
超全Spark性能优化总结
点击上方蓝色字体,选择“设为星标”





Spark是大数据分析的利器,在工作中用到spark的地方也比较多,这篇总结是希望能将自己使用spark的一些调优经验分享出来。
一、常用参数说明
--driver-memory 4g : driver内存大小,一般没有广播变量(broadcast)时,
设置4g足够,如果有广播变量,视情况而定,可设置6G,8G,12G等均可
--executor-memory 4g : 每个executor的内存,正常情况下是4g足够,但有时
处理大批量数据时容易内存不足,再多申请一点,如6G
--num-executors 15 : 总共申请的executor数目,普通任务十几个或者几十个
足够了,若是处理海量数据如百G上T的数据时可以申请多一些,100,200等
--executor-cores 2 : 每个executor内的核数,即每个executor中的任务
task数目,此处设置为2,即2个task共享上面设置的6g内存,每个map或reduce
任务的并行度是executor数目*executor中的任务数
yarn集群中一般有资源申请上限,如,executor-memory*num-executors
< 400G 等,所以调试参数时要注意这一点
—-spark.default.parallelism 200 :Spark作业的默认为500~1000个比较
合适,如果不设置,spark会根据底层HDFS的block数量设置task的数量,这样
会导致并行度偏少,资源利用不充分。该参数设为num-executors *
executor-cores的2~3倍比较合适。
-- spark.storage.memoryFraction 0.6 : 设置RDD持久化数据在Executor
内存中能占的最大比例。默认值是0.6
—-spark.shuffle.memoryFraction 0.2 :设置shuffle过程中一个task拉取
到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,
默认是0.2,如果shuffle聚合时使用的内存超出了这个20%的限制,多余数据会
被溢写到磁盘文件中去,降低shuffle性能
—-spark.yarn.executor.memoryOverhead 1G :executor执行的时候,用的
内存可能会超过executor-memory,所以会为executor额外预留一部分内存,
spark.yarn.executor.memoryOverhead即代表这部分内存二、Spark常用编程建议
避免创建重复的RDD,尽量复用同一份数据。
尽量避免使用shuffle类算子,因为shuffle操作是spark中最消耗性能的地方,reduceByKey、join、distinct、repartition等算子都会触发shuffle操作,尽量使用map类的非shuffle算子
用aggregateByKey和reduceByKey替代groupByKey,因为前两个是预聚合操作,会在每个节点本地对相同的key做聚合,等其他节点拉取所有节点上相同的key时,会大大减少磁盘IO以及网络开销。
repartition适用于RDD[V], partitionBy适用于RDD[K, V]
mapPartitions操作替代普通map,foreachPartitions替代foreach
filter操作之后进行coalesce操作,可以减少RDD的partition数量
