
DETR忆往昔 | 全面回顾DETR目标检测的预训练方法,让DETR训练起来更加丝滑
点击下方卡片,关注「集智书童」公众号

受到DETR基于方法在COCO检测和分割基准上取得新纪录的激励,最近的许多努力都表现出对如何通过自监督方式预训练Transformer并保持Backbone网络不变以进一步改进DETR方法的兴趣增加。一些研究已经声称在准确性方面取得了显著的改进。
在本文中,作者对他们的实验方法进行了更详细的研究,并检查他们的方法在最近的H-Deformable-DETR等最先进模型上是否仍然有效。作者对COCO目标检测任务进行了全面的实验,研究了预训练数据集的选择、定位和分类目标生成方案的影响。
不幸的是,作者发现之前代表性的自监督方法,如DETReg,在完整的数据范围上未能提升强大的基于DETR的方法的性能。作者进一步分析了原因,并发现仅仅将更准确的边界框预测器与Objects365基准相结合,就可以显著提高后续实验的结果。
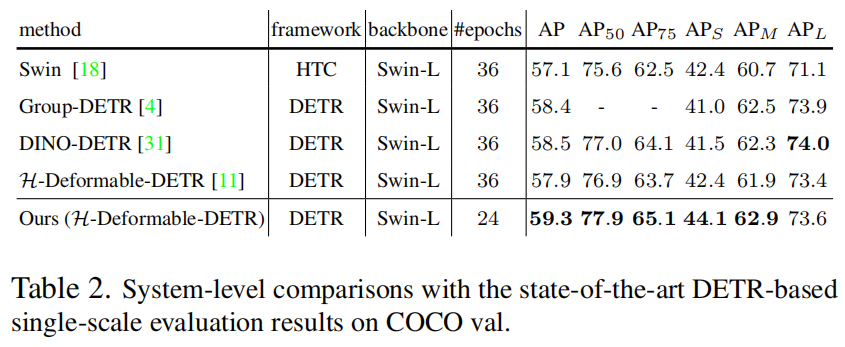
作者通过在COCO验证集上实现AP=59.3%的强大目标检测结果来证明作者方法的有效性,这超过了H-Deformable-DETR + Swin-L 1.4%。
最后,作者通过结合最近的图像到文本字幕模型(LLaVA)和文本到图像生成模型(SDXL)生成了一系列合成的预训练数据集。值得注意的是,对这些合成数据集进行预训练可以显著提高目标检测性能。展望未来,作者预计通过扩展合成预训练数据集将获得实质性的优势。
1、简介
最近,基于DETR的方法在目标检测和分割任务上取得了显著进展,并推动了前沿研究。例如,DINO-DETR、H-Deformable-DETR和Group-DETRv2在COCO基准上刷新了目标检测性能的最新成果。MaskDINO进一步扩展了DINO-DETR,在COCO实例分割和全景分割任务上取得了最佳结果。在某种程度上,这是首次端到端的Transformer方法能够比基于卷积的常规高度调优的强检测器(如Cascade Mask-RCNN和HTC++)实现更好的性能。
这些基于DETR的方法取得了巨大的成功,但它们仍然选择随机初始化Transformer,因此未能充分发挥像《 Aligning pretraining for detection via object-level contrastive learning》这样完全预训练的检测架构的潜力,该架构已经验证了将预训练架构与下游架构对齐的好处。
