
视觉Transformer最新综述


论文标题:
A Survey on Visual Transformer
论文链接:
https://arxiv.org/pdf/2012.12556.pdf
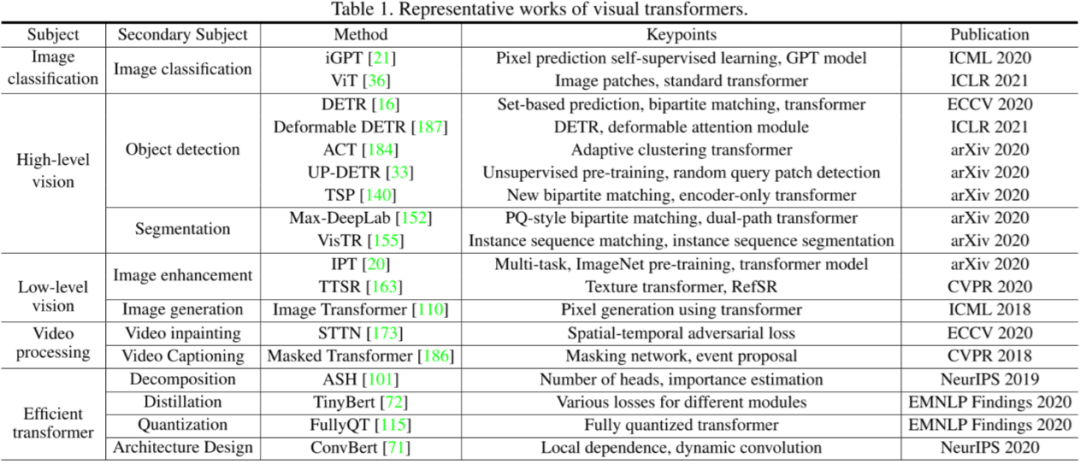

Formulation of Transformer

计算不同输入向量的得分 为了梯度的稳定性进行归一化 将得分转化为概率 最后得到加权的矩阵
这整个过程可以被统一为一个简单的函数:
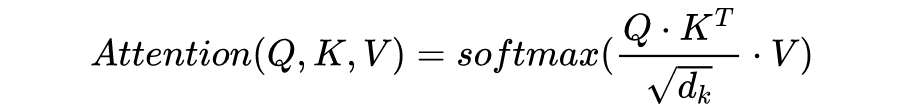
直观来看,第 1 步计算两个不同向量之间的分数,这个分数用来确定我们在当前位置编码单词时对其他单词的注意程度。步骤 2 标准化得分,使其具有更稳定的梯度,以便更好地训练;步骤 3 将得分转换为概率。最后,将每个值向量乘以概率的总和,概率越大的向量将被下面几层更多地关注。
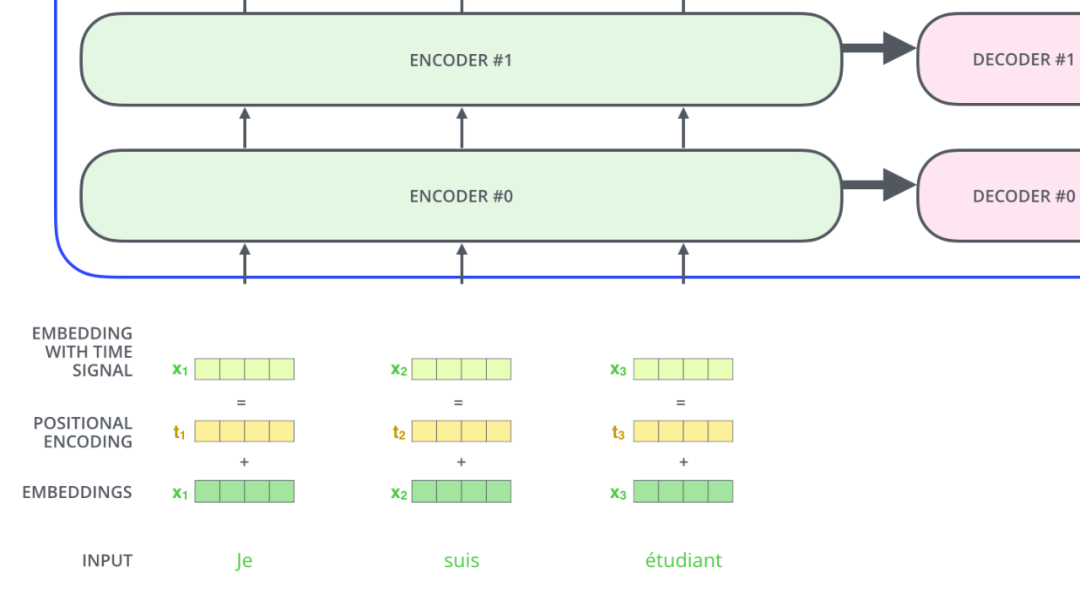
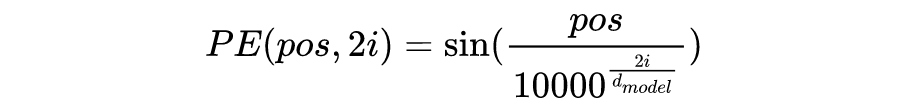
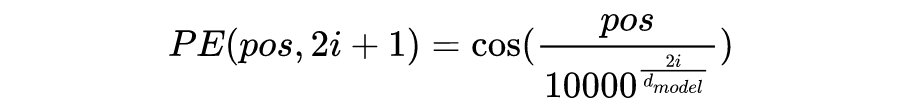
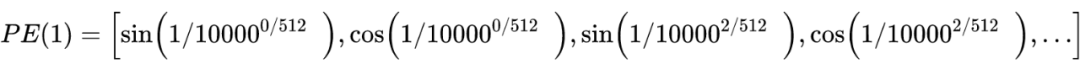
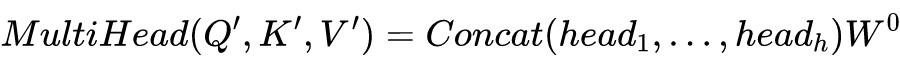
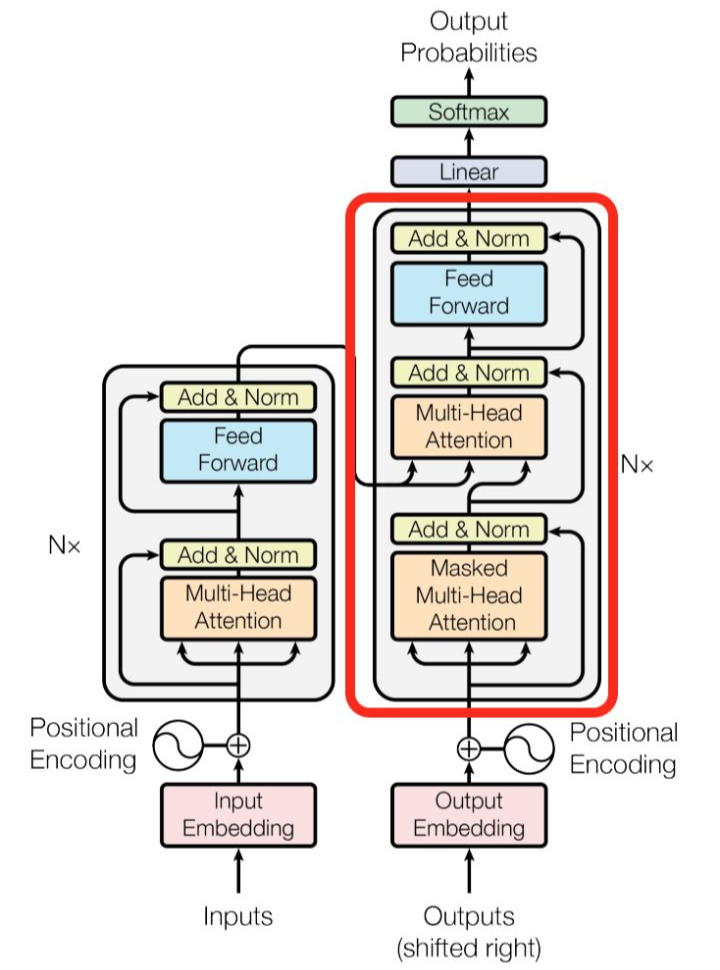
