
数据不够,游戏来凑!随机三维人物实现可泛化的行人再辨识(ReID)
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
转载:52cv
【导语】数据不够,游戏来凑!阿联酋起源人工智能研究院(IIAI)科学家通过随机组合颜色和纹理产生了8000个三维人物模型,并在游戏环境里模拟真实监控得到一个虚拟行人数据集,最终通过跨库泛化性测试一举超越了CUHK03,Market-1501,DukeMTMC-reID和几乎MSMT17在内的四大主流行人再辨识数据集。

相关论文(Surpassing Real-World Source Training Data: Random 3D Characters for Generalizable Person Re-Identification)已被ACMMM 2020接收,数据已开源。

图1. RandPerson虚拟数据库示例图简介
行人再辨识是近年来的热门研究领域,随着深度学习的发展取得了很大的进步。但是已有模型在不同场景下的泛化能力依然较差。一个可能的原因是,由于标注困难和隐私敏感,目前仍然缺乏大规模和多样性的训练数据。
有鉴于此,本文提出一种随机自动产生大量三维人物模型的方法,并在游戏环境里模拟真实监控进行渲染,由此得到一个大规模的虚拟行人数据集,并最终实现可泛化的行人再辨识。
具体地,本文提出一种通过随机组合颜色和纹理产生大量UV纹理图的方法,并由此创建了大量的三维衣服模型。随后,针对MakeHuman的人物格式,我们设计了一个代码随机生成各种不同的身高、皮肤、衣服穿搭和配饰的三维人物模型。
最后,我们在Unity3D的多个室内外场景下模拟真实监控定制了多摄像机环境和行走路径,并导入大量三维人物同时进行行走穿插和多摄像机录像。
由此,我们得到一个包含全自动标注的虚拟行人数据集,称为RandPerson,它包含8,000个虚拟人物,11个场景,19个摄像机,38段密集行人的视频,1,801,816张切好的行人图片,示例如图1所示。
通过训练行人再辨识模型并直接跨库测试泛化性能,我们首次证明了虚拟数据上训练的行人再辨识模型可以更好地泛化到未知场景的真实图像上:对比之下RandPerson一举超越了CUHK03,Market-1501,DukeMTMC-reID和几乎MSMT17在内的四大主流行人再辨识数据集。
研究动机
数据匮乏一直制约着行人再辨识的发展,除了标注困难之外,近年来对监控视频数据的隐私敏感性更是让这个问题雪上加霜,已经有一些公开数据集因此而下架了。
MSMT17是目前多样性最大的行人再辨识数据集,但是它的数据依然是局限在同一个局部校园场景中采集的。因此,如何创建有类别标签且多样性丰富的行人再辨识数据集依然是个挑战,比如在场景、光照、服饰等各方面的多样性。
在当前的数据条件下,深度学习在同一个库上训练和测试已经取得了很好的性能,甚至已接近天花板。然而,受制于训练数据,在跨库测试时,这些方法训练的模型在未知场景上的泛化性能依然较差。
为此,研究人员提出了许多迁移学习方法来提升模型在目标场景上的性能。然而,这些方法都需要在目标场景上重新采集训练数据进行深度学习,虽然无需人工标注,但仍然费时费力。
另一方面,为了解决数据问题,研究人员开始探索通过游戏引擎产生虚拟数据以辅助行人再辨识,例如SOMAset,SyRI,和PersonX。然而,这些方法主要采用的是公开获取的或手工制作的三维人物模型,因此其人物数量很难增长到一定的量级。