图1a和1b说明了基于ResNet50 Backbone网的标准Deformable-DETR网络中参数数量和GFLOPs的分布情况。作者可以看到,Transformer编码器和解码器占据了65%的GFLOPs和34%的参数,这意味着在DETR内部进行Transformer部分的预训练路径上存在着很大的改进空间。

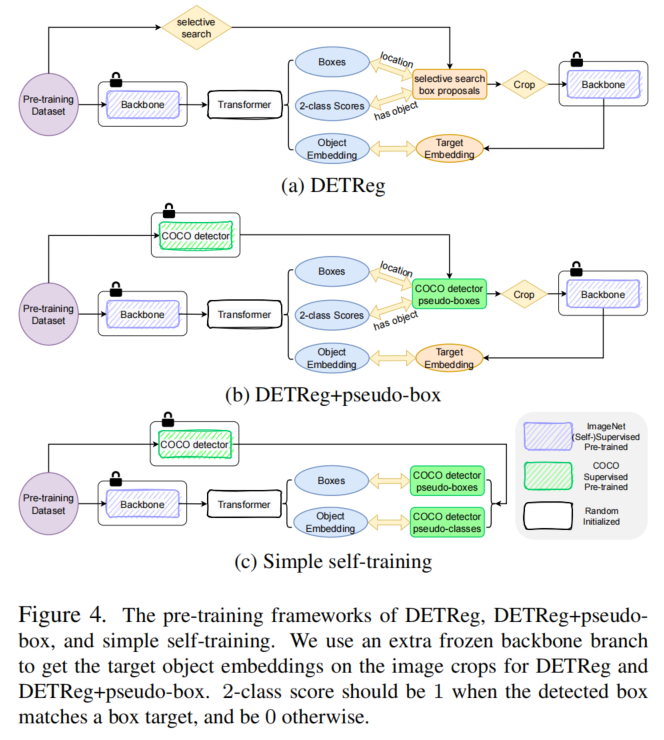
近期有几项研究通过在Transformer编码器和解码器上进行自监督预训练,并冻结Backbone网络,改善了基于DETR的目标检测模型(请参见图2的流程)。例如,UP-DETR 将Transformer预训练为检测图像中的随机Patch,DETReg 将Transformer预训练为将对象位置和特征与从选择性搜索方案生成的先验匹配,最近,Siamese DETR使用从不同视角的对应框中提取的查询特征定位目标框。
然而,这些方法要么使用基本的DETR模型(AP=42.1%),要么使用Deformable-DETR变种(AP=45.2%)。当在最新的、更强大的DETR模型(如H-Deformable-DETR,AP=49.6%)上进行预训练时,它们的结果明显不及预期,无法在COCO上达到较好的目标检测性能。(以DETReg为例,在图1c中,所有结果都是使用SwAV初始化的ResNet50 Backbone网获得)

在这项工作中,作者首先仔细研究了以DETReg为代表的自监督预训练方法对COCO目标检测基准上不断增强的DETR架构的改进程度。作者的调查揭示了DETReg在应用于通过SwAV预训练的Backbone网络、Deformable-DETR中的可变形技术以及H-Deformable-DETR中固有的混合匹配方案等功能强大的DETR网络上时效果的显著局限性(见图1c)。
作者将问题的关键点确定为由无监督方法(如选择性搜索)生成的不可靠的proposals框,这导致生成了噪声预训练目标,并且通过特征重建引入了弱语义信息,进一步恶化了问题。这些缺点使得无监督预训练方法在应用于已经强大的DETR模型时变得无效。
为了解决这个问题,作者提出使用COCO目标检测器来获得更准确的伪框,并使用信息丰富的伪类别标签。通过广泛的消融实验,作者强调了3个关键因素的影响:
-
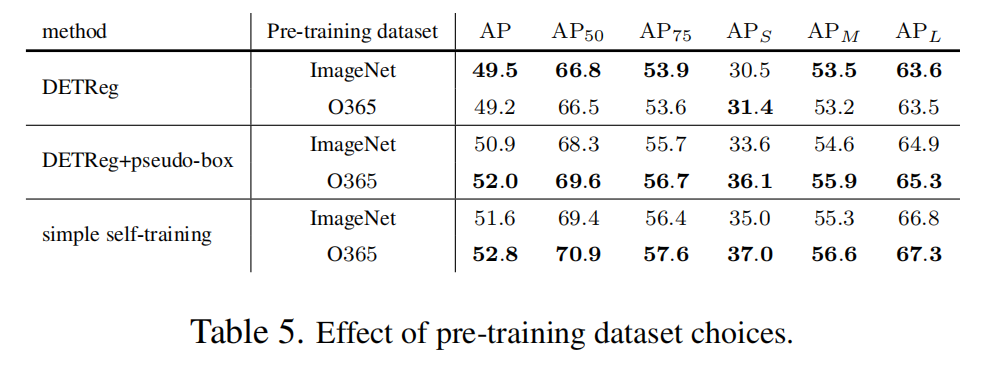
预训练数据集的选择(ImageNet与Objects365)
-