这就是基本的 Multihead Attention 单元,对于 encoder 来说就是利用这些基本单元叠加,其中 key, query, value 均来自前一层 encoder 的输出,即 encoder 的每个位置都可以注意到之前一层 encoder 的所有位置。
对于 decoder 来讲,我们注意到有两个与 encoder 不同的地方,一个是第一级的 Masked Multi-head,另一个是第二级的 Multi-Head Attention 不仅接受来自前一级的输出,还要接收 encoder 的输出,下面分别解释一下是什么原理。
第一级 decoder 的 key, query, value 均来自前一层 decoder 的输出,但加入了 Mask 操作,即我们只能attend到前面已经翻译过的输出的词语,因为翻译过程我们当前还并不知道下一个输出词语,这是我们之后才会推测到的。
而第二级 decoder 也被称作 encoder-decoder attention layer,即它的 query 来自于之前一级的 decoder 层的输出,但其 key 和 value 来自于 encoder 的输出,这使得 decoder 的每一个位置都可以 attend 到输入序列的每一个位置。
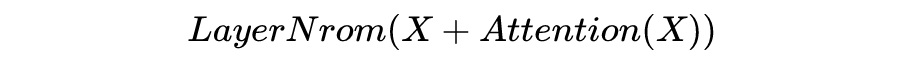
