
基于微博评论的文本情感分析与关键词提取的实战案例~
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是志斌~
上一篇文章基于Scrapy框架的微博评论爬虫实战,志斌给大家介绍了,如何用Scrapy框架,爬取微博评论的内容,接下来就要对爬取下来的评论文本进行情感分析。
在评论文本情感分析之前,我们需要将语句通过分词使其成为词语,然后优化分词结果,去掉无关的词语和字符。,以提高文本情感分析的准确度。
01
分词
对中文句子按照其语义进行切割的这类操作,被称为“分词”。目前的分词技术有两种,一种是从统计学的角度进行分词,另一种是从词库的角度基于TF-IDF算法,来对语句进行分词。
Python中的Jieba库就是利用词库来对语句进行自动分词的,所以志斌就给大家介绍一下如何用Jieba库来实现文本分割。
01
分词原理
Jieba库在安装时,会附带一个词库,这个词库中包含了日常汉语的词语和词性。在分词时,Jieba库会先基于词库对文本进行匹配,生成文本中的汉字最有可能形成的词。
然后将这些词组成一个DAG,用动态规划算法来查找最大的概率路径,尽可能不将一个词拆成单独的汉字。
最后,再从词库中找出基于词频的最大切分组合,把这些组合在文本中找出来,进而形成一个一个的词语。
同时Jieba库还使用了HMM模型,用以提高分词的准确率,该模型可以对词库中没有的词进行分词。
02
分词方法
Jieba库里有一个cut函数,它为我们提供了自动分词功能,代码如下:
import jieba # 分词
with open('text.txt','r',encoding='utf-8') as f:
read = f.read()
word = jieba.cut(read)
打印一下分词后的结果

我们发现,上面的分词结果中,有大量的标点符号,和一些与情感表达无关的词语,为了避免无关词语对情感分析的影响和加快计算词语的情感速度,我们就需要对分词的结果进行优化。
02
优化分词
我们主要从以下两个方面来对分词结果进行优化:1.移除标点符号和换行符;2.删除与情感表达无关的词。
接下来,我将给大家介绍两种方法来实现对分词进行优化。
01
使用停用词集
停用词设置是分词中常用的一种手段,可以提高分割的准确度,同时减少硬件成本、时间成本。网上有许多的停用词集,我们可以挑一个进行下载。在文末,志斌会放自己使用的停用词集链接。代码如下:
import jieba # 分词
with open('text.txt','r',encoding='utf-8') as f:
read = f.read()
with open('停用词表.txt','r',encoding='utf-8') as f:
stop_word = f.read()
word = jieba.cut(read)
words = []
for i in list(word):
if i not in stop_word:
words.append(i)打印一下分词后的结果

