
基于度量学习的行人重识别(一)
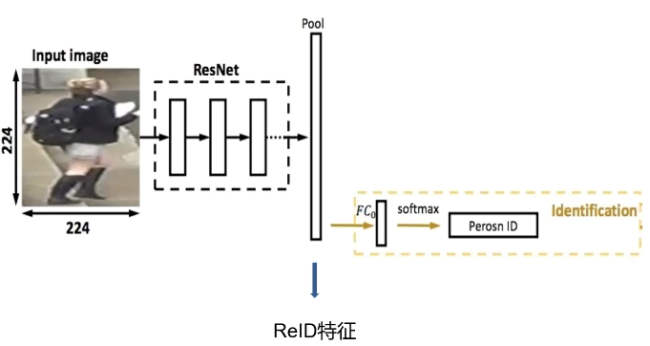
在前面的推文中,我们使用了表征学习来进行行人的重识别,但是在实际使用的时候,我们会发现一个问题,不同人之间的特征向量距离并不是特别的大,很容易造成误识别。那么有没有一个比较好的方法能够使不同人之间的特征距离尽可能地大而同一个人之间的距离尽可能小呢?
度量学习
当然是有的,这就是本章要说到度量学习,所谓度量学习(Metric Learning)是一种空间映射的方法,其能够学习到一种特征(Embedding)空间,在此空间中,所有的数据都被转换成一个特征向量,并且相似样本的特征向量之间距离小,不相似样本的特征向量之间距离大,从而对数据进行区分。度量学习应用在很多领域中,比如图像检索,人脸识别,目标跟踪等等。
三元组损失
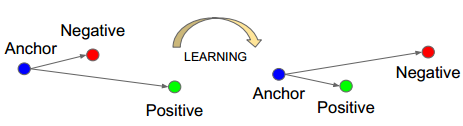
其中,使用最为广泛的就当属三元组损失了(Triplet loss),Triplet Loss的思想是让负样本对之间的距离大于正样本对之间的距离,在训练过的过程中同时选取一对正样本对和负样本对,且正负样本对中有一个样本是相同的。以狗、狼、猫数据为例,首先随机选取一个样本,此样本称之为anchor 样本,假设此样本类别为狗,然后选取一个与anchor样本同类别的样本(另一个狗狗),称之为positive,并让其与anchor样本组成一个正样本对(anchor-positive);再选取一个与anchor不同类别的样本(猫),称之为negative,让其与anchor样本组成一个负样本对(anchor-negative)。这样一共选取了三个样本,这也是为什么叫triplet的原因了。
Triplet Loss 的公式如下,通过公式可以看出,当负样本对之间的距离比正样本对之间的距离大m的时候,loss为0 ,认为当前模型已经学的不错了,所以不对模型进行更新。

Triplet Loss最先被用于人脸识别中,如下图,输入一个triplet对(三张图像),使用同一个网络对这个三张图像进行特征提取,得到三个embedding向量,三个向量输入到Triplet Loss中得到loss,然后根据loss值使用反向传播算法对模型进行更新。
在python中,Triplet loss的实现如下
import tensorflow as tffrom keras import backend as Kimport osdef triplet_loss(alpha = 0.2, batch_size = 32):def _triplet_loss(y_true, y_pred):anchor, positive, negative = y_pred[:batch_size], y_pred[batch_size:int(2*batch_size)], y_pred[-batch_size:]# 同一张人脸的 欧几里得距离pos_dist = K.sqrt(K.sum(K.square(anchor - positive), axis=-1))# 不同人脸的 欧几里得距离neg_dist = K.sqrt(K.sum(K.square(anchor - negative), axis=-1))# Triplet Lossbasic_loss = pos_dist - neg_dist + alpha #小idxs = tf.where(basic_loss > 0)select_loss = tf.gather_nd(basic_loss,idxs) #大loss = K.sum(K.maximum(basic_loss, 0)) / tf.cast(tf.maximum(1, tf.shape(select_loss)[0]), tf.float32)return lossreturn _triplet_loss
模型结构搭建
接下来我们进行模型搭建,模型我们使用的Google 的MobileNetV2,别问为什么,问就是它快!代码如下,由于tensorflow中自带预训练模型的优势,我们很快就可以搭建出一个模型出来。具体思路为
加载预训练模型MobileNetV2
获取MobileNetV2的global_average_pooling2d层的输出
进行随机失活,并全连接到128层的特征向量
使用批量标准化层将数据标准化
创建基础模型结构
使用normalize以及 softmax 作为模型的输出
normalize层我们使用三元组损失进行训练、softmax我们使用交叉熵损失辅助训练,这是为了模型更快地进行收敛。
返回训练模型以及基础模型
from tensorflow.keras.applications import MobileNetV2import tensorflow as tffrom tensorflow.keras.layers import *import tensorflow.keras.backend as K# import os# os.environ['CUDA_VISIBLE_DEVICES'] = "-1"def Create_Model(inpt=(128,128,3),num_classes=10,embedding_size=128, dropout_keep_prob=0.4):inpt = tf.keras.Input(inpt)base_model = MobileNetV2(include_top=True, input_tensor=inpt)out = base_model.get_layer('global_average_pooling2d').outputx = Dropout(1.0 - dropout_keep_prob, name='Dropout')(out)# 全连接层到128# 128x = Dense(embedding_size, use_bias=False, name='Bottleneck')(x)x = BatchNormalization(momentum=0.995, epsilon=0.001, scale=False,name='BatchNorm_Bottleneck')(x)# 创建模型model = tf.keras.Model(inpt, x, name='mobilenet')logits = Dense(num_classes)(model.output)softmax = Activation("softmax", name="Softmax")(logits)normalize = Lambda(lambda x: K.l2_normalize(x, axis=1), name="Embedding")(model.output)combine_model = tf.keras.Model(inpt, [softmax, normalize])x = Lambda(lambda x: K.l2_normalize(x, axis=1), name="Embedding")(model.output)model = tf.keras.Model(inpt, x)return combine_model,model
然后使用下面的代码就可以看到我们的模型结构啦!
model,_= Create_Model()model.summary()
最重要的数据处理以及模型训练由于篇幅的原因,就往后稍稍啦!有兴趣的同学记得关注一波