
[ACM MM 2020] EFIFSTR: 基于字体风格无关特征学习的场景文本识别(有源码)
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文简要介绍ACM Multimedia 2020录用论文:“Exploring Font-independent Features for Scene Text Recognition”的主要工作。该工作旨在对场景文字图片提取字体风格无关特征,从而增强文本识别模型对文字风格的鲁棒性。
一、研究背景

图1 (a) 研究背景 (b) NFST数据集
二、原理简述
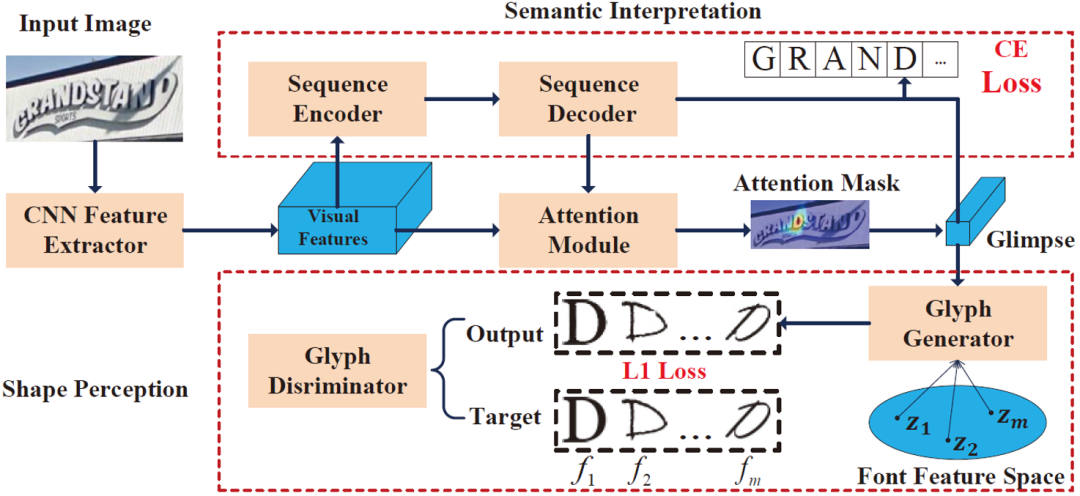
 提取特征
提取特征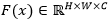 。网络结构基于ASTER[1],但
。网络结构基于ASTER[1],但 的高度
的高度 不会被下采样到维度是1,目的是为了保留更多的空间信息。在宽度
不会被下采样到维度是1,目的是为了保留更多的空间信息。在宽度 方向的每个特征会沿着高度方向进行池化,然后送入到LSTM 编码器;解码的时刻
方向的每个特征会沿着高度方向进行池化,然后送入到LSTM 编码器;解码的时刻 ,LSTM解码器的隐藏状态
,LSTM解码器的隐藏状态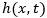 和一起送入到注意力模块。注意力模块用于计算注意力掩膜矩阵(Attention Mask):
和一起送入到注意力模块。注意力模块用于计算注意力掩膜矩阵(Attention Mask):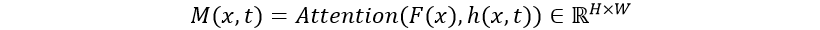
每个位置特征在时刻相对重要性,其计算方式如下: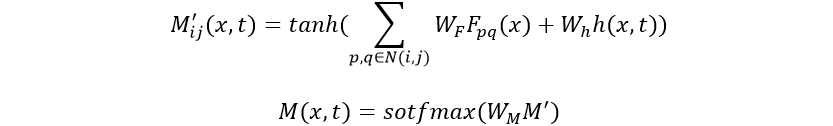
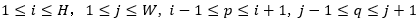 ;然后,
;然后, 和的每个通道的特征进行点乘,得到注意力内容向量
和的每个通道的特征进行点乘,得到注意力内容向量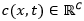 ,又称Glimpse向量。
,又称Glimpse向量。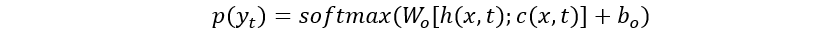