如果有RDD复用,尤其是该RDD需要花费比较长的时间,建议对该RDD做cache,若该RDD每个partition需要消耗很多内存,建议开启Kryo序列化机制(据说可节省2到5倍空间),若还是有比较大的内存开销,可将storage_level设置为MEMORY_AND_DISK_SER
尽量避免在一个Transformation中处理所有的逻辑,尽量分解成map、filter之类的操作
多个RDD进行union操作时,避免使用rdd.union(rdd).union(rdd).union(rdd)这种多重union,rdd.union只适合2个RDD合并,合并多个时采用SparkContext.union(Array(RDD)),避免union嵌套层数太多,导致的调用链路太长,耗时太久,且容易引发StackOverFlow
spark中的Group/join/XXXByKey等操作,都可以指定partition的个数,不需要额外使用repartition和partitionBy函数
尽量保证每轮Stage里每个task处理的数据量>128M
如果2个RDD做join,其中一个数据量很小,可以采用Broadcast Join,将小的RDD数据collect到driver内存中,将其BroadCast到另外以RDD中,其他场景想优化后面会讲
2个RDD做笛卡尔积时,把小的RDD作为参数传入,如BigRDD.certesian(smallRDD)
若需要Broadcast一个大的对象到远端作为字典查询,可使用多executor-cores,大executor-memory。若将该占用内存较大的对象存储到外部系统,executor-cores=1, executor-memory=m(默认值2g),可以正常运行,那么当大字典占用空间为size(g)时,executor-memory为2*size,executor-cores=size/m(向上取整)
15.如果对象太大无法BroadCast到远端,且需求是根据大的RDD中的key去索引小RDD中的key,可使用zipPartitions以hash join的方式实现,具体原理参考下一节的shuffle过程
如果需要在repartition重分区之后还要进行排序,可直接使用repartitionAndSortWithinPartitions,比分解操作效率高,因为它可以一边shuffle一边排序
三、shuffle性能优化
3.1 什么是shuffle操作 spark中的shuffle操作功能:将分布在集群中多个节点上的同一个key,拉取到同一个节点上,进行聚合或join操作,类似洗牌的操作。这些分布在各个存储节点上的数据重新打乱然后汇聚到不同节点的过程就是shuffle过程。
3.2 哪些操作中包含shuffle操作
RDD的特性是不可变的带分区的记录集合,Spark提供了Transformation和Action两种操作RDD的方式。Transformation是生成新的RDD,包括map, flatMap, filter, union, sample, join, groupByKey, cogroup, ReduceByKey, cros, sortByKey, mapValues等;Action只是返回一个结果,包括collect,reduce,count,save,lookupKey等
Spark所有的算子操作中是否使用shuffle过程要看计算后对应多少分区:
若一个操作执行过程中,结果RDD的每个分区只依赖上一个RDD的同一个分区,即属于窄依赖,如map、filter、union等操作,这种情况是不需要进行shuffle的,同时还可以按照pipeline的方式,把一个分区上的多个操作放在同一个Task中进行
