
缩小规模,OpenAI文本生成图像新模型GLIDE用35亿参数媲美DALL-E
模型的参数规模并不需要那么大。





论文地址:https://arxiv.org/pdf/2112.10741.pdf
项目地址:https://github.com/openai/glide-text2im
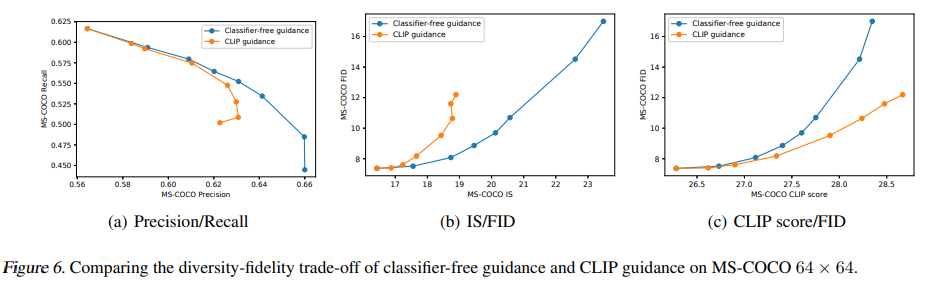
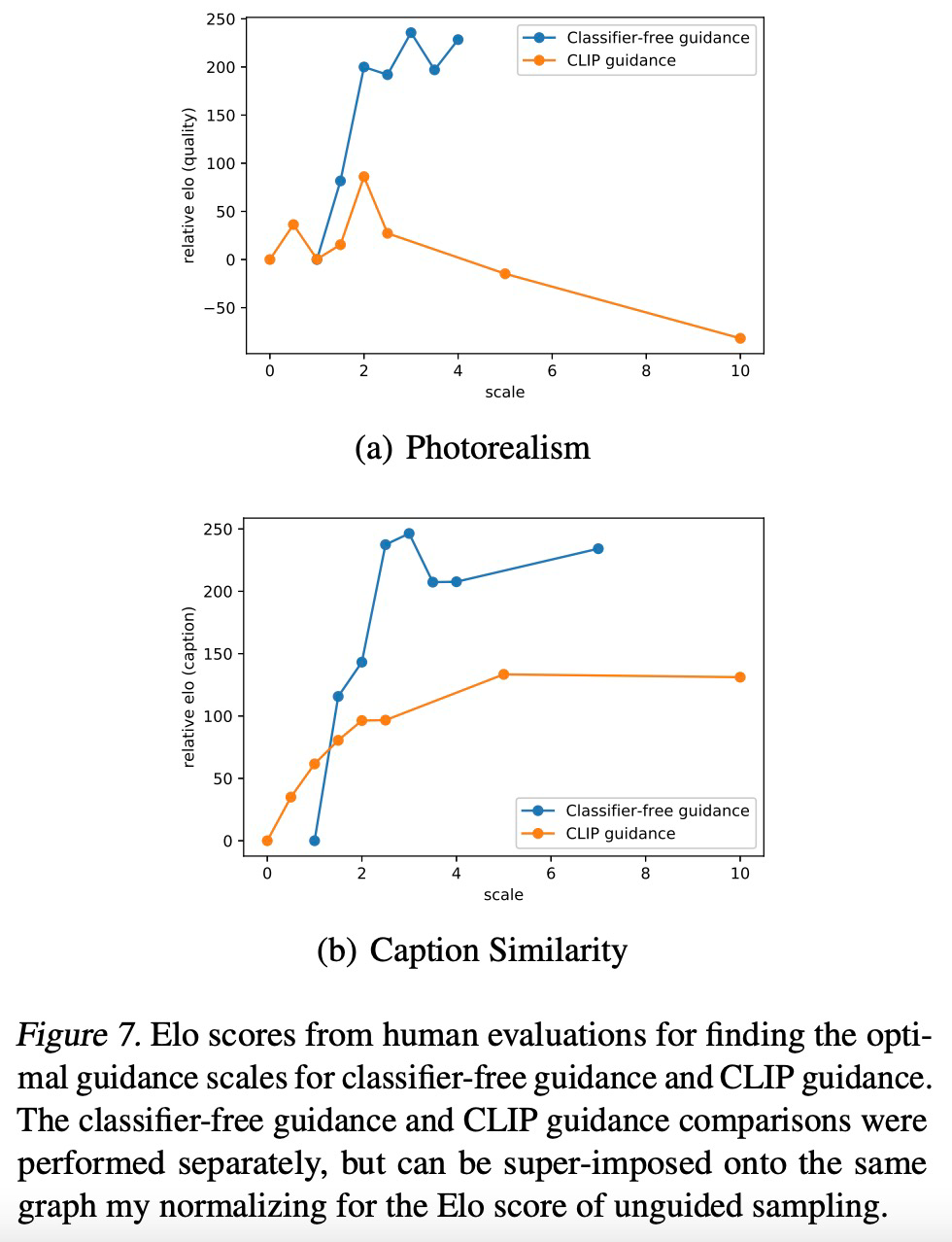
