
再见,迁移学习?可解释和泛化的行人再辨识|ECCV 2020

极市导读
本文提出了一种查询图自适应的卷积,这种技术比特征学习更容易泛化至未知场景,有助于“开箱即用”的行人再辨识技术的发展。>>加入极市CV技术交流群,走在计算机视觉的最前沿

简介

研究动机
查询图自适应卷积
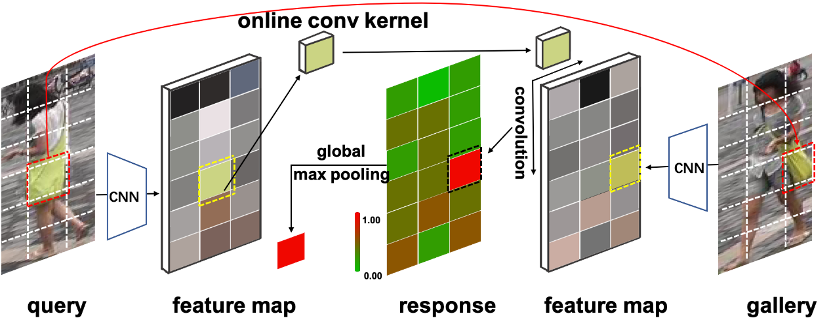
QAConv 训练时的网络结构如图 3 所示,包含骨干网络、QAConv 模块、类别记忆模块、全局最大池化(GMP)、BN-FC-BN 度量学习模块和损失函数。
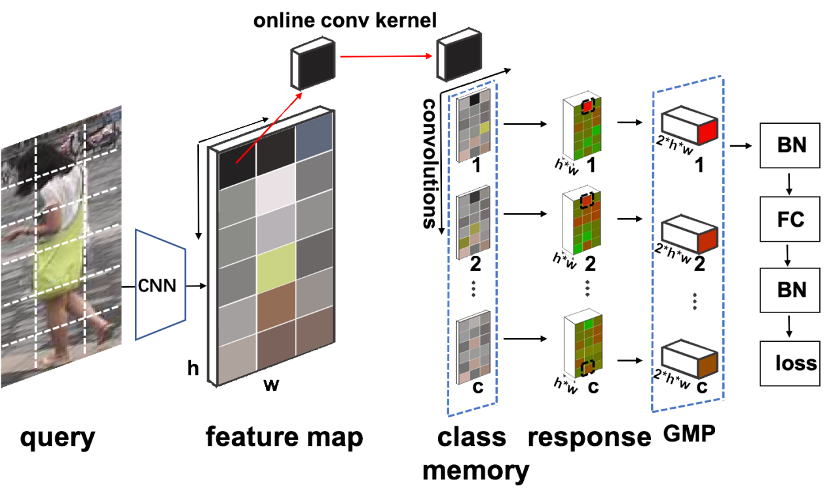