大多数用于计算机视觉任务的 Transformer 都使用原编码器模块。总之,它可以被视为一种不同于 CNN 和递归神经网络 RNN 的新型特征选择器。与只关注局部特征的 CNN 相比,transformer 能够捕捉到长距离特征,这意味着 transformer 可以很容易地获得全局信息。

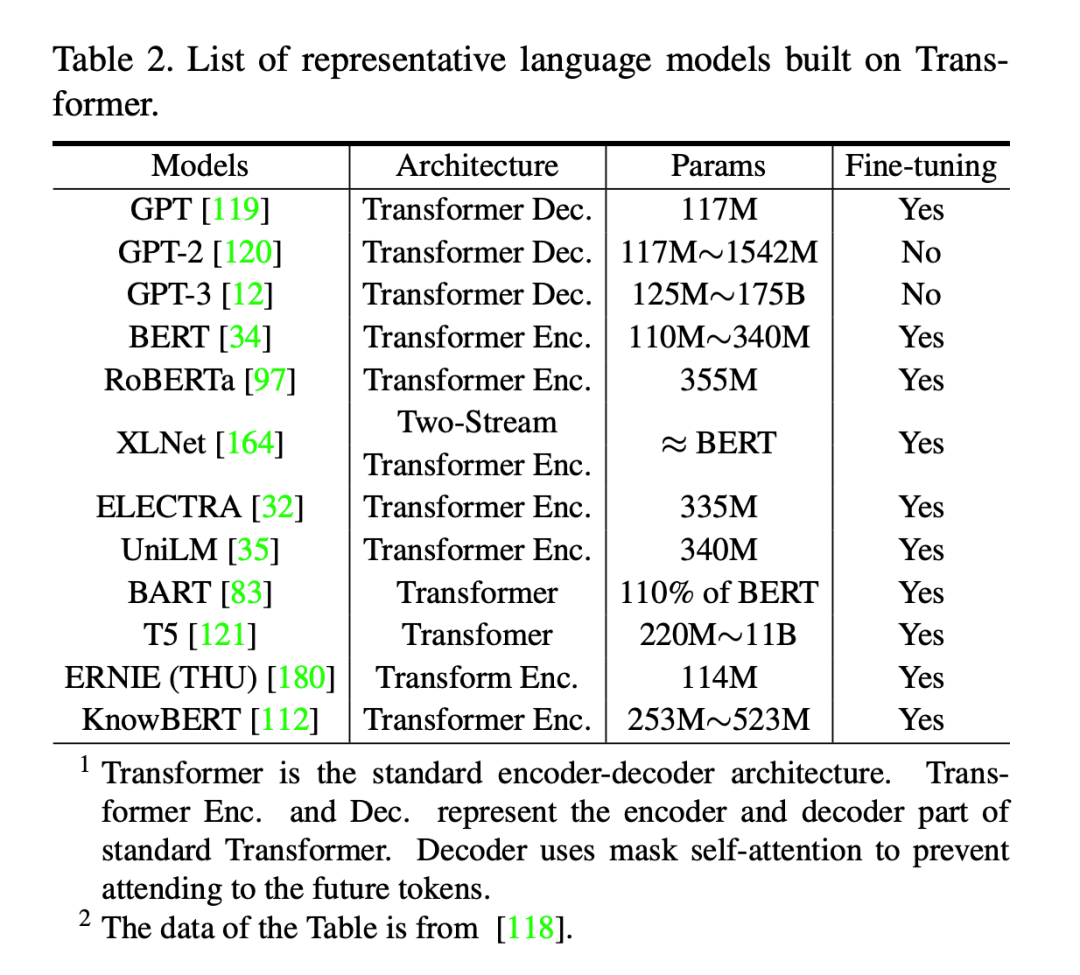
Transformers 出现后,克服了RNN训练速度慢的缺陷,使得大规模预训练模型成为可能。BETR 及其变种(SpanBERT,RoBERTa)等都是基于 transformer 的模型。在 BERT 的预训练阶段,对 BookCorpus 和英语维基百科数据集进行了两个任务
Mask 一部分 token 让模型来预测。
输入两个句子让模型预测第二个句子是否是文档中的原始句子。在预训练之后,BERT 可以添加一个输出层在下游任务进行 fine-tune。在执行序列级任务(如情感分析)时,BERT 使用第一个 token 的表示进行分类;而对于 token 级别的任务(例如,名称实体识别),所有 token 都被送入 softmax 层进行分类。
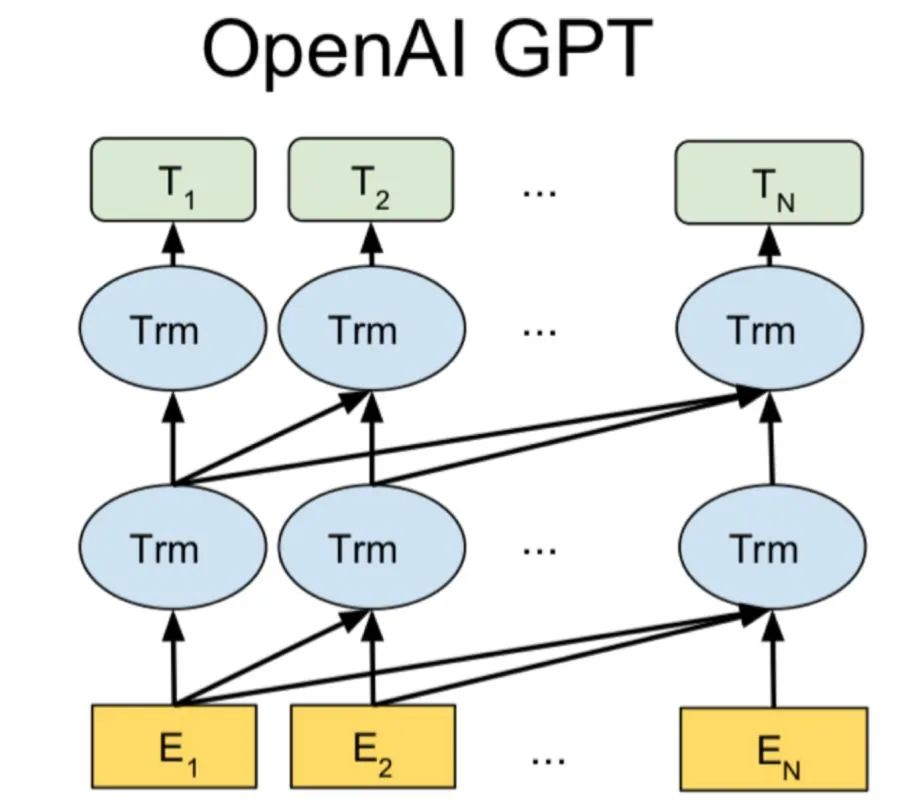
Generative Pre-Trained Transformer(GPT2,GPT3)是另一种基于 Transformer 解码器架构的预训练模型,它使用了带掩码的自我注意机制。
还有一些多模态的 transformer 和这篇文章比较相关,可以简单了解一下。VideoBERT 使用基于 CNN 的 module 将图像转化为 token,然后使用 transformer 的 encoder 来为下游任务学习一个 video-text representation。