定位预训练目标的选择(选择性搜索提案与伪框预测)
-
分类预训练目标的选择(对象嵌入损失与伪类别预测)
这些因素对改进方法的效果产生了重要影响。作者的研究结果表明,在各种情况下,一个简单的自训练方案,使用伪框和伪类别预测作为预训练目标,优于DETReg方法。值得注意的是,即使在没有访问预训练基准的真实标签的情况下,这种简单的设计也能显著提升最先进的DETR网络的预训练效果。
例如,使用ResNet50 Backbone网络和Objects365预训练数据集,简单的自训练将H-Deformable-DETR上DETReg的COCO目标检测结果提高了3.6%。此外,作者还观察到了Swin-L Backbone网络的出色性能,取得了59.3%。
2、本文方法
2.1 DETR预训练方案
传统的DETR由两个网络模块组成(图2),包括提取通用图像特征的Backbone网络和获取检测特定特征以及预测目标位置和类别的Transformer。Transformer进一步由编码器和解码器模块组成,这些模块由多个线性神经网络层构建而成。编码器应用自注意力机制来提取更好的图像特征,而解码器查询编码器的特征并预测所需的信息作为任务目标。
现有的自监督方法针对预训练Transformer组件采用了与图2中所示相似的预训练方案。它们选择ImageNet作为大规模预训练基准,并且仅访问输入图像来建立自监督模式。精心设计的预训练任务通常包括定位任务,用于预测无监督的伪框提案,以及特征重构任务,以保留Transformer的特征判别能力。
为了保护Backbone网络的通用特征提取能力,使其不受预训练任务的损害,它们冻结了使用普通ImageNet预训练或更强的自监督预训练(称为SwAV)初始化的Backbone网络权重。Transformer的编码器和解码器在预训练期间是随机初始化和更新的。在微调阶段,Backbone网络加载未更改的ImageNet预训练权重,而Transformer加载更新后的权重。然后,在目标检测数据集的真实标签监督下,所有模型权重一起进行调优。其中一个代表性的自监督方法是DETReg。
DETReg使用选择性搜索作为无监督方法来创建用于定位预训练的框提案。选择性搜索在不知道对象的语义类别的情况下,生成可能对象周围的框。为了弥补缺乏类别信息,它还学习重构框的特征(也称为对象特征),这些特征是从裁剪后的输入图像中提取的,并使用固定的SwAVBackbone网络。通过这种方式,DETReg使得检测器能够同时对其位置和分类能力进行预训练,使用3个预测头部分别预测框的位置、指示框内是否存在目标的二进制类别以及相关的目标特征。