例如,上述三个虚拟行人数据集中最大的是PersonX,但也仅有1266人。此外,这些数据集都是每个人物独立导入场景中并在同一时刻只有一个摄像机进行拍照或录像的,这与真实监控场景下多摄像机同时拍摄一个大场景下所有人的活动有很大的区别,最明显的区别是缺乏人与人之间的遮挡和摄像机之间的转移规律。
因此,为了解决上述这些问题,我们提出一种通过Python代码随机自动产生大量三维人物模型的方法,使得创建的三维人物在数量上具有很好的可扩展性,且在身高、肤色、衣服颜色和纹理、配饰等方面拥有丰富的多样性。
其次,我们在Unity3D的多个室内外场景下定制了多摄像机环境、光照、视角、视距和行走路径等,并导入大量三维人物同时进行行走穿插和多摄像机录像。这在一定程度上模拟了真实监控,使得产生的数据在背景、光照、分辨率、视角、姿态、遮挡等方面也拥有丰富的多样性,从而有力地支持了训练出可泛化的行人再辨识。
随机三维人物
我们采用了MakeHuman来制作三维人物,该软件的用户社区资源中包含多种衣服模型,包括外套、上衣、裤子等,如图2所示。
 图2. MakeHuman社区资源中不同种类的衣服在MakeHuman中,新人物的创建主要通过面板操作进行,例如增加配饰、调整身体参数、添加人物骨骼等。图3展示了在MakeHuman中搭配配饰的过程。图中第一列为配饰三维模型,第二列为配饰相应的UV纹理映射图,第三列为生成的人物。
图2. MakeHuman社区资源中不同种类的衣服在MakeHuman中,新人物的创建主要通过面板操作进行,例如增加配饰、调整身体参数、添加人物骨骼等。图3展示了在MakeHuman中搭配配饰的过程。图中第一列为配饰三维模型,第二列为配饰相应的UV纹理映射图,第三列为生成的人物。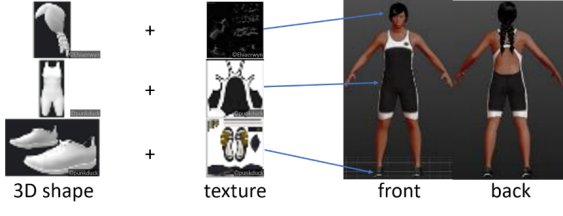 图3. MakeHuman中的三维人物搭配过程虽然MakeHuman社区中提供了很多衣服模型,但是只有几百个常用的模型,因此仍然很有限。由于衣服模型的外观主要由其UV纹理映射图决定,因此,针对这个特点,我们提出直接对现有模型中的纹理映射图进行各种修改来产生大量不同外观的衣服模型。
图3. MakeHuman中的三维人物搭配过程虽然MakeHuman社区中提供了很多衣服模型,但是只有几百个常用的模型,因此仍然很有限。由于衣服模型的外观主要由其UV纹理映射图决定,因此,针对这个特点,我们提出直接对现有模型中的纹理映射图进行各种修改来产生大量不同外观的衣服模型。
我们主要通过两种方式来生成纹理映射图。一种是简单地采用网络图案进行贴图,但该种方式产生的纹理图分布并不可控,难以覆盖足够的多样性。
因此,我们进一步对颜色和纹理模式进行采样和组合来产生更具多样性的纹理映射图。我们在HSV空间均匀地采样了625种颜色作为调色板(如图4所示),并绘制了16种不同的纹理模式(如图5所示)。
在此基础上,我们将颜色与纹理进行组合,得到625*16=10,000张纹理映射图,如图6所示。
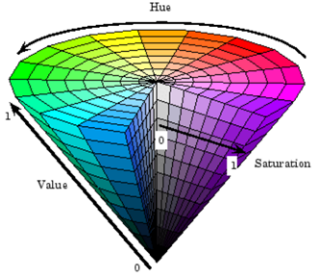 图4. HSV空间
图4. HSV空间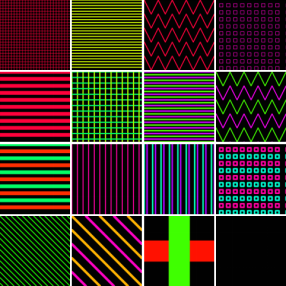 图5. 16种不同的纹理模式
图5. 16种不同的纹理模式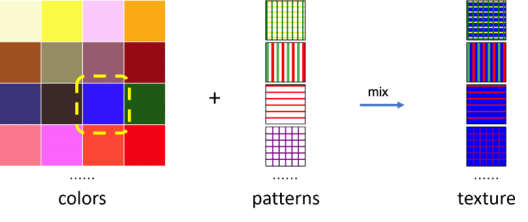 图6. 组合颜色和纹理模式产生不同的纹理映射图的过程通过获得的大量UV纹理映射图,我们可以通过替换已有衣服模型纹理图的方式生成不同的衣服,如图7所示,左边为原始的衣服模型及其效果,中间为替换成网络贴图后的效果,右边为我们提出的组合颜色和纹理模式的效果。
