
DETR目标检测新范式带来的思考
2020年,Transformer在计算机视觉领域大放异彩。Detection Transformer (DETR) [1]就是Transformer在目标检测领域的成功应用。利用Transformer中attention机制能够有效建模图像中的长程关系(long range dependency),简化目标检测的pipeline,构建端到端的目标检测器。然而DETR在目标检测领域带来的革新远远不止这些。本文首先对DETR原文进行介绍,随后总结DETR这一新范式在目标检测等领域带来的变革与思考。熟悉DETR的小伙伴可以直接跳到第二部分。
目录
一、DETR简介
二、DETR在目标检测领域带来的新思考
如何有效利用transformer解决图像中的目标检测问题 Sparse的目标检测方法 新的label assignment机制 如何构建end-to-end的目标检测器 如何更好地将DETR拓展到实例分割任务
一、DETR简介

DETR将目标检测看作一种set prediction问题,并提出了一个十分简洁的目标检测pipeline,即CNN提取基础特征,送入Transformer做关系建模,得到的输出通过二分图匹配算法与图片上的ground truth做匹配。
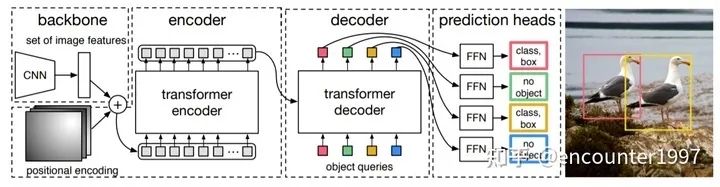
DETR的方法详情如上图所示,其关键的设计包含:
(1)Transformer
CNN提取的特征拉直(flatten)后加入位置编码(positional encoding)得到序列特征,作为Transformer encoder的输入。Transformer中的attention机制具有全局感受野,能够实现全局上下文的关系建模,其中encoder和decoder均由多个encoder、decoder层堆叠而成。每个encoder层中包含self-attention机制,每个decoder中包含self-attention和cross-attention。
(2)object queries
如上图所示,transformer解码器中的序列是object queries。每个query对应图像中的一个物体实例( 包含背景实例 ),它通过cross-attention从编码器输出的序列中对特定物体实例的特征做聚合,又通过self-attention建模该物体实例域其他物体实例之间的关系。最终,FFN基于特征聚合后的object queries做分类的检测框的回归。
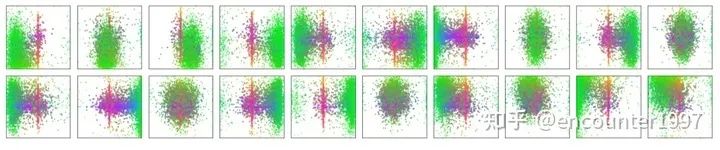
值得一提的是,object queries是可学习的embedding,与当前输入图像的内容无关(不由当前图像内容计算得到)。论文中对不同object query在COCO数据集上输出检测框的位置做了统计(如上图所示),可以看不同object query是具有一定位置倾向性的。对object queries的理解可以有多个角度。首先,它随机初始化,并随着网络的训练而更新,因此隐式建模了整个训练集上的统计信息。其次,在目标检测中每个object query可以看作是一种可学习的动态anchor,可以发现,不同于Faster RCNN, RetinaNet等方法在特征的每个像素上构建稠密的anchor不同,detr只用少量稀疏的anchor(object queries)做预测,这也启发了后续的一系列工作[4]。