若结果RDD的每个分区需要依赖上一个RDD的全部分区,即属于宽依赖,如repartition相关操作(repartition,coalesce)、 * ByKey操作(groupByKey,ReduceByKey,combineByKey、aggregateByKey等)、join相关操作(cogroup,join)、distinct操作,这种依赖是需要进行shuffle操作的
3.3 shuffle操作过程
shuffle过程分为shuffle write和shuffle read两部分
shuffle write:分区数由上一阶段的RDD分区数控制,shuffle write过程主要是将计算的中间结果按某种规则临时放到各个executor所在的本地磁盘上(当前stage结束之后,每个task处理的数据按key进行分类,数据先写入内存缓冲区,缓冲区满,溢写spill到磁盘文件,最终相同key被写入同一个磁盘文件)创建的磁盘文件数量=当前stage中task数量 * 下一个stage的task数量
shuffle read:从上游stage的所有task节点上拉取属于自己的磁盘文件,每个read task会有自己的buffer缓冲,每次只能拉取与buffer缓冲相同大小的数据,然后聚合,聚合完一批后拉取下一批,边拉取边聚合。分区数由Spark提供的一些参数控制,如果这个参数值设置的很小,同时shuffle read的数据量很大,会导致一个task需要处理的数据非常大,容易发生JVM crash,从而导致shuffle数据失败,同时executor也丢失了,就会看到Failed to connect to host 的错误(即executor lost)。
shuffle过程中,各个节点会通过shuffle write过程将相同key都会先写入本地磁盘文件中,然后其他节点的shuffle read过程通过网络传输拉取各个节点上的磁盘文件中的相同key。这其中大量数据交换涉及到的网络传输和文件读写操作是shuffle操作十分耗时的根本原因
3.4 spark的shuffle类型
参数spark.shuffle.manager用于设置ShuffleManager的类型。Spark1.5以后,该参数有三个可选项:hash、sort和tungsten-sort。
HashShuffleManager是Spark1.2以前的默认值,Spark1.2之后的默认值都是SortShuffleManager。tungsten-sort与sort类似,但是使用了tungsten计划中的堆外内存管理机制,内存使用效率更高。
由于SortShuffleManager默认会对数据进行排序,因此如果业务需求中需要排序的话,使用默认的SortShuffleManager就可以;但如果不需要排序,可以通过bypass机制或设置HashShuffleManager避免排序,同时也能提供较好的磁盘读写性能。
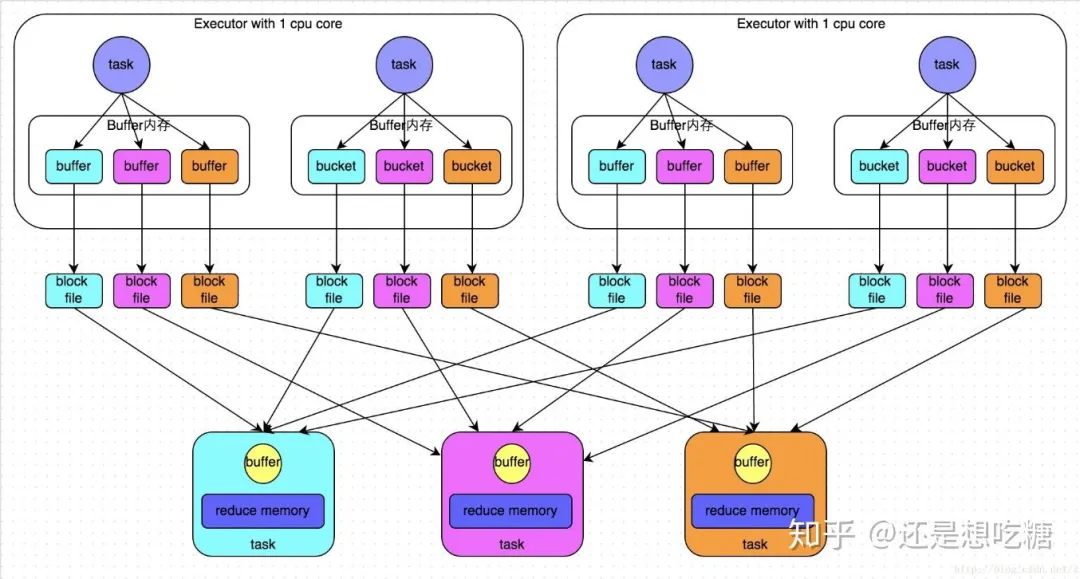
HashShuffleManager流程:
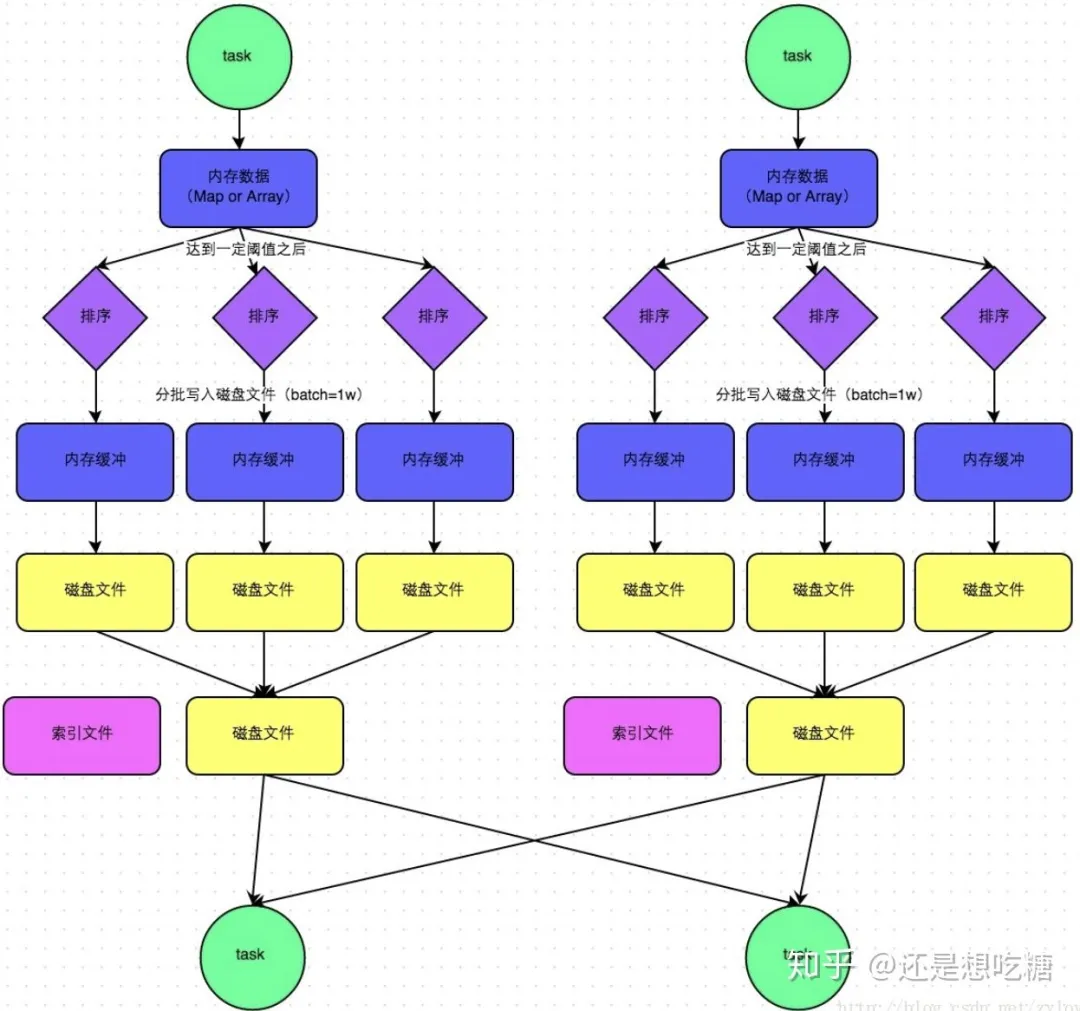
SortShuffleManager流程:
3.5 如何开启bypass机制
bypass机制通过参数spark.shuffle.sort.bypassMergeThreshold设置,默认值是200,表示当ShuffleManager是SortShuffleManager时,若shuffle read task的数量小于这个阈值(默认200)时,则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式写数据,但最后会将每个task产生的所有临时磁盘文件合并成一个文件,并创建索引文件。