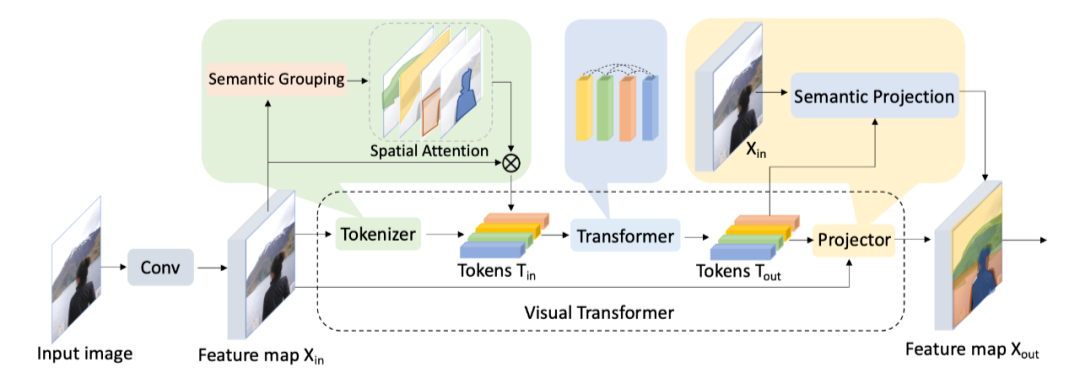
图像作为一种高维、噪声大、冗余度高的形态,被认为是生成建模的难点,这也是为什么过了好几年,transformer 才应用到视觉领域。比较初始的应用是在 Visual Transformer 一文中,作者使用 CNN 提取 low-level 的特征,然后将这些特征输 入Visual Transformer [1](VT)。
与这项工作不同的是,最近出现的 iGPT , ViT 和 DeiT 都是只使用 transformer 的文章。
在 CV 中使用 transformer,目前来看主要的两个问题,以及下列文章的核心区别在于:
得到 Token 的方式
训练的方式
评估 representation 的方式
3.1.1 iGPT

论文标题:Generative Pretraining from Pixels
论文链接:https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf
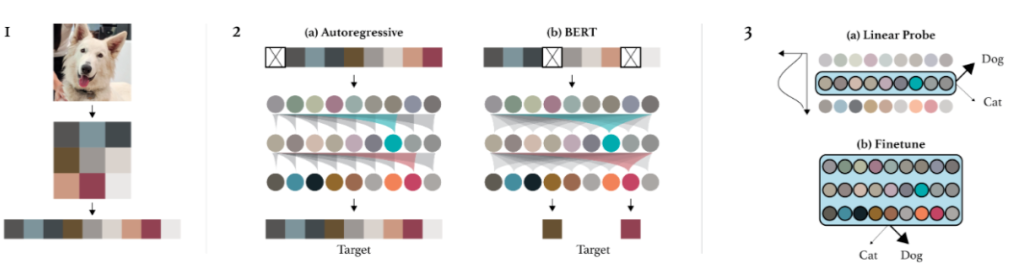
nn.Embedding(num_vocab, embed_dim)提取每个像素 embedding。至此图片数据已经完全转化为了 transformer 的输入形式 。其中 seq_len 取决于 down sample 保留了多少 pixel。attn_mask = torch.full(
