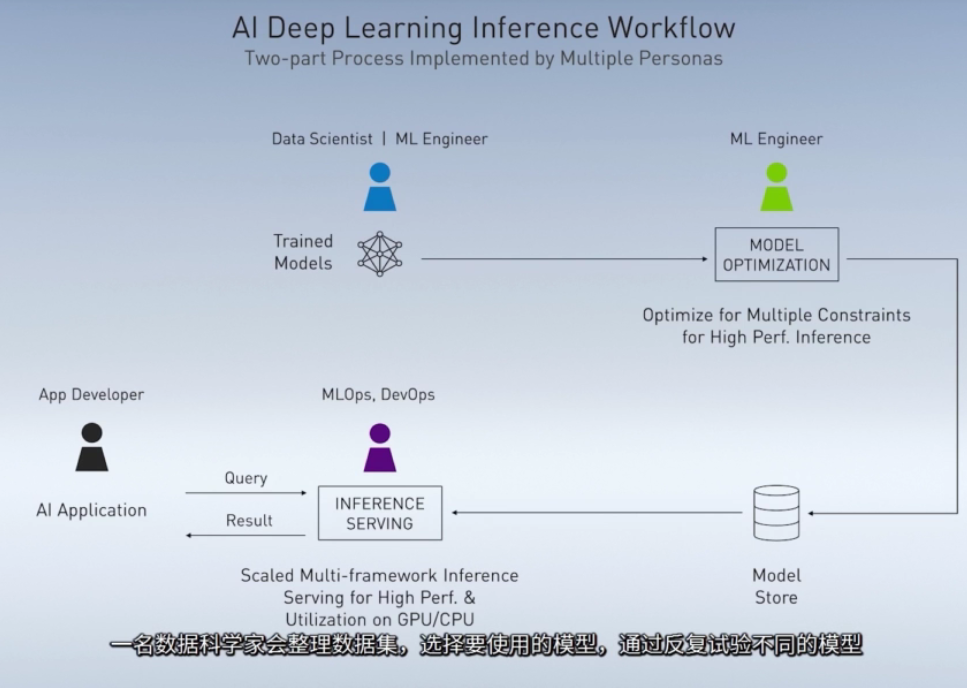
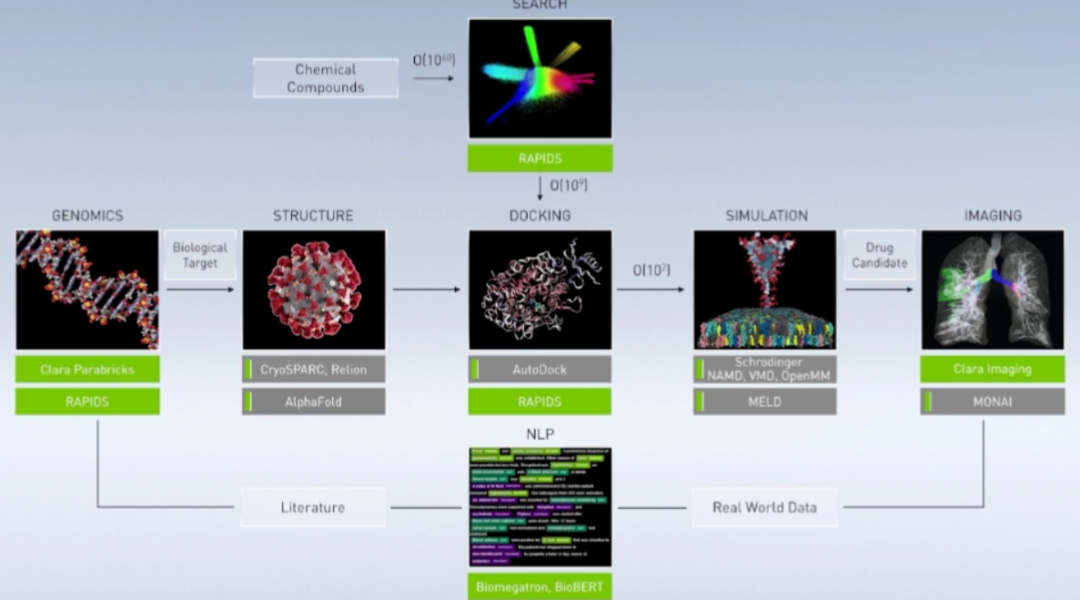
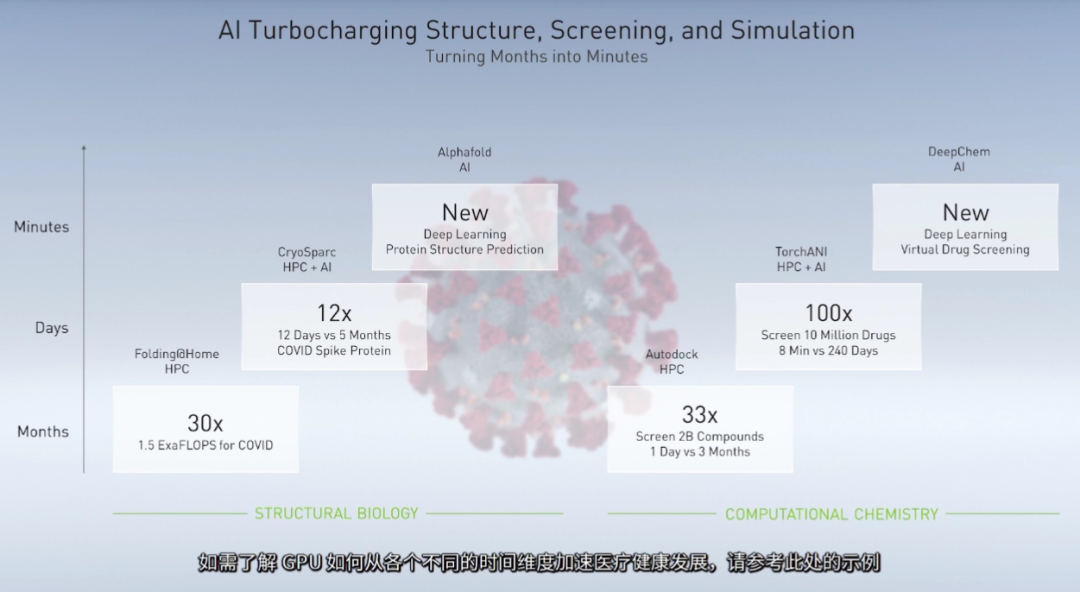
