点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

近年来,可解释机器学习(IML) 的相关研究蓬勃发展。尽管这个领域才刚刚起步,但是它在回归建模和基于规则的机器学习方面的相关工作却始于20世纪60年代。最近,arXiv上的一篇论文简要介绍了解释机器学习(IML)领域的历史,给出了最先进的可解释方法的概述,并讨论了遇到的挑战。
当机器学习模型用在产品、决策或者研究过程中的时候,“可解释性”通常是一个决定因素。
可解释机器学习(Interpretable machine learning ,简称 IML)可以用来来发现知识,调试、证明模型及其预测,以及控制和改进模型。
研究人员认为 IML的发展在某些情况下可以认为已经步入了一个新的阶段,但仍然存在一些挑战。
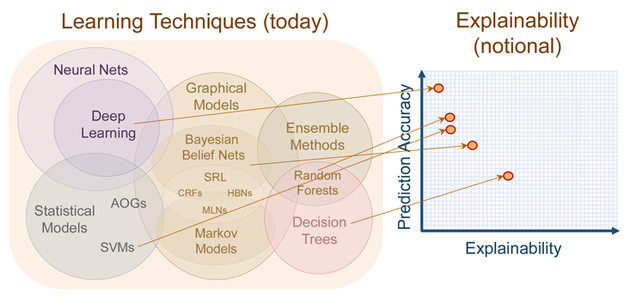
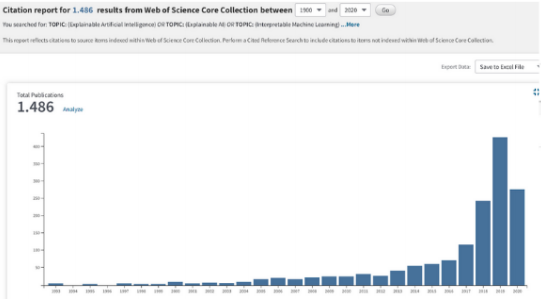
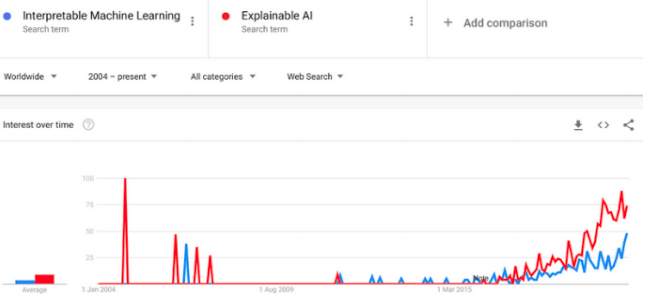
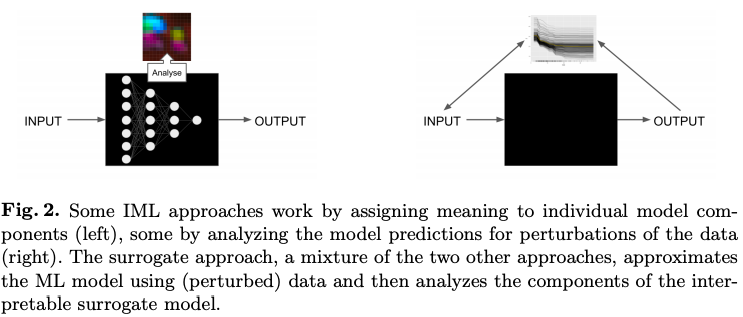
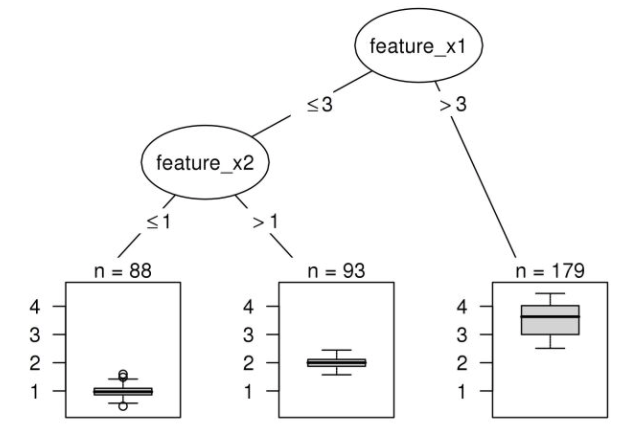
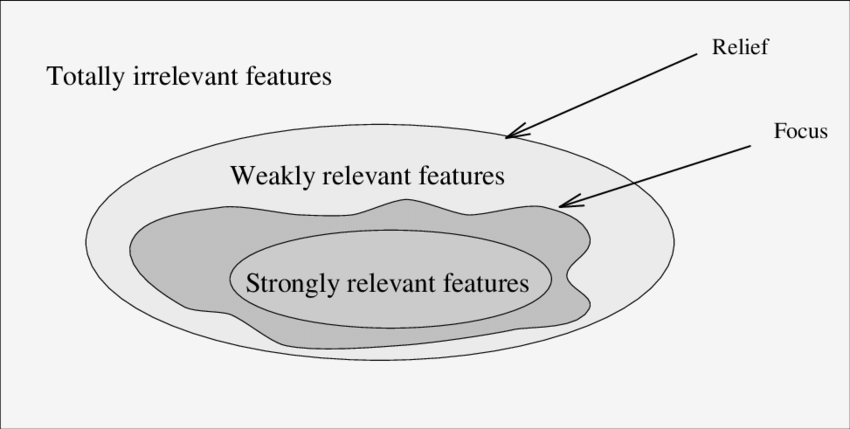
最近几年有很多关于可解释机器学习的相关研究, 但是从数据中学习可解释模型的历史由来已久。线性回归早在19世纪初就已经被使用,从那以后又发展成各种各样的回归分析工具,例如,广义相加模型(generalized additive models)和弹性网络(elastic net)等。这些统计模型背后的哲学意义通常是做出某些分布假设或限制模型的复杂性,并因此强加模型的内在可解释性。机器学习算法通常遵循非线性,非参数方法,而不是预先限制模型的复杂性,在该方法中,模型的复杂性通过一个或多个超参数进行控制,并通过交叉验证进行选择。这种灵活性通常会导致难以解释的模型具有良好的预测性能。虽然机器学习算法通常侧重于预测的性能,但关于机器学习的可解释性的工作已经存在了很多年。随机森林中内置的特征重要性度量是可解释机器学习的重要里程碑之一。深度学习在经历了很长时间的发展后,终于在2010年的ImageNet中获胜。从那以后的几年,根据Google上“可解释性机器学习”和“可解释的AI”这两个搜索词的出现频率,可以大概得出IML领域在2015年才真正起飞。通常会通过分析模型组件,模型敏感性或替代模型来区分IML方法。