(len(x), len(x)), -float("Inf"), device=x.device, dtype=x.dtype
)
attn_mask = torch.triu(attn_mask, diagonal=1)#[784, 784]
#attn_mask = [[0,-inf,-inf...,-inf],
# [0,0,-inf,...,-inf],
# [0,0,0,...,-inf],
# [0,0,0,...,0]]
Evaluation:两种评估方式:1)fine-tune:增加了一个小的分类头,用于优化分类目标并 adapt 所有权重;2)Linear-probe:将 pretraining 的模型视作特征提取器,增加一个分类头,只训练这个分类头。第二种方式的直觉在于“一个好的特征应该能够区分不同的类”,除此之外,fine-tune 效果好有可能是因为架构很适合下游任务,但是 linear-probe 只取决于特征质量。
主要过程的代码如下,数字只是为了示例,下面假设字典长度为 16(pixel 一共 16 种)。
# x:原始图像处理后得到的序列 [32*32, 64],64为batchsize,32是下采样后的长款
length, batch = x.shape
# 将每个pixel作为token求embedding,128为embedding的维度
h = self.token_embeddings(x) # [32*32, 64, 128]
# 添加位置编码
h = h + self.position_embeddings(positions).expand_as(h)
# transformer
for layer in self.layers:
h = layer(h)
# 自回归编码需要输出logits,映射回字典长度
logits = self.head(h) # [32*32,64,16]
# 16类的cross_entropy,对每个pixel计算损失
loss = self.criterion(logits.view(-1, logits.size(-1)), x.view(-1))
3.1.2 ViT

论文标题:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
论文链接:https://arxiv.org/abs/2010.11929
代码链接:https://github.com/google-research/vision_transformer
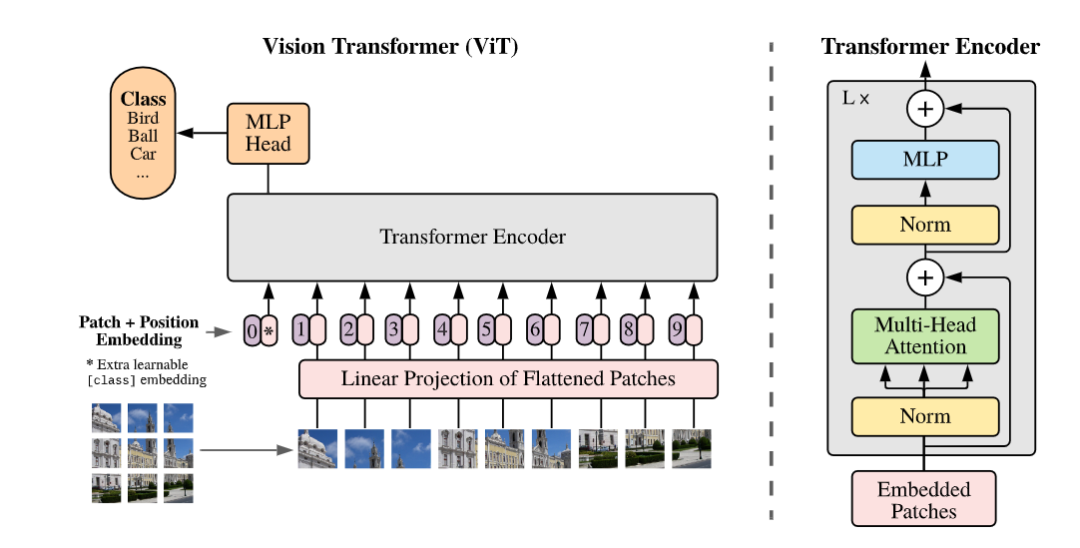
Pretrain:传统情况下 ViT 也是要预训练的,不同于 iGPT,这不是一个生成式的模型,只采用了 transformer 的 encoder,因此直接在 imagenet 做分类任务进行 pretrain。文章显示数据集小的时候效果一般,数据集大的时候因为 data bias 已经被消除了很多,此时效果非常好。