这里给出的调优建议是,当使用SortShuffleManager时,如果的确不需要排序,可以将这个参数值调大一些,大于shuffle read task的数量。那么此时就会自动开启bypass机制,map-side就不会进行排序了,减少排序的性能开销,提升shuffle操作效率。但这种方式并没有减少shuffle write过程产生的磁盘文件数量,所以写的性能没有改变。
3.6 HashShuffleManager优化建议
如果使用HashShuffleManager,可以设置spark.shuffle.consolidateFiles参数。该参数默认为false,只有当使用HashShuffleManager且该参数设置为True时,才会开启consolidate机制,大幅度合并shuffle write过程产生的输出文件,对于shuffle read task 数量特别多的情况下,可以极大地减少磁盘IO开销,提升shuffle性能。参考社区同学给出的数据,consolidate性能比开启bypass机制的SortShuffleManager高出10% ~ 30%。
3.7 shuffle调优建议
除了上述的几个参数调优,shuffle过程还有一些参数可以提高性能:
- spark.shuffle.file.buffer : 默认32M,shuffle Write阶段写文件
时的buffer大小,若内存资源比较充足,可适当将其值调大一些(如64M),
减少executor的IO读写次数,提高shuffle性能
- spark.shuffle.io.maxRetries :默认3次,Shuffle Read阶段取数据
的重试次数,若shuffle处理的数据量很大,可适当将该参数调大。3.8 shuffle操作过程中的常见错误
SparkSQL中的shuffle错误:
org.apache.spark.shuffle.MetadataFetchFailedException:
Missing an output location for shuffle 0
org.apache.spark.shuffle.FetchFailedException:Failed to
connect to hostname/192.168.xx.xxx:50268RDD中的shuffle错误:
WARN TaskSetManager: Lost task 17.1 in stage 4.1
(TID 1386, spark050013): java.io.FileNotFoundException:
/data04/spark/tmp/blockmgr-817d372f-c359-4a00-96dd
-8f6554aa19cd/2f/temp_shuffle_e22e013a-5392-4edb
-9874-a196a1dad97c (没有那个文件或目录)
FetchFailed(BlockManagerId(6083b277-119a-49e8-8a49
-3539690a2a3f-S155, spark050013, 8533), shuffleId=1,
mapId=143, reduceId=3, message=
org.apache.spark.shuffle.FetchFailedException: Error