我们发现标点符号和与情感表达无关的词都被过滤掉了。
02
根据词性提取关键词
大家知道,每个词语都是有着自己的词性,我们可以通过Jieba库提取出来每个词的词性,然后进行筛选,保留你需要的词语,代码如下:
import jieba.posseg as psg
cixing = ()
words = []
for i in psg.cut(read):
cixing = (i.word,i.flag) #词语和词性
words.append(cixing)
save = ['a'] #挑选词性
for i in words:
if i[1] in save:
print(i)
给大家分享一个汉语词性表(部分),有更多了解兴趣的读者可以上网搜一下看看。
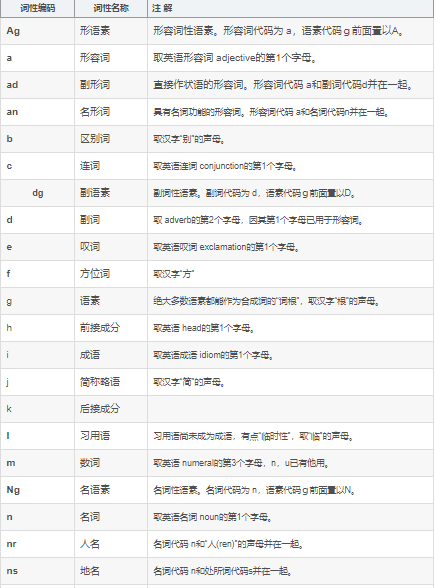
我们上面是只保留了形容词,如果大家想保留更多词性的词语,就在save列表中进行添加即可。
03
结果展示
分词结果优化过之后,我们就得到了自己想要的结果。接下来就是对这些词来进行词频展示和情感分析了。
01
高频词语展示
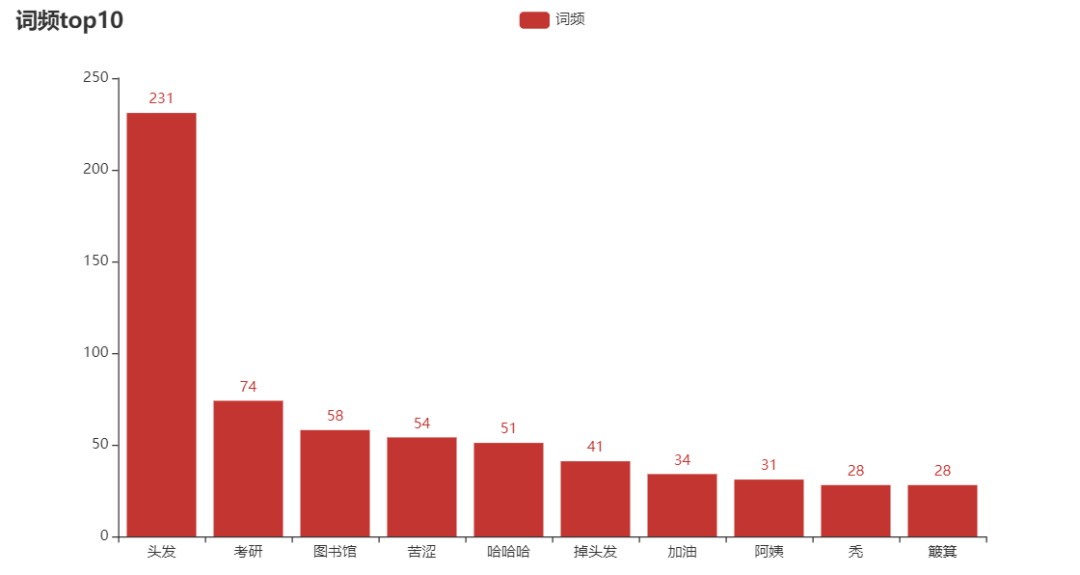
由柱状图可知,“头发”占据词频最高,有231条,其次是词语“考研”和“图书馆”,两个词语分别有74条和58条。
所以我们这条微博的主要关键词是“头发”、“考研”和“图书馆”。

代码如下:
from pyecharts.charts import Bar
from pyecharts import options as opts
columns = []
data = []
for k,v in dict(Counter(words).most_common(10)).items():
columns.append(k)
data.append(v)
bar = (
Bar()
.add_xaxis(columns)
.add_yaxis("词频", data)
.set_global_opts(title_opts=opts.TitleOpts(title="词频top10"))
)
bar.render("词频.html")
02
情感分析
在之前跟大家介绍过两种文本情感分析方法,有兴趣的读者可以看看这篇文章推荐一个强大的自然语言处理库—snownlp。
在本文,我使用的是Snownlp库来对文本进行情感分析。
从图中,我们可以看到,大家的评论积极态度的有32%,中等态度的占60%,消极态度只占8%,看来大家的心态还是很平和的。

代码如下:
from snownlp import SnowNLP
positibe = negtive = middle = 0
for i in words:
pingfen = SnowNLP(i)
if pingfen.sentiments>0.7:
positibe+=1
elif pingfen.sentiments<0.3:
negtive+=1
else:
middle+=1
04
总结
1. 本文详细介绍了如何使用Jieba库对文本进行分词,并使用Snownlp库配合对分词结果进行语义情感分析。
2. 通过对用户评论的分析,我们可以知道用户的喜好程度,从而有策略的改进。
3. 本文仅供学习参考,不做它用。

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~