Evaluation:分类任务的评价不再多说。
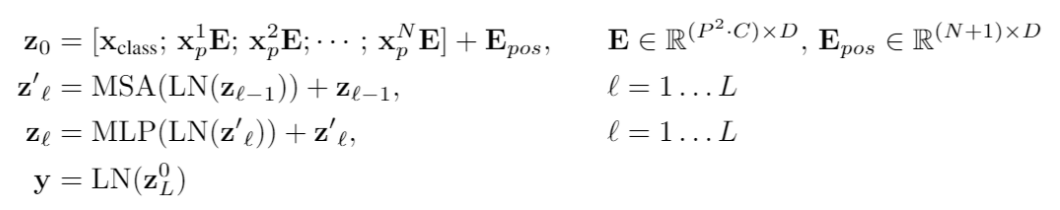
3.2.1 Generic Object Detection
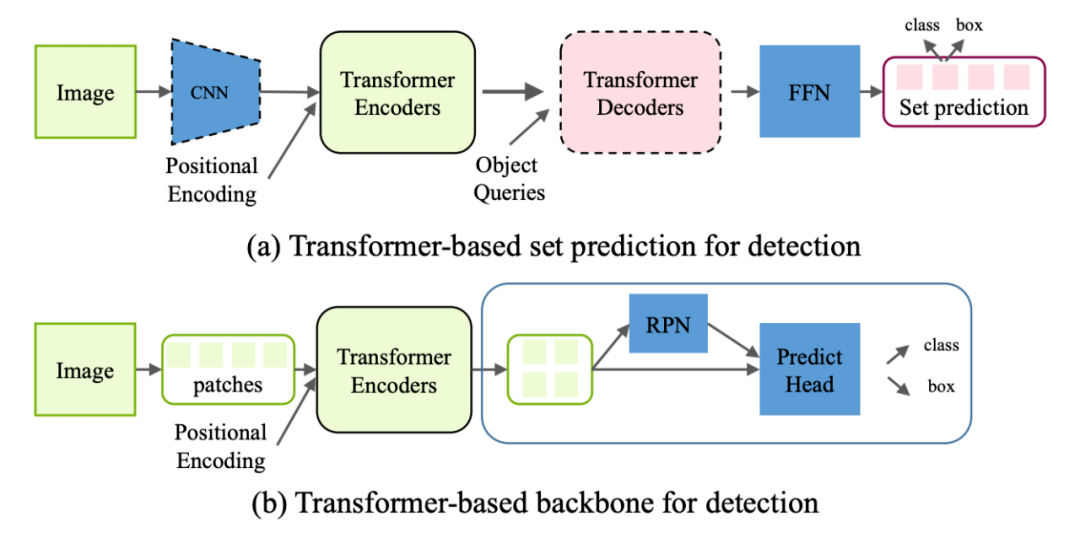
Transformer-based set prediction for detection. DETR [2] 是这类工作的先驱,其将目标检测视为集合预测问题,去掉了目标检测种很多手工的组件像 NMS,anchor generation 等。
Train:如何将 object detection 转化为 set prediction 然后进行训练,这是一个非常有意思的问题。作者使用了 object queries,这实际上是另一组可学习的 positional embedding,其功能类似于 anchor。之后每个 query 进过 decoder 后算一个 bbox 和 class prob。
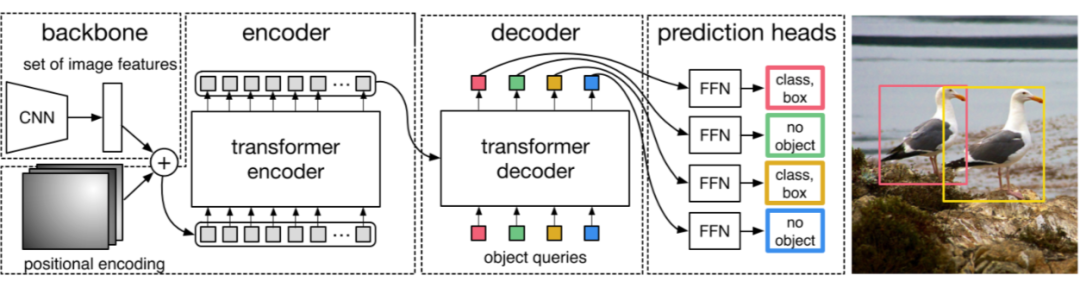
DETR 也大方地承认了他的缺点:训练周期长,对小物体检测效果差。
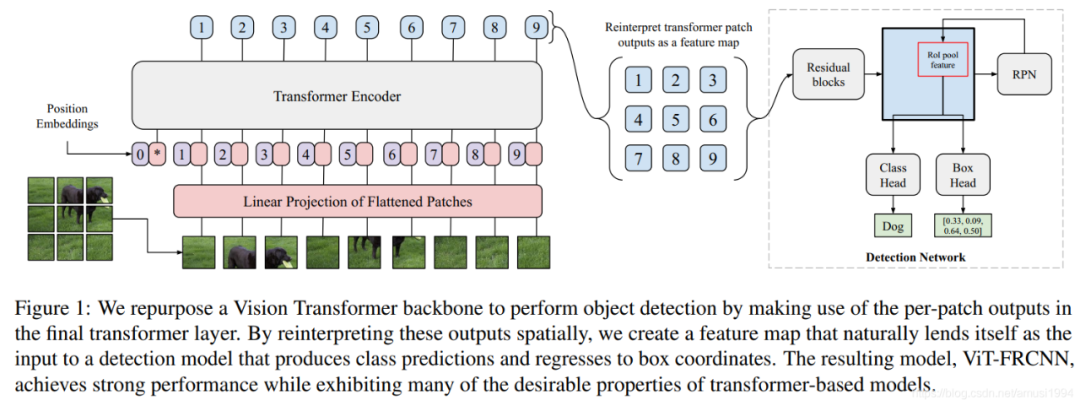
总结一下,目前 transformer 已经在很多视觉应用中展现出了强大的实力。使用 transformer 最重要的两个问题是如何得到输入的 embedding(妥善处理position embedding),模型的训练与评估。