in opening FileSegmentManagedBuffer{file=/data04/spark
/tmp/blockmgr-817d372f-c359-4a00-96dd-8f6554aa19cd/0e/
shuffle_1_143_0.data, offset=997061, length=112503}处理shuffle类操作的注意事项:
减少shuffle数据量:在shuffle前过滤掉不必要的数据,只选取需要的字段处理
针对SparkSQL和DataFrame的join、group by等操作:可以通过 spark.sql.shuffle.partitions控制分区数,默认设置为200,可根据shuffle的量以及计算的复杂度提高这个值,如2000等
RDD的join、group by、reduceByKey等操作:通过spark.default.parallelism控制shuffle read与reduce处理的分区数,默认为运行任务的core总数,官方建议为设置成运行任务的core的2~3倍
提高executor的内存:即spark.executor.memory的值
分析数据验证是否存在数据倾斜的问题:如空值如何处理,异常数据(某个key对应的数据量特别大)时是否可以单独处理,可以考虑自定义数据分区规则,如何自定义可以参考下面的join优化环节
四、join性能优化
Spark所有的操作中,join操作是最复杂、代价最大的操作,也是大部分业务场景的性能瓶颈所在。所以针对join操作的优化是使用spark必须要学会的技能。
spark的join操作也分为Spark SQL的join和Spark RDD的join。
4.1 Spark SQL 的join操作
4.1.1 Hash Join
Hash Join的执行方式是先将小表映射成Hash Table的方式,再将大表使用相同方式映射到Hash Table,在同一个hash分区内做join匹配。
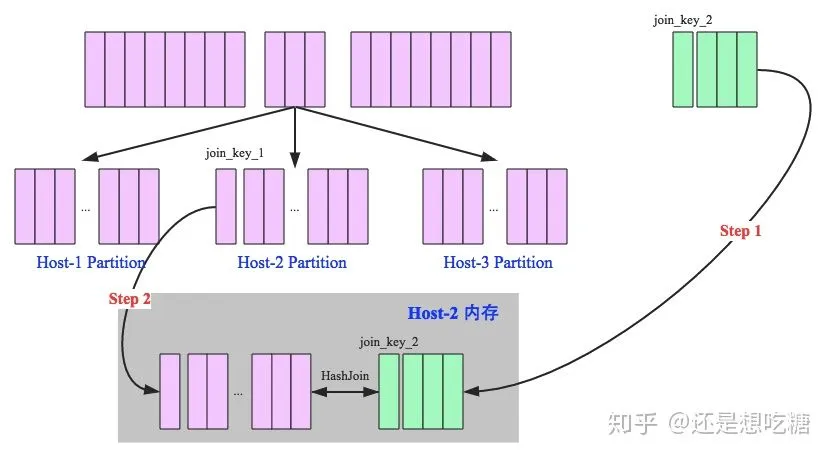
hash join又分为broadcast hash join和shuffle hash join两种。其中Broadcast hash join,顾名思义,就是把小表广播到每一个节点上的内存中,大表按Key保存到各个分区中,小表和每个分区的大表做join匹配。这种情况适合一个小表和一个大表做join且小表能够在内存中保存的情况。如下图所示:
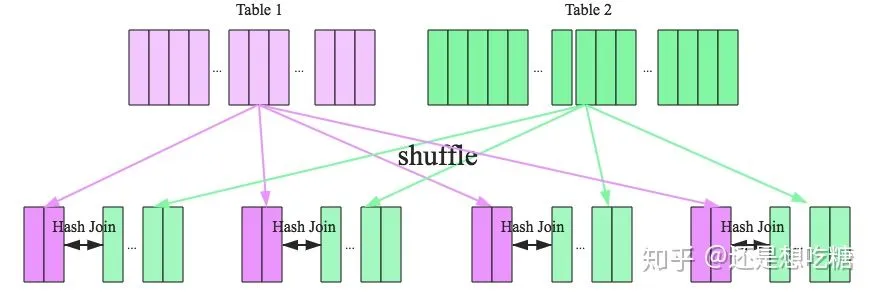
当Hash Join不能适用的场景就需要Shuffle Hash Join了,Shuffle Hash Join的原理是按照join Key分区,key相同的数据必然分配到同一分区中,将大表join分而治之,变成小表的join,可以提高并行度。执行过程也分为两个阶段:
shuffle阶段:分别将两个表按照join key进行分区,将相同的join key数据重分区到同一节点
hash join阶段:每个分区节点上的数据单独执行单机hash join算法
Shuffle Hash Join的过程如下图所示:
4.1.2 Sort-Merge Join
SparkSQL针对两张大表join的情况提供了全新的算法——Sort-merge join,整个过程分为三个步骤:
Shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式进行处理
sort阶段:对单个分区节点的两表数据,分别进行排序
