
多模态图像版「GPT-3」来了!OpenAI推出DALL-E模型,一句话即可生成对应图像

新智元报道
新智元报道
来源:OpenAI
编辑:Q、小匀
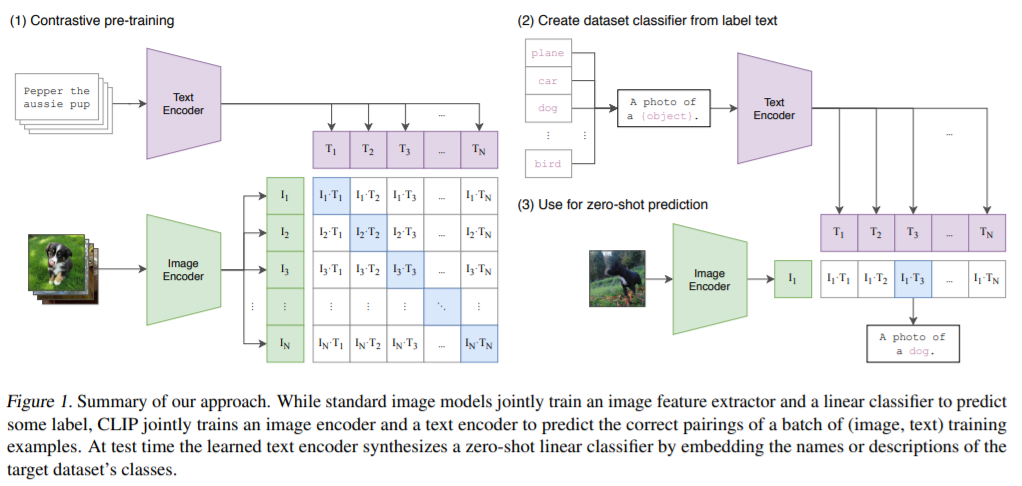
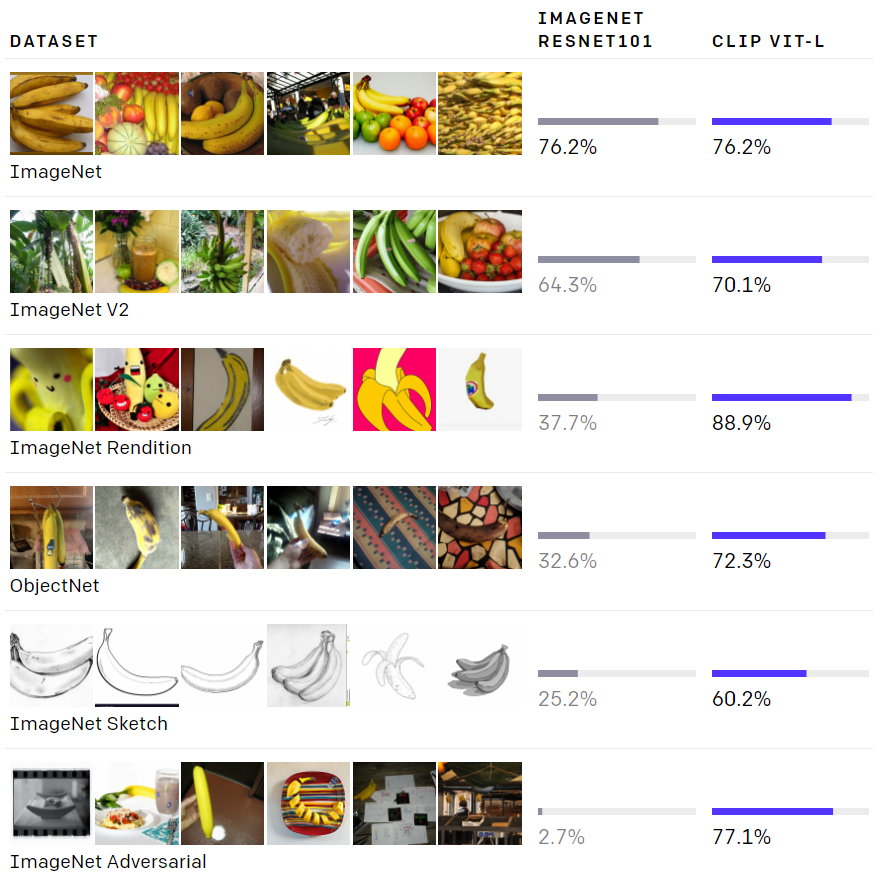
【新智元导读】OpenAI又放大招了!今天,其博客宣布,推出了两个结合计算机视觉和NLP结合的多模态模型:DALL-E和CLIP,它们可以通过文本,直接生成对应图像,堪称图像版「GPT-3」。









DALL-E和CLIP等类似的一系列生成模型,都具有模拟或扭曲现实来预测人们如何绘制风景和静物艺术的能力。比如StyleGAN,就表现出了种族偏见的倾向。
而从事CLIP和DALL-E的OpenAI研究人员呼吁对这两个系统的潜在社会影响进行更多的研究。GPT-3显示出显著的黑人偏见,因此同样的缺点也可存在于DALL-E中。在CLIP论文中包含的偏见测试发现,该模型最有可能将20岁以下的人错误地归类为罪犯或非人类,被归类为男性的人相比女性更有可能被贴上罪犯的标签,这表明数据集中包含的一些标签数据存在严重的性别差异。
参考链接:
https://openai.com/blog/dall-e/


评论