2.2 简单自训练
在这项工作中,作者发现自监督预训练方法只能为下游任务带来轻微的改进,特别是当DETR架构的原始准确性较高时。
例如,在图1c的DeformableDETR架构上,DETReg预训练方法提高了0.3,但在更强的H-Deformable-DETR架构上降低了0.1的性能。
作者提出了一个简单的自训练方案,不仅可以缓解这个问题,还可以使预训练模型在最先进的DETR架构上有所提升。
其思路是用经过训练的目标检测器预测的更准确的proposals框替换定位预训练中的低质量无监督proposals框。虽然特征重构对于分类预训练有助于防止网络判别能力的退化,但作者通过将其替换为由训练的检测器预测的伪类标签来进一步增强容量。
这种修改引入了语义信息到预训练中。尽管简单的自训练并不属于自监督方法,但它仅访问预训练数据集的图像,而由训练的检测器引入的监督是来自下游任务数据集,作者假设该数据集已经可用。
与传统的自训练方案不同,传统方案依赖于采用复杂的数据增强策略来提高伪标签的质量,并且需要仔细调整非极大值抑制(NMS)阈值,并迭代地基于微调模型生成更准确的伪标签。
相比之下,作者的方法直接一次性生成伪标签,无需使用这些技巧,伪标签只包含了一定数量的最可信的预测结果,因此被称为简单自训练。
为了生成伪标签,作者首先在COCO数据集上训练一个目标检测模型,然后使用该模型在预训练基准数据集(如ImageNet)上进行伪边界框和伪类标签的预测。然后,使用带有伪标签的基准数据集对所选的基于DETR的网络进行预训练。
在这项工作中,作者旨在研究代表性的自监督方法DETReg和作者的简单自训练方法中两个关键组件的影响:定位预训练目标的选择和分类预训练目标的选择。此外,在割离研究中,作者强调了预训练基准选择对预训练性能的重要性。
2.3 定位预训练目标
在自监督的预训练方法中使用了几种unsupervised box proposal algorithms,例如UP-DETR中的随机块、DETReg中的选择性搜索和Siamese DETR中的EdgeBoxes。关于定位预训练目标,作者的讨论将围绕DETReg使用的选择性搜索框(图4a)和简单自训练中使用的经过训练的目标检测器生成的伪边界框预测(图4c)展开。
1、选择性搜索框