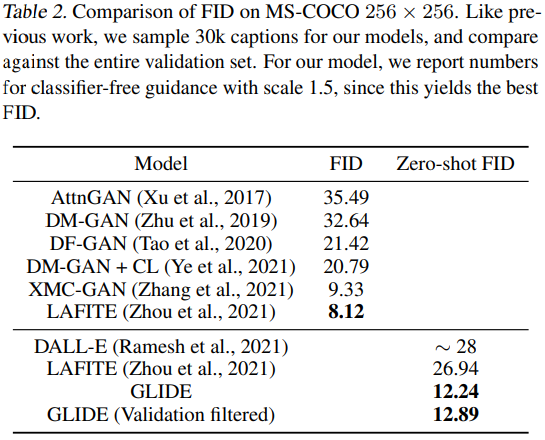
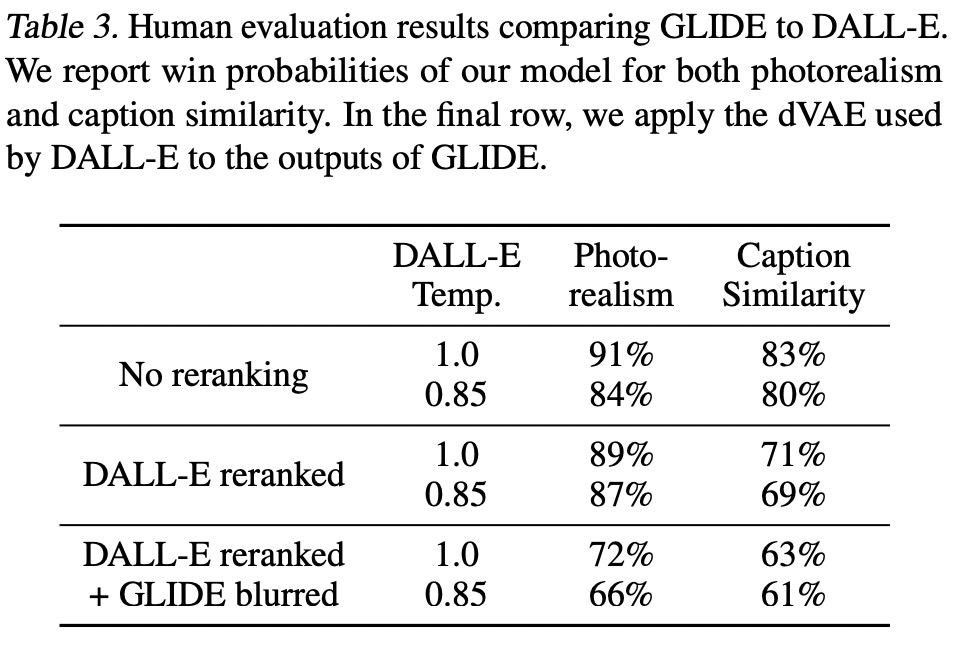
首先,使用最终的 token 嵌入代替 ADM 模型中的类嵌入;
其次,最后一层的 token 嵌入(K 个特征向量序列)分别投影到 ADM 模型中每个注意力层,然后连接到每一层的注意力上下文。


© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论