(3)将目标检测问题看做Set Prediction问题,用二分图匹配实现label assignment
DETR中将目标检测问题看做Set Prediction问题,即将图像中所有感兴趣的物体看作是一个集和,要实现的目标是预测出这一集和。也就是说在DETR的视角下,目标检测不再是单独预测多个感兴趣的物体,而是从全局上将检测出所有目标所构成的整体作为目标。对应的,DETR站在全局的视角,用二分图匹配算法(匈牙利算法)计算prediction与ground truth之间的最佳匹配,从而实现label assignment。以上过程中需要定义什么是最佳匹配,也就是对所有可能的匹配做排序,DETR将一种匹配下模型的总定位和分类损失作为评判标准,损失越低,匹配越佳。注意,该匹配过程是不回传梯度的。DETR这种从全局的视角来实现label assignment的范式也启发了后续的一系列工作[5]。
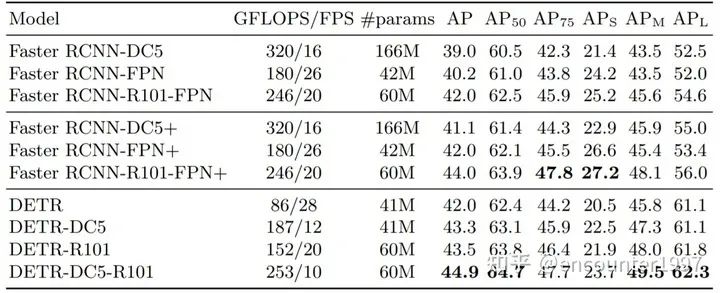
在训练过程中,DETR采用了deep supervision做为辅助损失,即在每个decoder layer的输出上都做预测和监督。DETR一般需要更长的训练时间达到收敛,例如在coco上需要300-500个周期收敛到比较好的结果。在性能上DETR相比于faster rcnn这类检测器能够在大物体上实现更好的检测,而对于小物体而言性能较差,具体性能如下表所示。
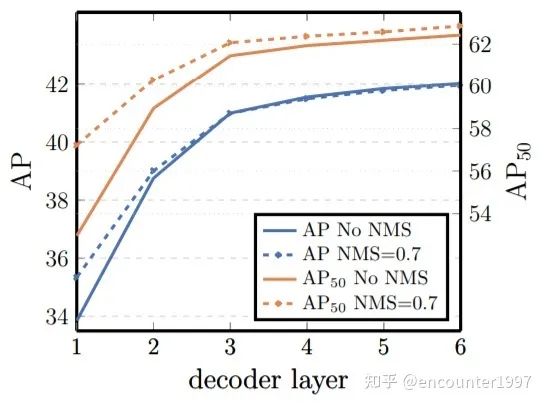
将目标检测看作set prediction问题,使用稀疏的object queries做预测,并采用二分图匹配做label assignment,DETR避免了预测时产生大量的重复检测(duplicates),因此不需要非极大值抑制(NMS)等后处理操作。下图对比了DETR中是否采用NMS的对性能的影响,可以看到到Decoder层数增加,NMS对模型性能的积极影响逐渐消失。
(4)拓展到全景分割
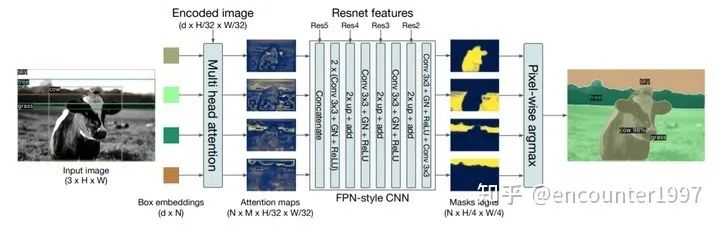
事实上DETR可以很容易的拓展到全景分割任务上,类比于Mask RCNN在Faster RCNN基础上加入mask预测分支实现实例分割。作者在DETR的Prediction Head分支上添加mask分支来实现全景分割。作者基于object query的attention map做mask分支预测,并结合CNN backbone的层级特征构建类似FPN结构的mask预测分支,如上图所示。
尽管本文introduction的写作是从构建端到端目标检测器,去除现有目标检测框架中复杂的手工设计这一角度出发的,但本文的意义远不止如此,下面将介绍DETR为目标检测社区带来的新思考。