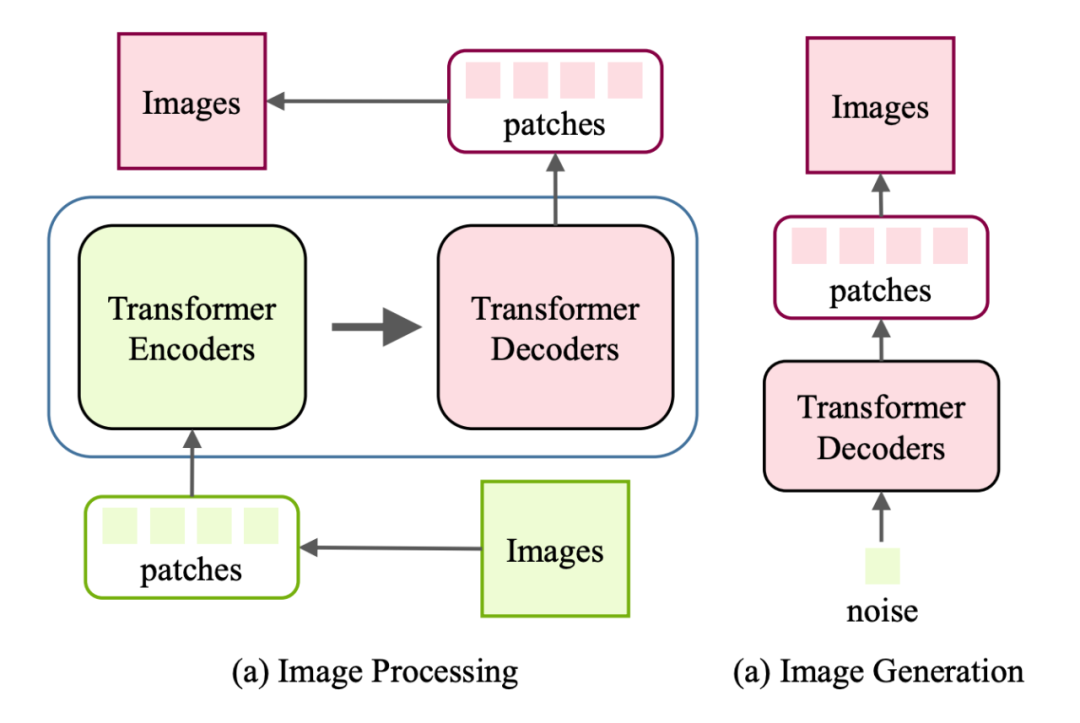
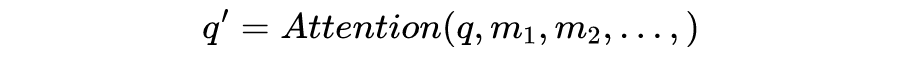
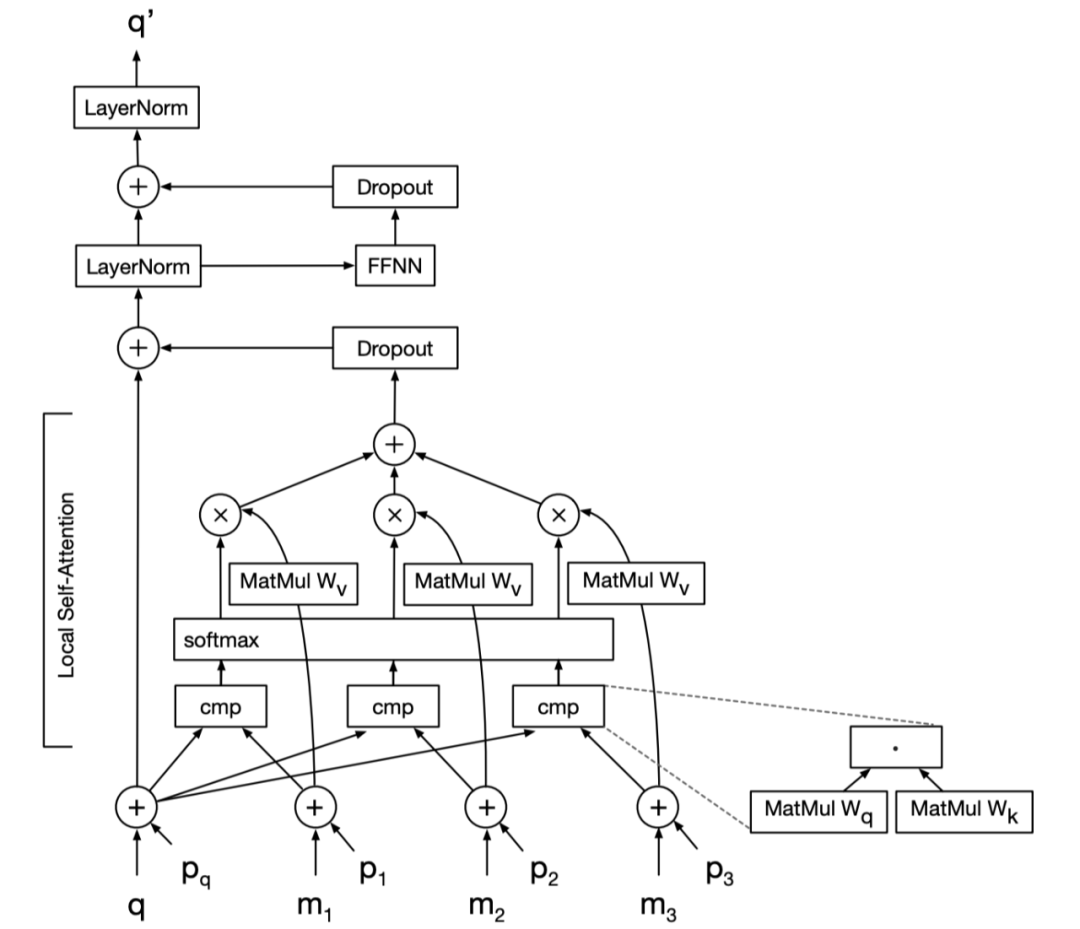
由于解码器的输入是原生成的像素,在生成高分辨率图像时会带来较大的计算成本,因此提出了一种局部自注意方案,只使用最接近的生成像素作为解码器的输入。结果表明,该图像转换器在图像生成和翻译任务上与基于 cnn 的模型具有竞争性能,表明了基于转换器的模型在低层次视觉任务上的有效性。

Conclusions and Discussions
4.1 Challenges
目前来看,大多数应用都保留了 transformer 在 NLP 任务中的原始形态,这一形态不一定适合 images,因此是否会有改进版本,更加适合视觉任务的 transformer 尚且未知。除此之外,transformer 需要的数据量太大,缺少像 CNN 一样的 inductive biases,我们也很难解释他为什么 work,在本就是黑盒的DL领域又套了一层黑盒。
像 NLP 一样的大一统模型,一个 transformer 解决所有下游任务。 高效的部署与运行。 可解释性。

参考文献
推荐阅读
GPU底层优化 | 如何让Transformer在GPU上跑得更快?
如何看待Transformer在CV上的应用前景,未来有可能替代CNN吗?