图6. 组合颜色和纹理模式产生不同的纹理映射图的过程通过获得的大量UV纹理映射图,我们可以通过替换已有衣服模型纹理图的方式生成不同的衣服,如图7所示,左边为原始的衣服模型及其效果,中间为替换成网络贴图后的效果,右边为我们提出的组合颜色和纹理模式的效果。 图7. 替换纹理映射图产生的人物模型在MakeHuman中可以通过调整身体参数改变人物模型外观,比如身高、体重、肌肉比例等。由于手工调整这些参数和给人物添加不同衣服非常耗时耗力,我们分析了MakeHuman保存的人物模型文件后,编写了一个Python代码自动生成人物模型文件。
图7. 替换纹理映射图产生的人物模型在MakeHuman中可以通过调整身体参数改变人物模型外观,比如身高、体重、肌肉比例等。由于手工调整这些参数和给人物添加不同衣服非常耗时耗力,我们分析了MakeHuman保存的人物模型文件后,编写了一个Python代码自动生成人物模型文件。
该代码主要通过随机设定性别、身高、体重、肤色等参数,并随机组合衣服模型和配饰等来创建三维人物模型。最终,我们创建了8,000个人物,包括使用原始衣服模型创建了114个人物,使用网络图案创建了2886个人物,使用颜色和纹理模式组合创建了5000个人物。
虚拟环境
Unity3D是一个跨平台3D游戏引擎,它的资源商店拥有很多可获得的模型,例如场景,人物,动作等。然而,免费的3D人物模型较少,因此我们使用上述设计的随机3D人物。
我们从Unity3D资源商店下载了8个室外场景和3个室内场景,模拟不同场景下的行人数据。通过场景的改变,可以产生不同光照、背景的数据;通过架设不同的摄像机,可以产生不同视角、清晰度的数据;通过行人的运动(走路和跑步等),可以产生不同姿态的数据。在一些场景中,我们通过将光照强度在0到1.5之间逐渐改变来模仿一天中光照的变化。图8展示了本文用到的11个场景。
 图8. 本文用到的11个场景与之前的虚拟行人数据不同的是,我们对多个场景建立了多摄像机网络同时进行录制,并且在场景中导入大量人物同时进行行走穿插。由于视角、背景、分辨率都是行人再辨识中的重要因素,我们在架设摄像机时尽量选择不同的区域、朝向、俯仰角和视距,如图9所示。
图8. 本文用到的11个场景与之前的虚拟行人数据不同的是,我们对多个场景建立了多摄像机网络同时进行录制,并且在场景中导入大量人物同时进行行走穿插。由于视角、背景、分辨率都是行人再辨识中的重要因素,我们在架设摄像机时尽量选择不同的区域、朝向、俯仰角和视距,如图9所示。
我们在11个场景中共架设了19个摄像机。由于摄像机高度、角度、距离的不同,生成的数据在背景、视角、分辨率上也各不相同,由此增加了数据的多样性。由于我们在多摄像机场景中同时渲染大量人物,因此,人与人之间的遮挡很常见,这也是在真实场景中很常见的,同时也是影响行人再辨识的重要因素。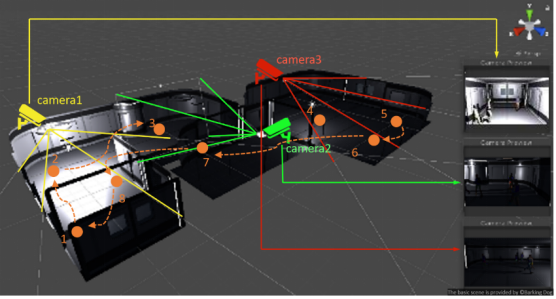 图9.多摄像机网络架设示意图除了多摄像机视频录制外,为了追踪每个人物的轨迹并实现全自动的数据标注和切图,我们将每个人物轨迹的位置、时间和关键点坐标也保存下来,最后根据这些标注数据产生人物的包围框并从视频中切图。
图9.多摄像机网络架设示意图除了多摄像机视频录制外,为了追踪每个人物的轨迹并实现全自动的数据标注和切图,我们将每个人物轨迹的位置、时间和关键点坐标也保存下来,最后根据这些标注数据产生人物的包围框并从视频中切图。
通过以上步骤,我们创建了一个虚拟行人数据集,称为RandPerson。它包括8,000个人物和1,801,816张图片。表1统计了RandPerson和其他虚拟行人数据集的一些特征。除了拥有更多的人物和图片数外,RandPerson最重要的特征是与真实监控场景类似,有多人同时在场景中进行运动并由多摄像机同时拍摄。 表1. 虚拟行人数据集统计表实验结果