二、DETR在目标检测领域带来的新思考
1、如何有效利用transformer解决图像中的目标检测问题
(1)Deformable DETR [2]
Deformable DETR对DETR的两处缺陷(收敛速度慢和对小物体的检测性能不佳)进行分析和改进,作者指出这两点缺陷事实上源自相同的原因:Transformer在处理图像特征时存在缺陷。具体来说,在初始化时transformer中每个query对所有位置给予几乎相同的权重,这使得网络需要经过长时间的训练将attention收敛到特定的区域。同时,由于transformer中attention机制随着图像中像素数目的增加呈平方增长,使用大的特征图输入encoder的代价极其高昂。因此,DETR只采用32倍下采样的特征图作为输入,导致其对小物体的检测性能不佳。
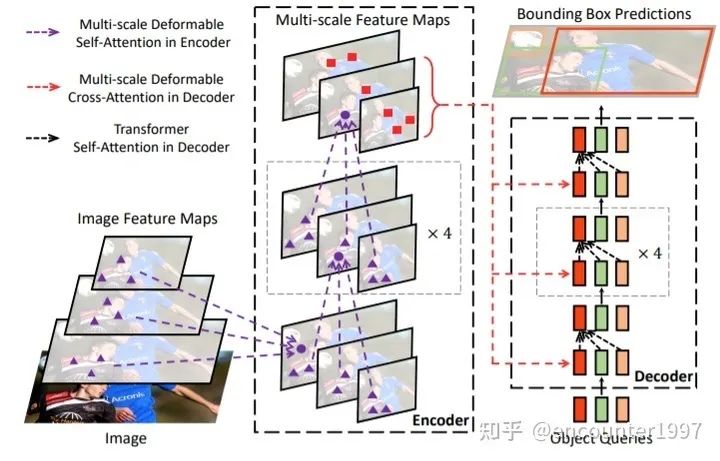
既然模型最终是要关注到稀疏的注意力区域,为什么不在一开始就让模型只关注稀疏的区域呢?作者提出Deformable Attention,在attention操作中对密集的key做稀疏采样,随后在query和稀疏的key之间做attention运算。由于模型只需要关注稀疏的采样点,其收敛速度显著提升。同时,由于每个query只需要对稀疏的key做聚合,模型的运算量和显存消耗显著下降,这使得Deformable Attention能够在可控的计算消耗下利用图像的多尺度特征。由此,得到的模型DeformableDETR如下图所示。
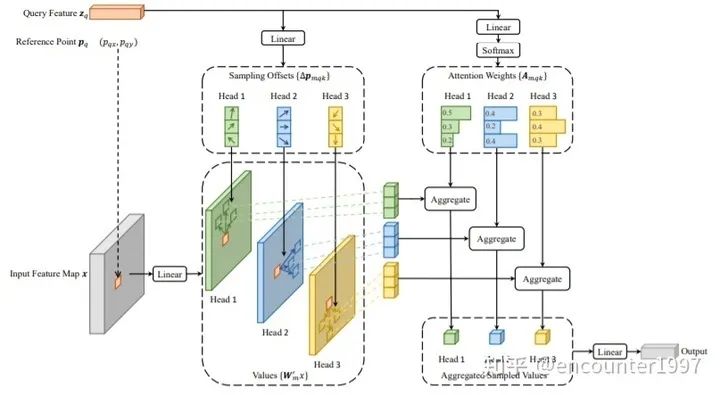
Deformable Attn示意图如下。值得一提的是,Deformable Attention中attention权重并非由query和稀疏的key之间做相似性计算得到的,而是直接由query经过projection得到。作者解释这是因为采用前者的方式计算的attention权重存在退化问题,即最后得到的attention权重与并没有随key的变化而变化。因此,这两种计算attention权重的方式最终得到的结果相当,而后者耗时更短、计算代价更小,所以作者选择直接对query做projection得到attention权重。具体的讨论请参见 Deformable DETR OpenReview(https://openreview.net/forum?id=gZ9hCDWe6ke¬eId=x1VT5henOtF)
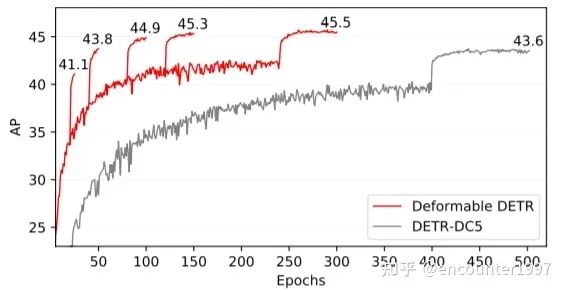
最终,DefomableDETR能够在以十分之一的迭代次数得到比DETR更好的性能。
(2)UP-DETR [3]
DETR存在的一个显著问题是模型收敛慢,训练周期长,这主要是因为随机初始化的Transformer需要很长的训练时间才能收敛。那么我们能否利用无监督的预训练来提升DETR中Transformer的收敛速度呢?为了实现这一目标,UP-DETR提出一个新的pretext task——multi-query localization(如图所示)来预训练DETR中的object query,以此来预训练Transformer的定位能力。同时,作者固定CNN backbone,并利用特征重建损失来保留特征的语义性,从而避免对定位的预训练伤害检测模型的分类能力。