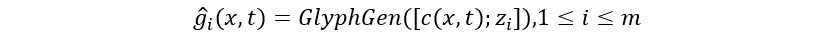
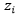 是第
是第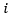 种字体的嵌入向量,
种字体的嵌入向量,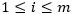 。最开始,所有字体的Font Embedding随机初始化,训练过程中使用梯度下降的方法,对它进行不断的优化,使得Font Embedding更加符合字体的风格特征。同时,我们也加入了一个字形辨别器(Glyph Discriminator)对生成的字形和真实的字形进行判别,其给出字形为真的概率为:
。最开始,所有字体的Font Embedding随机初始化,训练过程中使用梯度下降的方法,对它进行不断的优化,使得Font Embedding更加符合字体的风格特征。同时,我们也加入了一个字形辨别器(Glyph Discriminator)对生成的字形和真实的字形进行判别,其给出字形为真的概率为: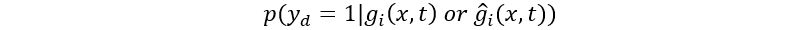

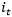 是每个训练Step时随机采样的目标字体风格的索引。
是每个训练Step时随机采样的目标字体风格的索引。 和
和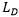 :
: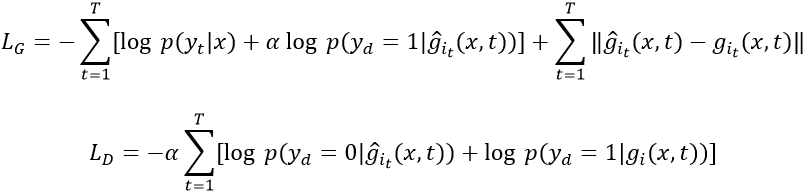
其中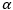 是超参数,设为0.01。采用Adam优化器对模型进行优化,初始学习率设置为0.001,每4万步衰减为原来的0.9倍。我们采用Microsoft Typography字体库中325种字体作为实验中的目标字体。
是超参数,设为0.01。采用Adam优化器对模型进行优化,初始学习率设置为0.001,每4万步衰减为原来的0.9倍。我们采用Microsoft Typography字体库中325种字体作为实验中的目标字体。
三、实验结果