表1. 虚拟行人数据集统计表实验结果
通过训练行人再辨识的深度学习模型并直接跨库测试泛化性能,我们首次证明了在虚拟数据上训练的模型超越了在各种真实数据库上训练的模型,包括CUHK03、Market-1501和DukeMTMC-reID,以及大部分MSMT17的结果,如表2-5所示。只不过以DuckMTMC-reID作为测试集时RandPerson训练的结果还是比MSMT17略差,这一方面是因为MSMT17是目前多样性最大的行人再辨识数据集,另一方面是因为虚拟数据和真实数据之间本身还是有领域差异。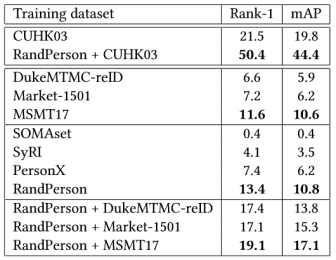 表2. CUHK03-NP作为测试集的结果
表2. CUHK03-NP作为测试集的结果 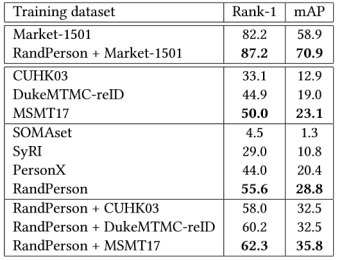 表3. Market-1501作为测试集的结果
表3. Market-1501作为测试集的结果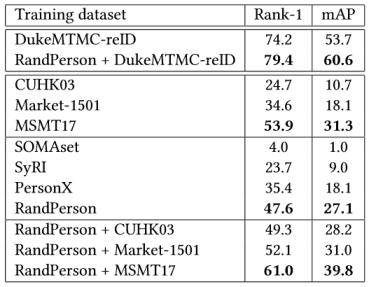 表4. DukeMTMC-reID作为测试集的结果
表4. DukeMTMC-reID作为测试集的结果
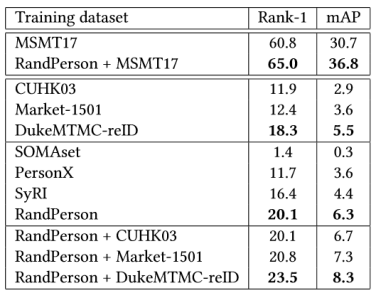 表5. MSMT17作为测试集的结果 一种缩短这种差异的方法是将虚拟数据和真实数据融合在一起当做一个数据源进行训练,结果也列在表2-5中。
表5. MSMT17作为测试集的结果 一种缩短这种差异的方法是将虚拟数据和真实数据融合在一起当做一个数据源进行训练,结果也列在表2-5中。
我们从三方面进行总结:
第一,在跨库测试时,数据融合后训练的结果比单独使用单个真实数据集有大幅提升,这表明RandPerson虽然是个虚拟数据集,但是在训练时依然可以作为真实数据集的有效补充。
第二,在同库测试时,数据融合后进一步提升了测试结果。以CUHK03-NP为例,数据融合后在Rank-1上提升了28.9%,在mAP上提升了24.6%。
第三,在跨库测试时与只使用RandPerson相比,测试结果在数据融合后也有很大提升,这表明将虚拟数据和真实数据融合训练时,确实缩短了真实数据和虚拟数据之间的差异。
结论
为了提升行人再辨识模型的泛化能力,本文提出了一个称为RandPerson的大规模虚拟行人数据集。该数据集主要通过自动代码生成大规模随机三维人物,并且模拟真实监控场景,在虚拟环境中采用多摄像机同时录制大量人物在场景中的运动。
通过训练行人识别模型并直接跨库测试,我们首次证明了从虚拟数据中训练的模型能更好地泛化到未知场景的真实图像上,超过了CUHK03、Market-1501、DukeMTMC-reID和几乎MSMT17在内的四大主流行人再辨识数据集上训练的模型。
本文提出的方法的优势是在产生虚拟行人数据时可以方便扩展到大量的人物和场景,同时不需要人工标注,并且避免了真实监控视频的隐私问题。本文提出的虚拟行人数据集还包含多摄像机视频和人物关键点信息,因此未来也可以在其他领域进行探索,例如姿态估计和多摄像机跟踪。
论文地址:
https://arxiv.org/abs/2006.12774
项目地址:
https://github.com/VideoObjectSearch/RandPerson
作者简介
王雅楠,现任阿联酋起源人工智能研究院工程师。研究兴趣为行人分析。
廖胜才,中科院自动化所博士及曾任副研究员,现任阿联酋起源人工智能研究院Lead Scientist。IEEE高级会员。研究兴趣为行人和人脸分析。