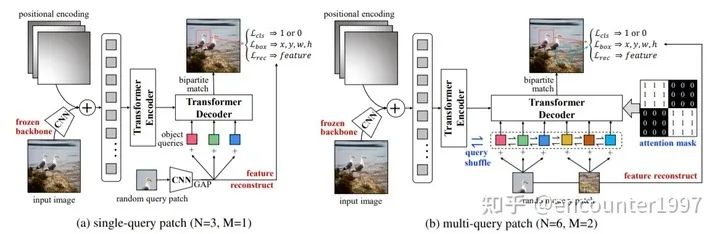
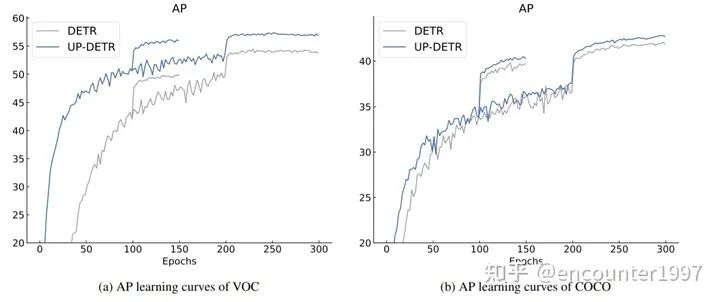
在完成预训练后,UP-DETR可以在检测任务上fine-tune,该fine-tuning过程与DETR原文的训练过程一致。如图,可以看出经过预训练后,UP-DETR能够取得比DETR更快的收敛速度以及更由的检测性能。
更详细的介绍请参见原作者的知乎回答:
如何评价华南理工和微信AI提出的无监督预训练检测器UP-DETR?
https://www.zhihu.com/question/432321109/answer/1606004872
2、Sparse的目标检测方法
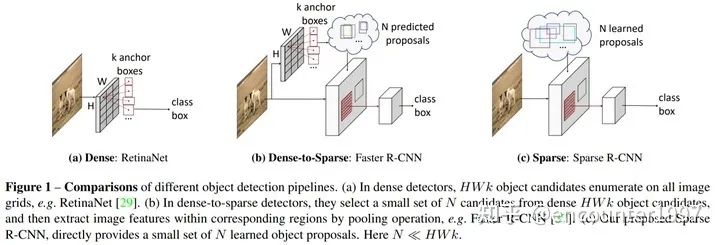
在DETR之前,主流的目标检测算法都依赖于稠密的anchor box或者anchor point。如上图所示,(a) 一阶段检测器如RetinaNet往往基于稠密的候选框做预测,(b) 二阶段目标检测器如faster rcnn则通过RPN从dense的候选框中筛选出稀疏的候选框,对比之下,DETR只将少量的(稀疏的)object queries作为目标检测的候选。受到这种sparse检测候选范式的启发,Sparse RCNN [4]提出仅用少量的(稀疏的)可学习的proposal作为候选框,并基于此提出一种基于RCNN的端到端目标检测方法。
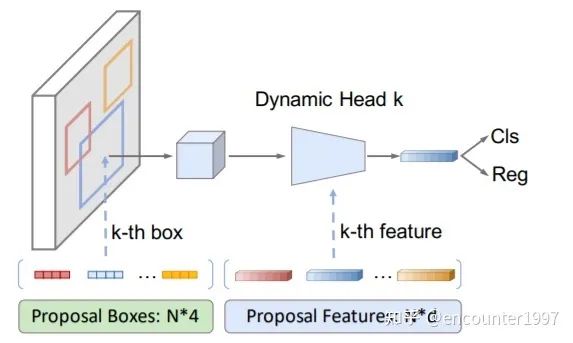
少量可学习的proposal反映了图像中物体位置的统计信息,然而仅使用4位的位置向量作为proposal无法反映物体的形状、姿态等细粒度的特征。相比之下,DETR中的object queries采用256维的嵌入向量来反映物体的特征,受此启发,作者在可学习的proposal基础上引入proposal feature来编码物体的精细特征,其与proposal数量相等,并存在一一对应关系。为了有效利用proposal feature,并为每个物体实例学习特异性的预测头,作者提出dynamic head,如下图所示。
该算法流程的伪代码如下图所示,proposal feature经过映射后得到1x1卷积核的参数(动态网络),与输入的物体实例特征做交互并输出。

值得一提的是,Sparse RCNN将Sparse这一特性应当同时包含(1)稀疏的检测候选,而不是遍历特征上的每个像素位置;(2)检测候选与图像特征之间只需要稀疏的交互,而非与图像特征的每个像素位置做交互。显然DETR满足第一条,而不满足第二条(Decoder中cross attention从整个图像特征序列中聚合信息),从这个意义上来说,DETR不完全是sparse的,而Deformable DETR和Sparse RCNN则满足sparse的特性。