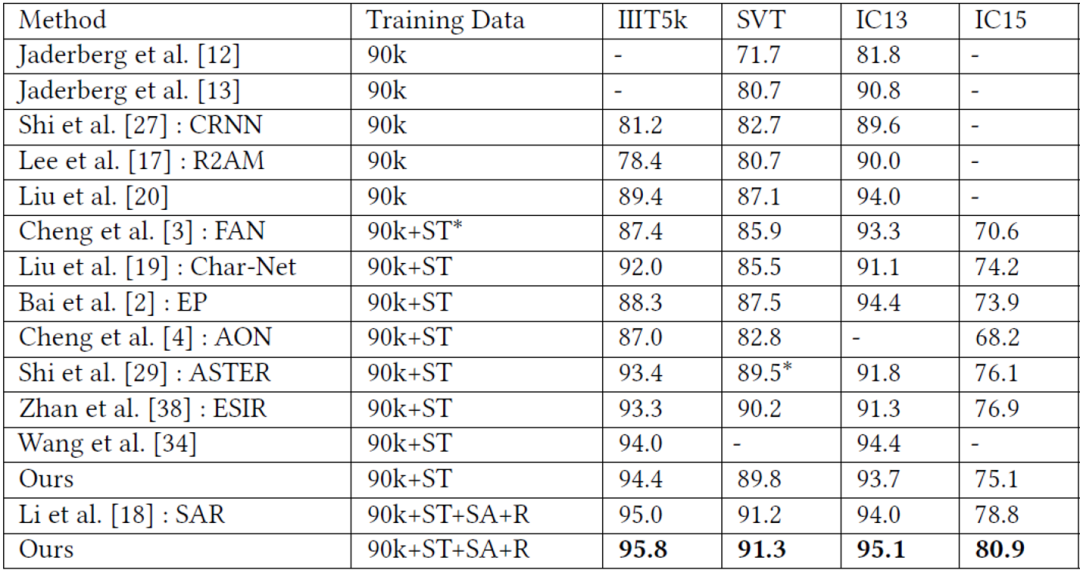
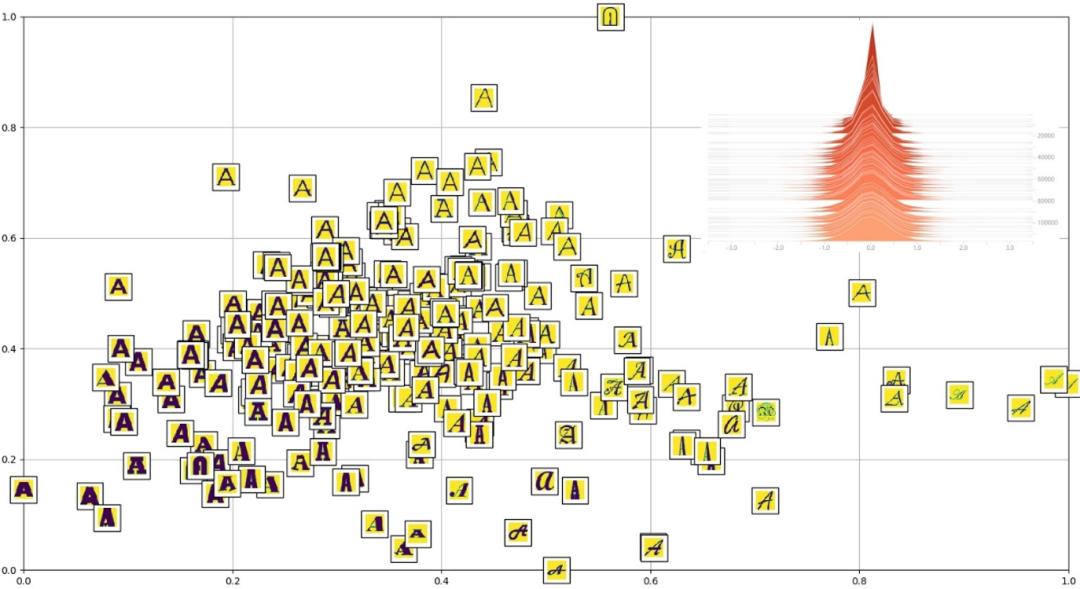
图6展示了字体风格嵌入向量的分布图及学习过程,在训练结束时,我们使用PCA(主成分分析)将所有字体风格嵌入向量降为2维坐标,并在每个点坐标上贴上每个字体对应的字符“A”图片;右上角展示了向量值的分布随着训练Step变化的过程。可以看出,向量值的分布在一定训练步数后趋于稳定,最终呈现的分布较好得体现了字体风格特征的分布,即风格越相近的字体,其Embedding在分布图中也越相近。
四、总结
本文针对自然场景文字识别提出了一种风格无关特征学习方法,该方法使用空间注意力机制、可训练的字体风格嵌入向量,来重建不同字体风格的标准字形,使得抽取的场景文本特征尽可能地与自身风格无关。实验结果证明本方法有效地提升了模型对于字体风格的鲁棒性。可改进的方面包括:(1)结合最新的图像生成方法,提升字形生成的效果;(2)使用基于Transformer、BERT的模型,更好地对文字序列进行建模。
五、相关资源
· EFIFSTR开源代码:https://github.com/Actasidiot/EFIFSTR
参考文献
[1] BaoguangShi, Mingkun Yang, Xinggang Wang, Pengyuan Lyu, Cong Yao, and Xiang Bai. 2018.ASTER: An Attentional Scene Text Recognizer with Flexible Rectification. IEEE TPAMI (2018), 1–1.
[2] Hui Li, Peng Wang, Chunhua Shen, andGuyu Zhang. 2019. Show, attend and read: A simple and strong baseline for irregular text recognition. In AAAI, Vol. 33. 8610–8617.
审校:殷 飞
发布:金连文
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
下载3 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得不错就点亮在看吧