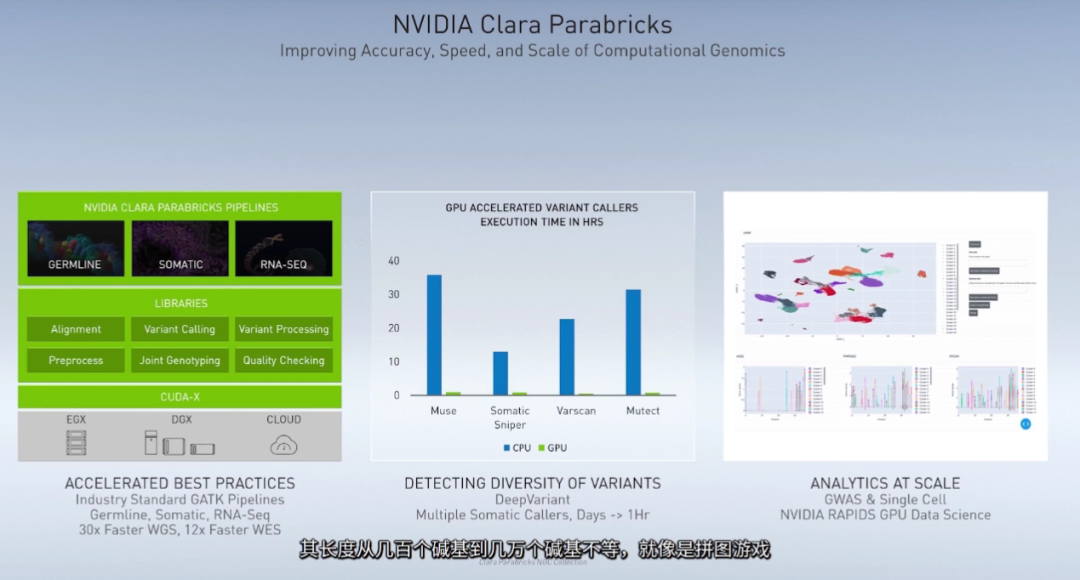
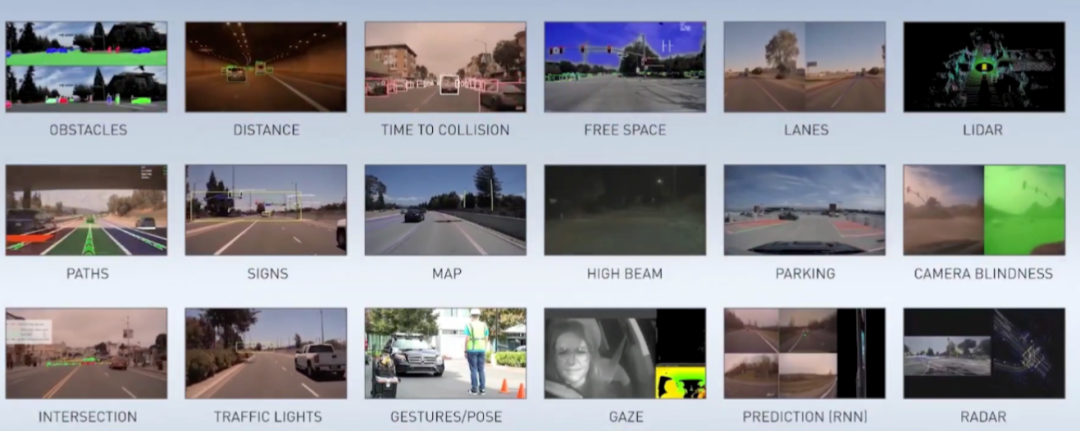
图像的未来看AI,未来的人类生活也看AI





评论