最终,如图所示,Sparse RCNN能够在较短的训练周期下到达比500个周期训练的DETR更好的实验结果,并且性能优于Faster RCNN和RetinaNet等经典算法。
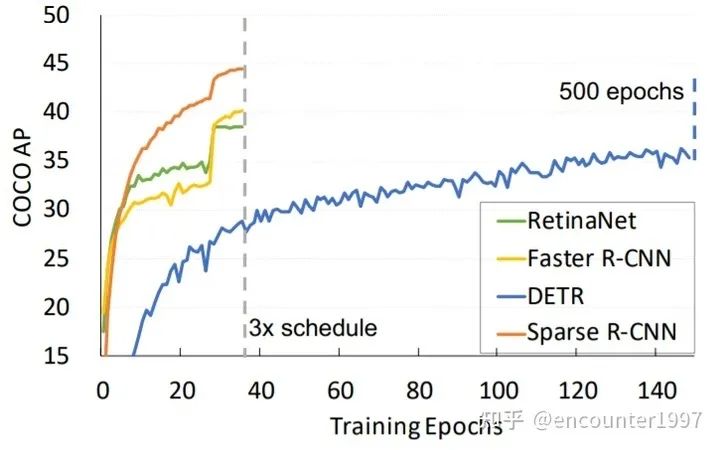
3、新的label assignment机制
对于图像分类、语义分割等问题,我们很容易建立输入图像和标签之之间的关联。例如,对于分类而言,模型只需要将输入与Ground Truth类别向量对应起来即可;而对于语义分割而言,由于模型输入和Ground Truth分割图之间存在空间对应关系,可以很容易的将原图上的像素与Ground Truth上相同像素位置的标签对应起来。对比之下,目标检测中输入图像和输出标签之间没有直接的对应关系:一张图片可能包含一个物体,也可能包含多个物体;一个像素可能在零个/一个检测框内,也可能在多个检测框内。
在DETR之前,大部分基于目标检测器根据像素(或anchor)与Ground Truth之间的局部空间位置关系(如IoU)来实现标签的分配(也因此造成了很多重复检测的存在)。而DETR采用二分图匹配方式,从全局的视角,在模型输出与标签之间建立一一对应的关系。
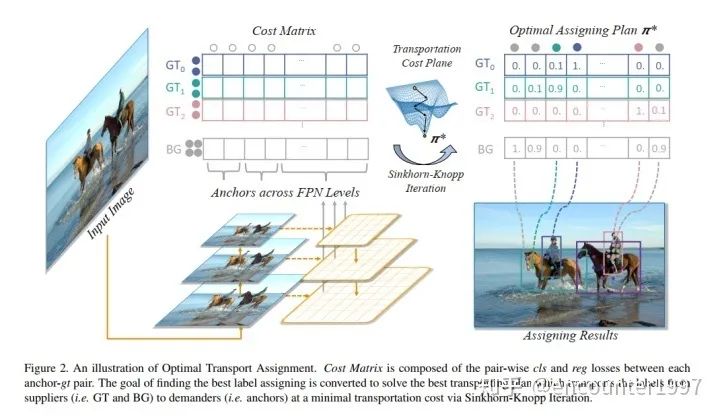
受到这一做法的启发,OTA(Optimal Transport Assignment)[5] 提出从全局的视角来实现label assignment。具体来说,它将每个GT instance看作一个supplier,将每个anchor看作一个demander,利用分类和定位损失计算一个supplier到一个demander的传输距离(即将一个GT分配给一个特定anchor的损失),随后利用Sinkhorn-Knopp计算GT到anchor之间的最优传输(即最佳的label assignment)。整个OTA算法流程如下图所示:

个人认为OTA与DETR中利用二分图匹配实现label assignment没有显著区别,不过将GT和anchor分别理解为supplier和demander,并用最优传输理论来解释整个标签分配过程还是让人觉得耳目一新。
4、如何构建end-to-end的目标检测器
DETR基于Transformer提出首个端到端的目标检测方法,那么很自然的问题就是:(1)基于CNN的目标检测方法能否做到端到端?(2)哪些因素是实现端到端目标检测的关键?以下三篇文章对这两个问题展开了探讨:
OneNet: Towards End-to-End One-Stage Object Detection
https://arxiv.org/abs/2012.05780
End-to-End Object Detection with Fully Convolutional Network
https://arxiv.org/abs/2012.03544
What Makes for End-to-End Object Detection?