为了分析模型的组成部分,需要将其分解为可以单独解释的部分。但是,并不一定需要用户完全了解该模型。通常可解释模型是具有可学习的结构和参数的模型,可以为其分配特定的解释。在这种情况下,线性回归模型,决策树和决策规则被认为是可解释的。线性回归模型可以通过分析组件来解释:模型结构(特征的加权求和)允许将权重解释为特征对预测的影响。研究人员还会分析更复杂的黑盒模型的组成部分。例如,可以通过查找或生成激活的CNN特征图的图像来可视化卷积神经网络(CNN)学习的抽象特征。对于随机森林,通过树的最小深度分布和基尼系数来分析随机森林中的树,可以用来量化特征的重要性。模型成分分析是一个不错的工具,但是它的缺点是与特定的模型相关, 而且它不能与常用的模型选择方法很好地结合,通常是通过机器学习搜索很多不同的ML模型进行交叉验证。许多 IML 方法,例如:特征重要度的排列组合等,在不量化解释不确定性的情况下提供了解释。模型本身以及其解释都是根据数据计算的,因此存在不确定性。目前研究正在努力量化解释的不确定性,例如对于特征重要性的逐层分析相关性等。理想情况下,模型应反映其潜在现象的真实因果结构,以进行因果解释。如果在科学中使用IML,则因果解释通常是建模的目标。但是大多数统计学习程序仅反映特征之间的相关结构并分析数据的生成过程,而不是其真正的固有结构。这样的因果结构也将使模型更强大地对抗攻击,并且在用作决策依据时更有用。不幸的是,预测性能和因果关系可能是一种相互矛盾的目标。例如,今天的天气直接导致明天的天气,但是我们可能只能使用“湿滑的地面”这个信息,在预测模型中使用“湿滑的地面”来表示明天的天气很有用,因为它含有今天的天气的信息,但由于ML模型中缺少了今天的天气信息,因此不能对其进行因果解释。特征之间的依赖引入了归因和外推问题。例如,当特征之间相互关联并共享信息时,特征的重要性和作用就变得难以区分。随机森林中的相关特征具有较高的重要性,许多基于灵敏度分析的方法会置换特征,当置换后的特征与另一特征具有某种依赖性时,此关联将断开,并且所得数据点将外推到分布之外的区域。ML模型从未在这类组合数据上进行过训练,并且可能不会在应用程序中遇到类似的数据点。因此,外推可能会引起误解。如何向具有不同知识和背景的个人解释预测结果,以及满足有关机构或社会层面的可解释性的需求可能是IML今后的目标。它涵盖了更广泛的领域,例如人机交互,心理学和社会学等。为了解决未来的挑战,作者认为可解释机器学习领域必须横向延伸到其他领域,并在统计和计算机科学方面纵向延伸。https://arxiv.org/abs/2010.09337