在 BN-FC-BN 模块之后,我们采用了一个 sigmoid 函数将相似度分数映射到 [0,1] 区间,并计算二值交叉熵损失。由于负样本对比正样本对多得多,为了平衡样本分布同时在线挖掘难例样本,我们也采用了 focal loss 来加权损失。
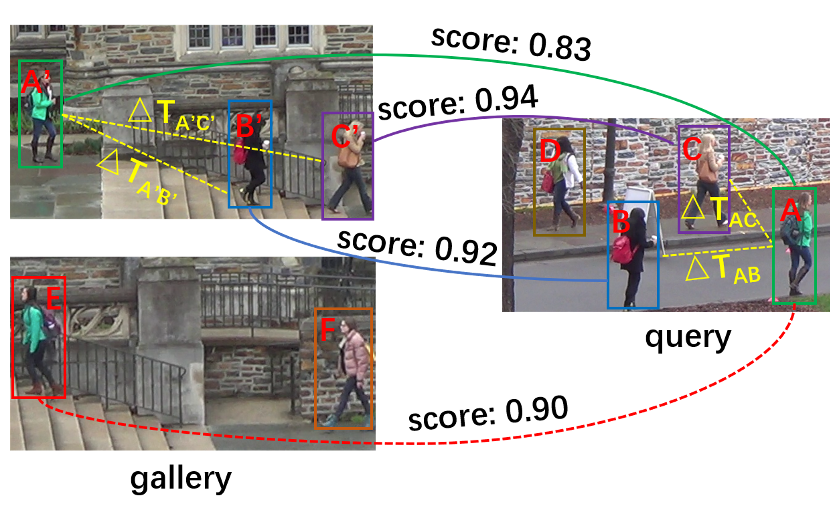
时序提举
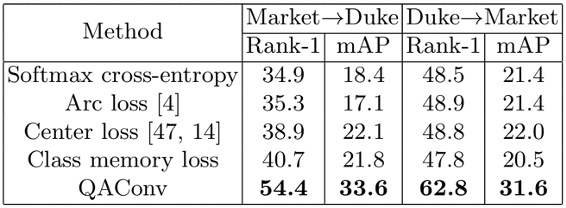
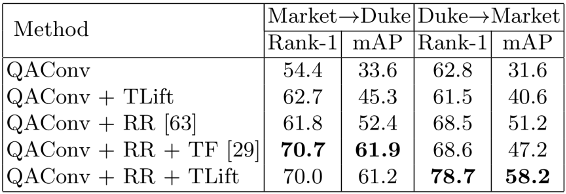
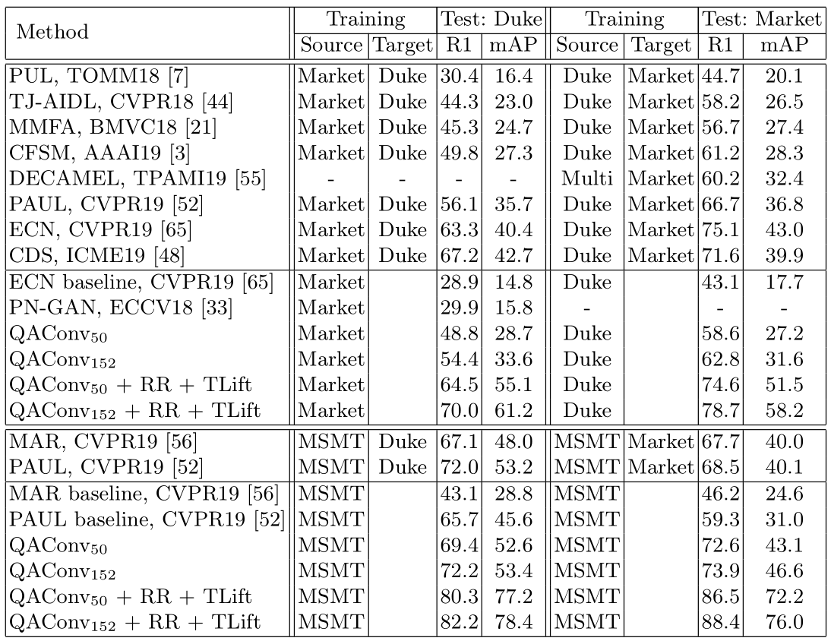
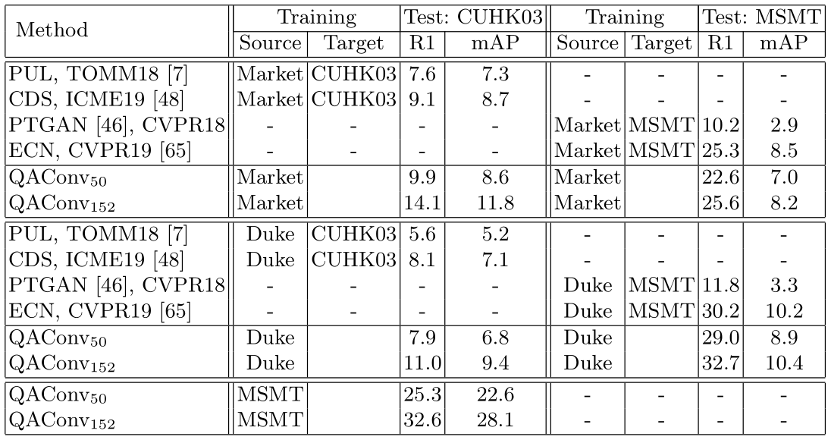
实验结果
结语
推荐阅读

评论