merge阶段:对排好序的两张分区表数据执行join操作。分别遍历两个有序序列,遇到相同的join key就merge输出,否则继续取更小一边的key,即合并两个有序列表的方式。
sort-merge join流程如下图所示。
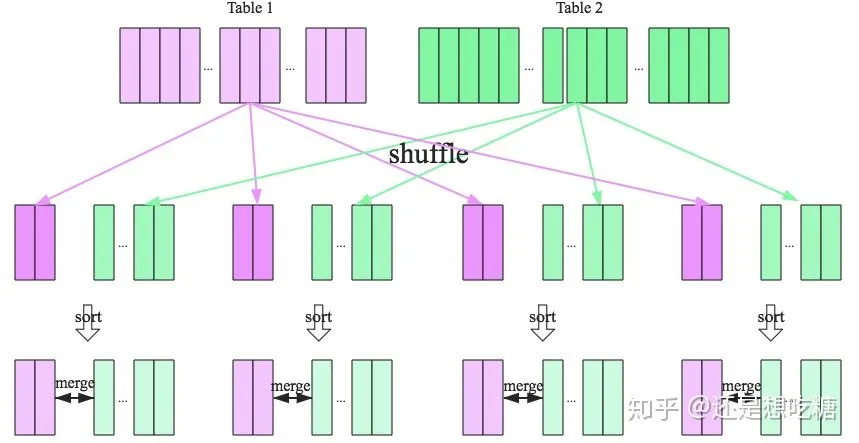
4.2 Spark RDD的join操作
Spark的RDD join没有上面这么多的分类,但是面临的业务需求是一样的。如果是大表join小表的情况,则可以将小表声明为broadcast变量,使用map操作快速实现join功能,但又不必执行Spark core中的join操作。
如果是两个大表join,则必须依赖Spark Core中的join操作了。Spark RDD Join的过程可以自行阅读源码了解,这里只做一个大概的讲解。
spark的join过程中最核心的函数是cogroup方法,这个方法中会判断join的两个RDD所使用的partitioner是否一样,如果分区相同,即存在OneToOneDependency依赖,不用进行hash分区,可直接join;如果要关联的RDD和当前RDD的分区不一致时,就要对RDD进行重新hash分区,分到正确的分区中,即存在ShuffleDependency,需要先进行shuffle操作再join。因此提升join效率的一个思路就是使得两个RDD具有相同的partitioners。
所以针对Spark RDD的join操作的优化建议是:
如果需要join的其中一个RDD比较小,可以直接将其存入内存,使用broadcast hash join
在对两个RDD进行join操作之前,使其使用同一个partitioners,避免join操作的shuffle过程
如果两个RDD其一存在重复的key也会导致join操作性能变低,因此最好先进行key值的去重处理
4.3 数据倾斜优化
均匀数据分布的情况下,前面所说的优化建议就足够了。但存在数据倾斜时,仍然会有性能问题。主要体现在绝大多数task执行得都非常快,个别task执行很慢,拖慢整个任务的执行进程,甚至可能因为某个task处理的数据量过大而爆出OOM错误。
4.3.1 分析数据分布
如果是Spark SQL中的group by、join语句导致的数据倾斜,可以使用SQL分析执行SQL中的表的key分布情况;如果是Spark RDD执行shuffle算子导致的数据倾斜,可以在Spark作业中加入分析Key分布的代码,使用countByKey()统计各个key对应的记录数。
4.3.2 数据倾斜的解决方案
这里参考美团技术博客中给出的几个方案。
1)针对hive表中的数据倾斜,可以尝试通过hive进行数据预处理,如按照key进行聚合,或是和其他表join,Spark作业中直接使用预处理后的数据。
2)如果发现导致倾斜的key就几个,而且对计算本身的影响不大,可以考虑过滤掉少数导致倾斜的key
3)设置参数spark.sql.shuffle.partitions,提高shuffle操作的并行度,增加shuffle read task的数量,降低每个task处理的数据量
4)针对RDD执行reduceByKey等聚合类算子或是在Spark SQL中使用group by语句时,可以考虑两阶段聚合方案,即局部聚合+全局聚合。第一阶段局部聚合,先给每个key打上一个随机数,接着对打上随机数的数据执行reduceByKey等聚合操作,然后将各个key的前缀去掉。第二阶段全局聚合即正常的聚合操作。