https://icml.cc/Conferences/2021/Schedule?showEvent=8868
事实上,构建端到端的目标检测器与label assignment息息相关,这里不做展开介绍,感兴趣的小伙伴可以参考论文原文和作者的知乎介绍。
https://zhuanlan.zhihu.com/p/336016003
https://zhuanlan.zhihu.com/p/332281368
5、如何更好地将DETR拓展到实例分割任务
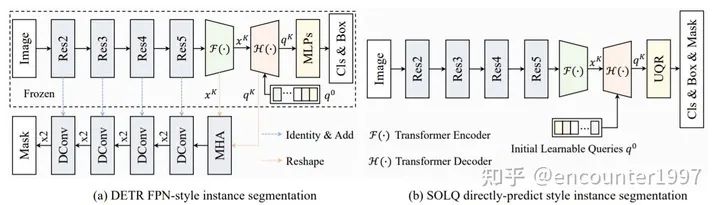
DETR论文中效仿Mask RCNN,添加mask分支来实现全景分割,同样的方法也可以被运用在实例分割任务上。然而DETR的mask分支十分复杂,需要使用复杂的网络,并利用类似FPN的结构来融合CNN特征。这主要是由于mask的输出空间较为复杂,不同于分类和定位只需要输出向量来表示类别和回归值,mask的预测需要输出2D的map。
SOLQ [6]在DETR基础上提出利用统一的类别、位置和mask特征表示UQR(Unified query representation)来实现端到端的实例分割。
具体来说,SOLQ提出对mask进行可逆的压缩编码,这样在训练时模型的mask分支只需要将query的映射与低维的mask编码作比较、计算损失;而在预测时,通过解码将预测出的低维mask编码解码为2D的分割map,如下图所示。
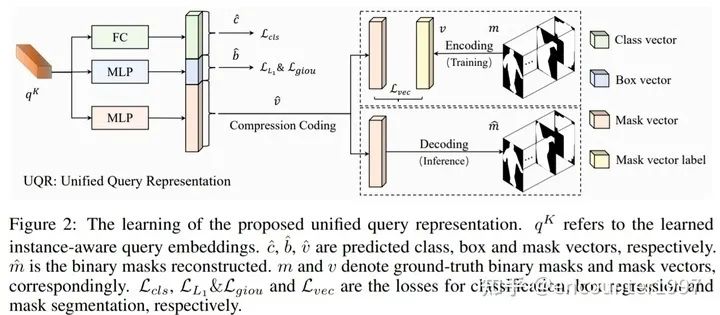
这样利用统一的query特征表示来实现分类、定位和分割三个任务使得模型,不仅大大简化了DETR做实例分割的整体流程,还能够充分利用多任务训练的好处。实验表明,采用UQR不仅能够同时也能够提升目标检测的精度。
总结
本文主要介绍了DETR在目标检测领域带来的变革与思考。由于涉及的文章数量较多,没有全部展开介绍,感兴趣的小伙伴还请参见论文原文。一个全新的目标检测框架能够为整个社区带来这么多新的思考,不经让人感慨。个人认为一个很锻炼科研思维的方法就是尝试站在某篇代表性文章刚刚发表的时间节点(先不看其后续工作),思考自己能够从这篇文章中得到哪些启发,会考虑从哪些角度做进一步的研究。再拿自己的思考与后续研究者的工作做比较,在这个过程中提升自己的科研直觉和判断力。
由于笔者能力有限,如有叙述不当之处,欢迎不吝赐教。
[1] End-to-End Object Detection with Transformers
[2] Deformable DETR: Deformable Transformers for End-to-End Object Detection
[3] UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
[4] Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
[5] OTA: Optimal Transport Assignment for Object Detection
[6] SOLQ: Segmenting Objects by Learning Queries
[7] You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
[8] Exploring Sequence Feature Alignment for Domain Adaptive Detection Transformers
——The End——

读者,你好!我们建立了学习交流群,欢迎大家扫码进群讨论!
微商和广告请绕道,谢谢合作!

如果觉得有用,就请分享到朋友圈吧!