在深度学习领域,选择性搜索是在深度学习时代之前最具影响力的区域提议生成方法之一,其在召回率方面表现出色。选择性搜索的灵感来自于图像本身具有的层次性,它采用了一种分层分组算法作为基础,通过使用FH算法生成初始区域,并利用贪婪算法根据颜色、纹理、大小和形状的相似性迭代地将区域组合成更大的区域。最终生成的区域形成了一组候选对象提议,每个提议对应于图像中可能包含感兴趣对象的区域。
与DETReg方法类似,作者将保留置信度最高的约30个proposals框作为基于选择性搜索的定位预训练目标。
2、伪边界框预测
对于伪边界框预测方案,作者直接选择了几个现成的经过良好训练的COCO目标检测器来预测用于预训练基准的伪边界框。
具体而言,作者选择了一种名为H-Deformable-DETR的强大的基于DETR的网络作为作者的目标检测器,并选择了两种不同的Backbone网络,包括ResNet50和Swin-L。这两个检测器在COCO数据集上具有显著的检测性能差异,这是由于它们的Backbone网络能力和训练时长不同:
-
H-Deformable-DETR + ResNet50训练12个epoch(AP=48.7%)
-
H-Deformable-DETR + Swin-L训练36个epoch(AP=57.8%)
然后,通过对预训练基准进行推理,作者得到了伪边界框的预测结果,并保留置信度最高的约30个边界框预测。
3、讨论
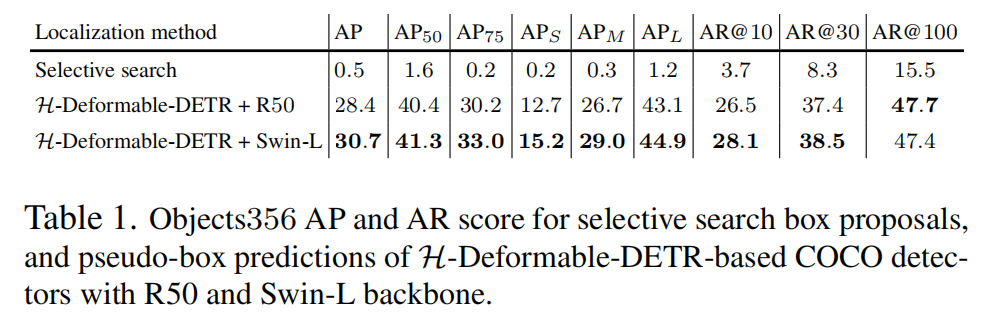
表格1比较了各种proposals框方法在预训练基准数据集Objects365上的边界框质量,作者报告了类别无关的精确度和召回率。可以看出,H-Deformable-DETR预测的伪边界框比无监督的选择性搜索方法更准确。
为了了解质量差异,作者在图3中可视化了Objects365上两个检测器的真实边界框、选择性搜索边界框和伪边界框预测结果。

2.4 预训练目标分类
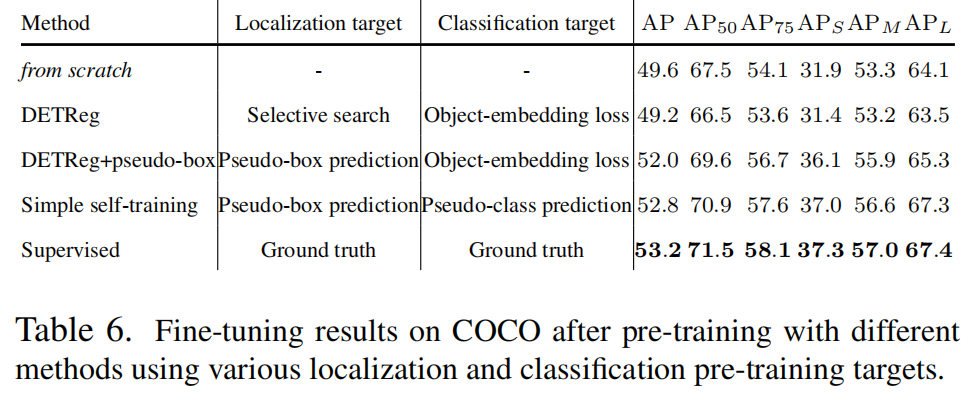
作者讨论了两种生成分类预训练目标的方法,其中包括特征重建方法(由DETReg的目标嵌入损失代表,图4a)和简单自训练中使用的伪类别预测(图4c)。
1、对象嵌入损失
为了将每个边界框与明确的语义类别意义相关联,DETReg在解码器中的每个查询嵌入上应用了一个目标嵌入头,以回归一个目标嵌入,其中包含了与相关边界框内的语义意义编码相关的信息。DETReg通过将使用SwAV预训练的Backbone网络的图像区域(由proposals框进行裁剪)馈送到其中来获得目标嵌入,如图4a所示。