5)针对两个数据量都比较大的RDD/hive表进行join的情况,如果其中一个RDD/hive表的少数key对应的数据量过大,另一个比较均匀时,可以先分析数据,将数据量过大的几个key统计并拆分出来形成一个单独的RDD,得到的两个RDD/hive表分别和另一个RDD/hive表做join,其中key对应数据量较大的那个要进行key值随机数打散处理,另一个无数据倾斜的RDD/hive表要1对n膨胀扩容n倍,确保随机化后key值仍然有效。
6)针对join操作的RDD中有大量的key导致数据倾斜,对有数据倾斜的整个RDD的key值做随机打散处理,对另一个正常的RDD进行1对n膨胀扩容,每条数据都依次打上0~n的前缀。处理完后再执行join操作
五、其他错误总结
(1) 报错信息
java.lang.OutOfMemory, unable to create new native thread
Caused by: java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:640)解决方案:
上面这段错误提示的本质是Linux操作系统无法创建更多进程,导致出错,并不是系统的内存不足。因此要解决这个问题需要修改Linux允许创建更多的进程,就需要修改Linux最大进程数
(2)报错信息
由于Spark在计算的时候会将中间结果存储到/tmp目录,而目前linux又都支持tmpfs,其实就是将/tmp目录挂载到内存当中, 那么这里就存在一个问题,中间结果过多导致/tmp目录写满而出现如下错误 No Space Left on the device(Shuffle临时文件过多)
解决方案:
修改配置文件spark-env.sh,把临时文件引入到一个自定义的目录中去, 即:
export SPARK_LOCAL_DIRS=/home/utoken/datadir/spark/tmp(3)报错信息 Worker节点中的work目录占用许多磁盘空间, 这些是Driver上传到worker的文件, 会占用许多磁盘空间 需要定时做手工清理work目录
(4)spark-shell提交Spark Application如何解决依赖库 解决方案:
(5)内存不足或数据倾斜导致Executor Lost,shuffle fetch失败,Task重试失败等(spark-submit提交)
TaskSetManager: Lost task 1.0 in stage 6.0 (TID 100, 192.168.10.37): java.lang.OutOfMemoryError: Java heap space
INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on 192.168.10.37:57139 (size: 42.0 KB, free: 24.2 MB)
INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on 192.168.10.38:53816 (size: 42.0 KB, free: 24.2 MB)
INFO TaskSetManager: Starting task 3.0 in stage 6.0 (TID 102, 192.168.10.37, ANY, 2152 bytes)解决方案:增加worker内存,或者相同资源下增加partition数目,这样每个task要处理的数据变少,占用内存变少
如果存在shuffle过程,设置shuffle read阶段的并行数。


版权声明:
编辑 《大数据技术与架构》
插画 《大数据技术与架构》
文章链接 https://blog.csdn.net/kisimple
文章不错?点个【在看】吧! ?