然后,它计算预测的对象嵌入与相应目标嵌入之间的L1损失作为目标嵌入损失。在DETReg中,用于提取目标嵌入的Backbone网络以及基于DETReg的主要网络中的Backbone网络是固定的,只有Transformer编码器、解码器和预测头在预训练期间进行更新。
2、伪类别预测
作者还可以利用前述COCO目标检测器的类别预测作为每个边界框目标对应的分类目标,其中包含更精细和更丰富的语义信息。
由于检测器是在COCO上训练的,它所预测的伪类别标签就是COCO的80个类别。作为预训练基准类别的子集,它可以帮助实现高效的预训练效果。由于COCO伪类别还包含了下游基准(COCO和PASCAL VOC)的类别,它缩小了预训练和下游任务之间的差距。
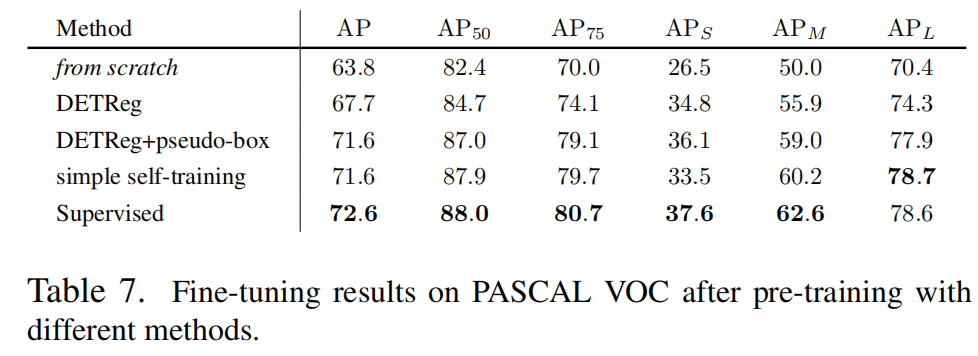
由于每个伪类别预测都被分配给了目标检测器中的一个伪边界框,作者无法将其与选择性搜索定位目标一起使用。图4展示了剩余3种定位和分类预训练目标的研究结果,它们分别是原始的DETReg方法、通过COCO检测器的伪边界框增强的DETReg方法,以及简单的自训练方法。
3、实验
3.1 Comparison to the State-of-the-art
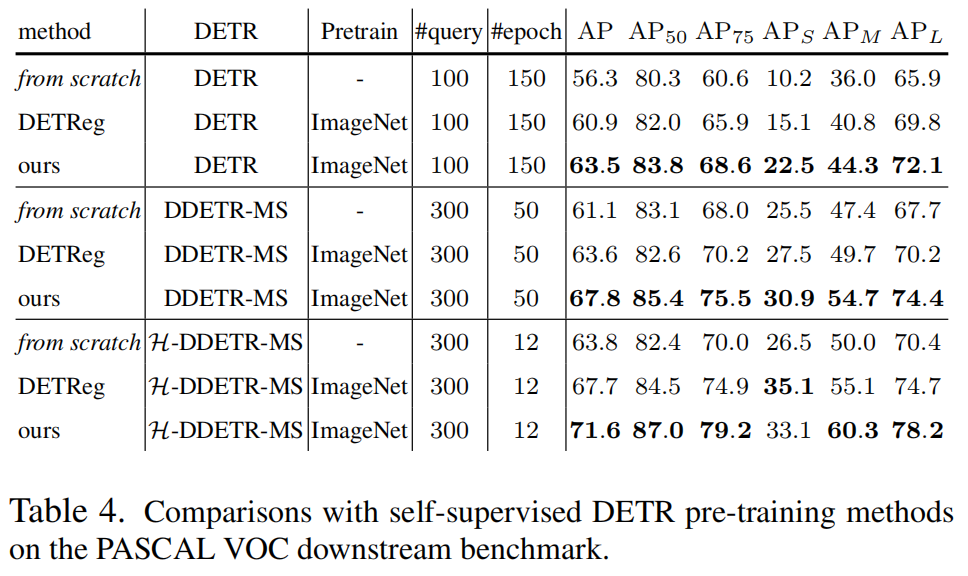
3.2 不同的DETR结构的研究结果

3.3 消融实验
3.3.1 预训练数据集的选择
3.3.2 预训练方法
3.3.3 pseudo-box数量

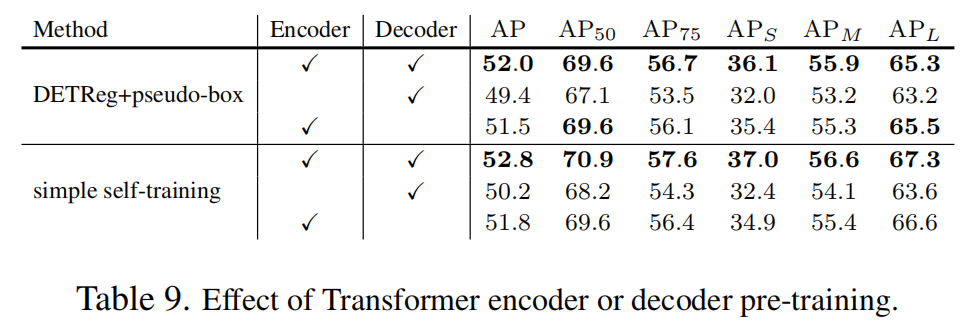
3.3.4 编码器和解码器预训练
3.3.5 Fine-tuning数据集大小
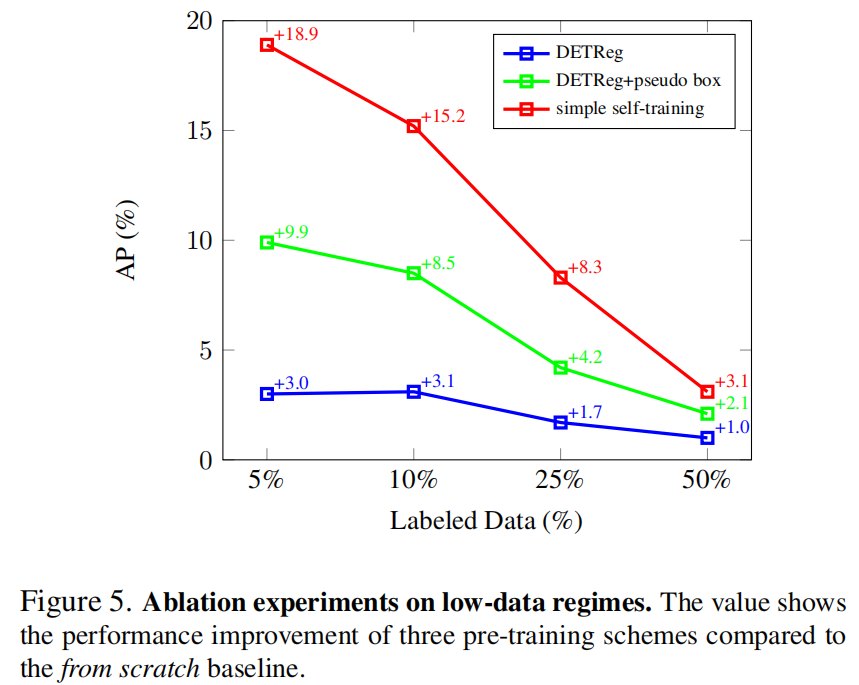
3.3.6 定性分析


3.4 通过T2I生成的合成数据的结果

4、参考
[1].Revisiting DETR Pre-training for Object Detection.
5、推荐阅读
训练Backbone你还用EMA?ViT训练的大杀器EWA升级来袭
ADAS落地 | 自动驾驶的硬件加速
Fast-BEV的CUDA落地 | 5.9ms即可实现环视BEV 3D检测落地!代码开源
扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)




前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!